简介
Apache Hadoop 2.0 包含 YARN,它将资源管理和处理组件分开。基于 YARN 的架构不受 MapReduce 约束。本文将介绍 YARN,以及它相对于 Hadoop 中以前的分布式处理层的一些优势。本文将了解如何使用 YARN 的可伸缩性、效率和灵活性增强您的集群。
Apache Hadoop 简介
Apache Hadoop 是一个开源软件框架,可安装在一个商用机器集群中,使机器可彼此通信并协同工作,以高度分布式的方式共同存储和处理大量数据。最初,Hadoop 包含以下两个主要组件:Hadoop Distributed File System (HDFS) 和一个分布式计算引擎,该引擎支持以 MapReduce 作业的形式实现和运行程序。
MapReduce 是 Google 推广的一个简单的编程模型,它对以高度并行和可扩展的方式处理大数据集很有用。MapReduce 的灵感来源于函数式编程,用户可将他们的计算表达为 map 和 reduce 函数,将数据作为键值对来处理。Hadoop 提供了一个高级 API 来在各种语言中实现自定义的 map 和 reduce 函数。
Hadoop 还提供了软件基础架构,以一系列 map 和 reduce 任务的形式运行 MapReduce 作业。Map 任务 在输入数据的子集上调用 map 函数。在完成这些调用后,reduce 任务 开始在 map 函数所生成的中间数据上调用 reduce 任务,生成最终的输出。 map 和 reduce 任务彼此单独运行,这支持并行和容错的计算。
最重要的是,Hadoop 基础架构负责处理分布式处理的所有复杂方面:并行化、调度、资源管理、机器间通信、软件和硬件故障处理,等等。得益于这种干净的抽象,实现处理数百(或者甚至数千)个机器上的数 TB 数据的分布式应用程序从未像现在这么容易过,甚至对于之前没有使用分布式系统的经验的开发人员也是如此。
Hadoop 的黄金时代
尽管 MapReduce 模型存在着多种开源实现,但 Hadoop MapReduce 很快就变得非常流行。Hadoop 也是全球最令人兴奋的开源项目之一,它提供了多项出色的功能:高级 API、近线性的可伸缩性、开源许可、在商用硬件上运行的能力,以及容错。它已获得数百(或许已达数千)个公司的成功部署,是大规模分布式存储和处理的最新标准。
一些早期的 Hadoop 采用者,比如 Yahoo! 和 Facebook,构建了包含 4,000 个节点的大型集群,以满足不断增长和变化的数据处理需求。但是,在构建自己的集群后,他们开始注意到了 Hadoop MapReduce 框架的一些局限性。
经典 MapReduce 的局限性
经典 MapReduce 的最严重的限制主要关系到可伸缩性、资源利用和对与 MapReduce 不同的工作负载的支持。在 MapReduce 框架中,作业执行受两种类型的进程控制:
- 一个称为 JobTracker 的主要进程,它协调在集群上运行的所有作业,分配要在 TaskTracker 上运行的 map 和 reduce 任务。
- 许多称为 TaskTracker 的下级进程,它们运行分配的任务并定期向 JobTracker 报告进度。
Apache Hadoop 的经典版本 (MRv1)

大型的 Hadoop 集群显现出了由单个 JobTracker 导致的可伸缩性瓶颈。依据 Yahoo!,在集群中有 5,000 个节点和 40,000 个任务同时运行时,这样一种设计实际上就会受到限制。由于此限制,必须创建和维护更小的、功能更差的集群。
此外,较小和较大的 Hadoop 集群都从未最高效地使用他们的计算资源。在 Hadoop MapReduce 中,每个从属节点上的计算资源由集群管理员分解为固定数量的 map 和 reduce slot,这些 slot 不可替代。设定 map slot 和 reduce slot 的数量后,节点在任何时刻都不能运行比 map slot 更多的 map 任务,即使没有 reduce 任务在运行。这影响了集群的利用率,因为在所有 map slot 都被使用(而且我们还需要更多)时,我们无法使用任何 reduce slot,即使它们可用,反之亦然。
最后但同样重要的是,Hadoop 设计为仅运行 MapReduce 作业。随着替代性的编程模型(比如 Apache Giraph 所提供的图形处理)的到来,除 MapReduce 外,越来越需要为可通过高效的、公平的方式在同一个集群上运行并共享资源的其他编程模型提供支持。
2010 年,Yahoo! 的工程师开始研究一种全新的 Hadoop 架构,用这种架构来解决上述所有限制并增加多种附加功能。
解决可伸缩性问题
在 Hadoop MapReduce 中,JobTracker 具有两种不同的职责:
- 管理集群中的计算资源,这涉及到维护活动节点列表、可用和占用的 map 和 reduce slots 列表,以及依据所选的调度策略将可用 slots 分配给合适的作业和任务
- 协调在集群上运行的所有任务,这涉及到指导 TaskTracker 启动 map 和 reduce 任务,监视任务的执行,重新启动失败的任务,推测性地运行缓慢的任务,计算作业计数器值的总和,等等
为单个进程安排大量职责会导致重大的可伸缩性问题,尤其是在较大的集群上,JobTracker 必须不断跟踪数千个 TaskTracker、数百个作业,以及数万个 map 和 reduce 任务。下图演示了这一问题。相反,TaskTracker 通常近运行十来个任务,这些任务由勤勉的 JobTracker 分配给它们。
大型 Apache Hadoop 集群 (MRv1) 上繁忙的 JobTracker
![]()
为了解决可伸缩性问题,一个简单而又绝妙的想法应运而生:我们减少了单个 JobTracker 的职责,将部分职责委派给 TaskTracker,因为集群中有许多 TaskTracker。在新设计中,这个概念通过将 JobTracker 的双重职责(集群资源管理和任务协调)分开为两种不同类型的进程来反映。
不再拥有单个 JobTracker,一种新方法引入了一个集群管理器,它惟一的职责就是跟踪集群中的活动节点和可用资源,并将它们分配给任务。对于提交给集群的每个作业,会启动一个专用的、短暂的 JobTracker 来控制该作业中的任务的执行。有趣的是,短暂的 JobTracker 由在从属节点上运行的 TaskTracker 启动。因此,作业的生命周期的协调工作分散在集群中所有可用的机器上。得益于这种行为,更多工作可并行运行,可伸缩性得到了显著提高。
YARN:下一代 Hadoop 计算平台
我们现在稍微改变一下用辞。以下名称的改动有助于更好地了解 YARN 的设计:
- ResourceManager 代替集群管理器
- ApplicationMaster 代替一个专用且短暂的 JobTracker
- NodeManager 代替 TaskTracker
- 一个分布式应用程序代替一个 MapReduce 作业
YARN 是下一代 Hadoop 计算平台,如下所示。
YARN 的架构

在 YARN 架构中,一个全局 ResourceManager 以主要后台进程的形式运行,它通常在专用机器上运行,在各种竞争的应用程序之间仲裁可用的集群资源。ResourceManager 会追踪集群中有多少可用的活动节点和资源,协调用户提交的哪些应用程序应该在何时获取这些资源。ResourceManager 是惟一拥有此信息的进程,所以它可通过某种共享的、安全的、多租户的方式制定分配(或者调度)决策(例如,依据应用程序优先级、队列容量、ACLs、数据位置等)。
在用户提交一个应用程序时,一个称为 ApplicationMaster 的轻量型进程实例会启动来协调应用程序内的所有任务的执行。这包括监视任务,重新启动失败的任务,推测性地运行缓慢的任务,以及计算应用程序计数器值的总和。这些职责以前分配给所有作业的单个 JobTracker。ApplicationMaster 和属于它的应用程序的任务,在受 NodeManager 控制的资源容器中运行。
NodeManager 是 TaskTracker 的一种更加普通和高效的版本。没有固定数量的 map 和 reduce slots,NodeManager 拥有许多动态创建的资源容器。容器的大小取决于它所包含的资源量,比如内存、CPU、磁盘和网络 IO。目前,仅支持内存和 CPU (YARN-3)。未来可使用 cgroups 来控制磁盘和网络 IO。一个节点上的容器数量,由配置参数与专用于从属后台进程和操作系统的资源以外的节点资源总量(比如总 CPU 数和总内存)共同决定。
有趣的是,ApplicationMaster 可在容器内运行任何类型的任务。例如,MapReduce ApplicationMaster 请求一个容器来启动 map 或 reduce 任务,而 Giraph ApplicationMaster 请求一个容器来运行 Giraph 任务。您还可以实现一个自定义的 ApplicationMaster 来运行特定的任务,进而发明出一种全新的分布式应用程序框架,改变大数据世界的格局。您可以查阅 Apache Twill,它旨在简化 YARN 之上的分布式应用程序的编写。
在 YARN 中,MapReduce 降级为一个分布式应用程序的一个角色(但仍是一个非常流行且有用的角色),现在称为 MRv2。MRv2 是经典 MapReduce 引擎(现在称为 MRv1)的重现,运行在 YARN 之上。
一个可运行任何分布式应用程序的集群
ResourceManager、NodeManager 和容器都不关心应用程序或任务的类型。所有特定于应用程序框架的代码都转移到它的 ApplicationMaster,以便任何分布式框架都可以受 YARN 支持 — 只要有人为它实现了相应的 ApplicationMaster。
得益于这个一般性的方法,Hadoop YARN 集群运行许多不同工作负载的梦想才得以实现。想像一下:您数据中心中的一个 Hadoop 集群可运行 MapReduce、Giraph、Storm、Spark、Tez/Impala、MPI 等。
单一集群方法明显提供了大量优势,其中包括:
- 更高的集群利用率,一个框架未使用的资源可由另一个框架使用
- 更低的操作成本,因为只有一个 “包办一切的” 集群需要管理和调节
- 更少的数据移动,无需在 Hadoop YARN 与在不同机器集群上运行的系统之间移动数据
管理单个集群还会得到一个更环保的数据处理解决方案。使用的数据中心空间更少,浪费的硅片更少,使用的电源更少,排放的碳更少,这只是因为我们在更小但更高效的 Hadoop 集群上运行同样的计算。
YARN 中的应用程序提交
本节讨论在应用程序提交到 YARN 集群时,ResourceManager、ApplicationMaster、NodeManagers 和容器如何相互交互。下图显示了一个例子。
YARN 中的应用程序提交

假设用户采用与 MRv1 中相同的方式键入 hadoop jar 命令,将应用程序提交到 ResourceManager。ResourceManager 维护在集群上运行的应用程序列表,以及每个活动的 NodeManager 上的可用资源列表。ResourceManager 需要确定哪个应用程序接下来应该获得一部分集群资源。该决策受到许多限制,比如队列容量、ACL 和公平性。ResourceManager 使用一个可插拔的 Scheduler。Scheduler 仅执行调度;它管理谁在何时获取集群资源(以容器的形式),但不会对应用程序内的任务执行任何监视,所以它不会尝试重新启动失败的任务。
在 ResourceManager 接受一个新应用程序提交时,Scheduler 制定的第一个决策是选择将用来运行 ApplicationMaster 的容器。在 ApplicationMaster 启动后,它将负责此应用程序的整个生命周期。首先也是最重要的是,它将资源请求发送到 ResourceManager,请求运行应用程序的任务所需的容器。资源请求是对一些容器的请求,用以满足一些资源需求,比如:
- 一定量的资源,目前使用 MB 内存和 CPU 份额来表示
- 一个首选的位置,由主机名、机架名称指定,或者使用 * 来表示没有偏好
- 此应用程序中的一个优先级,而不是跨多个应用程序
如果可能的话,ResourceManager 会分配一个满足 ApplicationMaster 在资源请求中所请求的需求的容器(表达为容器 ID 和主机名)。该容器允许应用程序使用特定主机上给定的资源量。分配一个容器后,ApplicationMaster 会要求 NodeManager(管理分配容器的主机)使用这些资源来启动一个特定于应用程序的任务。此任务可以是在任何框架中编写的任何进程(比如一个 MapReduce 任务或一个 Giraph 任务)。NodeManager 不会监视任务;它仅监视容器中的资源使用情况,举例而言,如果一个容器消耗的内存比最初分配的更多,它会结束该容器。
ApplicationMaster 会竭尽全力协调容器,启动所有需要的任务来完成它的应用程序。它还监视应用程序及其任务的进度,在新请求的容器中重新启动失败的任务,以及向提交应用程序的客户端报告进度。应用程序完成后,ApplicationMaster 会关闭自己并释放自己的容器。
尽管 ResourceManager 不会对应用程序内的任务执行任何监视,但它会检查 ApplicationMaster 的健康状况。如果 ApplicationMaster 失败,ResourceManager 可在一个新容器中重新启动它。您可以认为 ResourceManager 负责管理 ApplicationMaster,而 ApplicationMasters 负责管理任务。
有趣的事实和特性
YARN 提供了多种其他的优秀特性。介绍所有这些特性不属于本文的范畴,我仅列出一些值得注意的特性:
- 如果作业足够小,Uberization 支持在 ApplicationMaster 的 JVM 中运行一个 MapReduce 作业的所有任务。这样,您就可避免从 ResourceManager 请求容器以及要求 NodeManagers 启动(可能很小的)任务的开销。
- 与为 MRv1 编写的 MapReduce 作业的二进制或源代码兼容性 (MAPREDUCE-5108)。
- 针对 ResourceManager 的高可用性 (YARN-149)。此工作正在进行中,已由一些供应商完成。
- 重新启动 ResourceManager 后的应用程序恢复 (YARN-128)。ResourceManager 将正在运行的应用程序和已完成的任务的信息存储在 HDFS 中。如果 ResourceManager 重新启动,它会重新创建应用程序的状态,仅重新运行不完整的任务。此工作已接近完成,社区正在积极测试。它已由一些供应商完成。
- 简化的用户日志管理和访问。应用程序生成的日志不会留在各个从属节点上(像 MRv1 一样),而转移到一个中央存储区,比如 HDFS。在以后,它们可用于调试用途,或者用于历史分析来发现性能问题。
- Web 界面的新外观。
结束语
YARN 是一个完全重写的 Hadoop 集群架构。它似乎在商用机器集群上实现和执行分布式应用程序的方式上带来了变革。
与第一版 Hadoop 中经典的 MapReduce 引擎相比,YARN 在可伸缩性、效率和灵活性上提供了明显的优势。小型和大型 Hadoop 集群都从 YARN 中受益匪浅。对于最终用户(开发人员,而不是管理员),这些更改几乎是不可见的,因为可以使用相同的 MapReduce API 和 CLI 运行未经修改的 MapReduce 作业。
没有理由不将 MRv1 迁移到 YARN。最大型的 Hadoop 供应商都同意这一点,而且为 Hadoop YARN 的运行提供了广泛的支持。如今,YARN 已被许多公司成功应用在生产中,比如 Yahoo!、eBay、Spotify、Xing、Allegro 等。
=====================================
YARN Commands
Overview
YARN commands are invoked by the bin/yarn script. Running the yarn script without any arguments prints the description for all commands.
Usage: yarn [--config confdir] COMMAND [--loglevel loglevel] [GENERIC_OPTIONS] [COMMAND_OPTIONS]
YARN has an option parsing framework that employs parsing generic options as well as running classes.
| COMMAND_OPTIONS | Description |
|---|---|
| --config confdir | Overwrites the default Configuration directory. Default is ${HADOOP_PREFIX}/conf. |
| --loglevel loglevel | Overwrites the log level. Valid log levels are FATAL, ERROR, WARN, INFO, DEBUG, and TRACE. Default is INFO. |
| GENERIC_OPTIONS | The common set of options supported by multiple commands. See the Hadoop Commands Manual for more information. |
| COMMAND COMMAND_OPTIONS | Various commands with their options are described in the following sections. The commands have been grouped into User Commands and Administration Commands. |
User Commands
Commands useful for users of a Hadoop cluster.
application
Usage: yarn application [options]
| COMMAND_OPTIONS | Description |
|---|---|
| -appStates <States> | Works with -list to filter applications based on input comma-separated list of application states. The valid application state can be one of the following: ALL, NEW, NEW_SAVING, SUBMITTED, ACCEPTED, RUNNING, FINISHED, FAILED, KILLED |
| -appTypes <Types> | Works with -list to filter applications based on input comma-separated list of application types. |
| -list | Lists applications from the RM. Supports optional use of -appTypes to filter applications based on application type, and -appStates to filter applications based on application state. |
| -kill <ApplicationId> | Kills the application. |
| -status <ApplicationId> | Prints the status of the application. |
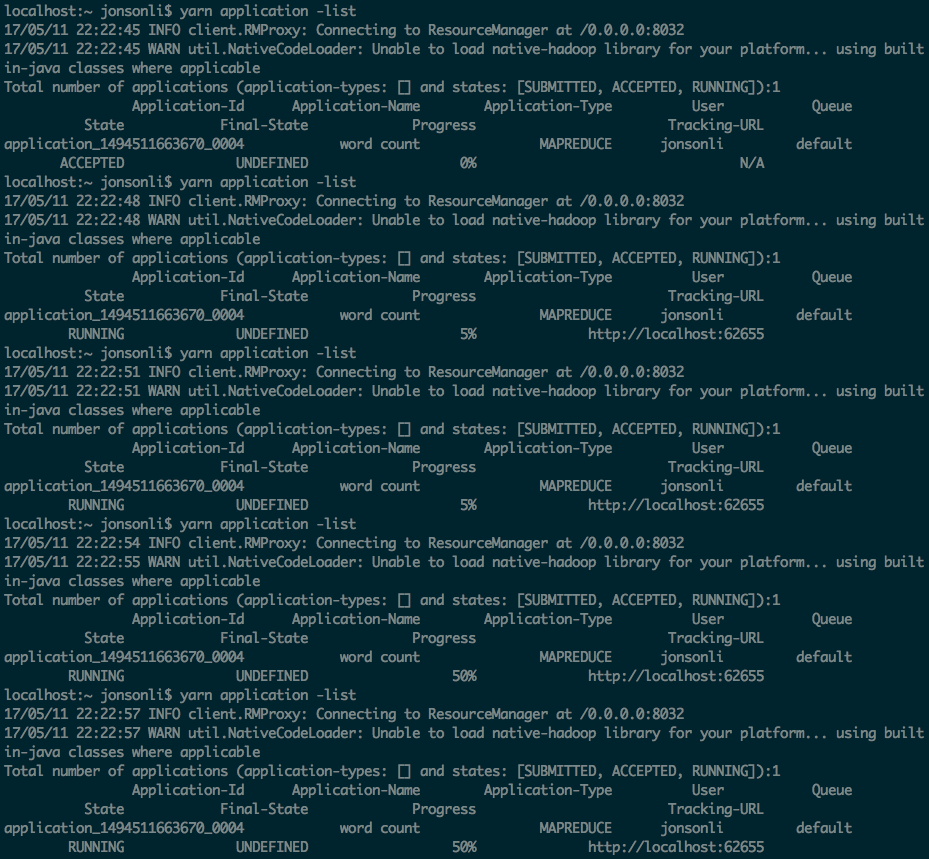
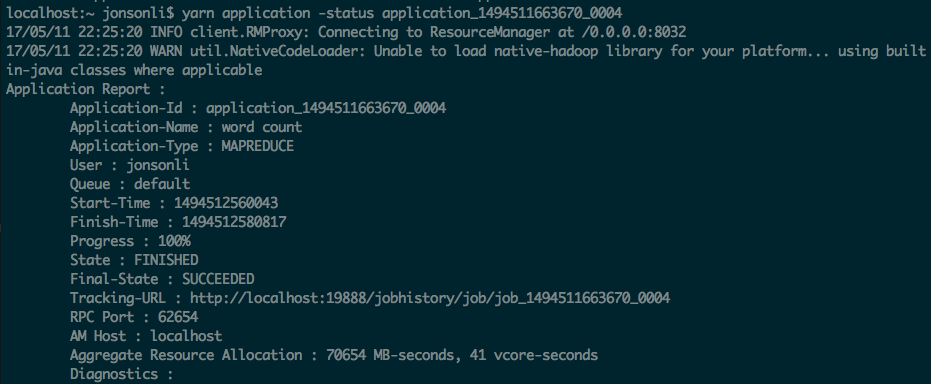
Prints application(s) report/kill application
yarn application -list
yarn application -status application_1494511663670_0004
applicationattempt
Usage: yarn applicationattempt [options]
| COMMAND_OPTIONS | Description |
|---|---|
| -help | Help |
| -list <ApplicationId> | Lists applications attempts for the given application. |
| -status <Application Attempt Id> | Prints the status of the application attempt. |
prints applicationattempt(s) report
localhost:~ jonsonli$ yarn applicationattempt -list application_1494511663670_0004
17/05/11 22:26:33 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/05/11 22:26:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Total number of application attempts :1
ApplicationAttempt-Id State AM-Container-Id Tracking-URL
appattempt_1494511663670_0004_000001 FINISHED container_1494511663670_0004_01_000001 http://localhost:8088/proxy/application_1494511663670_0004/

classpath
Usage: yarn classpath
Prints the class path needed to get the Hadoop jar and the required libraries
container
Usage: yarn container [options]
| COMMAND_OPTIONS | Description |
|---|---|
| -help | Help |
| -list <Application Attempt Id> | Lists containers for the application attempt. |
| -status <ContainerId> | Prints the status of the container. |
prints container(s) report
jar
Usage: yarn jar <jar> [mainClass] args...
Runs a jar file. Users can bundle their YARN code in a jar file and execute it using this command.
logs
Usage: yarn logs -applicationId <application ID> [options]
| COMMAND_OPTIONS | Description |
|---|---|
| -applicationId <application ID> | Specifies an application id |
| -appOwner <AppOwner> | AppOwner (assumed to be current user if not specified) |
| -containerId <ContainerId> | ContainerId (must be specified if node address is specified) |
| -help | Help |
| -nodeAddress <NodeAddress> | NodeAddress in the format nodename:port (must be specified if container id is specified) |
Dump the container logs
localhost:~ jonsonli$ yarn logs -applicationId application_1494511663670_0004
17/05/11 22:28:17 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/05/11 22:28:17 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Container: container_1494511663670_0004_01_000004 on localhost_62244
======================================================================
LogType:stderr
Log Upload Time:星期四 五月 11 22:23:08 +0800 2017
LogLength:0
Log Contents:
End of LogType:stderr
LogType:stdout
Log Upload Time:星期四 五月 11 22:23:08 +0800 2017
LogLength:0
Log Contents:
End of LogType:stdout
LogType:syslog
Log Upload Time:星期四 五月 11 22:23:08 +0800 2017
LogLength:3093
Log Contents:
2017-05-11 22:22:58,224 WARN [main] org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2017-05-11 22:22:58,303 INFO [main] org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2017-05-11 22:22:58,377 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s).
2017-05-11 22:22:58,377 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system started
2017-05-11 22:22:58,390 INFO [main] org.apache.hadoop.mapred.YarnChild: Executing with tokens:
2017-05-11 22:22:58,390 INFO [main] org.apache.hadoop.mapred.YarnChild: Kind: mapreduce.job, Service: job_1494511663670_0004, Ident: (org.apache.hadoop.mapreduce.security.token.JobTokenIdentifier@27462a88)
2017-05-11 22:22:58,581 INFO [main] org.apache.hadoop.mapred.YarnChild: Sleeping for 0ms before retrying again. Got null now.
2017-05-11 22:22:58,895 INFO [main] org.apache.hadoop.mapred.YarnChild: mapreduce.cluster.local.dir for child: /Users/jonsonli/Bigdata/hadoopdata/nm-local-dir/usercache/jonsonli/appcache/application_1494511663670_0004
2017-05-11 22:22:59,280 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
2017-05-11 22:22:59,905 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: File Output Committer Algorithm version is 1
2017-05-11 22:22:59,918 INFO [main] org.apache.hadoop.yarn.util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
2017-05-11 22:22:59,919 INFO [main] org.apache.hadoop.mapred.Task: Using ResourceCalculatorProcessTree : null
2017-05-11 22:22:59,924 INFO [main] org.apache.hadoop.mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@1e7aa82b
2017-05-11 22:23:00,347 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2017-05-11 22:23:00,556 INFO [main] org.apache.hadoop.mapred.Task: Task:attempt_1494511663670_0004_r_000000_0 is done. And is in the process of committing
2017-05-11 22:23:00,579 INFO [main] org.apache.hadoop.mapred.Task: Task attempt_1494511663670_0004_r_000000_0 is allowed to commit now
2017-05-11 22:23:00,591 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: Saved output of task 'attempt_1494511663670_0004_r_000000_0' to hdfs://localhost:9000/output/_temporary/1/task_1494511663670_0004_r_000000
2017-05-11 22:23:00,602 INFO [main] org.apache.hadoop.mapred.Task: Task 'attempt_1494511663670_0004_r_000000_0' done.
2017-05-11 22:23:00,608 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping ReduceTask metrics system...
2017-05-11 22:23:00,608 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system stopped.
2017-05-11 22:23:00,609 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system shutdown complete.
End of LogType:syslog
LogType:syslog.shuffle
Log Upload Time:星期四 五月 11 22:23:08 +0800 2017
LogLength:3835
Log Contents:
2017-05-11 22:22:59,947 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: MergerManager: memoryLimit=130652568, maxSingleShuffleLimit=32663142, mergeThreshold=86230696, ioSortFactor=10, memToMemMergeOutputsThreshold=10
2017-05-11 22:22:59,950 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: attempt_1494511663670_0004_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
2017-05-11 22:22:59,959 INFO [fetcher#1] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: Assigning localhost:13562 with 1 to fetcher#1
2017-05-11 22:22:59,959 INFO [fetcher#1] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: assigned 2 of 2 to localhost:13562 to fetcher#1
2017-05-11 22:22:59,959 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: attempt_1494511663670_0004_r_000000_0: Got 2 new map-outputs
2017-05-11 22:23:00,105 INFO [fetcher#1] org.apache.hadoop.mapreduce.task.reduce.Fetcher: for url=13562/mapOutput?job=job_1494511663670_0004&reduce=0&map=attempt_1494511663670_0004_m_000001_0,attempt_1494511663670_0004_m_000000_0 sent hash and received reply
2017-05-11 22:23:00,109 INFO [fetcher#1] org.apache.hadoop.mapreduce.task.reduce.Fetcher: fetcher#1 about to shuffle output of map attempt_1494511663670_0004_m_000001_0 decomp: 12794 len: 12798 to MEMORY
2017-05-11 22:23:00,111 INFO [fetcher#1] org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput: Read 12794 bytes from map-output for attempt_1494511663670_0004_m_000001_0
2017-05-11 22:23:00,113 INFO [fetcher#1] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 12794, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->12794
2017-05-11 22:23:00,114 INFO [fetcher#1] org.apache.hadoop.mapreduce.task.reduce.Fetcher: fetcher#1 about to shuffle output of map attempt_1494511663670_0004_m_000000_0 decomp: 12794 len: 12798 to MEMORY
2017-05-11 22:23:00,115 INFO [fetcher#1] org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput: Read 12794 bytes from map-output for attempt_1494511663670_0004_m_000000_0
2017-05-11 22:23:00,115 INFO [fetcher#1] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 12794, inMemoryMapOutputs.size() -> 2, commitMemory -> 12794, usedMemory ->25588
2017-05-11 22:23:00,116 INFO [fetcher#1] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: localhost:13562 freed by fetcher#1 in 157ms
2017-05-11 22:23:00,116 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: EventFetcher is interrupted.. Returning
2017-05-11 22:23:00,122 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: finalMerge called with 2 in-memory map-outputs and 0 on-disk map-outputs
2017-05-11 22:23:00,130 INFO [main] org.apache.hadoop.mapred.Merger: Merging 2 sorted segments
2017-05-11 22:23:00,130 INFO [main] org.apache.hadoop.mapred.Merger: Down to the last merge-pass, with 2 segments left of total size: 25576 bytes
2017-05-11 22:23:00,160 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merged 2 segments, 25588 bytes to disk to satisfy reduce memory limit
2017-05-11 22:23:00,161 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merging 1 files, 25590 bytes from disk
2017-05-11 22:23:00,162 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
2017-05-11 22:23:00,162 INFO [main] org.apache.hadoop.mapred.Merger: Merging 1 sorted segments
2017-05-11 22:23:00,184 INFO [main] org.apache.hadoop.mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 25580 bytes
End of LogType:syslog.shuffle
Container: container_1494511663670_0004_01_000003 on localhost_62244
======================================================================
LogType:stderr
Log Upload Time:星期四 五月 11 22:23:08 +0800 2017
LogLength:0
Log Contents:
End of LogType:stderr
LogType:stdout
Log Upload Time:星期四 五月 11 22:23:08 +0800 2017
LogLength:0
Log Contents:
End of LogType:stdout
LogType:syslog
Log Upload Time:星期四 五月 11 22:23:08 +0800 2017
LogLength:3736
Log Contents:
2017-05-11 22:22:51,021 WARN [main] org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2017-05-11 22:22:51,213 INFO [main] org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2017-05-11 22:22:51,439 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s).
2017-05-11 22:22:51,439 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system started
2017-05-11 22:22:51,455 INFO [main] org.apache.hadoop.mapred.YarnChild: Executing with tokens:
2017-05-11 22:22:51,455 INFO [main] org.apache.hadoop.mapred.YarnChild: Kind: mapreduce.job, Service: job_1494511663670_0004, Ident: (org.apache.hadoop.mapreduce.security.token.JobTokenIdentifier@27462a88)
2017-05-11 22:22:51,901 INFO [main] org.apache.hadoop.mapred.YarnChild: Sleeping for 0ms before retrying again. Got null now.
2017-05-11 22:22:52,515 INFO [main] org.apache.hadoop.mapred.YarnChild: mapreduce.cluster.local.dir for child: /Users/jonsonli/Bigdata/hadoopdata/nm-local-dir/usercache/jonsonli/appcache/application_1494511663670_0004
2017-05-11 22:22:52,935 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
2017-05-11 22:22:53,495 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: File Output Committer Algorithm version is 1
2017-05-11 22:22:53,505 INFO [main] org.apache.hadoop.yarn.util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
2017-05-11 22:22:53,506 INFO [main] org.apache.hadoop.mapred.Task: Using ResourceCalculatorProcessTree : null
2017-05-11 22:22:53,791 INFO [main] org.apache.hadoop.mapred.MapTask: Processing split: hdfs://localhost:9000/input/file02:0+19002
2017-05-11 22:22:53,945 INFO [main] org.apache.hadoop.mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
2017-05-11 22:22:53,945 INFO [main] org.apache.hadoop.mapred.MapTask: mapreduce.task.io.sort.mb: 100
2017-05-11 22:22:53,945 INFO [main] org.apache.hadoop.mapred.MapTask: soft limit at 83886080
2017-05-11 22:22:53,945 INFO [main] org.apache.hadoop.mapred.MapTask: bufstart = 0; bufvoid = 104857600
2017-05-11 22:22:53,945 INFO [main] org.apache.hadoop.mapred.MapTask: kvstart = 26214396; length = 6553600
2017-05-11 22:22:53,952 INFO [main] org.apache.hadoop.mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2017-05-11 22:22:54,060 INFO [main] org.apache.hadoop.mapred.MapTask: Starting flush of map output
2017-05-11 22:22:54,060 INFO [main] org.apache.hadoop.mapred.MapTask: Spilling map output
2017-05-11 22:22:54,060 INFO [main] org.apache.hadoop.mapred.MapTask: bufstart = 0; bufend = 30225; bufvoid = 104857600
2017-05-11 22:22:54,060 INFO [main] org.apache.hadoop.mapred.MapTask: kvstart = 26214396(104857584); kvend = 26202940(104811760); length = 11457/6553600
2017-05-11 22:22:54,213 INFO [main] org.apache.hadoop.mapred.MapTask: Finished spill 0
2017-05-11 22:22:54,272 INFO [main] org.apache.hadoop.mapred.Task: Task:attempt_1494511663670_0004_m_000001_0 is done. And is in the process of committing
2017-05-11 22:22:54,331 INFO [main] org.apache.hadoop.mapred.Task: Task 'attempt_1494511663670_0004_m_000001_0' done.
2017-05-11 22:22:54,398 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping MapTask metrics system...
2017-05-11 22:22:54,411 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system stopped.
2017-05-11 22:22:54,412 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system shutdown complete.
End of LogType:syslog
Container: container_1494511663670_0004_01_000002 on localhost_62244
======================================================================
LogType:stderr
Log Upload Time:星期四 五月 11 22:23:08 +0800 2017
LogLength:0
Log Contents:
End of LogType:stderr
LogType:stdout
Log Upload Time:星期四 五月 11 22:23:08 +0800 2017
LogLength:0
Log Contents:
End of LogType:stdout
LogType:syslog
Log Upload Time:星期四 五月 11 22:23:08 +0800 2017
LogLength:3736
Log Contents:
2017-05-11 22:22:51,085 WARN [main] org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2017-05-11 22:22:51,268 INFO [main] org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2017-05-11 22:22:51,449 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s).
2017-05-11 22:22:51,449 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system started
2017-05-11 22:22:51,466 INFO [main] org.apache.hadoop.mapred.YarnChild: Executing with tokens:
2017-05-11 22:22:51,467 INFO [main] org.apache.hadoop.mapred.YarnChild: Kind: mapreduce.job, Service: job_1494511663670_0004, Ident: (org.apache.hadoop.mapreduce.security.token.JobTokenIdentifier@27462a88)
2017-05-11 22:22:51,938 INFO [main] org.apache.hadoop.mapred.YarnChild: Sleeping for 0ms before retrying again. Got null now.
2017-05-11 22:22:52,527 INFO [main] org.apache.hadoop.mapred.YarnChild: mapreduce.cluster.local.dir for child: /Users/jonsonli/Bigdata/hadoopdata/nm-local-dir/usercache/jonsonli/appcache/application_1494511663670_0004
2017-05-11 22:22:52,921 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
2017-05-11 22:22:53,515 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: File Output Committer Algorithm version is 1
2017-05-11 22:22:53,526 INFO [main] org.apache.hadoop.yarn.util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
2017-05-11 22:22:53,527 INFO [main] org.apache.hadoop.mapred.Task: Using ResourceCalculatorProcessTree : null
2017-05-11 22:22:53,840 INFO [main] org.apache.hadoop.mapred.MapTask: Processing split: hdfs://localhost:9000/input/file01:0+19002
2017-05-11 22:22:54,105 INFO [main] org.apache.hadoop.mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
2017-05-11 22:22:54,105 INFO [main] org.apache.hadoop.mapred.MapTask: mapreduce.task.io.sort.mb: 100
2017-05-11 22:22:54,105 INFO [main] org.apache.hadoop.mapred.MapTask: soft limit at 83886080
2017-05-11 22:22:54,105 INFO [main] org.apache.hadoop.mapred.MapTask: bufstart = 0; bufvoid = 104857600
2017-05-11 22:22:54,106 INFO [main] org.apache.hadoop.mapred.MapTask: kvstart = 26214396; length = 6553600
2017-05-11 22:22:54,112 INFO [main] org.apache.hadoop.mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2017-05-11 22:22:54,202 INFO [main] org.apache.hadoop.mapred.MapTask: Starting flush of map output
2017-05-11 22:22:54,202 INFO [main] org.apache.hadoop.mapred.MapTask: Spilling map output
2017-05-11 22:22:54,202 INFO [main] org.apache.hadoop.mapred.MapTask: bufstart = 0; bufend = 30225; bufvoid = 104857600
2017-05-11 22:22:54,202 INFO [main] org.apache.hadoop.mapred.MapTask: kvstart = 26214396(104857584); kvend = 26202940(104811760); length = 11457/6553600
2017-05-11 22:22:54,432 INFO [main] org.apache.hadoop.mapred.MapTask: Finished spill 0
2017-05-11 22:22:54,451 INFO [main] org.apache.hadoop.mapred.Task: Task:attempt_1494511663670_0004_m_000000_0 is done. And is in the process of committing
2017-05-11 22:22:54,480 INFO [main] org.apache.hadoop.mapred.Task: Task 'attempt_1494511663670_0004_m_000000_0' done.
2017-05-11 22:22:54,484 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping MapTask metrics system...
2017-05-11 22:22:54,485 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system stopped.
2017-05-11 22:22:54,485 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system shutdown complete.
End of LogType:syslog
Container: container_1494511663670_0004_01_000001 on localhost_62244
======================================================================
LogType:stderr
Log Upload Time:星期四 五月 11 22:23:08 +0800 2017
LogLength:1773
Log Contents:
五月 11, 2017 10:22:45 下午 com.sun.jersey.guice.spi.container.GuiceComponentProviderFactory register
信息: Registering org.apache.hadoop.mapreduce.v2.app.webapp.JAXBContextResolver as a provider class
五月 11, 2017 10:22:45 下午 com.sun.jersey.guice.spi.container.GuiceComponentProviderFactory register
信息: Registering org.apache.hadoop.yarn.webapp.GenericExceptionHandler as a provider class
五月 11, 2017 10:22:45 下午 com.sun.jersey.guice.spi.container.GuiceComponentProviderFactory register
信息: Registering org.apache.hadoop.mapreduce.v2.app.webapp.AMWebServices as a root resource class
五月 11, 2017 10:22:45 下午 com.sun.jersey.server.impl.application.WebApplicationImpl _initiate
信息: Initiating Jersey application, version 'Jersey: 1.9 09/02/2011 11:17 AM'
五月 11, 2017 10:22:45 下午 com.sun.jersey.guice.spi.container.GuiceComponentProviderFactory getComponentProvider
信息: Binding org.apache.hadoop.mapreduce.v2.app.webapp.JAXBContextResolver to GuiceManagedComponentProvider with the scope "Singleton"
五月 11, 2017 10:22:46 下午 com.sun.jersey.guice.spi.container.GuiceComponentProviderFactory getComponentProvider
信息: Binding org.apache.hadoop.yarn.webapp.GenericExceptionHandler to GuiceManagedComponentProvider with the scope "Singleton"
五月 11, 2017 10:22:46 下午 com.sun.jersey.guice.spi.container.GuiceComponentProviderFactory getComponentProvider
信息: Binding org.apache.hadoop.mapreduce.v2.app.webapp.AMWebServices to GuiceManagedComponentProvider with the scope "PerRequest"
log4j:WARN No appenders could be found for logger (org.apache.hadoop.ipc.Server).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
End of LogType:stderr
LogType:stdout
Log Upload Time:星期四 五月 11 22:23:08 +0800 2017
LogLength:0
Log Contents:
End of LogType:stdout
LogType:syslog
Log Upload Time:星期四 五月 11 22:23:08 +0800 2017
LogLength:40682
Log Contents:
2017-05-11 22:22:42,505 INFO [main] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: Created MRAppMaster for application appattempt_1494511663670_0004_000001
2017-05-11 22:22:42,719 WARN [main] org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2017-05-11 22:22:42,755 INFO [main] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: Executing with tokens:
2017-05-11 22:22:42,755 INFO [main] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: Kind: YARN_AM_RM_TOKEN, Service: , Ident: (appAttemptId { application_id { id: 4 cluster_timestamp: 1494511663670 } attemptId: 1 } keyId: 1756661102)
2017-05-11 22:22:42,963 INFO [main] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: Using mapred newApiCommitter.
2017-05-11 22:22:42,965 INFO [main] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: OutputCommitter set in config null
2017-05-11 22:22:43,018 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: File Output Committer Algorithm version is 1
2017-05-11 22:22:43,493 INFO [main] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2017-05-11 22:22:43,631 INFO [main] org.apache.hadoop.yarn.event.AsyncDispatcher: Registering class org.apache.hadoop.mapreduce.jobhistory.EventType for class org.apache.hadoop.mapreduce.jobhistory.JobHistoryEventHandler
2017-05-11 22:22:43,632 INFO [main] org.apache.hadoop.yarn.event.AsyncDispatcher: Registering class org.apache.hadoop.mapreduce.v2.app.job.event.JobEventType for class org.apache.hadoop.mapreduce.v2.app.MRAppMaster$JobEventDispatcher
2017-05-11 22:22:43,633 INFO [main] org.apache.hadoop.yarn.event.AsyncDispatcher: Registering class org.apache.hadoop.mapreduce.v2.app.job.event.TaskEventType for class org.apache.hadoop.mapreduce.v2.app.MRAppMaster$TaskEventDispatcher
2017-05-11 22:22:43,634 INFO [main] org.apache.hadoop.yarn.event.AsyncDispatcher: Registering class org.apache.hadoop.mapreduce.v2.app.job.event.TaskAttemptEventType for class org.apache.hadoop.mapreduce.v2.app.MRAppMaster$TaskAttemptEventDispatcher
2017-05-11 22:22:43,634 INFO [main] org.apache.hadoop.yarn.event.AsyncDispatcher: Registering class org.apache.hadoop.mapreduce.v2.app.commit.CommitterEventType for class org.apache.hadoop.mapreduce.v2.app.commit.CommitterEventHandler
2017-05-11 22:22:43,639 INFO [main] org.apache.hadoop.yarn.event.AsyncDispatcher: Registering class org.apache.hadoop.mapreduce.v2.app.speculate.Speculator$EventType for class org.apache.hadoop.mapreduce.v2.app.MRAppMaster$SpeculatorEventDispatcher
2017-05-11 22:22:43,640 INFO [main] org.apache.hadoop.yarn.event.AsyncDispatcher: Registering class org.apache.hadoop.mapreduce.v2.app.rm.ContainerAllocator$EventType for class org.apache.hadoop.mapreduce.v2.app.MRAppMaster$ContainerAllocatorRouter
2017-05-11 22:22:43,640 INFO [main] org.apache.hadoop.yarn.event.AsyncDispatcher: Registering class org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncher$EventType for class org.apache.hadoop.mapreduce.v2.app.MRAppMaster$ContainerLauncherRouter
2017-05-11 22:22:43,675 INFO [main] org.apache.hadoop.mapreduce.v2.jobhistory.JobHistoryUtils: Default file system [hdfs://localhost:9000]
2017-05-11 22:22:43,701 INFO [main] org.apache.hadoop.mapreduce.v2.jobhistory.JobHistoryUtils: Default file system [hdfs://localhost:9000]
2017-05-11 22:22:43,727 INFO [main] org.apache.hadoop.mapreduce.v2.jobhistory.JobHistoryUtils: Default file system [hdfs://localhost:9000]
2017-05-11 22:22:43,736 INFO [main] org.apache.hadoop.mapreduce.jobhistory.JobHistoryEventHandler: Emitting job history data to the timeline server is not enabled
2017-05-11 22:22:43,775 INFO [main] org.apache.hadoop.yarn.event.AsyncDispatcher: Registering class org.apache.hadoop.mapreduce.v2.app.job.event.JobFinishEvent$Type for class org.apache.hadoop.mapreduce.v2.app.MRAppMaster$JobFinishEventHandler
2017-05-11 22:22:43,849 INFO [main] org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2017-05-11 22:22:43,904 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s).
2017-05-11 22:22:43,904 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MRAppMaster metrics system started
2017-05-11 22:22:43,913 INFO [main] org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl: Adding job token for job_1494511663670_0004 to jobTokenSecretManager
2017-05-11 22:22:44,016 INFO [main] org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl: Not uberizing job_1494511663670_0004 because: not enabled;
2017-05-11 22:22:44,029 INFO [main] org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl: Input size for job job_1494511663670_0004 = 38004. Number of splits = 2
2017-05-11 22:22:44,030 INFO [main] org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl: Number of reduces for job job_1494511663670_0004 = 1
2017-05-11 22:22:44,030 INFO [main] org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl: job_1494511663670_0004Job Transitioned from NEW to INITED
2017-05-11 22:22:44,032 INFO [main] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: MRAppMaster launching normal, non-uberized, multi-container job job_1494511663670_0004.
2017-05-11 22:22:44,057 INFO [main] org.apache.hadoop.ipc.CallQueueManager: Using callQueue class java.util.concurrent.LinkedBlockingQueue
2017-05-11 22:22:44,069 INFO [Socket Reader #1 for port 62654] org.apache.hadoop.ipc.Server: Starting Socket Reader #1 for port 62654
2017-05-11 22:22:44,090 INFO [main] org.apache.hadoop.yarn.factories.impl.pb.RpcServerFactoryPBImpl: Adding protocol org.apache.hadoop.mapreduce.v2.api.MRClientProtocolPB to the server
2017-05-11 22:22:44,090 INFO [IPC Server Responder] org.apache.hadoop.ipc.Server: IPC Server Responder: starting
2017-05-11 22:22:44,090 INFO [IPC Server listener on 62654] org.apache.hadoop.ipc.Server: IPC Server listener on 62654: starting
2017-05-11 22:22:44,092 INFO [main] org.apache.hadoop.mapreduce.v2.app.client.MRClientService: Instantiated MRClientService at localhost/127.0.0.1:62654
2017-05-11 22:22:44,217 INFO [main] org.mortbay.log: Logging to org.slf4j.impl.Log4jLoggerAdapter(org.mortbay.log) via org.mortbay.log.Slf4jLog
2017-05-11 22:22:44,228 INFO [main] org.apache.hadoop.security.authentication.server.AuthenticationFilter: Unable to initialize FileSignerSecretProvider, falling back to use random secrets.
2017-05-11 22:22:44,236 INFO [main] org.apache.hadoop.http.HttpRequestLog: Http request log for http.requests.mapreduce is not defined
2017-05-11 22:22:44,244 INFO [main] org.apache.hadoop.http.HttpServer2: Added global filter 'safety' (class=org.apache.hadoop.http.HttpServer2$QuotingInputFilter)
2017-05-11 22:22:44,251 INFO [main] org.apache.hadoop.http.HttpServer2: Added filter AM_PROXY_FILTER (class=org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter) to context mapreduce
2017-05-11 22:22:44,251 INFO [main] org.apache.hadoop.http.HttpServer2: Added filter AM_PROXY_FILTER (class=org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter) to context static
2017-05-11 22:22:44,254 INFO [main] org.apache.hadoop.http.HttpServer2: adding path spec: /mapreduce/*
2017-05-11 22:22:44,254 INFO [main] org.apache.hadoop.http.HttpServer2: adding path spec: /ws/*
2017-05-11 22:22:44,845 INFO [main] org.apache.hadoop.yarn.webapp.WebApps: Registered webapp guice modules
2017-05-11 22:22:44,848 INFO [main] org.apache.hadoop.http.HttpServer2: Jetty bound to port 62655
2017-05-11 22:22:44,848 INFO [main] org.mortbay.log: jetty-6.1.26
2017-05-11 22:22:44,891 INFO [main] org.mortbay.log: Extract jar:file:/Users/jonsonli/Bigdata/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-common-2.7.3.jar!/webapps/mapreduce to /Users/jonsonli/Bigdata/hadoopdata/nm-local-dir/usercache/jonsonli/appcache/application_1494511663670_0004/container_1494511663670_0004_01_000001/tmp/Jetty_0_0_0_0_62655_mapreduce____kehpzz/webapp
2017-05-11 22:22:46,570 INFO [main] org.mortbay.log: Started [email protected]:62655
2017-05-11 22:22:46,570 INFO [main] org.apache.hadoop.yarn.webapp.WebApps: Web app mapreduce started at 62655
2017-05-11 22:22:46,574 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.speculate.DefaultSpeculator: JOB_CREATE job_1494511663670_0004
2017-05-11 22:22:46,575 INFO [main] org.apache.hadoop.ipc.CallQueueManager: Using callQueue class java.util.concurrent.LinkedBlockingQueue
2017-05-11 22:22:46,576 INFO [Socket Reader #1 for port 62657] org.apache.hadoop.ipc.Server: Starting Socket Reader #1 for port 62657
2017-05-11 22:22:46,579 INFO [IPC Server Responder] org.apache.hadoop.ipc.Server: IPC Server Responder: starting
2017-05-11 22:22:46,579 INFO [IPC Server listener on 62657] org.apache.hadoop.ipc.Server: IPC Server listener on 62657: starting
2017-05-11 22:22:46,602 INFO [main] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerRequestor: nodeBlacklistingEnabled:true
2017-05-11 22:22:46,603 INFO [main] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerRequestor: maxTaskFailuresPerNode is 3
2017-05-11 22:22:46,603 INFO [main] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerRequestor: blacklistDisablePercent is 33
2017-05-11 22:22:46,656 INFO [main] org.apache.hadoop.yarn.client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8030
2017-05-11 22:22:46,735 INFO [main] org.apache.hadoop.mapreduce.v2.app.rm.RMCommunicator: maxContainerCapability: <memory:8192, vCores:32>
2017-05-11 22:22:46,735 INFO [main] org.apache.hadoop.mapreduce.v2.app.rm.RMCommunicator: queue: default
2017-05-11 22:22:46,740 INFO [main] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Upper limit on the thread pool size is 500
2017-05-11 22:22:46,740 INFO [main] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: The thread pool initial size is 10
2017-05-11 22:22:46,742 INFO [main] org.apache.hadoop.yarn.client.api.impl.ContainerManagementProtocolProxy: yarn.client.max-cached-nodemanagers-proxies : 0
2017-05-11 22:22:46,749 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl: job_1494511663670_0004Job Transitioned from INITED to SETUP
2017-05-11 22:22:46,751 INFO [CommitterEvent Processor #0] org.apache.hadoop.mapreduce.v2.app.commit.CommitterEventHandler: Processing the event EventType: JOB_SETUP
2017-05-11 22:22:46,759 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl: job_1494511663670_0004Job Transitioned from SETUP to RUNNING
2017-05-11 22:22:46,777 INFO [AsyncDispatcher event handler] org.apache.hadoop.yarn.util.RackResolver: Resolved localhost to /default-rack
2017-05-11 22:22:46,780 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskImpl: task_1494511663670_0004_m_000000 Task Transitioned from NEW to SCHEDULED
2017-05-11 22:22:46,781 INFO [AsyncDispatcher event handler] org.apache.hadoop.yarn.util.RackResolver: Resolved localhost to /default-rack
2017-05-11 22:22:46,781 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskImpl: task_1494511663670_0004_m_000001 Task Transitioned from NEW to SCHEDULED
2017-05-11 22:22:46,781 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskImpl: task_1494511663670_0004_r_000000 Task Transitioned from NEW to SCHEDULED
2017-05-11 22:22:46,783 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_m_000000_0 TaskAttempt Transitioned from NEW to UNASSIGNED
2017-05-11 22:22:46,783 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_m_000001_0 TaskAttempt Transitioned from NEW to UNASSIGNED
2017-05-11 22:22:46,783 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_r_000000_0 TaskAttempt Transitioned from NEW to UNASSIGNED
2017-05-11 22:22:46,785 INFO [Thread-50] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: mapResourceRequest:<memory:1024, vCores:1>
2017-05-11 22:22:46,793 INFO [Thread-50] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: reduceResourceRequest:<memory:1024, vCores:1>
2017-05-11 22:22:46,829 INFO [eventHandlingThread] org.apache.hadoop.mapreduce.jobhistory.JobHistoryEventHandler: Event Writer setup for JobId: job_1494511663670_0004, File: hdfs://localhost:9000/tmp/hadoop-yarn/staging/jonsonli/.staging/job_1494511663670_0004/job_1494511663670_0004_1.jhist
2017-05-11 22:22:47,738 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Before Scheduling: PendingReds:1 ScheduledMaps:2 ScheduledReds:0 AssignedMaps:0 AssignedReds:0 CompletedMaps:0 CompletedReds:0 ContAlloc:0 ContRel:0 HostLocal:0 RackLocal:0
2017-05-11 22:22:47,782 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerRequestor: getResources() for application_1494511663670_0004: ask=3 release= 0 newContainers=0 finishedContainers=0 resourcelimit=<memory:6144, vCores:1> knownNMs=1
2017-05-11 22:22:47,783 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Recalculating schedule, headroom=<memory:6144, vCores:1>
2017-05-11 22:22:47,783 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Reduce slow start threshold not met. completedMapsForReduceSlowstart 1
2017-05-11 22:22:48,799 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Got allocated containers 2
2017-05-11 22:22:48,801 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Assigned container container_1494511663670_0004_01_000002 to attempt_1494511663670_0004_m_000000_0
2017-05-11 22:22:48,802 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Assigned container container_1494511663670_0004_01_000003 to attempt_1494511663670_0004_m_000001_0
2017-05-11 22:22:48,803 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Recalculating schedule, headroom=<memory:4096, vCores:1>
2017-05-11 22:22:48,803 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Reduce slow start threshold not met. completedMapsForReduceSlowstart 1
2017-05-11 22:22:48,803 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: After Scheduling: PendingReds:1 ScheduledMaps:0 ScheduledReds:0 AssignedMaps:2 AssignedReds:0 CompletedMaps:0 CompletedReds:0 ContAlloc:2 ContRel:0 HostLocal:2 RackLocal:0
2017-05-11 22:22:48,857 INFO [AsyncDispatcher event handler] org.apache.hadoop.yarn.util.RackResolver: Resolved localhost to /default-rack
2017-05-11 22:22:48,877 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: The job-jar file on the remote FS is hdfs://localhost:9000/tmp/hadoop-yarn/staging/jonsonli/.staging/job_1494511663670_0004/job.jar
2017-05-11 22:22:48,881 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: The job-conf file on the remote FS is /tmp/hadoop-yarn/staging/jonsonli/.staging/job_1494511663670_0004/job.xml
2017-05-11 22:22:48,882 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: Adding #0 tokens and #1 secret keys for NM use for launching container
2017-05-11 22:22:48,882 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: Size of containertokens_dob is 1
2017-05-11 22:22:48,883 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: Putting shuffle token in serviceData
2017-05-11 22:22:48,914 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_m_000000_0 TaskAttempt Transitioned from UNASSIGNED to ASSIGNED
2017-05-11 22:22:48,919 INFO [AsyncDispatcher event handler] org.apache.hadoop.yarn.util.RackResolver: Resolved localhost to /default-rack
2017-05-11 22:22:48,919 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_m_000001_0 TaskAttempt Transitioned from UNASSIGNED to ASSIGNED
2017-05-11 22:22:48,921 INFO [ContainerLauncher #1] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Processing the event EventType: CONTAINER_REMOTE_LAUNCH for container container_1494511663670_0004_01_000003 taskAttempt attempt_1494511663670_0004_m_000001_0
2017-05-11 22:22:48,921 INFO [ContainerLauncher #0] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Processing the event EventType: CONTAINER_REMOTE_LAUNCH for container container_1494511663670_0004_01_000002 taskAttempt attempt_1494511663670_0004_m_000000_0
2017-05-11 22:22:48,925 INFO [ContainerLauncher #1] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Launching attempt_1494511663670_0004_m_000001_0
2017-05-11 22:22:48,925 INFO [ContainerLauncher #0] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Launching attempt_1494511663670_0004_m_000000_0
2017-05-11 22:22:48,926 INFO [ContainerLauncher #1] org.apache.hadoop.yarn.client.api.impl.ContainerManagementProtocolProxy: Opening proxy : localhost:62244
2017-05-11 22:22:48,953 INFO [ContainerLauncher #0] org.apache.hadoop.yarn.client.api.impl.ContainerManagementProtocolProxy: Opening proxy : localhost:62244
2017-05-11 22:22:49,006 INFO [ContainerLauncher #1] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Shuffle port returned by ContainerManager for attempt_1494511663670_0004_m_000001_0 : 13562
2017-05-11 22:22:49,007 INFO [ContainerLauncher #0] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Shuffle port returned by ContainerManager for attempt_1494511663670_0004_m_000000_0 : 13562
2017-05-11 22:22:49,009 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: TaskAttempt: [attempt_1494511663670_0004_m_000001_0] using containerId: [container_1494511663670_0004_01_000003 on NM: [localhost:62244]
2017-05-11 22:22:49,013 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_m_000001_0 TaskAttempt Transitioned from ASSIGNED to RUNNING
2017-05-11 22:22:49,013 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: TaskAttempt: [attempt_1494511663670_0004_m_000000_0] using containerId: [container_1494511663670_0004_01_000002 on NM: [localhost:62244]
2017-05-11 22:22:49,014 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_m_000000_0 TaskAttempt Transitioned from ASSIGNED to RUNNING
2017-05-11 22:22:49,014 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.speculate.DefaultSpeculator: ATTEMPT_START task_1494511663670_0004_m_000001
2017-05-11 22:22:49,014 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskImpl: task_1494511663670_0004_m_000001 Task Transitioned from SCHEDULED to RUNNING
2017-05-11 22:22:49,014 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.speculate.DefaultSpeculator: ATTEMPT_START task_1494511663670_0004_m_000000
2017-05-11 22:22:49,014 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskImpl: task_1494511663670_0004_m_000000 Task Transitioned from SCHEDULED to RUNNING
2017-05-11 22:22:49,807 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerRequestor: getResources() for application_1494511663670_0004: ask=3 release= 0 newContainers=0 finishedContainers=0 resourcelimit=<memory:4096, vCores:1> knownNMs=1
2017-05-11 22:22:52,307 INFO [Socket Reader #1 for port 62657] SecurityLogger.org.apache.hadoop.ipc.Server: Auth successful for job_1494511663670_0004 (auth:SIMPLE)
2017-05-11 22:22:52,364 INFO [IPC Server handler 6 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: JVM with ID : jvm_1494511663670_0004_m_000003 asked for a task
2017-05-11 22:22:52,364 INFO [IPC Server handler 6 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: JVM with ID: jvm_1494511663670_0004_m_000003 given task: attempt_1494511663670_0004_m_000001_0
2017-05-11 22:22:52,372 INFO [Socket Reader #1 for port 62657] SecurityLogger.org.apache.hadoop.ipc.Server: Auth successful for job_1494511663670_0004 (auth:SIMPLE)
2017-05-11 22:22:52,387 INFO [IPC Server handler 1 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: JVM with ID : jvm_1494511663670_0004_m_000002 asked for a task
2017-05-11 22:22:52,387 INFO [IPC Server handler 1 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: JVM with ID: jvm_1494511663670_0004_m_000002 given task: attempt_1494511663670_0004_m_000000_0
2017-05-11 22:22:54,053 INFO [IPC Server handler 6 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Progress of TaskAttempt attempt_1494511663670_0004_m_000001_0 is : 0.0
2017-05-11 22:22:54,200 INFO [IPC Server handler 1 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Progress of TaskAttempt attempt_1494511663670_0004_m_000000_0 is : 0.0
2017-05-11 22:22:54,318 INFO [IPC Server handler 3 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Progress of TaskAttempt attempt_1494511663670_0004_m_000001_0 is : 1.0
2017-05-11 22:22:54,329 INFO [IPC Server handler 2 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Done acknowledgement from attempt_1494511663670_0004_m_000001_0
2017-05-11 22:22:54,331 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_m_000001_0 TaskAttempt Transitioned from RUNNING to SUCCESS_CONTAINER_CLEANUP
2017-05-11 22:22:54,331 INFO [ContainerLauncher #2] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Processing the event EventType: CONTAINER_REMOTE_CLEANUP for container container_1494511663670_0004_01_000003 taskAttempt attempt_1494511663670_0004_m_000001_0
2017-05-11 22:22:54,332 INFO [ContainerLauncher #2] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: KILLING attempt_1494511663670_0004_m_000001_0
2017-05-11 22:22:54,332 INFO [ContainerLauncher #2] org.apache.hadoop.yarn.client.api.impl.ContainerManagementProtocolProxy: Opening proxy : localhost:62244
2017-05-11 22:22:54,351 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_m_000001_0 TaskAttempt Transitioned from SUCCESS_CONTAINER_CLEANUP to SUCCEEDED
2017-05-11 22:22:54,360 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskImpl: Task succeeded with attempt attempt_1494511663670_0004_m_000001_0
2017-05-11 22:22:54,361 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskImpl: task_1494511663670_0004_m_000001 Task Transitioned from RUNNING to SUCCEEDED
2017-05-11 22:22:54,365 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl: Num completed Tasks: 1
2017-05-11 22:22:54,475 INFO [IPC Server handler 4 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Progress of TaskAttempt attempt_1494511663670_0004_m_000000_0 is : 1.0
2017-05-11 22:22:54,478 INFO [IPC Server handler 5 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Done acknowledgement from attempt_1494511663670_0004_m_000000_0
2017-05-11 22:22:54,480 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_m_000000_0 TaskAttempt Transitioned from RUNNING to SUCCESS_CONTAINER_CLEANUP
2017-05-11 22:22:54,481 INFO [ContainerLauncher #3] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Processing the event EventType: CONTAINER_REMOTE_CLEANUP for container container_1494511663670_0004_01_000002 taskAttempt attempt_1494511663670_0004_m_000000_0
2017-05-11 22:22:54,481 INFO [ContainerLauncher #3] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: KILLING attempt_1494511663670_0004_m_000000_0
2017-05-11 22:22:54,481 INFO [ContainerLauncher #3] org.apache.hadoop.yarn.client.api.impl.ContainerManagementProtocolProxy: Opening proxy : localhost:62244
2017-05-11 22:22:54,491 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_m_000000_0 TaskAttempt Transitioned from SUCCESS_CONTAINER_CLEANUP to SUCCEEDED
2017-05-11 22:22:54,492 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskImpl: Task succeeded with attempt attempt_1494511663670_0004_m_000000_0
2017-05-11 22:22:54,492 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskImpl: task_1494511663670_0004_m_000000 Task Transitioned from RUNNING to SUCCEEDED
2017-05-11 22:22:54,492 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl: Num completed Tasks: 2
2017-05-11 22:22:54,831 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Before Scheduling: PendingReds:1 ScheduledMaps:0 ScheduledReds:0 AssignedMaps:2 AssignedReds:0 CompletedMaps:2 CompletedReds:0 ContAlloc:2 ContRel:0 HostLocal:2 RackLocal:0
2017-05-11 22:22:54,838 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Received completed container container_1494511663670_0004_01_000003
2017-05-11 22:22:54,840 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Received completed container container_1494511663670_0004_01_000002
2017-05-11 22:22:54,840 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: Diagnostics report from attempt_1494511663670_0004_m_000001_0: Container killed by the ApplicationMaster.
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
2017-05-11 22:22:54,840 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Recalculating schedule, headroom=<memory:6144, vCores:1>
2017-05-11 22:22:54,840 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Reduce slow start threshold reached. Scheduling reduces.
2017-05-11 22:22:54,840 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: All maps assigned. Ramping up all remaining reduces:1
2017-05-11 22:22:54,840 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: Diagnostics report from attempt_1494511663670_0004_m_000000_0: Container killed by the ApplicationMaster.
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
2017-05-11 22:22:54,840 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: After Scheduling: PendingReds:0 ScheduledMaps:0 ScheduledReds:1 AssignedMaps:0 AssignedReds:0 CompletedMaps:2 CompletedReds:0 ContAlloc:2 ContRel:0 HostLocal:2 RackLocal:0
2017-05-11 22:22:55,843 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerRequestor: getResources() for application_1494511663670_0004: ask=1 release= 0 newContainers=0 finishedContainers=0 resourcelimit=<memory:6144, vCores:1> knownNMs=1
2017-05-11 22:22:56,851 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Got allocated containers 1
2017-05-11 22:22:56,851 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Assigned to reduce
2017-05-11 22:22:56,851 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Assigned container container_1494511663670_0004_01_000004 to attempt_1494511663670_0004_r_000000_0
2017-05-11 22:22:56,851 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: After Scheduling: PendingReds:0 ScheduledMaps:0 ScheduledReds:0 AssignedMaps:0 AssignedReds:1 CompletedMaps:2 CompletedReds:0 ContAlloc:3 ContRel:0 HostLocal:2 RackLocal:0
2017-05-11 22:22:56,858 INFO [AsyncDispatcher event handler] org.apache.hadoop.yarn.util.RackResolver: Resolved localhost to /default-rack
2017-05-11 22:22:56,859 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_r_000000_0 TaskAttempt Transitioned from UNASSIGNED to ASSIGNED
2017-05-11 22:22:56,859 INFO [ContainerLauncher #4] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Processing the event EventType: CONTAINER_REMOTE_LAUNCH for container container_1494511663670_0004_01_000004 taskAttempt attempt_1494511663670_0004_r_000000_0
2017-05-11 22:22:56,860 INFO [ContainerLauncher #4] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Launching attempt_1494511663670_0004_r_000000_0
2017-05-11 22:22:56,860 INFO [ContainerLauncher #4] org.apache.hadoop.yarn.client.api.impl.ContainerManagementProtocolProxy: Opening proxy : localhost:62244
2017-05-11 22:22:56,877 INFO [ContainerLauncher #4] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Shuffle port returned by ContainerManager for attempt_1494511663670_0004_r_000000_0 : 13562
2017-05-11 22:22:56,878 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: TaskAttempt: [attempt_1494511663670_0004_r_000000_0] using containerId: [container_1494511663670_0004_01_000004 on NM: [localhost:62244]
2017-05-11 22:22:56,878 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_r_000000_0 TaskAttempt Transitioned from ASSIGNED to RUNNING
2017-05-11 22:22:56,878 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.speculate.DefaultSpeculator: ATTEMPT_START task_1494511663670_0004_r_000000
2017-05-11 22:22:56,879 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskImpl: task_1494511663670_0004_r_000000 Task Transitioned from SCHEDULED to RUNNING
2017-05-11 22:22:57,854 INFO [RMCommunicator Allocator] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerRequestor: getResources() for application_1494511663670_0004: ask=1 release= 0 newContainers=0 finishedContainers=0 resourcelimit=<memory:5120, vCores:1> knownNMs=1
2017-05-11 22:22:58,772 INFO [Socket Reader #1 for port 62657] SecurityLogger.org.apache.hadoop.ipc.Server: Auth successful for job_1494511663670_0004 (auth:SIMPLE)
2017-05-11 22:22:58,784 INFO [IPC Server handler 6 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: JVM with ID : jvm_1494511663670_0004_r_000004 asked for a task
2017-05-11 22:22:58,784 INFO [IPC Server handler 6 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: JVM with ID: jvm_1494511663670_0004_r_000004 given task: attempt_1494511663670_0004_r_000000_0
2017-05-11 22:22:59,952 INFO [IPC Server handler 1 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: MapCompletionEvents request from attempt_1494511663670_0004_r_000000_0. startIndex 0 maxEvents 10000
2017-05-11 22:23:00,119 INFO [IPC Server handler 3 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Progress of TaskAttempt attempt_1494511663670_0004_r_000000_0 is : 0.0
2017-05-11 22:23:00,186 INFO [IPC Server handler 2 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Progress of TaskAttempt attempt_1494511663670_0004_r_000000_0 is : 0.0
2017-05-11 22:23:00,575 INFO [IPC Server handler 8 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Commit-pending state update from attempt_1494511663670_0004_r_000000_0
2017-05-11 22:23:00,576 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_r_000000_0 TaskAttempt Transitioned from RUNNING to COMMIT_PENDING
2017-05-11 22:23:00,576 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskImpl: attempt_1494511663670_0004_r_000000_0 given a go for committing the task output.
2017-05-11 22:23:00,578 INFO [IPC Server handler 10 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Commit go/no-go request from attempt_1494511663670_0004_r_000000_0
2017-05-11 22:23:00,578 INFO [IPC Server handler 10 on 62657] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskImpl: Result of canCommit for attempt_1494511663670_0004_r_000000_0:true
2017-05-11 22:23:00,595 INFO [IPC Server handler 7 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Progress of TaskAttempt attempt_1494511663670_0004_r_000000_0 is : 1.0
2017-05-11 22:23:00,599 INFO [IPC Server handler 0 on 62657] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Done acknowledgement from attempt_1494511663670_0004_r_000000_0
2017-05-11 22:23:00,601 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_r_000000_0 TaskAttempt Transitioned from COMMIT_PENDING to SUCCESS_CONTAINER_CLEANUP
2017-05-11 22:23:00,627 INFO [ContainerLauncher #5] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Processing the event EventType: CONTAINER_REMOTE_CLEANUP for container container_1494511663670_0004_01_000004 taskAttempt attempt_1494511663670_0004_r_000000_0
2017-05-11 22:23:00,627 INFO [ContainerLauncher #5] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: KILLING attempt_1494511663670_0004_r_000000_0
2017-05-11 22:23:00,627 INFO [ContainerLauncher #5] org.apache.hadoop.yarn.client.api.impl.ContainerManagementProtocolProxy: Opening proxy : localhost:62244
2017-05-11 22:23:00,640 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1494511663670_0004_r_000000_0 TaskAttempt Transitioned from SUCCESS_CONTAINER_CLEANUP to SUCCEEDED
2017-05-11 22:23:00,640 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskImpl: Task succeeded with attempt attempt_1494511663670_0004_r_000000_0
2017-05-11 22:23:00,641 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskImpl: task_1494511663670_0004_r_000000 Task Transitioned from RUNNING to SUCCEEDED
2017-05-11 22:23:00,641 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl: Num completed Tasks: 3
2017-05-11 22:23:00,641 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl: job_1494511663670_0004Job Transitioned from RUNNING to COMMITTING
2017-05-11 22:23:00,642 INFO [CommitterEvent Processor #1] org.apache.hadoop.mapreduce.v2.app.commit.CommitterEventHandler: Processing the event EventType: JOB_COMMIT
2017-05-11 22:23:00,700 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl: Calling handler for JobFinishedEvent
2017-05-11 22:23:00,701 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl: job_1494511663670_0004Job Transitioned from COMMITTING to SUCCEEDED
2017-05-11 22:23:00,702 INFO [Thread-69] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: We are finishing cleanly so this is the last retry
2017-05-11 22:23:00,702 INFO [Thread-69] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: Notify RMCommunicator isAMLastRetry: true
2017-05-11 22:23:00,702 INFO [Thread-69] org.apache.hadoop.mapreduce.v2.app.rm.RMCommunicator: RMCommunicator notified that shouldUnregistered is: true
2017-05-11 22:23:00,702 INFO [Thread-69] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: Notify JHEH isAMLastRetry: true
2017-05-11 22:23:00,702 INFO [Thread-69] org.apache.hadoop.mapreduce.jobhistory.JobHistoryEventHandler: JobHistoryEventHandler notified that forceJobCompletion is true
2017-05-11 22:23:00,702 INFO [Thread-69] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: Calling stop for all the services
2017-05-11 22:23:00,703 INFO [Thread-69] org.apache.hadoop.mapreduce.jobhistory.JobHistoryEventHandler: Stopping JobHistoryEventHandler. Size of the outstanding queue size is 0
2017-05-11 22:23:00,744 INFO [eventHandlingThread] org.apache.hadoop.mapreduce.jobhistory.JobHistoryEventHandler: Copying hdfs://localhost:9000/tmp/hadoop-yarn/staging/jonsonli/.staging/job_1494511663670_0004/job_1494511663670_0004_1.jhist to hdfs://localhost:9000/tmp/hadoop-yarn/staging/history/done_intermediate/jonsonli/job_1494511663670_0004-1494512560043-jonsonli-word+count-1494512580690-2-1-SUCCEEDED-default-1494512566744.jhist_tmp
2017-05-11 22:23:00,770 INFO [eventHandlingThread] org.apache.hadoop.mapreduce.jobhistory.JobHistoryEventHandler: Copied to done location: hdfs://localhost:9000/tmp/hadoop-yarn/staging/history/done_intermediate/jonsonli/job_1494511663670_0004-1494512560043-jonsonli-word+count-1494512580690-2-1-SUCCEEDED-default-1494512566744.jhist_tmp
2017-05-11 22:23:00,773 INFO [eventHandlingThread] org.apache.hadoop.mapreduce.jobhistory.JobHistoryEventHandler: Copying hdfs://localhost:9000/tmp/hadoop-yarn/staging/jonsonli/.staging/job_1494511663670_0004/job_1494511663670_0004_1_conf.xml to hdfs://localhost:9000/tmp/hadoop-yarn/staging/history/done_intermediate/jonsonli/job_1494511663670_0004_conf.xml_tmp
2017-05-11 22:23:00,798 INFO [eventHandlingThread] org.apache.hadoop.mapreduce.jobhistory.JobHistoryEventHandler: Copied to done location: hdfs://localhost:9000/tmp/hadoop-yarn/staging/history/done_intermediate/jonsonli/job_1494511663670_0004_conf.xml_tmp
2017-05-11 22:23:00,802 INFO [eventHandlingThread] org.apache.hadoop.mapreduce.jobhistory.JobHistoryEventHandler: Moved tmp to done: hdfs://localhost:9000/tmp/hadoop-yarn/staging/history/done_intermediate/jonsonli/job_1494511663670_0004.summary_tmp to hdfs://localhost:9000/tmp/hadoop-yarn/staging/history/done_intermediate/jonsonli/job_1494511663670_0004.summary
2017-05-11 22:23:00,805 INFO [eventHandlingThread] org.apache.hadoop.mapreduce.jobhistory.JobHistoryEventHandler: Moved tmp to done: hdfs://localhost:9000/tmp/hadoop-yarn/staging/history/done_intermediate/jonsonli/job_1494511663670_0004_conf.xml_tmp to hdfs://localhost:9000/tmp/hadoop-yarn/staging/history/done_intermediate/jonsonli/job_1494511663670_0004_conf.xml
2017-05-11 22:23:00,809 INFO [eventHandlingThread] org.apache.hadoop.mapreduce.jobhistory.JobHistoryEventHandler: Moved tmp to done: hdfs://localhost:9000/tmp/hadoop-yarn/staging/history/done_intermediate/jonsonli/job_1494511663670_0004-1494512560043-jonsonli-word+count-1494512580690-2-1-SUCCEEDED-default-1494512566744.jhist_tmp to hdfs://localhost:9000/tmp/hadoop-yarn/staging/history/done_intermediate/jonsonli/job_1494511663670_0004-1494512560043-jonsonli-word+count-1494512580690-2-1-SUCCEEDED-default-1494512566744.jhist
2017-05-11 22:23:00,810 INFO [Thread-69] org.apache.hadoop.mapreduce.jobhistory.JobHistoryEventHandler: Stopped JobHistoryEventHandler. super.stop()
2017-05-11 22:23:00,812 INFO [Thread-69] org.apache.hadoop.mapreduce.v2.app.rm.RMCommunicator: Setting job diagnostics to
2017-05-11 22:23:00,812 INFO [Thread-69] org.apache.hadoop.mapreduce.v2.app.rm.RMCommunicator: History url is http://localhost:19888/jobhistory/job/job_1494511663670_0004
2017-05-11 22:23:00,818 INFO [Thread-69] org.apache.hadoop.mapreduce.v2.app.rm.RMCommunicator: Waiting for application to be successfully unregistered.
2017-05-11 22:23:01,821 INFO [Thread-69] org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator: Final Stats: PendingReds:0 ScheduledMaps:0 ScheduledReds:0 AssignedMaps:0 AssignedReds:1 CompletedMaps:2 CompletedReds:0 ContAlloc:3 ContRel:0 HostLocal:2 RackLocal:0
2017-05-11 22:23:01,822 INFO [Thread-69] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: Deleting staging directory hdfs://localhost:9000 /tmp/hadoop-yarn/staging/jonsonli/.staging/job_1494511663670_0004
2017-05-11 22:23:01,825 INFO [Thread-69] org.apache.hadoop.ipc.Server: Stopping server on 62657
2017-05-11 22:23:01,828 INFO [IPC Server listener on 62657] org.apache.hadoop.ipc.Server: Stopping IPC Server listener on 62657
2017-05-11 22:23:01,828 INFO [TaskHeartbeatHandler PingChecker] org.apache.hadoop.mapreduce.v2.app.TaskHeartbeatHandler: TaskHeartbeatHandler thread interrupted
2017-05-11 22:23:01,828 INFO [IPC Server Responder] org.apache.hadoop.ipc.Server: Stopping IPC Server Responder
End of LogType:syslog
node
Usage: yarn node [options]
| COMMAND_OPTIONS | Description |
|---|---|
| -all | Works with -list to list all nodes. |
| -list | Lists all running nodes. Supports optional use of -states to filter nodes based on node state, and -all to list all nodes. |
| -states <States> | Works with -list to filter nodes based on input comma-separated list of node states. |
| -status <NodeId> | Prints the status report of the node. |
Prints node report(s)
queue
Usage: yarn queue [options]
| COMMAND_OPTIONS | Description |
|---|---|
| -help | Help |
| -status <QueueName> | Prints the status of the queue. |
Prints queue information
version
Usage: yarn version
Prints the Hadoop version.
localhost:~ jonsonli$ yarn version
Hadoop 2.7.3
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on 2016-08-18T01:41Z
Compiled with protoc 2.5.0
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /Users/jonsonli/Bigdata/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar
Administration Commands
Commands useful for administrators of a Hadoop cluster.
daemonlog
Usage:
yarn daemonlog -getlevel <host:httpport> <classname> yarn daemonlog -setlevel <host:httpport> <classname> <level>
| COMMAND_OPTIONS | Description |
|---|---|
| -getlevel <host:httpport><classname> | Prints the log level of the log identified by a qualified <classname>, in the daemon running at <host:httpport>. This command internally connects to http://<host:httpport>/logLevel?log=<classname> |
| -setlevel <host:httpport> <classname> <level> | Sets the log level of the log identified by a qualified <classname> in the daemon running at <host:httpport>. This command internally connects to http://<host:httpport>/logLevel?log=<classname>&level=<level> |
Get/Set the log level for a Log identified by a qualified class name in the daemon.
Example: $ bin/yarn daemonlog -setlevel 127.0.0.1:8088 org.apache.hadoop.yarn.server.resourcemanager.rmapp.RMAppImpl DEBUG
resourcemanager
Usage: yarn resourcemanager [-format-state-store]
| COMMAND_OPTIONS | Description |
|---|---|
| -format-state-store | Formats the RMStateStore. This will clear the RMStateStore and is useful if past applications are no longer needed. This should be run only when the ResourceManager is not running. |
Start the ResourceManager
rmadmin
Usage:
yarn rmadmin [-refreshQueues]
[-refreshNodes]
[-refreshUserToGroupsMapping]
[-refreshSuperUserGroupsConfiguration]
[-refreshAdminAcls]
[-refreshServiceAcl]
[-getGroups [username]]
[-transitionToActive [--forceactive] [--forcemanual] <serviceId>]
[-transitionToStandby [--forcemanual] <serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId1> <serviceId2>]
[-getServiceState <serviceId>]
[-checkHealth <serviceId>]
[-help [cmd]]
| COMMAND_OPTIONS | Description |
|---|---|
| -refreshQueues | Reload the queues’ acls, states and scheduler specific properties. ResourceManager will reload the mapred-queues configuration file. |
| -refreshNodes | Refresh the hosts information at the ResourceManager. |
| -refreshUserToGroupsMappings | Refresh user-to-groups mappings. |
| -refreshSuperUserGroupsConfiguration | Refresh superuser proxy groups mappings. |
| -refreshAdminAcls | Refresh acls for administration of ResourceManager |
| -refreshServiceAcl | Reload the service-level authorization policy file ResourceManager will reload the authorization policy file. |
| -getGroups [username] | Get groups the specified user belongs to. |
| -transitionToActive [–forceactive] [–forcemanual] <serviceId> | Transitions the service into Active state. Try to make the target active without checking that there is no active node if the –forceactive option is used. This command can not be used if automatic failover is enabled. Though you can override this by –forcemanual option, you need caution. |
| -transitionToStandby [–forcemanual] <serviceId> | Transitions the service into Standby state. This command can not be used if automatic failover is enabled. Though you can override this by –forcemanual option, you need caution. |
| -failover [–forceactive] <serviceId1> <serviceId2> | Initiate a failover from serviceId1 to serviceId2. Try to failover to the target service even if it is not ready if the –forceactive option is used. This command can not be used if automatic failover is enabled. |
| -getServiceState <serviceId> | Returns the state of the service. |
| -checkHealth <serviceId> | Requests that the service perform a health check. The RMAdmin tool will exit with a non-zero exit code if the check fails. |
| -help [cmd] | Displays help for the given command or all commands if none is specified. |
Runs ResourceManager admin client
转载于:https://www.cnblogs.com/licheng/p/6832450.html