一、查找:
顺序查找:
哈希表是以一种容易找到它们的方式存储项的集合,哈希表的每个位置,通常称为一个槽,可以容纳一个项,并且由从0开始的整数值命名,例如有名为0的槽,名为1的槽......,最初,哈希表不包含项,因此每个槽为空,我们可以通过一个列表来实现哈希表每个元素初始化为none 。项和该项在散列表中所属的槽之间的映射被称为hash函数。hash函数将接受集合中的任何项,并在槽名范围内(0~m-1之间)返回一个整数
hash函数:
余数法:只需要一个项并将其除以表大小,返回剩余部分作为其散列值(h(item) = item % 11(槽的大小)) 结果必在槽名的范围内
一旦计算了哈希值,我们可以将每个项插入到指定位置的哈希表中
给定项的集合,将每个项映射到唯一槽的散列函数被称为完美散列函数,总是具有完美散列函数的一种方式就是增加散列表的大小,使得可以容纳项范围中的每个可能值
很多扩展简单余数法:
1、分组求和法
2、平方取中法
3、基于字符的项创建哈希函数 如:ord('c') == 99
哈希查找的具体原理在博客:https://blog.csdn.net/weixin_41362649/article/details/81865829
因为通过哈希函数计算计算机的槽名称,然后进行对哈希表进行查找,所以他的复杂度为O(1)
二、排序:
冒泡:
对列表中的像个的两项进行比较,将较大项放在较小项的后面,这样的话,比较n-1次,列表的最后意向是最大的一项,然后对剩下的n-1项进行第二次寻找最大项,然后放到最后,这样的话,如此循环n次,整个列表就会是递增的列表,但是复杂度也可以看到,是O(n2)。
选择:
选择排序是对冒泡的优化,它直接找到列表中的最大项,然后放置到列表的最后一个位置,然后对剩下的n-1项进行第二次寻找最大项,然后放到最后,然后对剩下的n-1项进行第二次寻找最大项,然后放到最后。可以看到选择排序与冒泡排序有相同数量的比较,因此也是 O(n2 )。 然而,由于交换数量的减少,选择排序通常执行得更快。
插入:
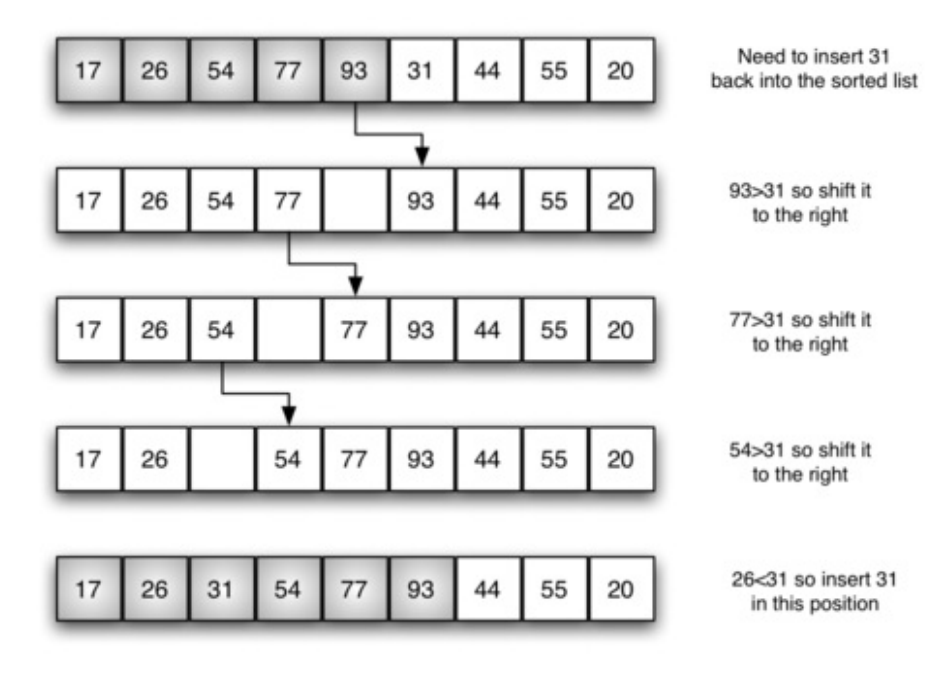
对[17 26 54 77 93]这个已经有序的列表插入31,然后对该子表通过移位来排序,以此循环,插入排序的最大比较次数是 n-1 个整数的总和,同样,是 O(n2)。通常,移位操作只需要交换大约三分之一的处理工作,因为仅执行一次分配,插入排序有非常好的性能。
希尔:
归并:
归并过程为:比较a[i]和b[j]的大小,若a[i]≤b[j],则将第一个有序表中的元素a[i]复制到r[k]中,并令i和k分别加上1;否则将第二个有序表中的元素b[j]复制到r[k]中,并令j和k分别加上1,如此循环下去,直到其中一个有序表取完,然后再将另一个有序表中剩余的元素复制到r中从下标k到下标t的单元。归并排序的算法我们通常用递归实现,先把待排序区间[s,t]以中点二分,接着把左边子区间排序,再把右边子区间排序,最后把左区间和右区间用一次归并操作合并成有序的区间[s,t]。
发现了一个C语言的关于归并的讲解https://www.cnblogs.com/Java3y/p/8631584.html,虽然语言不同,但是数据结构是一样的
快速:
快速排序通过在列表中随机确定一个参照值,进行跨越式比较,快速排序之所比较快,因为相比冒泡排序,每次交换是跳跃式的。每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样每次只能在相邻的数之间进行交换,交换的距离就大的多了。因此总的比较和交换次数就少了,速度自然就提高了。当然在最坏的情况下,仍可能是相邻的两个数进行了交换。因此快速排序的最差时间复杂度和冒泡排序是一样的都是O(N2),它的平均时间复杂度为O(NlogN)。
具体的话,在博客中很详细https://blog.csdn.net/adusts/article/details/80882649