介绍
深度学习现在是一个非常猖獗的领域 - 有如此多的应用程序日复一日地出现。深入了解深度学习的最佳方法是亲自动手。尽可能多地参与项目,并尝试自己完成。这将帮助您更深入地掌握主题,并帮助您成为更好的深度学习实践者。
在本文中,我们将看一个有趣的多模态主题,我们将结合图像和文本处理来构建一个有用的深度学习应用程序,即图像字幕。图像字幕是指从图像生成文本描述的过程 - 基于图像中的对象和动作。例如:

这个过程在现实生活中有很多潜在的应用。值得注意的是保存图像的标题,以便仅在此描述的基础上可以在稍后阶段轻松检索。
让我们继续吧!
注意:本文假设您了解深度学习的基础知识,并且之前使用过CNN处理图像处理问题。如果您想了解这些概念,可以先阅读这些文章:
目录
图像字幕问题需要什么?
假设你看到这张照片 -

你想到的第一件事是什么?(PS:请在下面的评论中告诉我们!)。
以下是人们可以提出的几句话:
一个男人和一个女孩坐在地上吃。
一个男人和一个小女孩正坐在人行道上附近一个蓝色的袋子吃。
一个男人穿着一件黑色的衬衫和一个穿着橙色礼服的小女孩分享一种享受。
快速浏览一下就足以让您理解并描述图片中正在发生的事情。从人工系统自动生成此文本描述是图像字幕的任务。
任务很简单 - 生成的输出应该在单个句子中描述图像中显示的内容 - 存在的对象,它们的属性,正在执行的动作以及对象之间的交互等。但是要复制此行为。与任何其他图像处理问题一样,人工系统是一项艰巨的任务,因此使用复杂和先进的技术(如深度学习)来解决任务。
解决任务的方法论
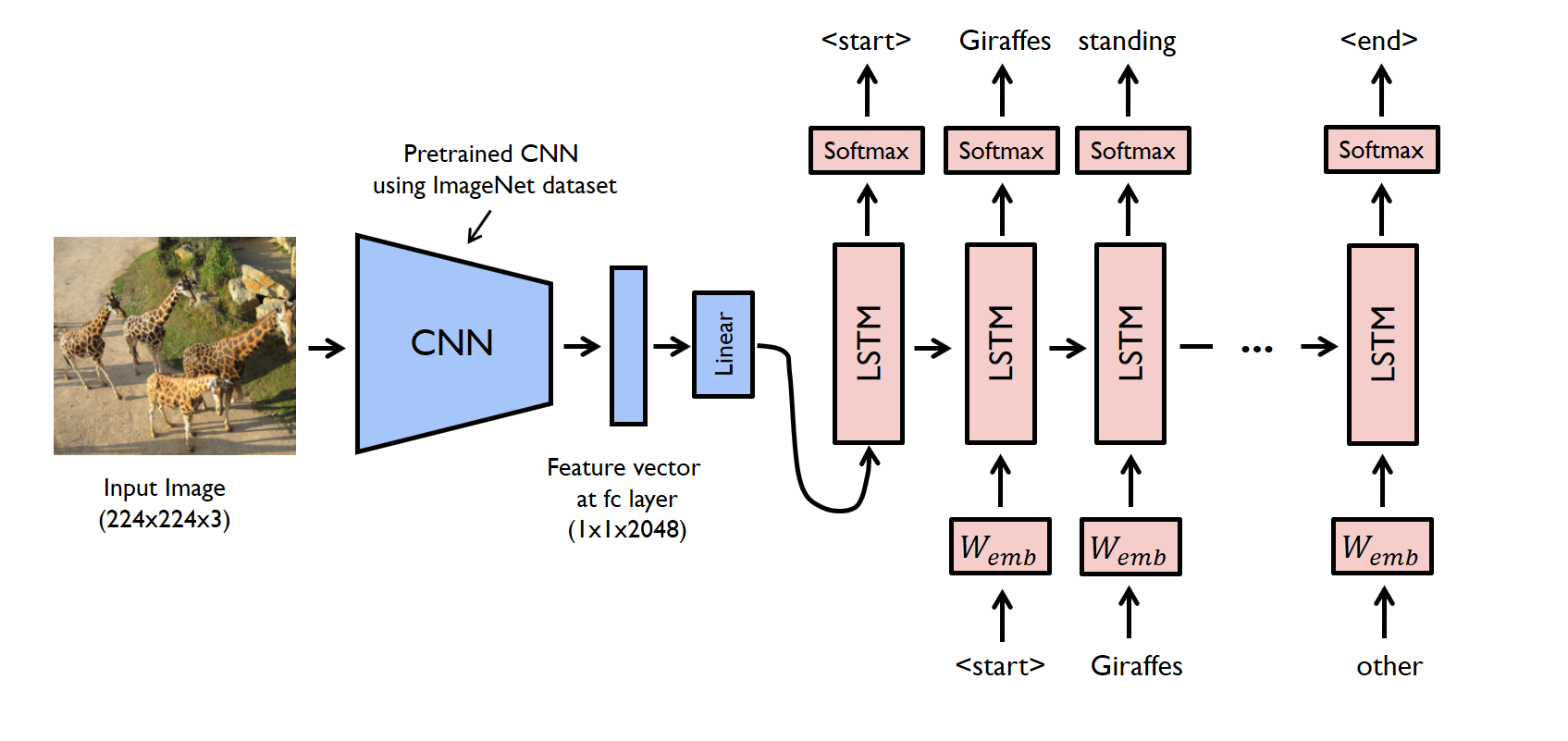
图像字幕的任务可以逻辑地分为两个模块 - 一个是基于图像的模型 - 从图像中提取特征和细微差别,另一个是基于语言的模型 - 它翻译我们的图像给出的特征和对象基于模型的自然句子。
对于我们的基于图像的模型(即编码器) - 我们通常依赖于卷积神经网络模型。对于我们基于语言的模型(即解码器) - 我们依赖于递归神经网络。下图总结了上面给出的方法。

通常,预训练的CNN从输入图像中提取特征。线性变换特征向量以具有与RNN / LSTM网络的输入维度相同的维度。该网络在我们的特征向量上被训练为语言模型。
为了训练我们的LSTM模型,我们预定义了标签和目标文本。例如,如果标题是“一个男人和一个女孩坐在地上吃饭”,我们的标签和目标将如下 -
标签 - [<开始>,A,男人,和,女孩,坐,上,地,和,吃,。]
目标 - [A,男人,和女孩,坐,上,地,和,吃,。,<结束>]
这样做是为了使我们的模型能够理解标记序列的开始和结束。

实施演练
让我们看一下Pytorch中图像字幕的简单实现。我们将图像作为输入,并使用深度学习模型预测其描述。
可以在GitHub上找到此示例的代码 。此代码的原作者是Yunjey Choi。在Pytorch中为他的优秀例子致敬!
在本演练中,预训练的 resnet-152模型用作编码器,解码器是LSTM网络。
要运行此示例中给出的代码,您必须安装先决条件。确保你有一个工作的python环境,最好安装anaconda。然后运行以下命令以安装其余所需的库。
git clone https://github.com/pdollar/coco.git cd coco / PythonAPI / cd ../../ git clone https://github.com/yunjey/pytorch-tutorial.git cd pytorch-tutorial / tutorials / 03-advanced / image_captioning / pip install -r requirements.txt
设置好系统后,应下载训练模型所需的数据集。这里我们将使用MS-COCO数据集。要自动下载数据集,可以运行以下命令:
chmod + x download.sh ./download.sh
现在,您可以继续开始模型构建过程。首先 - 您必须处理输入:
#搜索数据集中的所有可能单词 #建立一个词汇表 python build_vocab.py #调整所有图像的大小以使其形状为224x224 python resize.py
现在,您可以通过运行以下命令开始训练模型:
python train.py --num_epochs 10 --learning_rate 0.01
只是为了窥视引擎并查看我们如何定义模型,您可以参考model.py文件中编写的代码 。
class EncoderCNN(nn.Module): def __init __(self,embed_size): msgstr“”“加载预先训练的ResNet-152并替换顶部的fc层。”“ super(EncoderCNN,self).__ init __() resnet = models.resnet152(pretrained = True) modules = list(resnet.children())[: - 1]#删除最后一个fc图层。 self.resnet = nn.Sequential(* modules) self.linear = nn.Linear(resnet.fc.in_features,embed_size) self.bn = nn.BatchNorm1d(embed_size,momentum = 0.01) self.init_weights() def init_weights(self): msgstr“”“初始化权重。”“ self.linear.weight.data.normal_(0.0,0.02) self.linear.bias.data.fill_(0) def(self,figure): msgstr“”“提取图像特征向量。”“ features = self.resnet(图片) features = Variable(features.data) features = features.view(features.size(0), - 1) features = self.bn(self.linear(features)) return class DecoderRNN(nn.Module): def __init __(self,embed_size,hidden_size,vocab_size,num_layers): msgstr“”“设置超参数并构建图层。”“ super(DecoderRNN,self).__ init __() self.embed = nn.Embedding(vocab_size,embed_size) self.lstm = nn.LSTM(embed_size,hidden_size,num_layers,batch_first = True) self.linear = nn.Linear(hidden_size,vocab_size) self.init_weights() def init_weights(self): msgstr“”“初始化重量。”“ self.embed.weight.data.uniform _( - 0.1,0.1) self.linear.weight.data.uniform _( - 0.1,0.1) self.linear.bias.data.fill_(0) 向前(自我,特征,标题,长度): msgstr“”“解码图像特征向量并生成标题。”“ embeddings = self.embed(captions) embeddings = torch.cat((features.unsqueeze(1),embeddings),1) packed = pack_padded_sequence(embeddings,lengths,batch_first = True) hiddens,_ = self.lstm(打包) outputs = self.linear(hiddens [0]) 返回输出 def sample(self,features,states = None): “”给定图像特征的样本标题(贪婪搜索)。“”“ sampled_ids = [] inputs = features.unsqueeze(1) 对于范围内的i(20):#最大采样长度 hiddens,states = self.lstm(输入,状态)#(batch_size,1,hidden_size), outputs = self.linear(hiddens.squeeze(1))#(batch_size,vocab_size) 预测=输出.max(1)[1] sampled_ids.append(预测) inputs = self.embed(预测) inputs = inputs.unsqueeze(1)#(batch_size,1,embed_size) sampled_ids = torch.cat(sampled_ids,1)#(batch_size,20) return sampled_ids.squeeze()
现在我们可以测试我们的模型:
python sample.py --image = ' png / example.png '
对于我们的示例图像,我们的模型为我们提供了此输出

<开始>一群站在草地上的长颈鹿。<END>
这就是你为图像字幕构建深度学习模型的方法!
然后去哪儿?
我们上面看到的模型只是冰山一角。关于这个主题已经做了很多研究。目前,图像字幕中最先进的模型是微软的CaptionBot。您可以在他们的官方网站上查看该系统的演示(链接:www.captionbot.ai)。
我将列出一些您可以用来构建更好的图像字幕模型的想法。
- 添加更多数据 - 当然,这是深度学习模型的通常趋势。您为模型提供的数据越多,表现就越好。您可以将此资源用于其他图像字幕数据集 - - http://www.cs.toronto.edu/~fidler/slides/2017/CSC2539/Kaustav_slides.pdf
- 使用注意模型 - 正如我们在本文中所看到的(深度学习要点 -使用注意的序列到序列建模),使用注意力模型帮助我们微调模型性能。
- 继续研究更大更好的技术 - 研究人员正在研究一些技术 - 例如使用强化学习来构建端到端深度学习系统,或者使用 新颖的视觉哨兵注意模型。
结束说明
在本文中,我介绍了Image Captioning,这是一个多模式任务,它构成了对自然语句中的图像进行解密和描述。然后我解释了解决任务的方法,并详细介绍了它的实现。对于好奇,我还列出了可用于改善模型性能的方法列表。
我希望本文能激励您发现更多可以使用深度学习解决的任务,以便在行业中实现越来越多的突破和创新。如果您有任何建议/反馈,请在下面的评论中告诉我们!