HDFS存储方式:
将用户的文件分块,分散在多台主机上,同时每个块又有多个备份,多个备份不会出现在一台主机上,以确保即使一台主机出现问题,文件的访问依然正常。但是由于用户访问文件用的是一个路径指向一个文件,而具体的文件是被分块的,所以对于文件具体存储和路径之间存在映射关系,这个映射关系由namenode存储。客户通过虚拟的目录结构访问namenode,进而访问datanode得到数据文件。
1. 非HA下,namenode与secondnamenode的备份机制:
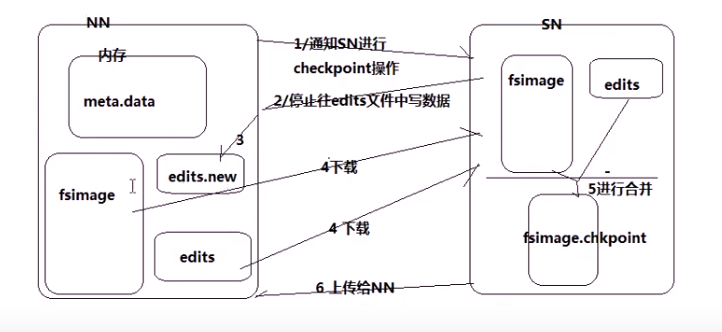
NN与SN之间的备份过程
当某个时刻内存中元数据metadata和fsimage同步时,新数据写入,文件的保存情况先记录日志到一个非常小的(通常64M,可配置)edits文件中,再向内存中的元数据发起更改,但并不向fsimage同步;直到edits快要满了,此时通知secondnamenode进行合并,停止向edits写入日志(如果有新写入,则临时创建为edits.new中),secondnamenode将通过网络从namenode下载fsimage和edits文件到本地合并为fsimage.checkpoint后保存并上传回namenode;最后namenode重命名fsimage.checkpoint为fsimage,将临时的edits.new更名为edits,合并结束。
这种模式下,数据安全性得到保证,但是服务不是可靠的,在修复namenode时,HDFS访问服务不可用。
2. HA下,有两台namenode主机:
分别为active与standby状态,状态竞选由qjournal实现,qjournal靠ZooKeeper实现,journalnode是qjournal的进程,可以跟zookeeper不在一个机器上。
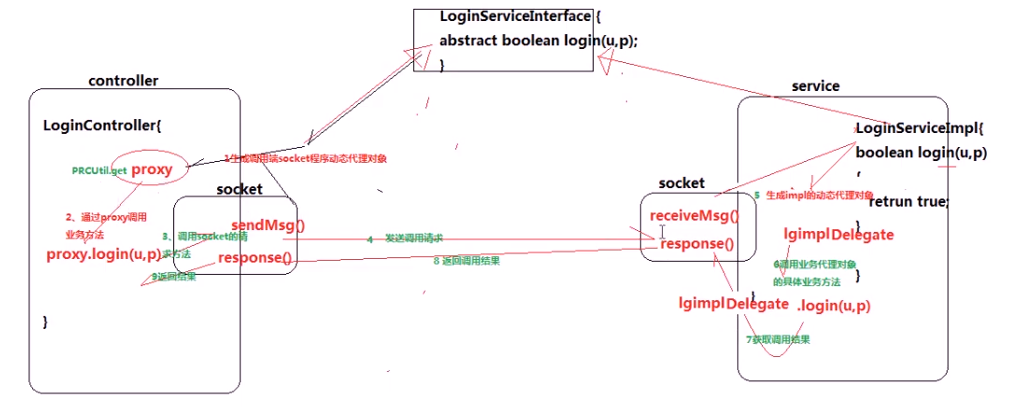
hadoop远程过程调用模型