百度作为国内第一个成立深度学习研究院(Institute of Deep Learning,IDL),并且也是国内第一个自研深度学习框架的企业,在WAVE SUMMIT深度学习开发者峰会上对自动化深度学习网络结构设计AutoDL Design系统进行了全面开源。
在人工智能(Artificial Intelligence,AI)领域占有重要一席之地的深度学习(Deep Learning)技术,在近些年来得到了高速的发展和广泛的应用。无论是在学术界还是在工业界,人脸识别(Face Recognition)、语音识别(Automatic Speech Recognition,ASR)、机器翻译(Machine Translation,MT),还是各类游戏机器人(如,AlphaGo)、各种智能音箱,无不体现着深度学习技术的强大能力。深度学习技术的背后是深度神经网络(Deep Neural Network,DNN),尝试设计效果更好、计算速度更快的网络结构是科学家和工程师们一直追求的目标。
百度基于自研的PaddlePaddle深度学习平台,以及PARL强化学习框架,进行了自动化网络结构设计的探索和尝试,并且开源了其中关于自动化网络结构设计的源代码和对应的预训练模型,将AutoDL这一前沿技术以更低的成本展示给业界和各位开发者,大幅降低了该类技术的上手门槛。
项目地址:https://github.com/PaddlePaddle/AutoDL/tree/master/AutoDL%20Design
论文地址:https://arxiv.org/abs/1902.00873
自动化网络结构设计是什么
传统的神经网络的结构设计是由人类手工完成的。研究者们通过自身的经验,通过尝试添加更多不同类型的层(变深)和在层与层之间添加更多的连接(变复杂),获得不同的神经网络结构,并且用它们不断进行模型训练和优中选优,获得了一代又一代有鲜明特色的一批网络结构,在一些典型的公开数据集上收获了很好的模型效果。
随着对典型神经网络结构研究的深入,人们开始希望能够用自动化的方式探索和设计出新型的网络结构,取代传统的“手工设计-尝试-修改-尝试”的较为复杂和费时费力的过程,于是“自动化网络结构设计”应运而生。理想状态下的AutoDL技术,只需要使用者提供一份数据集,整个系统就可以根据数据集自身,不断尝试不同类型的网络结构和连接方式,训练若干个神经网络模型,逐步进行自动化反复迭代和尝试,最后产出一个终版模型。
自动化网络结构设计的技术难点
目前已知的在各个领域中广泛应用的各种神经网络,都可以看成由若干个层(layer)或者由操作(op)组成的。每个独立的层或者是操作都分别完成一个相对简单的计算,如乘法(multiplication)、卷积(convolution)、池化(pooling)等等。而一个神经网络可以包括几个、几十个甚至上百个或者更多的这些组件,并且组件之间的连接方式也并不是类似于一条直线,中间会包含有多种分叉和合并,构成一个有向无环图(Directed Acyclic Graph,DAG)。因此试图通过类似暴力(Brute Force)的方法来尝试大量的新的网络结构是不现实的。
为了有效减少计算量,也可以采用部分固定网络范式的方式,即将网络结构中的整体框架或者层与层之间的连接方式固定,而用自动化的方式选择每个层的类型。这种方式的确可以缩小搜索空间,但是在一定程度上仍然严重依赖于人们对现有已知的优秀的网络结构的认知程度,也就限制了更多更新种类结构的发展。
AutoDL Design
百度的研究员和工程师们所使用的自动网络结构搜索的方法,目标是找到合适的“局部结构”。即,首先搜索得到一些合适的局部结构作为零件,然后类似流行的Inception结构那样,按照一定的整体框架堆叠成为一个较深的神经网络。
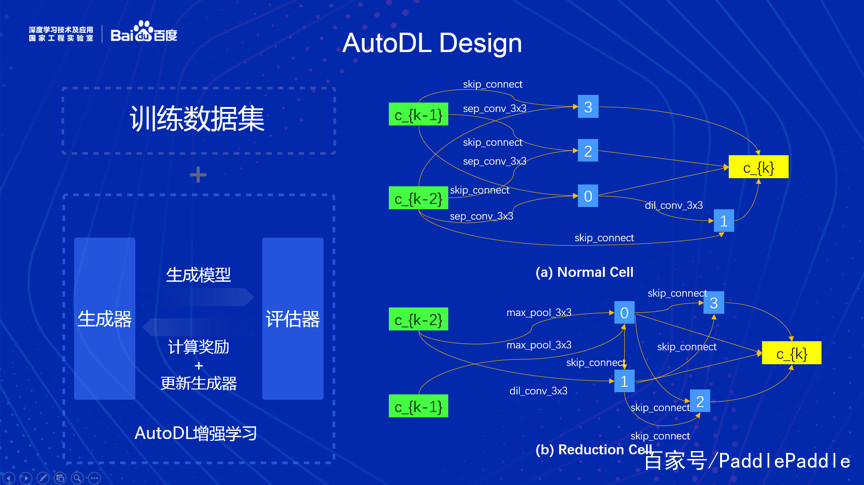
整个搜索过程,是基于增强学习(Reinforcement Learning,RL)思想设计出来的。因此很自然地包括了以下两个部分:第一个部分是生成器,对应增强学习中的智能体(agent),用于采样(sample),生成网络结构;第二个部分是评估器,用于计算奖励(reward),即用新生成的网络结构去训练模型,以模型的准确率(accuracy)或者是损失函数(loss function)返回给生成器。
第一部分,生成器:
生成器内部维护了一个循环神经网络(Recurrent Neural Network,RNN),更准确地说是一个长短时记忆网络(Long Short-Term Memory,LSTM)。它的输入始终是0,所以这个RNN的输出完全由其内部的状态所决定。由于需要生成的是一个神经网络的结构,是有向无环图,因此需要生成一系列的点(vertex)和边(edge)。有向无环图中的点对应神经网络中的层或者是操作,需要事先预置一些可供选择的常见操作,如卷积、池化等等。有向无环图中的边对应神经网络中的连接,有一些层会连接到多个层,有一些层也会接收多个层的输出作为自己的输入。
从代码层面或者从实现层面来说,生成器的输出包括两部分,第一个部分是id序列,每个id表示神经网络中的层或者是操作。第二个部分是邻接矩阵(Adjacent Matrix),用来表示各个层或者是操作之间的关联关系,邻接矩阵中只有0或者1,表示节点之间没有连接或者有连接。
生成器内部使用的是LSTM单元(cell),不过对单元的输出进行了一些额外的处理:针对生成id序列的部分,输出会先经过一个全连接层(Fully Connected layer,FC),然后经过一个多项分布(multinomial)的采样;针对生成邻接矩阵的部分,输出也是先经过一个全连接层,然后经过一个0-1分布(Bernoulli)的采样。
第二部分,评估器:
评估器的输入是由前述生成器生成的层或者操作的序列,以及对应的邻接矩阵。评估器首先要根据输入,构建出一个神经网络。注意生成器输出的很可能不是连通图(connected),所以还需要将所有没有出度(out degree)的节点都连接在一起。
随后,评估器会使用指定的数据进行训练,不过由于需要尝试的不同种类的网络结构太多,这里的训练不会像常规的训练那样进行非常多的轮数(epoch)直至收敛(convergence),而是会采用提前终止(early stop)策略,只进行很少的轮数的训练,然后将损失函数值作为奖励返回给生成器。生成器随后使用Policy Gradient的方式对其内部的RNN进行更新。
由于我们的目标任务和常见的增强学习的任务稍有不同(我们同时要输出id序列和邻接矩阵),因此对于损失函数的计算也稍有不同:需要把id序列的采样前和采样后的结果,以及邻接矩阵的采样前和采样后的结果都用来参与计算。
下图的左边,展示了整个系统的大致框架。右边展示了部分搜索出来的局部结构。
两份礼物
我们选择将预训练模型和代码全部进行公开化的发布,希望可以激发更多人的兴趣与灵感,也希望通过开源的方式和大家一起共同成长和进步。在AutoDL这个大的课题上,我们同时还做了自动化的模型压缩(Model Compression)、迁移(Transfer)以及生成(Generative Model,Automated GAN)的工作,后续有计划将这些技术逐步进行开源。
本次的发布,主要包括下面两个部分(所有的内容都在PaddlePaddle/AutoDL仓库下):
第一个,是用AutoDL Design方法生成的一系列神经网络,以及使用CIFAR10数据在其上训练出来的一共6个模型,包括了网络结构以及对应的权重。因此每一位业内同行或者是有兴趣的研究者都可以很容易使用PaddlePaddle以及公开的CIFAR10数据,在这6个模型上进行推理(inference)以及模型融合,获得超过98%的准确率。
第二个,是上面所描述的生成器和评估器的开源代码。如本文开头所述,该源代码使用了完全由百度自己研发的PaddlePaddle平台和PARL框架。代码中附带有中文文档,以及一些方便大家快速运行的更简单的小demo(例如,以“RNN生成多少个1”作为奖励,可以快速验证整个框架的正确性)。大家可以下载、安装和运行,尝试生成属于自己的、全新的神经网络结构。
再次感谢大家的关注,也欢迎更多开发者参与进来,一起创新,共同成长。