环境:
python3.6 + jupyter notebook
使用的库:
1.requests 一个HTTP客户端库,用来获取web网页,用法详见 requests文档
2.BeautifulSoup 可以从HTML或XML文件中提取数据,用法详见:beautifulsoup官方文档
具体实现
1.获取root页面的HTML代码
原页面:
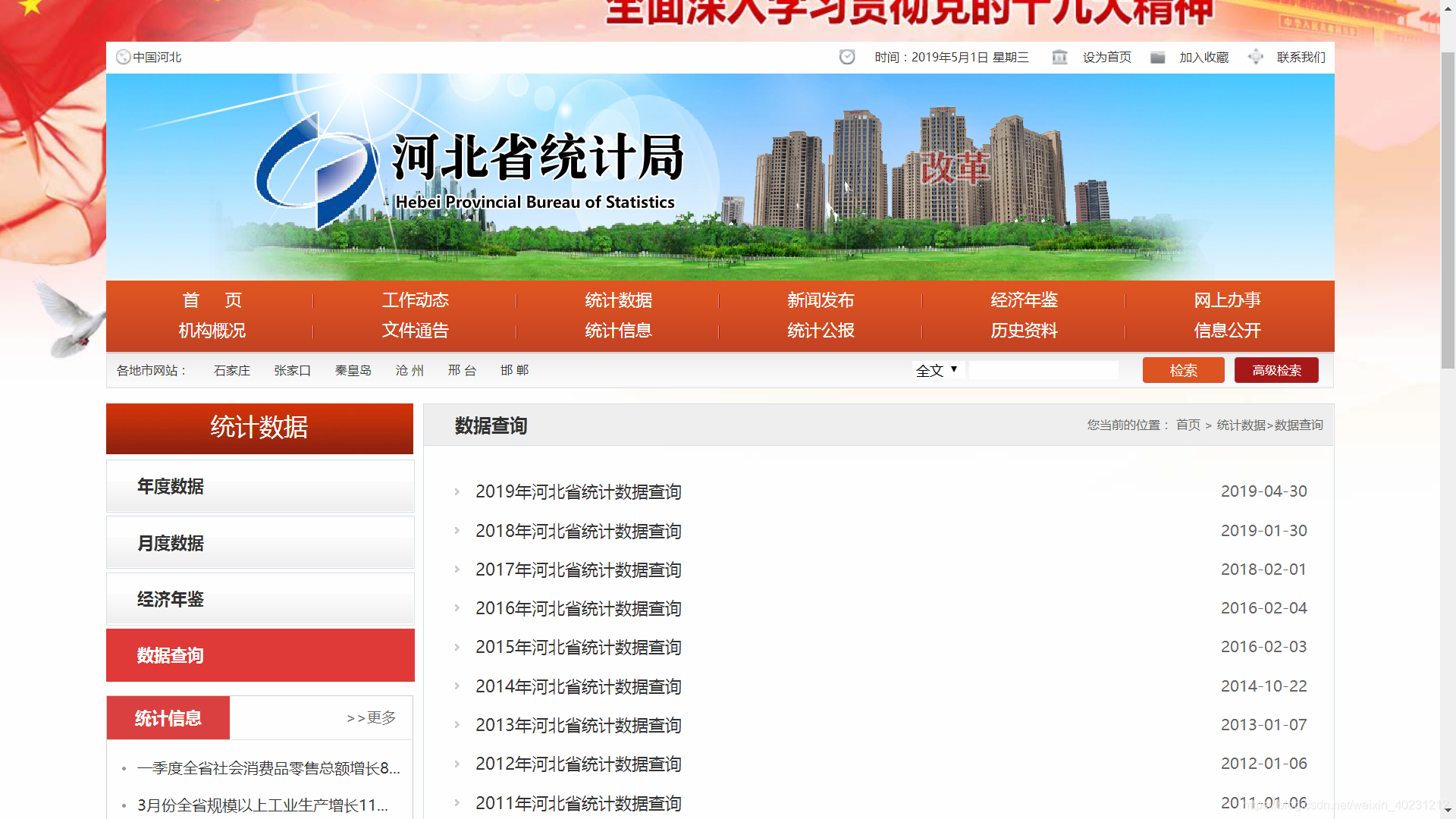
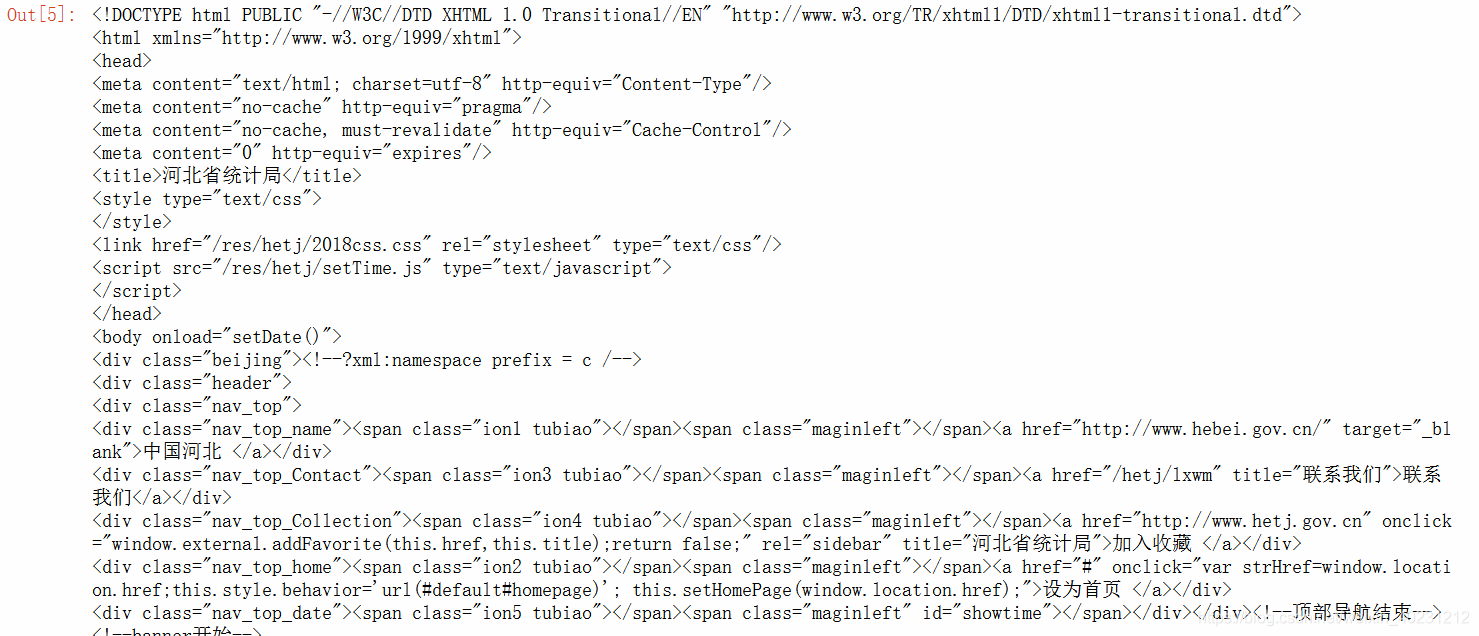
import requests
from bs4 import BeautifulSoup
target = 'http://www.hetj.gov.cn/hetj/tjsj/sjcx/'
req = requests.get(url=target)
# html = req.text
html=req.content #去除乱码
bf = BeautifulSoup(html,"lxml")#不加lmxl会有warning
bf效果 就是把html代码完整读出来:
2. 获取子URL
我们要进入这些web页面

所以需要找到这些页面在html代码中的共同点, 利用正则表达式进行URL匹配与提取;最后把提取出的子URL放入list中。
其中,由于2011-2013年数据统计形式与之后的不同,所以需要分两类处理。
import re
#利用正则表达式进行匹配、提取
subroot = bf.find_all('a',href={re.compile(r"/hetj/tjsj/sjcx/(\s\w+)?"),
re.compile(r"http://www.hetj.gov.cn/hetj/cx/(\s\w+)?")})
for t in subroot:
print(str(t['href']))
if(t['href'][0]!='h'):
t['href'] = 'http://www.hetj.gov.cn'+ t['href']
web1.append(str(t['href']))
else:
web2.append(str(t['href']))结果: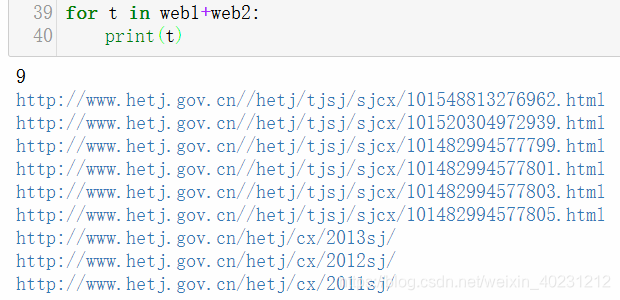
3. 在这个大表中 提取出真正的数据URL(也就是有超链接的部分)
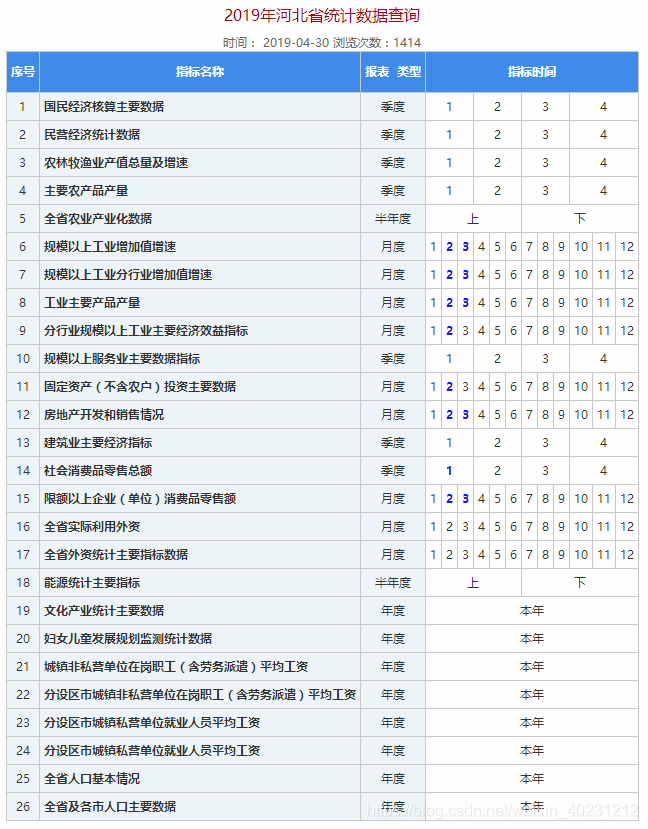
#先进入子url中
data_url_list=[]
for target in web1[0:1]:
req = requests.get(url=target)
html = req.content #这种方法去除乱码
bf = BeautifulSoup(html,"lxml")#不加lmxl会有warning
data_url = bf.tbody.find_all('a') #bf.标签名称:获取html标签中第一个匹配的标签内容,然后再find_all带a的,这里也就是带href的
for u in data_url:
data_url_list.append(u['href'])#直接这样读取属性href
结果:  这就是真正包含 要爬曲的数据的url列表。
这就是真正包含 要爬曲的数据的url列表。
4.将网页中的表格(table)转化成CSV或xlsx表格
以第一个为例:

进入页面: