版权声明:本文为博主原创文章,未经博主允许不得转载 https://blog.csdn.net/g_optimistic/article/details/90058038
创建项目:
scrapy startproject scrapyProject创建项目下的小爬虫:
scrapy genspider s_tencent careers.tencent.com目录
1.spiders文件夹下的s_tencent.py
# -*- coding: utf-8 -*-
import scrapy
import json
from scrapyProject.items import ScrapyprojectItem
class STencentSpider(scrapy.Spider):
name = 's_tencent'
allowed_domains = ['careers.tencent.com']
start_urls = []
for page in range(1, 62):
url = 'https://careers.tencent.com/tencentcareer/api/post/Query?keyword=python&pageIndex=%s&pageSize=10' % page
start_urls.append(url)
def parse(self, response):
# 读response的页面信息
content = response.body.decode('utf-8')
# json字符串转换为python格式
data = json.loads(content)
job_list = data['Data']['Posts']
for job in job_list:
# 每条职位都需要放入单独的ScrapyprojectItem类中
item = ScrapyprojectItem()
name = job['RecruitPostName'] # 工作名称
country = job['CountryName'] # 工作国家
duty = job['Responsibility'] # 工作职责
# 使用数据模型存数据的时候,不要用.语法
item['name'] = name
item['duty'] = duty
item['country'] = country
yield item # 生成一条数据就挂起,传给pipeline
# info=name+country+duty+'\n'
# info = {
# "name": name,
# "country": country,
# "duty": duty,
# }
# with open('job.txt', 'a', encoding='utf-8') as fp:
# fp.write(str(info)+'\n')
2.item.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
# 声明字段的
class ScrapyprojectItem(scrapy.Item):
# define the fields for your item here like:
# 定义需要的字段
name = scrapy.Field()
duty = scrapy.Field()
country=scrapy.Field()
3.pipelines.py
# -*- coding: utf-8 -*-
import json
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
# pipelines 管道 把item的字段传出到spider
class ScrapyprojectPipeline(object):
def process_item(self, item, spider):
# pipeline 作用是:存储数据 可以写入文件,也可以写入数据库
fp = open('tencent_job.txt', 'a', encoding='utf-8')
json.dump(dict(item), fp, ensure_ascii=False)
return item
4.settings.py
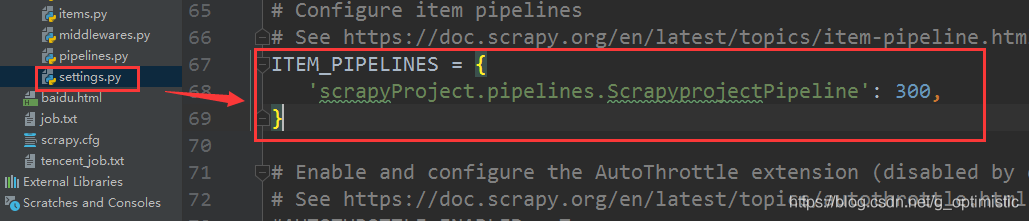
5.运行程序
scrapy crawl s_tencent