MNIST分类
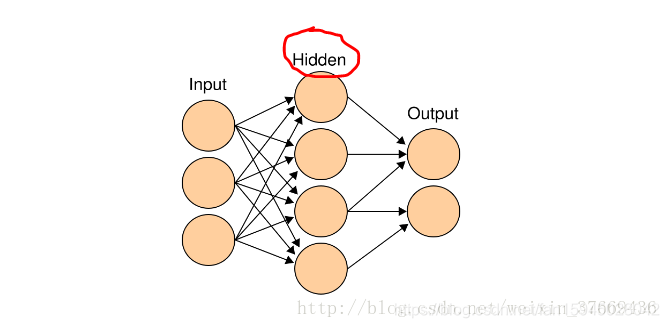
作为数据挖掘工作中处理的最多的任务,分类任务占据了机器学习的大半江山,而一个网络结构设计良好(即隐层层数和每个隐层神经元个数选择恰当)的多层感知机在分类任务上也有着非常优越的性能,依然以MNIST手写数字数据集作为演示,上一篇中我们利用一层输入层+softmax搭建的分类器在MNIST数据集的测试集上达到93%的精度,下面我们使用加上一层隐层的网络,以及一些tricks来看看能够提升多少精度
from tensorflow.examples.tutorials.mnist import input_data
载入tensorflow
import tensorflow as tf
mnist = input_data.read_data_sets(“MNIST_data/”,one_hot = True)
将session注册为默认session
sess = tf.InteractiveSession()
输入节点数
in_units = 784
隐含层节点数
h1_units = 300
variable存储模型参数
Variable长期存在并且每轮更新
隐含层初始化为截断的正态分布,标准差为0.1
w1 = tf.Variable(tf.truncated_normal([in_units,h1_units],stddev = 0.1))
隐含层偏置用0初始化
b1 = tf.Variable(tf.zeros([h1_units]))
输出层用0初始化,且维数为10
w2 = tf.Variable(tf.zeros([h1_units,10]))
b2 = tf.Variable(tf.zeros([10]))
placeholder定义输入数据的地方
数据类型;[个数,数据维数],none表示不限
x = tf.placeholder(tf.float32,[None,in_units])
dropout保留节点比率
dropout是防止过拟合的trick
keep_prob = tf.placeholder(tf.float32)
隐含层结构
relu激活函数是梯度弥散的trick
hidden1 = tf.nn.relu(tf.matmul(x,w1)+b1)
对隐含层输出进行dropout
hidden1_drop = tf.nn.dropout(hidden1,keep_prob)
输出层结构
y = tf.nn.softmax(tf.matmul(hidden1_drop,w2)+b2)
y_存储真实label
y_ = tf.placeholder(tf.float32,[None,10])
定义损失函数
reduce_sum求和,reduce_mean对每一个batch数据求均值
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y),reduction_indices = [1]))
只要定义好优化目标(损失函数)和优化算法,tensorflow就会自动求导进行反向传播
train_step = tf.train.AdagradOptimizer(0.3).minimize(cross_entropy)
全局参数初始化器
tf.global_variables_initializer().run()
前面只是定义了优化目标和优化算法,batch里必须feed数据才能进行训练
定义迭代次数和batch数据
for i in range(3000):
batch_xs,batch_ys = mnist.train.next_batch(100)
train_step.run({x:batch_xs,y_:batch_ys,keep_prob:0.75})
#测试
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
print accuracy.eval({x:mnist.test.images,y_:mnist.test.labels,keep_prob:1.0})