前言
Docker作为最重视安全的容器技术之一,在很多方面都提供了强安全性的默认配置,其中包括:容器root用户的Capability能力限制、Seccomp系统调用过滤、Apparmor的 MAC 访问控制、ulimit限制、pid-limits的支持,镜像签名机制等。这篇文章我们就带大家详细了解一下。
Docker利用Namespace实现了6项隔离,看似完整,实际上依旧没有完全隔离Linux资源,比如/proc 、/sys 、/dev/sd*等目录未完全隔离,SELinux、time、syslog等所有现有Namespace之外的信息都未隔离。 其实Docker在安全性上也做了很多工作,大致包括下面几个方面:
-
1、Linux内核 Capability 能力限制
Docker支持为容器设置Capabilities,指定开放给容器的权限。这样在容器中的root用户比实际的root少很多权限。Docker 在0.6版本以后支持将容器开启超级权限,使容器具有宿主机的root权限。 -
2、镜像签名机制
Docker 1.8版本以后提供了镜像签名机制来验证镜像的来源和完整性,这个功能需要手动开启,这样镜像制作者可以在push镜像前对镜像进行签名,在镜像pull的时候,Docker不会pull验证失败或者没有签名的镜像标签。 -
3、Apparmor的MAC访问控制
Apparmor可以将进程的权限与进程Capabilities能力联系在一起,实现对进程的强制性访问控制(MAC)。在Docker中,我们可以使用Apparmor来限制用户只能执行某些特定命令、限制容器网络、文件读写权限等功能。 -
4、Seccomp系统调用过滤
使用Seccomp可以限制进程能够调用的系统调用(system call)的范围,Docker提供的默认Seccomp配置文件已经禁用了大约44个超过300+的系统调用,满足大多数容器的系统调用诉求。 -
5、User Namespace隔离
Namespace为运行中进程提供了隔离,限制他们对系统资源的访问,而进程没有意识到这些限制,为防止容器内的特权升级攻击的最佳方法是将容器的应用程序配置为作为非特权用户运行,对于其进程必须作为容器中的root用户运行的容器,可以将此用户重新映射到Docker主机上权限较低的用户。映射的用户被分配了一系列UID,这些UID在命名空间内作为从0到65536的普通UID运行,但在主机上没有特权。 -
6、SELinux
SELinux主要提供了强制访问控制(MAC),即不再是仅依据进程的所有者与文件资源的rwx权限来决定有无访问能力。能在攻击者实施了容器突破攻击后增加一层壁垒。Docker提供了对SELinux的支持。 -
7、pid-limits的支持
在说pid-limits前,需要说一下什么是fork炸弹(fork bomb),fork炸弹就是以极快的速度创建大量进程,并以此消耗系统分配予进程的可用空间使进程表饱和,从而使系统无法运行新程序。说起进程数限制,大家可能都知道ulimit的nproc这个配置,nproc是存在坑的,与其他ulimit选项不同的是,nproc是一个以用户为管理单位的设置选项,即他调节的是属于一个用户UID的最大进程数之和。这部分内容下一篇会介绍。Docker从1.10以后,支持为容器指定–pids-limit 限制容器内进程数,使用其可以限制容器内进程数。 -
8、其他内核安全特性工具支持
在容器生态的周围,还有很多工具可以为容器安全性提供支持,比如可以使用Docker bench audit tool(工具地址:https://github.com/docker/docker-bench-security)检查你的Docker运行环境,使用Sysdig Falco(工具地址:https://sysdig.com/opensource/falco/) 来检测容器内是否有异常活动,可以使用GRSEC 和 PAX来加固系统内核等等。
一.Docker安全评估
Docker容器的安全性,很大程度上依赖于Linux系统自身,评估Docker的安全性时,主要考虑以下几个方面:
- Linux内核的命名空间机制提供的容器隔离安全
- Linux控制组机制对容器资源的控制能力安全。
- Linux内核的能力机制所带来的操作权限安全
- Docker程序(特别是服务端)本身的抗攻击性。
- 其他安全增强机制对容器安全性的影响。
下面简单谈谈上面所说的五个方面:
- 命名空间隔离的安全
- 当docker run启动一个容器时,Docker将在后台为容器创建一个独立的命名空间。命名空间提供了最基础也最直接的隔离。
- 与虚拟机方式相比,通过Linux namespace来实现的隔离不是那么彻底。
- 容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。
- 在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,比如:时间。
- 控制组资源控制的安全
- 当docker run启动一个容器时,Docker将在后台为容器创建一个独立的控制组策略集合。
- Linux Cgroups提供了很多有用的特性,确保各容器可以公平地分享主机的内存、CPU、磁盘IO等资源。
- 确保当发生在容器内的资源压力不会影响到本地主机系统和其他
- 容器,它在防止拒绝服务攻击(DDoS)方面必不可少。
- 内核能力机制
- 能力机制(Capability)是Linux内核一个强大的特性,可以提供细粒度的权限访问控制。
- 大部分情况下,容器并不需要“真正的”root权限,容器只需要少数的能力即可。
- 默认情况下,Docker采用“白名单”机制,禁用“必需功能”之外的其他权限。
- Docker服务端防护
- 使用Docker容器的核心是Docker服务端,确保只有可信的用户才能访问到Docker服务。
- 将容器的root用户映射到本地主机上的非root用户,减轻容器和主机之间因权限提升而引起的安全问题。
- 允许Docker 服务端在非root权限下运行,利用安全可靠的子进程来代理执行需要特权权限的操作。这些子进程只允许在特定范围内进行操作。
- 其他安全特性
- 在内核中启用GRSEC和PAX,这将增加更多的编译和运行时的安全检查;并且通过地址随机化机制来避免恶意探测等。启用该特性不需要Docker进行任何配置。
- 使用一些有增强安全特性的容器模板。
- 用户可以自定义更加严格的访问控制机制来定制安全策略。
- 在文件系统挂载到容器内部时,可以通过配置只读模式来避免容器内的应用通过文件系统破坏外部环境,特别是一些系统运行状态相关的目录。
二、容器资源控制
对容器实现资源控制我们使用的时由Linux提供的cgroups机制
简介:
1.什么是cgroups?
Cgroups 是 control groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如:cpu,memory,IO等等)的机制。最初由 google 的工程师提出,后来被整合进 Linux 内核。Cgroups 也是 LXC 为实现虚拟化所使用的资源管理手段,可以说没有cgroups就没有LXC。
2.cgroups可以干什么?
-
限制进程组可以使用的资源数量(Resource limiting )。比如:memory子系统可以为进程组设定一个memory使用上限,一旦进程组使用的内存达到限额再申请内存,就会出发OOM(out of memory)。
-
进程组的优先级控制(Prioritization )。比如:可以使用cpu子系统为某个进程组分配特定cpu share。
-
记录进程组使用的资源数量(Accounting )。比如:可以使用cpuacct子系统记录某个进程组使用的cpu时间
-
进程组隔离(Isolation)。比如:使用ns子系统可以使不同的进程组使用不同的namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。
-
进程组控制(Control)。比如:使用freezer子系统可以将进程组挂起和恢复
容器资源控制(一):内存限制
示例:
- 容器可用内存包括两个部分:物理内存和swap交换分区。
- docker run -it --memory 200M --memory-swap=200M ubuntu
–memory设置内存使用限额
–memory-swap设置swap交换分区限额
详解如下:
1.安装cgroup,可提供cgexec命令
[root@server1 ~]# yum install libcgroup-tools.x86_64 -y
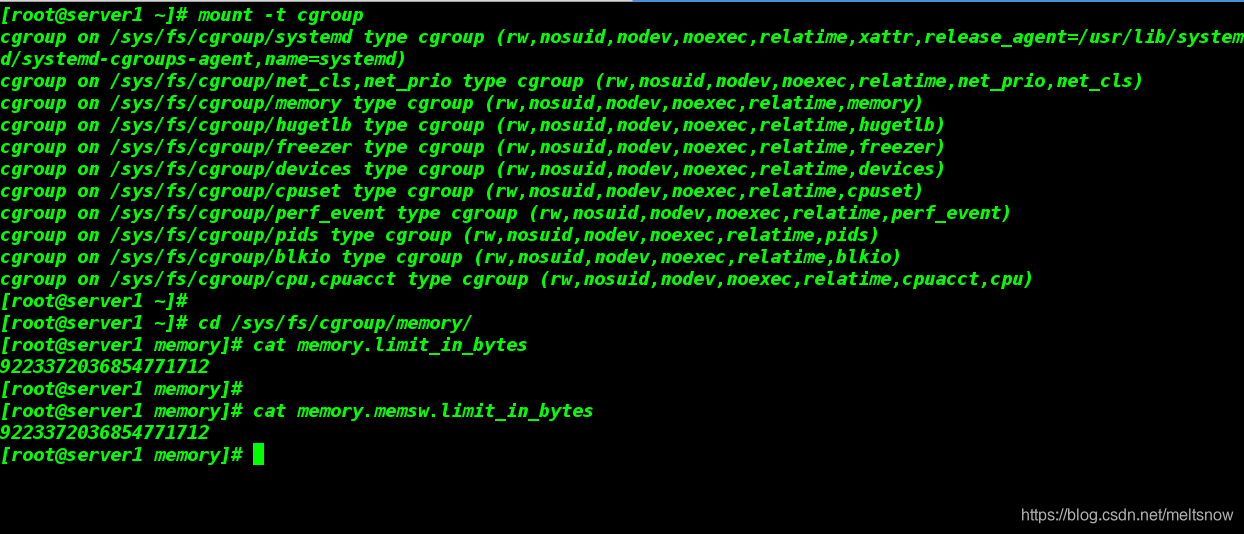
[root@server1 ~]# mount -t cgroup
[root@server1 ~]# cd /sys/fs/cgroup/memory/
[root@server1 memory]# cat memory.limit_in_bytes
9223372036854771712 数字太大,等同于没有做限制
[root@server1 memory]# cat memory.memsw.limit_in_bytes
9223372036854771712
2.设定资源限制参数:内存+交换分区<=200M
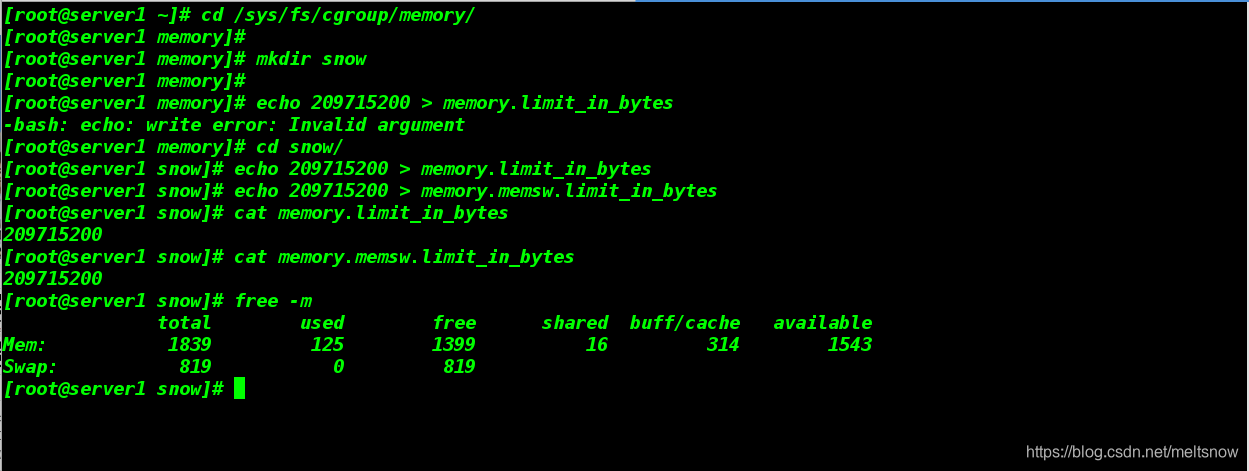
[root@server1 ~]# cd /sys/fs/cgroup/memory/
[root@server1 memory]# mkdir
##snow 创建目录snow,该目录的名字随意给。
##在/sys/fs/cgroup/memory目录中创建的目录,自动继承/sys/fs/cgroup/memory目录中的内容。
创建该目录的目的是(1)为了演示容器的运行过程。因为一旦运行容器,就会在该目录下,生成一个docker目录,
docker目录中会生成容器ID对应的目录,目录中memory目录下的内容继承于/sys/fs/cgroup/memeory目录下的内容。
##(2)直接修改/sys/fs/cgroup/memory中的文件的内容,会报错。
[root@server1 memory]# echo 209715200 > memory.limit_in_bytes
-bash: echo: write error: Invalid argument
[root@server1 memory]# cd snow/
[root@server1 snow]# echo 209715200 > memory.limit_in_bytes
#设定最大占用内存为200M(209715200=200*1024*1024。209715200的单位为BB)
[root@server1 snow]# echo 209715200 > memory.memsw.limit_in_bytes
#因为最大占用内存数和最大占 用swap分区的内存数一样。表明最大可用内存为200M,可用swap为0M。即限制了内存+交换分区<=200M
[root@server1 snow]# cat memory.limit_in_bytes
209715200
[root@server1 snow]# cat memory.memsw.limit_in_bytes
209715200
值的注意的是:/sys/fs/cgroup/memory目录中的文件,不能用vim进行编辑,
利用vim进行编辑,无法进行保存退出(即使使用"wq!",也不能保存退出。)
现在可用内存为1020M
3.测试
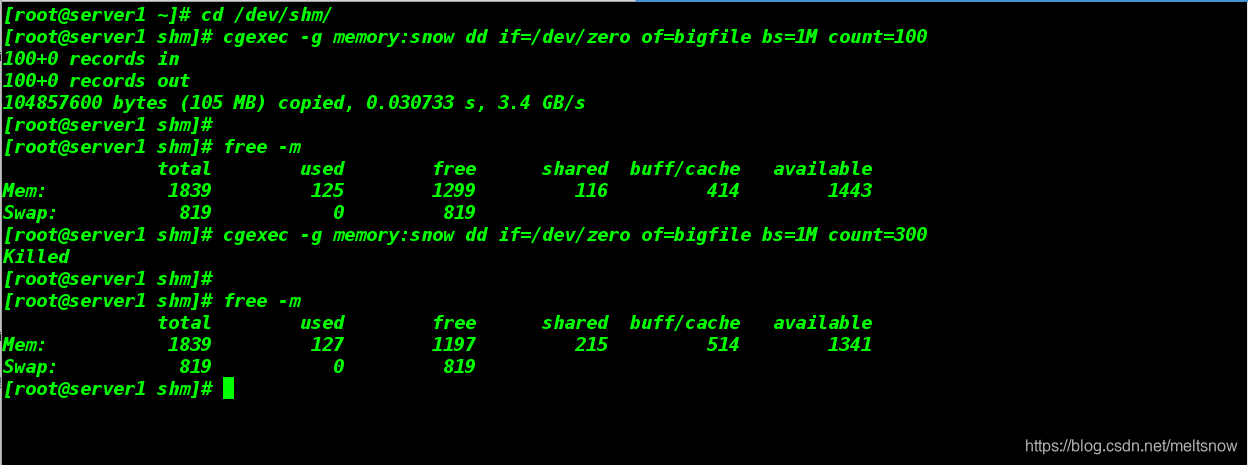
[root@server1 ~]# cd /dev/shm/
[root@server1 shm]# cgexec -g memory:snow dd if=/dev/zero of=bigfile bs=1M count=100
100+0 records in
100+0 records out
104857600 bytes (105 MB) copied, 0.030733 s, 3.4 GB/s
[root@server1 shm]#
[root@server1 shm]# free -m
total used free shared buff/cache available
Mem: 1839 125 1299 116 414 1443
Swap: 819 0 819
##我们发现可用内存少了100M
[root@server1 shm]# cgexec -g memory:snow dd if=/dev/zero of=bigfile bs=1M count=300
Killed
###因为指定的文件的大小为300M超过了限制,所以显示Killed,这就是之前我们为snow目录设置的限制,其最多只能占用200M
[root@server1 shm]#
[root@server1 shm]# free -m
total used free shared buff/cache available
Mem: 1839 127 1197 215 514 1341
Swap: 819 0 819
如果不对内存和swap分区进行限制,即不修改/sys/fs/cgroup/memory/memory.limit_in_bytes和/sys/fs/cgroup/memory/memory.memsw.limit_in_bytes文件中的内容。那么不管要生成的bigfile文件的大小为多少,dd命令永远会成功。
如果只是对内存进行限制(限制为200M),而没有对交换f分区进行限制,即只修改/sys/fs/cgroup/memory/memory.limit_in_bytes文件中的内容,而并没有修改/sys/fs/cgroup/memory/memory.memsw.limit_in_bytes文件中的内容。那么如果要生成的bigfile文件的大小大于200M,dd命令会成功,但是只有200M是取自内存,剩余的取自交换分区。
1.指定内存和交换分区的大小,运行容器
[root@server1 ~]# docker run -it --name vm1 --memory 209715200 --memory-swap 209715200 ubuntu
root@b1d8a47cd003:/# [root@server1 ~]#
##利用ubuntu镜像运行容器vm1,指定内存+交换分区<200M。并使用Ctrl+p+q退出,即不要让容器停掉。
2.查看设置是否生效
[root@server1 ~]# cd /sys/fs/cgroup/memory/docker
[root@server1 docker]# cd b1d8a47cd00354c4ee86ef2e80f12444d15569d3fa83fdff368c1633b783f32b/
[root@server1 b1d8a47cd00354c4ee86ef2e80f12444d15569d3fa83fdff368c1633b783f32b]#
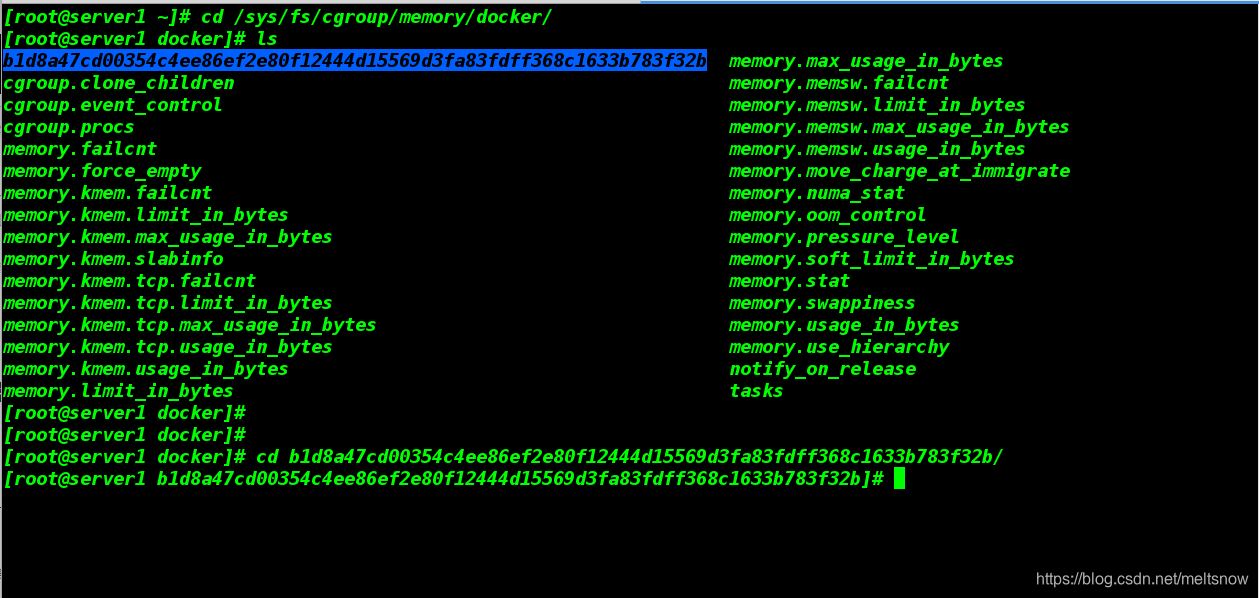
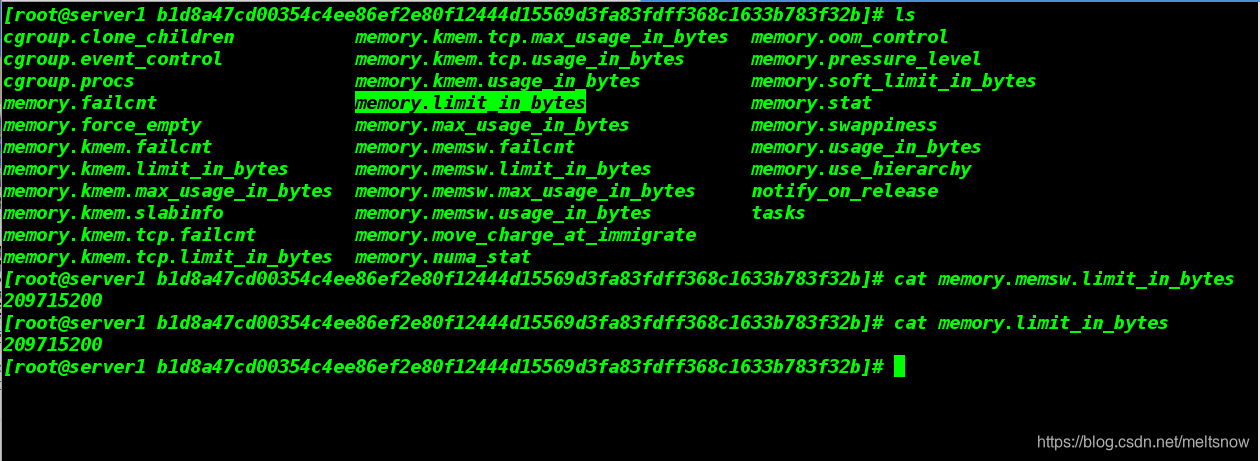
上面的字符串是我们查看到的内存和交换分区大小符合我们设置的大小,我们确认一下容器ID,以确保我们查看的确实是我们运行的容器

值的注意的是:因为容器的隔离性并不是很好,所以在容器内使用命令"free -m"看到的内容与宿主机上使用命令"free -m"看到的内容相同。所以如果要看是否限制成功,需要进入容器对应的目录中进行查看。
容器资源控制(二):CPU限额
1.打开docker并检测cgroup是否开启
都显示【on】即为开启
[root@server1 ~]# systemctl start docker
[root@server1 ~]# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
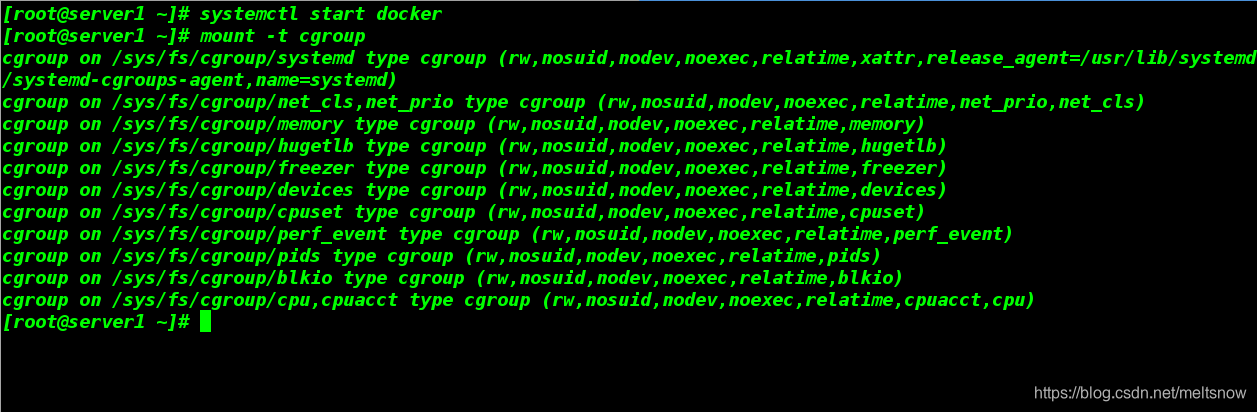
2.查看cgroup子系统的层级路径
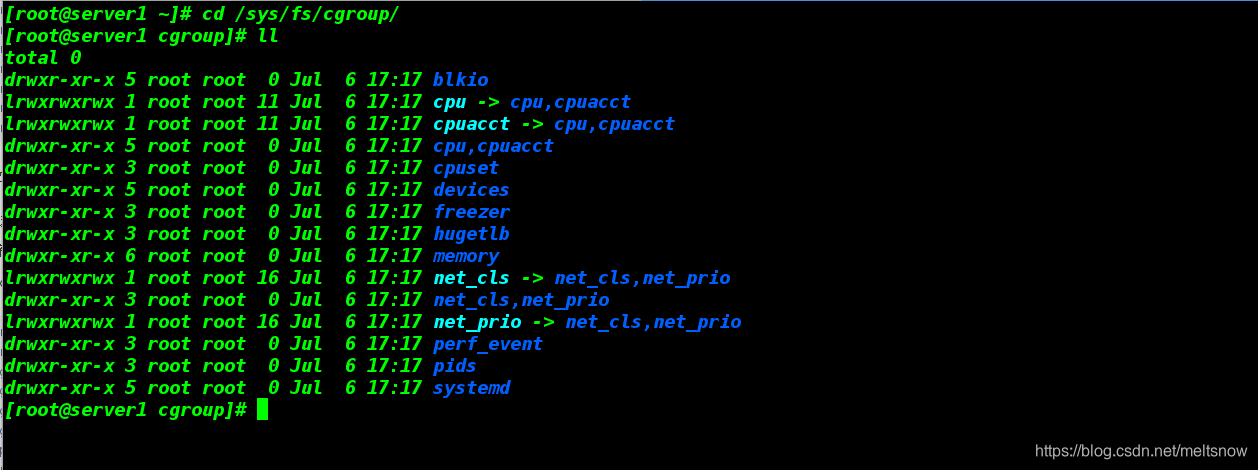
3.建立一个CPU控制族群
- 首先进入cpu子系统对应的层级路径下:cd /sys/fs/cgroup/cpu
- 通过新建文件夹创建一个cpu控制族群:mkdir x1,即新建了一个cpu控制族群:x1
- 新建x1之后,可以看到目录下自动建立了相关的文件,这些文件是伪文件。
[root@server1 cgroup]# pwd
/sys/fs/cgroup
[root@server1 cgroup]# cd cpu
[root@server1 cpu]# ls
cgroup.clone_children cpuacct.stat cpu.cfs_quota_us cpu.stat system.slice
cgroup.event_control cpuacct.usage cpu.rt_period_us docker tasks
cgroup.procs cpuacct.usage_percpu cpu.rt_runtime_us notify_on_release user.slice
cgroup.sane_behavior cpu.cfs_period_us cpu.shares release_agent
[root@server1 cpu]#
[root@server1 cpu]# mkdir x1 ##新建x1目录
[root@server1 cpu]# cd x1/
[root@server1 x1]# ll ##目录里自动生成相关文件
total 0
-rw-r--r-- 1 root root 0 Jul 6 18:14 cgroup.clone_children
--w--w--w- 1 root root 0 Jul 6 18:14 cgroup.event_control
-rw-r--r-- 1 root root 0 Jul 6 18:14 cgroup.procs
-r--r--r-- 1 root root 0 Jul 6 18:14 cpuacct.stat
-rw-r--r-- 1 root root 0 Jul 6 18:14 cpuacct.usage
-r--r--r-- 1 root root 0 Jul 6 18:14 cpuacct.usage_percpu
-rw-r--r-- 1 root root 0 Jul 6 18:14 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 Jul 6 18:14 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 Jul 6 18:14 cpu.rt_period_us
-rw-r--r-- 1 root root 0 Jul 6 18:14 cpu.rt_runtime_us
-rw-r--r-- 1 root root 0 Jul 6 18:14 cpu.shares
-r--r--r-- 1 root root 0 Jul 6 18:14 cpu.stat
-rw-r--r-- 1 root root 0 Jul 6 18:14 notify_on_release
-rw-r--r-- 1 root root 0 Jul 6 18:14 tasks
[root@server1 x1]#
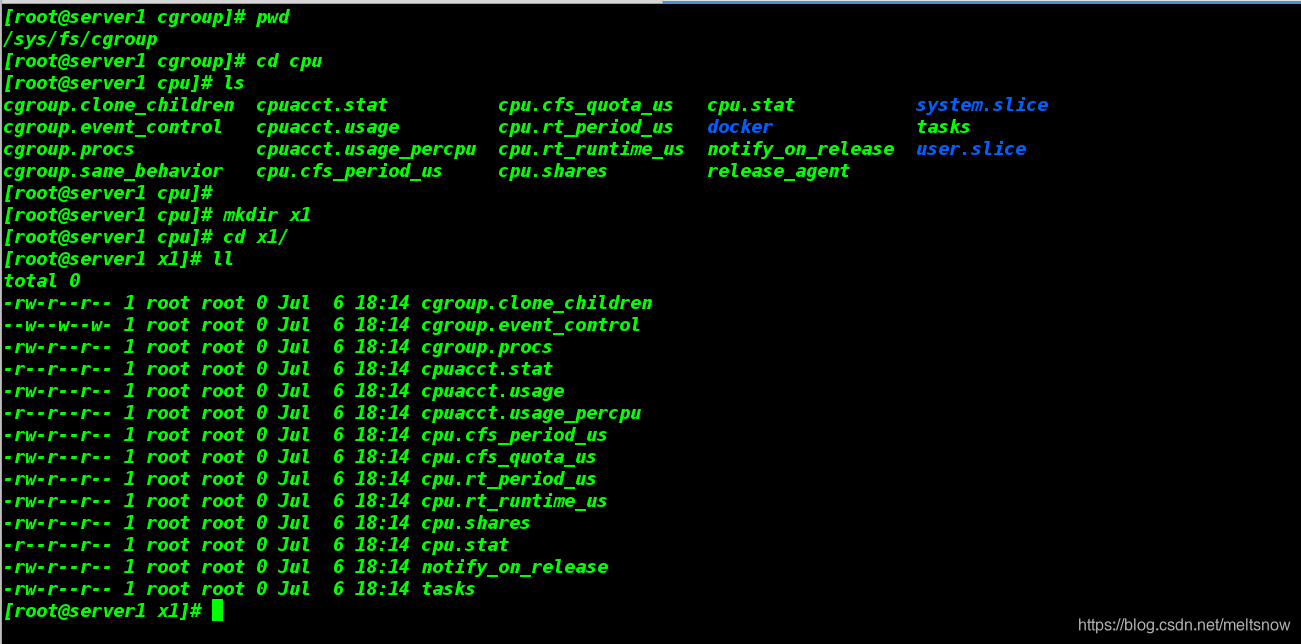
4.测试限制cpu的使用
- 我们的测试示例主要用到cpu.cfs_period_us和cpu.cfs_quota_us两个文件。
- cpu.cfs_period_us:cpu分配的周期(微秒),默认为100000。
- cpu.cfs_quota_us:表示该control group限制占用的时间(微秒),默认为-1,表示不限制。如果设为20000,表示占用20000/100000=20%的CPU。
[root@server1 x1]# cat cpu.cfs_period_us
100000
[root@server1 x1]# cat cpu.cfs_quota_us ##默认为-1,表示不限制
-1
[root@server1 x1]# echo 20000 > cpu.cfs_quota_us ##修改占用时间为20%
[root@server1 x1]# cat cpu.cfs_quota_us
20000

6.测试
[root@server1 x1]# dd if=/dev/zero of=/dev/null & ##开启任务。打入后台,然后使用【top】命令查看
- 查看占用了百分之100
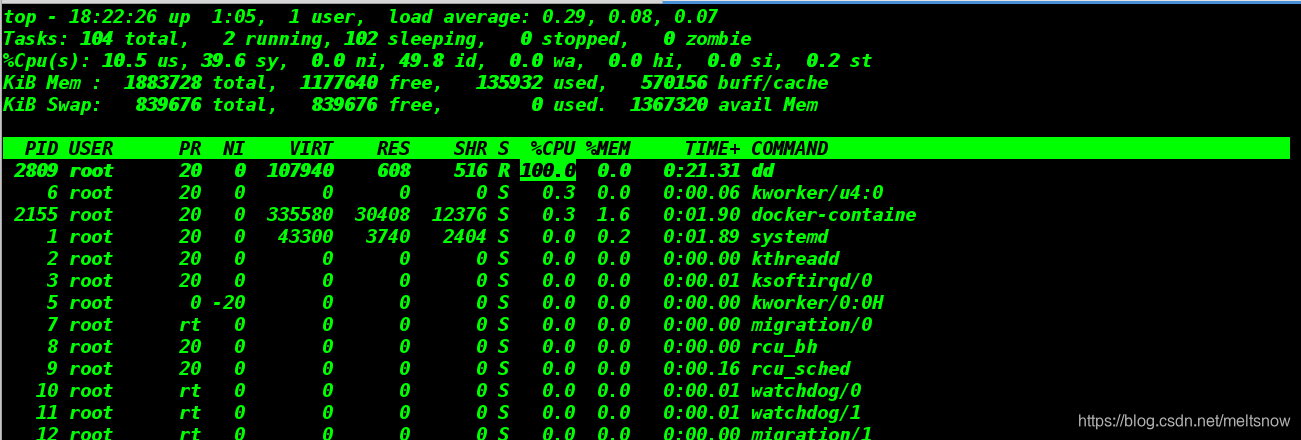
- 按“1”查看,cpu0使用约20%

6.创建一个容器,并限制cpu的使用
[root@server1 x1]# echo 2809 > tasks ##dd命令的进程号
[root@server1 x1]# fg
dd if=/dev/zero of=/dev/null
^C456424541+0 records in
456424541+0 records out
233689364992 bytes (234 GB) copied, 201.225 s, 1.2 GB/s
[root@server1 ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@server1 x1]# docker run -it --name vm1 --cpu-quota=20000 ubuntu
root@9431d483af1e:/# dd if=/dev/zero of=/dev/null

再开一个shell查看 top > cpu 使用率20%
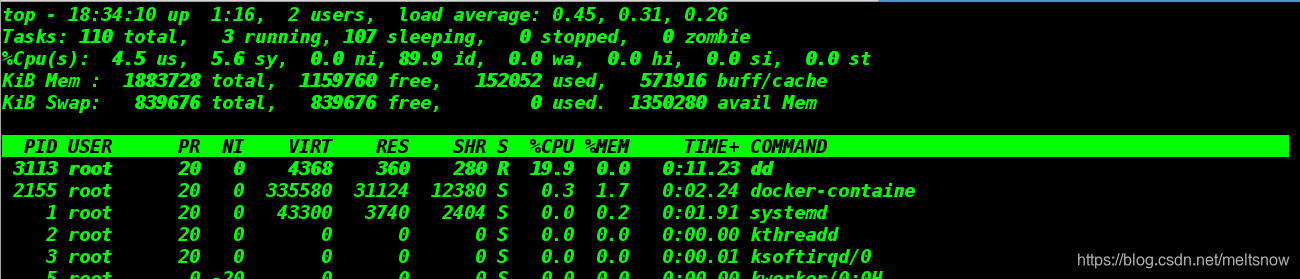
假如在创建容器时不做限制,那么占用率会达到100%
[root@server1 ~]# docker rm -f vm1
vm1
[root@server1 ~]#
[root@server1 ~]# docker run -it --name vm1 ubuntu
root@cc62dd927ede:/# dd if=/dev/zero of=/dev/null


容器资源控制(三):Block IO限制(限制写入速度)
示例:
docker run -it --device-write-bps /dev/sda:30MB ubuntu
–device-write-bps限制写设备的bps
目前的block IO限制只对direct IO有效。(不使用文件缓存)
1.首先可以查看一下分区,确定写入的位置
[root@server1 ~]# docker run -it --rm --privileged=true ubuntu ##--rm参数指容器退出后,自动删除容器
root@d3bc318587e7:/# fdisk -l
Disk /dev/sda: 8589 MB, 8589934592 bytes
255 heads, 63 sectors/track, 1044 cylinders, total 16777216 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x000a8154
Device Boot Start End Blocks Id System
/dev/sda1 * 2048 2099199 1048576 83 Linux
/dev/sda2 2099200 16777215 7339008 8e Linux LVM
root@d3bc318587e7:/#
2.新建容器,进行测试
[root@server1 ~]# docker run -it --rm --device-write-bps /dev/sda:30M ubuntu ##写入速度为每秒30M
root@d3f749bb200d:/# dd if=/dev/zero of=file bs=1M count=300 oflag=direct
300+0 records in
300+0 records out
314572800 bytes (315 MB) copied, 9.91935 s, 31.7 MB/s ##用时约10秒
root@d3f749bb200d:/# dd if=/dev/zero of=file bs=1M count=300
300+0 records in
300+0 records out
314572800 bytes (315 MB) copied, 0.130683 s, 2.4 GB/s ##用时不到一秒
root@d3f749bb200d:/#
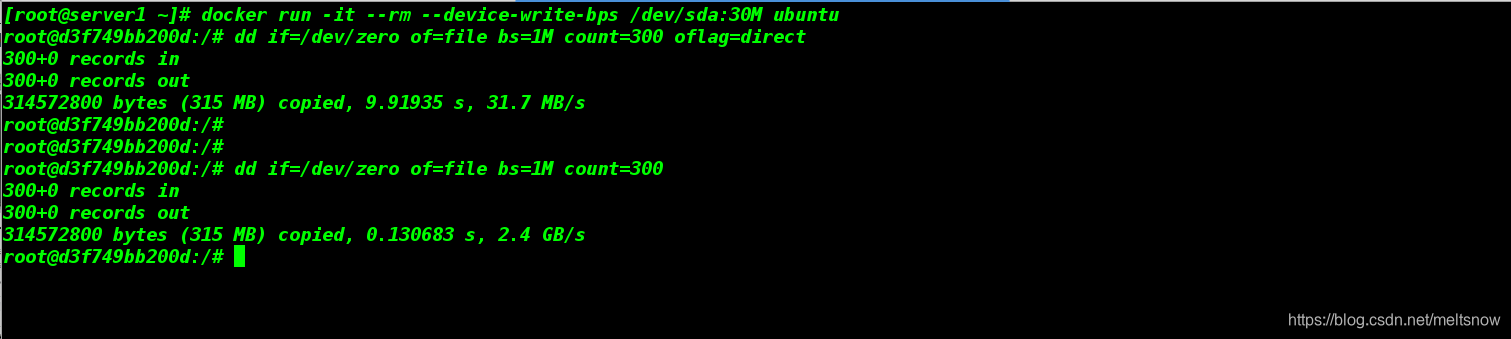
由上图可见,我们对容器IO限制奏效,至于在演示操作中,为什么第二次的写入速度如此之快,这取决于参数【oflag=direct】。它的意思是指:读写数据采用直接IO方式。