编程和学习python,最后快速上手。能写小工具,写自动化用例这类要求对鹅厂的测试人员来说都是一些基础的必备素质,但是一个优秀的测试,也是有着一颗开发完美测试工具的心的。但是罗马不是一天构建成,特别是业务测试人员,编写代码水平的提升更不可能一蹴而就,立竿见影,因此更需要我们在平常的工作中,通过一点一滴的积累,来达成从量变到质变的过程飞跃,不断的打磨自己的测试工具,提升测试效率。
一:基础语法篇
1、python最为推荐的三元表达式:(y,x)[x > y]
三元表达式:condition_is_true if condition else condition_is_false
x,y =5,7 if x > y: print x else: print y print x if x > y else y print (y,x)[x > y]
2、python最推荐的字符串格式化方法:str.format()
format方法的常见四种用法:
#用法1:使用位置符号
print "{0} {1}".format("hello", "world")
#用法2:使用名称
print("网站名:{name}, 地址 {url}".format(name="hello", url="www.world.com"))
#用法3:使用格式化元组
dic_site = {"name": "hello", "url": "www.world.com"}
print("网站名:{name}, 地址 {url}".format(**dic_site))
list_site = ['hello', 'www.runoob.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(list_site)) # "0" 是必须的
#用法四:使用对象
class Customer(object):
def __init__(self, name,age):
self.name = name
self.age = age
def __str__(self):
return 'Customer({self.name},{self.age})'.format(self=self)
print str(Customer('loleina',27))
相比较之前常用的%操作符,format函数更灵活,参数的顺序与格式化的顺序可以不一致,还支持传各种类型的参数。
3、python不推荐使用type进行类型检查
常用的有2个函数可以对数据类型进行检查:type和isinstance方法。
A : 基于内建的基本类型,比如types.ListType,types.BooleanType,可以用type。
B: 基于内建类型的扩展类,type函数不能返回准确的结果。使用isinstance更精准。
下面这个例子,对象int_a,使用type函数会认为不是int类型,使用isinstance则返回True
import types class UserInt(int): def __init__(self,value): self.value = value int_a = UserInt(1) if type(int_a) is types.IntType: print 'is IntType' else: print 'not IntType' print isinstance(int_a,int)
C: 古典类中,所有类的实例的type值都是相等的。因为所有类的实例的type函数都是返回<type 'instance'>.
class A: pass class B: pass a = A() b = B() print type(a) == type(b)
4、使用enumerate()获取序列LIST迭代的索引和值
对序列进行迭代并获取序列中的所有元素进行处理是一个非常基础的场景。有N种实现的方法。最常用的方法如下:
lol = [1,2,3,4,5]
for i in range(len(lol)):
print lol[i]
但是python最推荐的是使用enumerate()获取序列迭代的索引和值,这个函数是在python2.3引入的。它还具有一定的惰性,每次仅在需要的时候才产生一个(index,item)对。
for i,e in enumerate(lol):
print lol[i]
e = enumerate(lol)
print e.next()
print e.next()[1]
但是对于字典的迭代循环,enumerate函数并不合适,还是应该使用iteritems()方法。
5、is 和 == 的区别
is表示的是对象标识符,而 == 表示的意思是相等,两者不是一个东西。is的作用是用来检查对象的标识符是不是一致的,也就是检查两个对象在内存中是否是拥有同一个空间,不适合来判断字符串是否相等。
a = 1
b = 1
print a == b
print a is b
list_a =[0,1,2,3,4]
list_b =[0,1,2,3,4] print list_a == list_b print list_a is list_b
这份代码运行完结果是怎么样的呢?
True
True
True
False
6、i+=1不等于++i
在c++的代码里,有++i,i++两种表示i=i+1的表达(两个表达式有差异),但是在python中没有i++,这样的写法解释器会直接报错,但是有++i,但是++i不等于i+=1,python解释器会将这个操作解释为+(+i),其中+表示正数符号。比如以下的代码,会无限循环的打印1.而不是遍历mylist的所有元素。
i =0
myslist =[1,2,3,4,5]
while i < len(myslist):
print myslist[i]
++i
7、python异常遵循的几个基本原则
python的异常是由关键字try,except,else,finally 组成的,基本语法如下所示:
try:
<statements> # Run this main action first
except <name1>:
<statements> #当 try中发生name1的异常时处理
except (name2, name3):
<statements> #当try中发生name2或name3中的某个异常的时候处理
except <name4> as <data>: <statements> #当 try中发生name4的异常时处理,并获取对应实例 except: <statements> #其他异常发生时处理 else: <statements> #没有异常发生时执行 finally: <statements> #不管有没有异常发生都会
异常处理流程如下:
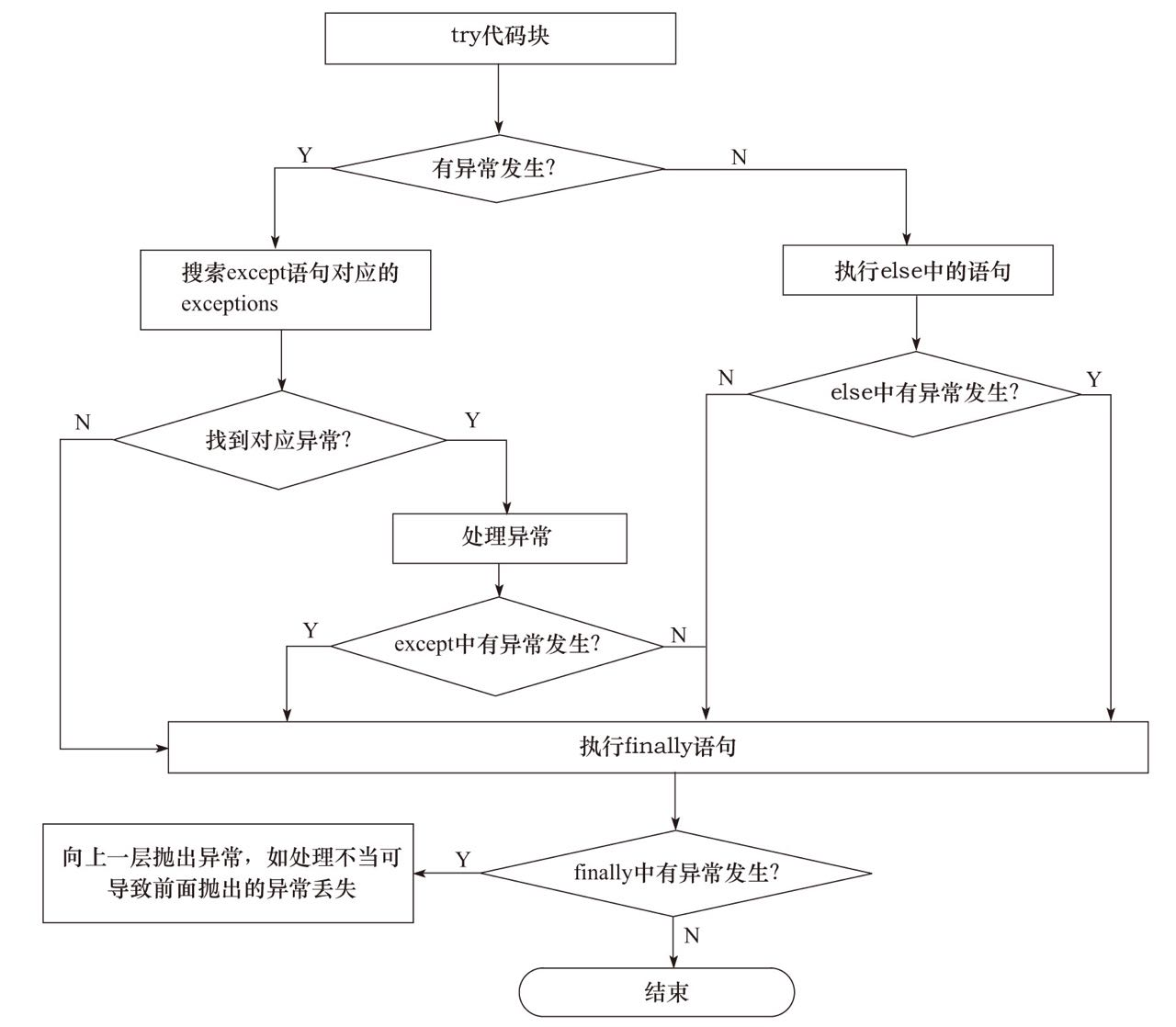
原则1:注意异常的粒度,不推荐在try中放入过多的代码,会导致抛出的异常很难定位问题。
原则2:谨慎使用单独的except语句处理所有异常,最好能定位到具体的异常。不推荐使用except Exception和except StandardError来捕获异常,会把真实的错误掩盖,给debug造成一定的困扰,如下:
import sys
try:
b =0
print a/b
except:
sys.exit("ZeroDivisionError")
这个会一直报ZeroDivisionError,而实际上问题是a没有初始化。因为捕获异常单独用except导致。改正如下:
import sys
try:
b =0
print a/b
except ZeroDivisionError:
sys.exit("ZeroDivisionError")
这样异常就能正常打印:
Traceback (most recent call last):
File "E:/tools/loleina test/test2.py", line 7, in <module>
print a/b
NameError: name 'a' is not defined
如果在某些情况下不得不使用单独的except语句,最好能使用raise语句将异常抛出向上层传递
原则3:注意在合适的层次处理异常。一个原则就是如果异常能够在捕获的时候处理,那么就应该及时处理,不能处理就应该以适合的方式向上抛出。遇到异常不分好歹就向上层抛出是非常不明智的,向上层传递的时候需要警惕异常被丢失的情况。
原则4:不推荐在finally中使用return语句进行返回,这不仅会带来误解还可能引入非常严重的错误。如下个例子:
def FinallyTest():
print 'i am starting------'
while True:
try:
print "I am running"
raise IndexError("r")#抛出异IndexError异常
except NameError,e:
print 'NameError happended %s',e break finally: print 'finally executed' return 'loleina'if __name__ == "__main__": print FinallyTest()
i am starting------
I am running
finally executed
loleina
上面这个例子try中捕获到抛出了异常,按常理程序应该输出而实际却没有任何异常提示,丢失了IndexError。因为当try块中发生异常时,如果在except语句中找不到对应的异常处理,异常将会被临时保存起来,执行完finally完再被抛出,但是如果finally语句产生了新的异常或者执行了return或者break语句,那么临时保存的异常将会被丢失,从而导致异常被屏蔽。
8、常量None的认识
常量None的特殊表现体现在它既不是0,False,也不是空字符串,它就是一个空对象,其数据类型就是NoneType,遵循单例模式,是唯一的,不能被创建的None对象。所有赋值是None的变量都是相等。
print None ==0
print None ==''
print None ==False
a = None
b = None
print id(a)
print id(b)
print a == b
运行结果如下:
False
False
False
1759571064
1759571064
True
常见的一个错误用法就是把None当成空,以下是一个常见的错误示例。对列表是否为空进行判断:
list1=[]
if list1 is not None:
print "list1 is :{0}".format(list1)
else:
print "list1 is empty"
预期是打印list1 is empt, 实际是打印list1 is :[]。正确的写法如下:
list1=[]
if list1:
print "list1 is :{0}".format(list1)
else:
print "list1 is empty"
if list1 在调用的过程中会调用内部方法__nonzero__()来判断变量list1的是否为空并返回结果。如果一个对象没有自定义改方法,python将获取__len__()方法进行判断。如果一个类里既没有定义__nonzero__()也没有定于__len__(),那么该类的实例用if来判断就是空。字典判断为空是可以
用if的,用户自定义的类要谨慎使用。
9、列表解析初始化列表
现在需要对一个list的元素做去前后空格的操作,一般会怎么写的呢?
words = [' Are', ' abandon', 'Passion','Business',' fruit ','quit']
newlist = []
for i,value in enumerate(words):
newlist.append(value.strip())
print newlist
没错,这段程序并没有什么问题,但是优先推荐使用列表解析的方法来实现。列表解析的语法为:[expr for iter_item in iterable if cond_expr]. 它迭代 iterable中的每一个元素,当条件cond_expr满足的时候,便根据表达式expr 计算值在放入到新的列表中,直到返回最终整个列表。
上面的示例就可以简写为:
words = [' Are', ' abandon', 'Passion','Business',' fruit ','quit']
newlist=[value.strip() for value in words ]
print newlist
使用列表解析使得代码更简洁,直观清晰外,还提升了性能。因为生成普通list时调用append函数,会增加额外时间的开销,特别是对于大数据的处理。但是对于大数据的处理,列表解析不一定是最佳选择,过多的内存消耗可能会导致MemoryError。还有2个常见的用法,列表中的
expr 可以是简单的表达式,也可以是一个函数。iterable 可以是一个迭代 对象,也可以是文件句柄。
def f(v):
if v%2 == 0:
v = v**2
else:
v = v+1
return v #表达式可以是函数 print [f(v) for v in [2,3,4,-1] if v>0] [4, 4, 16] #也可以是普通计算 print [v**2 if v%2 ==0 else v+1 for v in [2,3,4,-1] if v>0] [4, 4, 16] #文件句柄可以当做可迭代对象 fh = open("test.txt", "r") result = [i for i in fh if "abc" in i] print result
二、良好的编码习惯
1、尽量转换为浮点数类型再做除法
现在如果要计算数字 1,3,4的平均值,在python3之前会怎么做呢?
print (1+3+4)/3 输出:2
显然这不是我们要的正确结果,在python3之前,当除法运算中的两个操作数都是整数的时候,其返回值也为整数,运算结果将直接截断,从而在实际应用中造成潜在的误差。因此推荐的方法就是当涉及除法运算的时候尽量先将操作数转换成浮点数再做运算。
print float(1+3+4)/3
在python3中这个问题已经不存在了,在python3之前的版本也可以通过from __future__ import division 机制使整数除法不再被截断,即使不做浮点类型转换,也不会出问题。那下面这段代码运行的次数是多少次呢?
i = 1 while i!=1.5: i = i+0.1 print i
答案不是5次,是无限次。因为在计算机的世界里,浮点数的存储规则决定了不是所有的浮点数都能准确的表示,有些是不准确的,只能无限接近。比如0.1.如果转换成二进制则是0.000110011001...后面就是1001无限次循环,在内存中根据浮点数的规定,多余的部分直接截断,因此当循环到第5次的时候i的实际值为1.500000000000000004,显然表达式为True,循环陷入无终止状态。如果计算对精度要求较高,可以使用Decimal来进行处理或者将浮点数尽量扩大为整数,计算完毕之后再转换回去。修改成以下这样就可以:
i = 1 while Decimal(i).quantize(Decimal('0.0'))!=1.5: i = i+0.1 print i
2、编写函数的4个基本原则
原则一:尽量短小,嵌套层次不宜过深。函数中需要用到if,else,while,for等循环语句的地方,尽量控制在3层以内。
原则二:函数申明应该做到合理,简单,便于使用,函数名能正确放映其功能,参数不能太多。
原则三:函数参数设计应该考虑向下兼容。常用的方法就是加默认参数。
原则四:一个函数只做一件事,保证函数语句粒度的一致性。
3、充分利用Lazy evaluation(延迟计算)的特性。
延迟计算,指的是仅仅在真正需要执行的时候才计算表达式的值。这样能避免不必要的计算,带来性能上的提升。
from time import time
t =time()
abbreviations = ['cf.', 'e.g.', 'ex.', 'etc.', 'fig.', 'i.e.', 'Mr.', 'vs.']
for i in xrange (1000000):
for w in ('Mr.', 'Hat', 'is', 'chasing', 'the', 'black', 'cat', '.'):
# if w in abbreviations: if w[-1] == '.' and w in abbreviations: pass print "total run time:" print time()-t
如果用# 注释的代码运行,耗时total run time:1.13800001144。而使用延迟计算,耗时0.850000143051
三:小改动,性能的大提升
1、python最为推荐的数据交换方法:使用类似 x,y = y,x
x,y=1,2 temp = x x = y y = temp print x,y
直接改写成
x,y=1,2 x,y = y,x print x,y
这样写的不仅代码看上去更简洁,而且性能更优
from timeit import Timer
print Timer('x,y = y,x','x = 1;y = 2').timeit()
print Timer('temp = x; x =y; y =temp','x = 1;y = 2').timeit()
测试结果: 0.020009818741 0.0246657380107
2、连接字符串应该优先使用join而不是+.
这2者的主要差异是在性能上,如下示例:
import timeit
count=1000000
#生成测试所需要的字符数组,#100000为字符串连接的数目,
strlist=["it is a long value string will not keep in memory" for n in range(count)]
#使用join方法连接strlist中的元素并返回字符串
def join_test():
return ''.join(strlist)
#使用进行字符串连接
def plus_test():
result = ''
for i,v in enumerate(strlist):
result= result+ v
return result
if __name__ == '__main__':
jointimer = timeit.Timer("join_test()","from __main__ import join_test")
print jointimer.timeit(number = 100)
plustimer = timeit.Timer("plus_test()","from __main__ import plus_test")
print plustimer.timeit(number = 100)
生成的strlist的count值越大,两者的时间差能差别上百倍。在超过1000时性能差就开始有明显的差异。
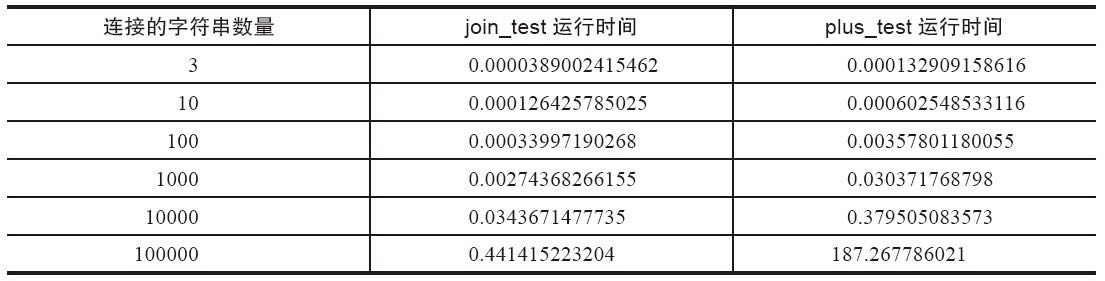
这是因为在使用join方法连接字符串的时候,会首先计算需要申请的总的内存空间,然后一次性申请所需的内存并将字符序列中的每一个元素复制到内存中去,时间复杂度是O(n)。而使用+连接字符串的时候,就完全不一样了。因为字符串是不可变对象,每执行一次+操作就需要在内存中申请一块新的内存空间,并将上次的操作结果和本次的操作数复制到新的内存空间,在N个字符串连接的过程中,会产生N-1个中间结果,需要申请N-1次内存,大大影响了执行效率,N越大,对内存的申请和复制的次数越多。+的效率就越低,字符串的连接时间复杂度接近O(n²)。