1、Tableau是用来做数据的管理和数据可视化的工具,是在整个数据科学从业公司中最火的、最好用的数据管理及可视化软件
(几下鼠标就能画出一个很好的图,也是比excel方便很多)
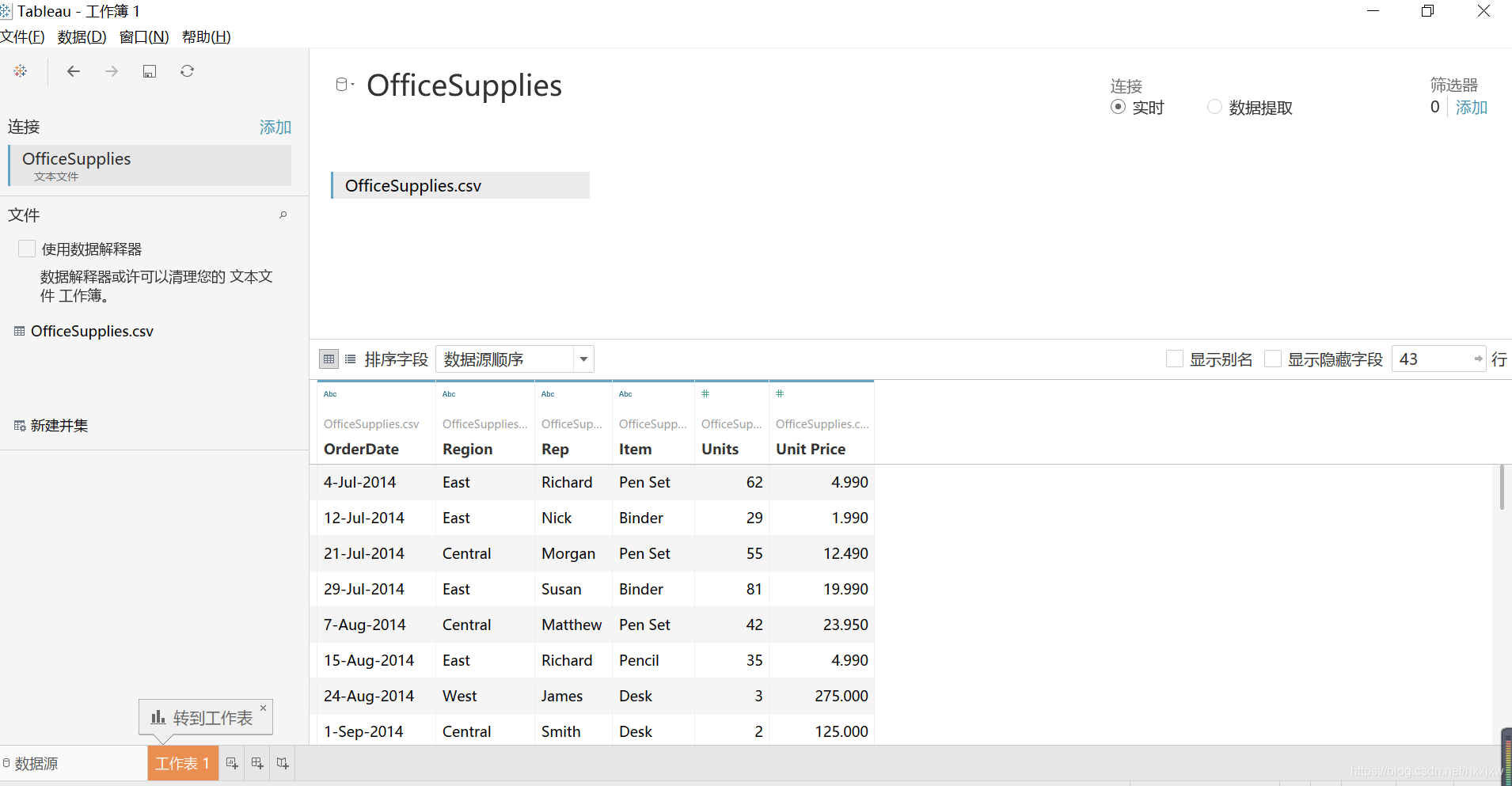
办公室办公用品的数据集
这是一个很简单的数据集
进入工作表
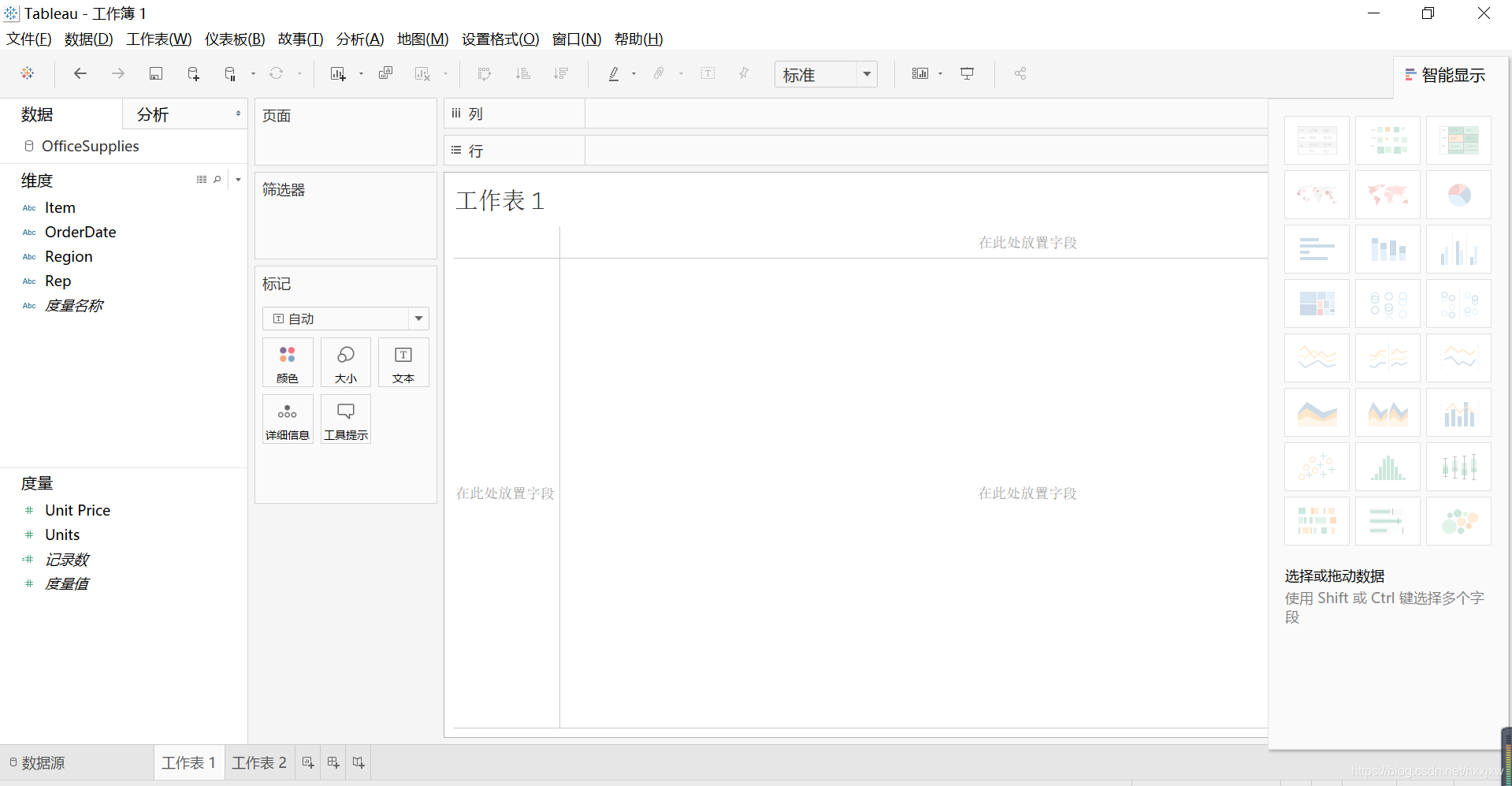
左边的dimensions(维度)和measures(度量)的区别是数据的类型
dimensions是类别型变量
measures是数值型变量/连续型数据变量
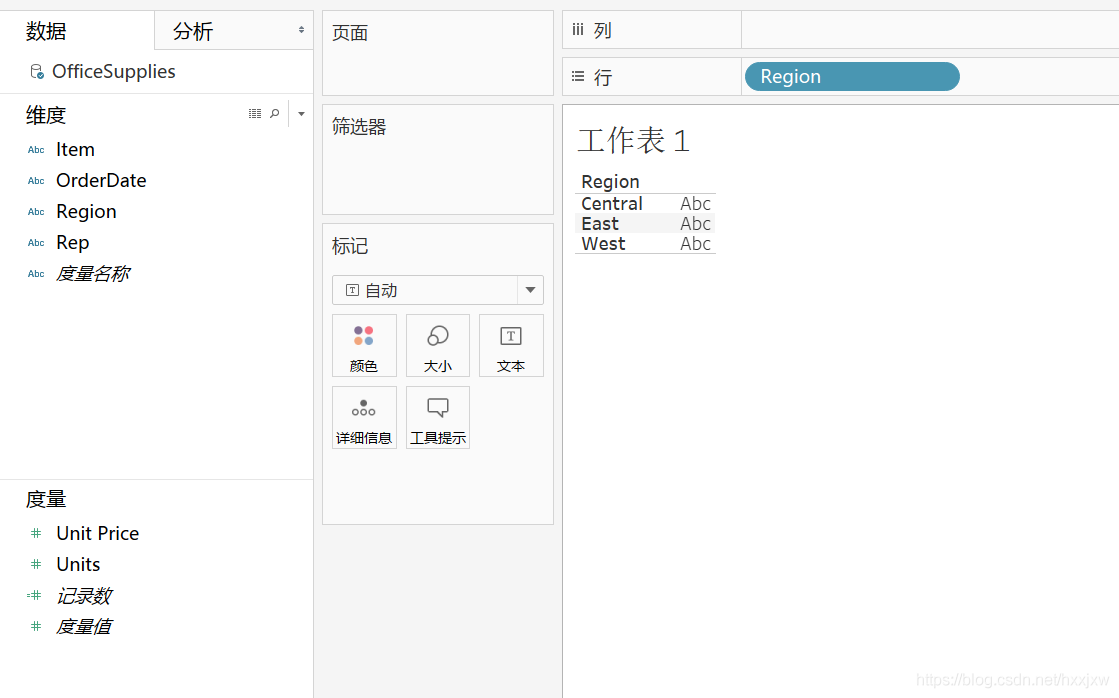
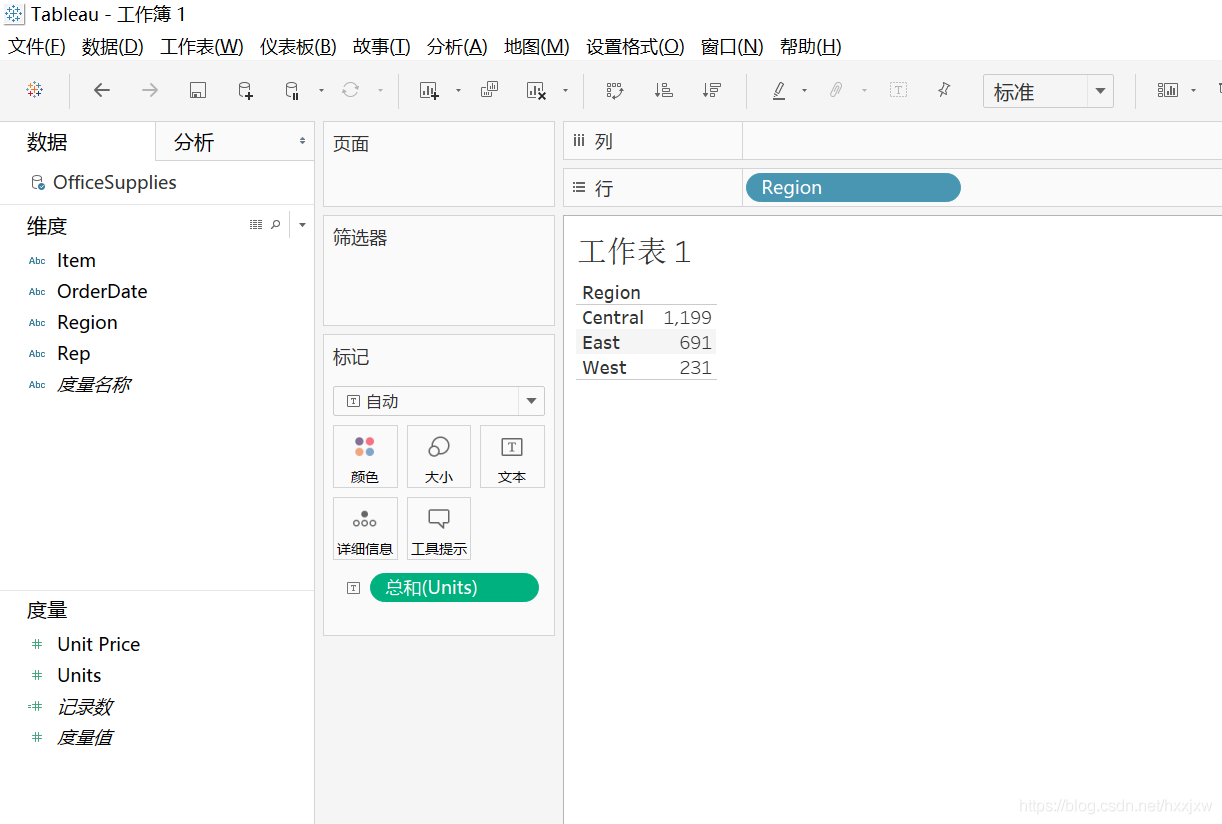
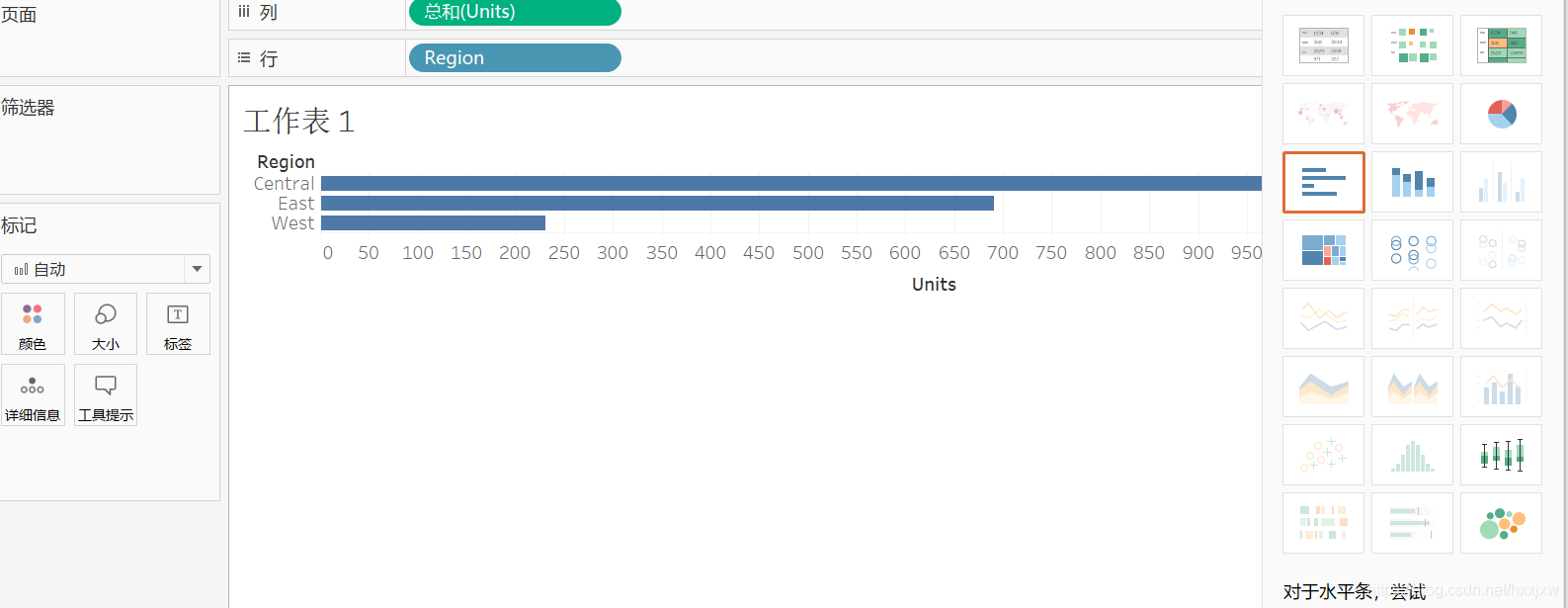
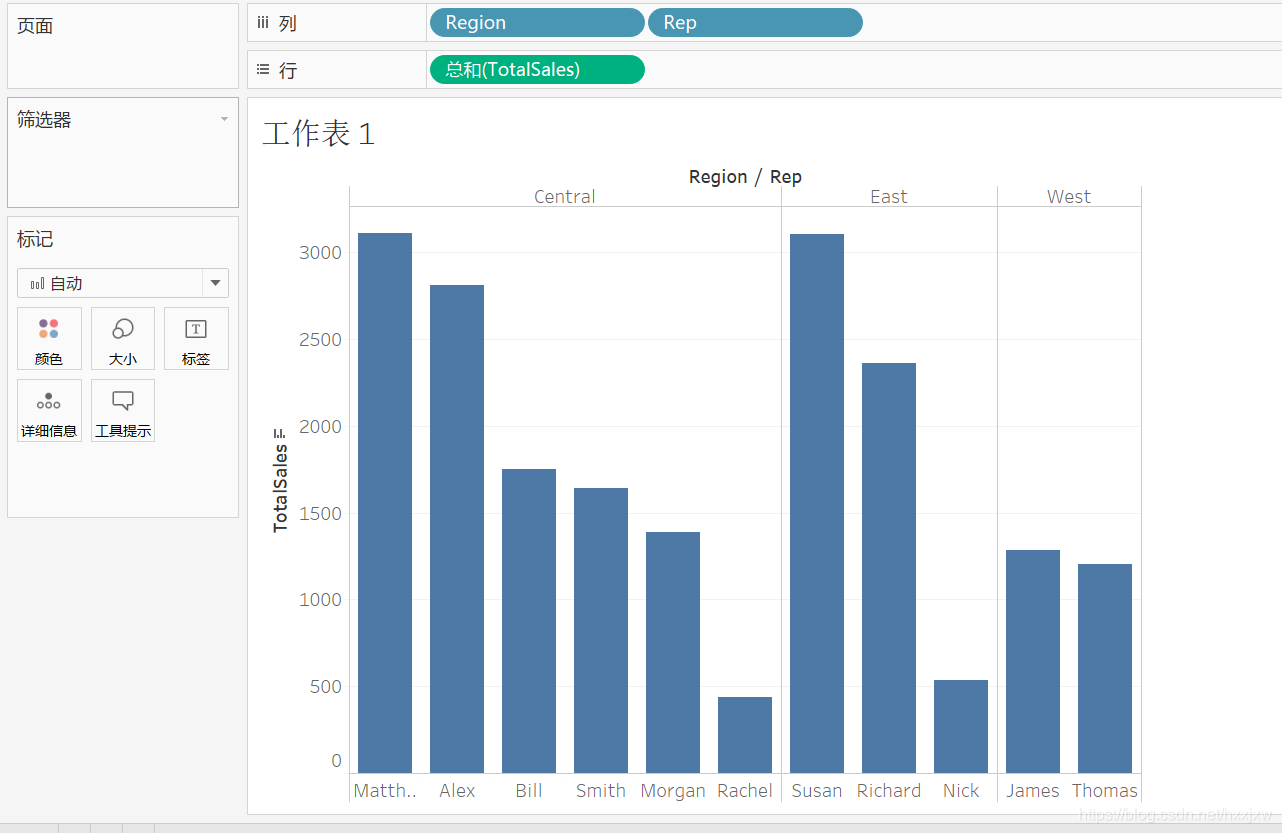
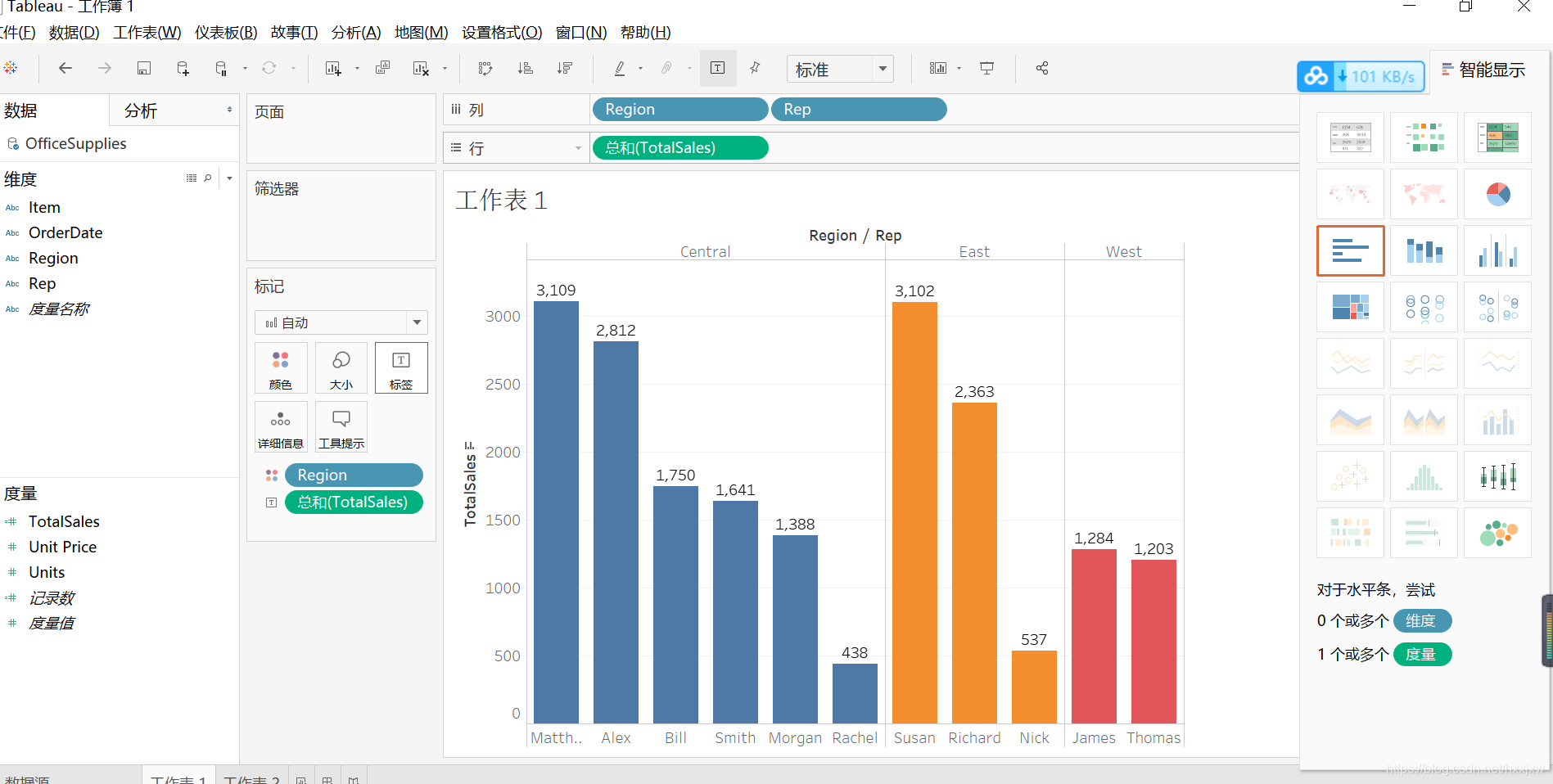
想知道各个地区卖了多少东西,可以把region拖到这里面来
扫描二维码关注公众号,回复: 6106667 查看本文章
可以在右上角选择进行图形显示
等等
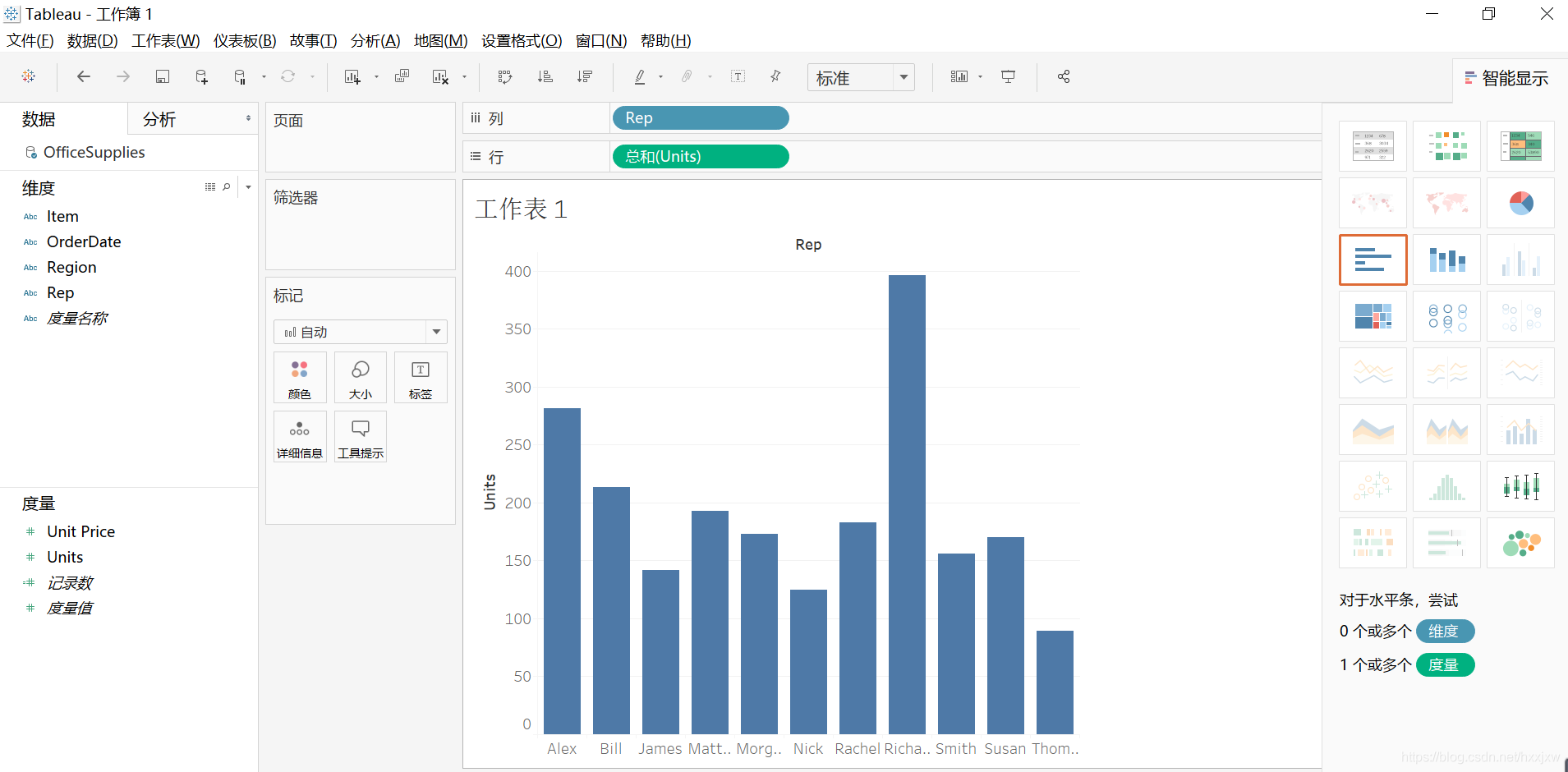
如果我不想看地区了,想看哪一个人卖了多少东西,我就可以直接把Rep拖过来覆盖Region就行了
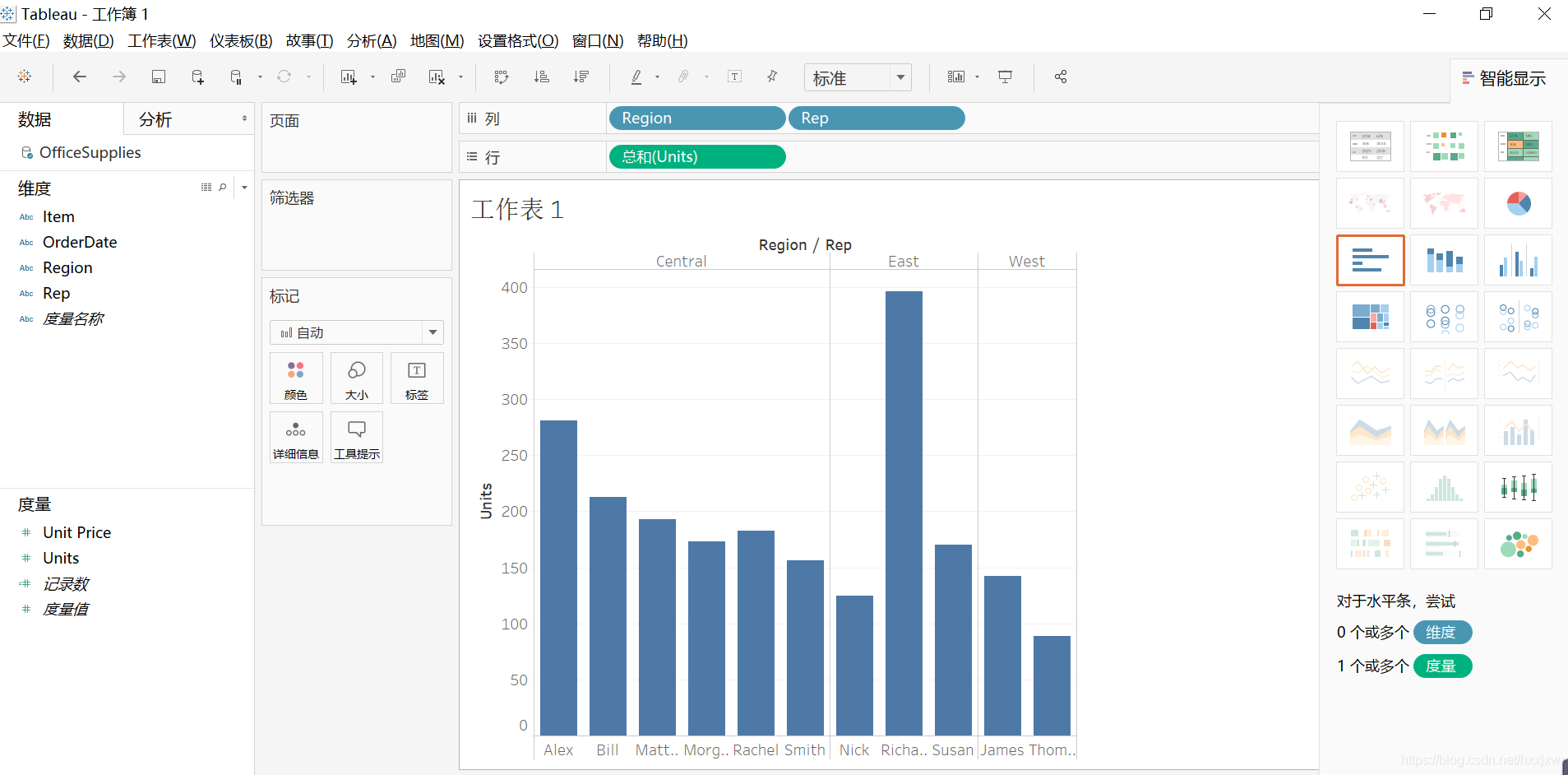
如果想要评选区域的销售冠军,也就是分人又要分地区,那么只需要再把Region拖过来就可以了
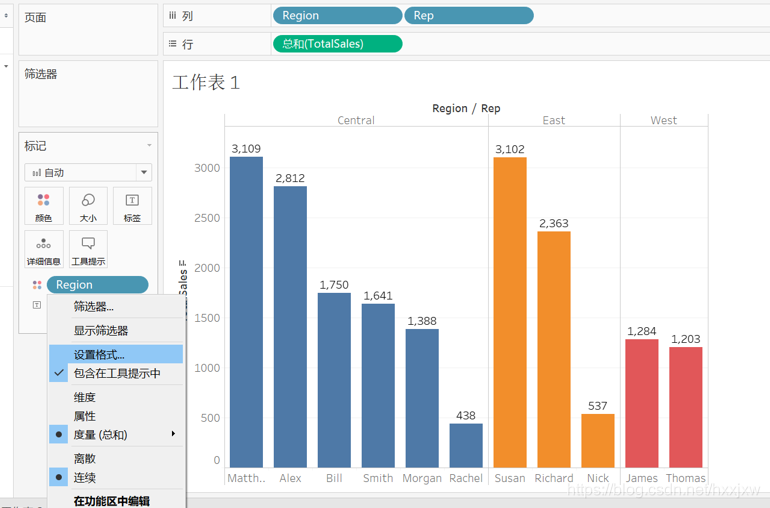
坐标轴旁边有一个小标记,一点它就自动从大到小排序了
、
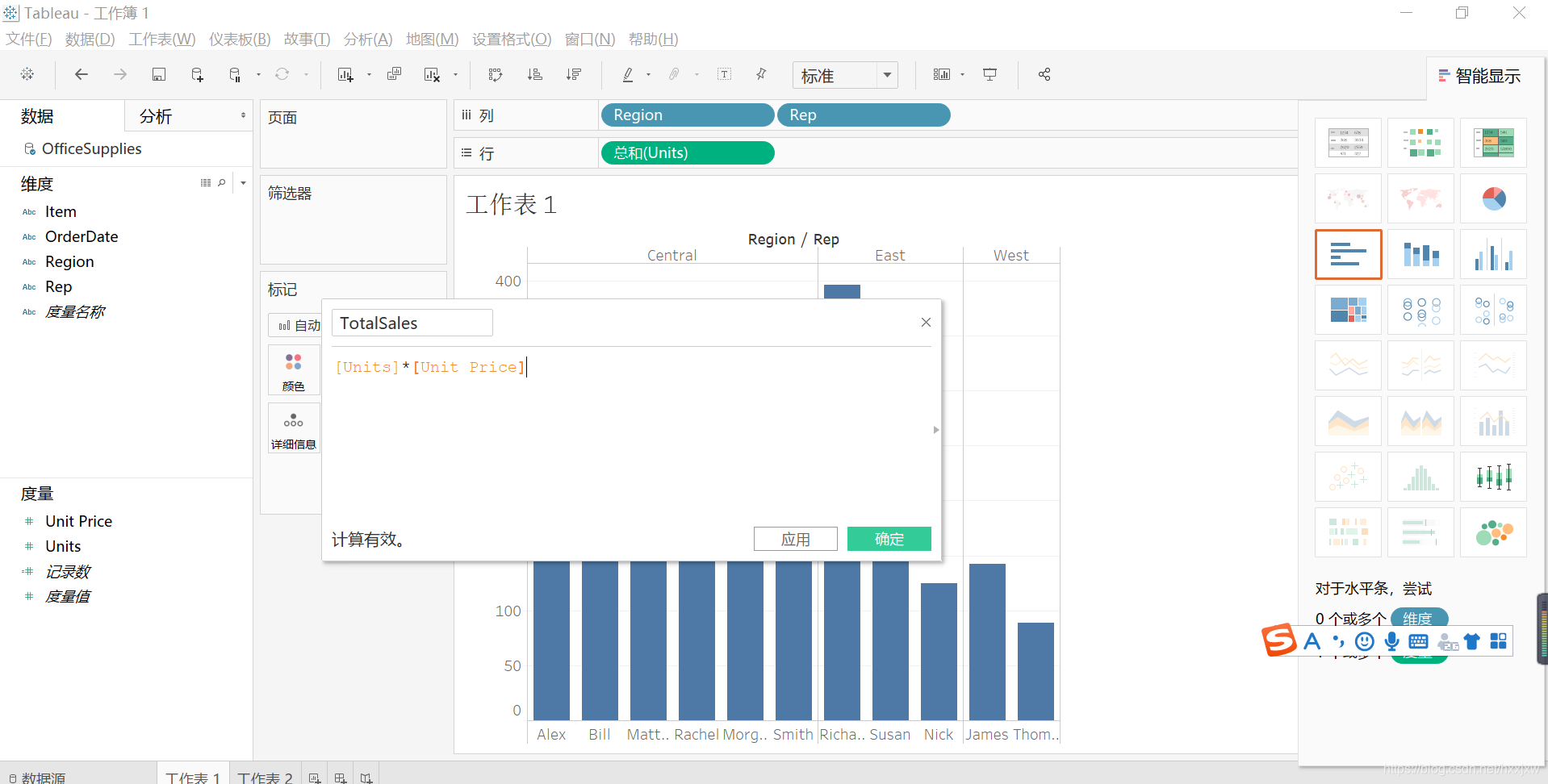
但是我们看数据集知道,有的物品价格高,有的低,所以就算有的人卖的件数很多,总价值也不一定多高,那么我们怎么看总价值呢
右击,新建计算字段
用方括号调用unit的值
这里的井号有等号的就代表不是在原始数据集里面的
然后用totalsales把units替换掉就可以看每个人的销售总量了
那么感觉看到这个颜色比较单一,该怎么调呢
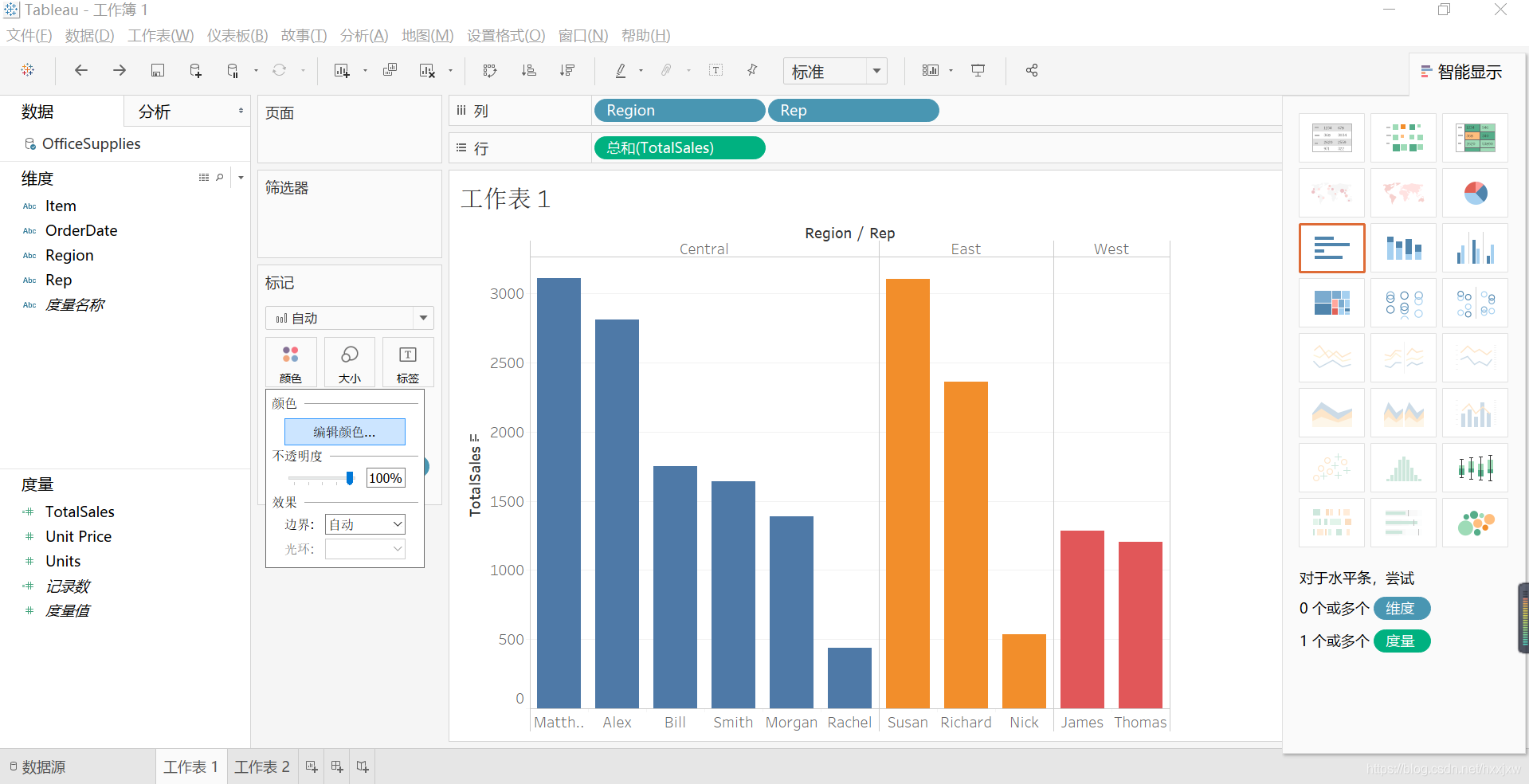
可以直接按住ctrl键,把region直接拖到右边的颜色上来
不满意配色还可以换颜色
点击颜色-->编辑颜色
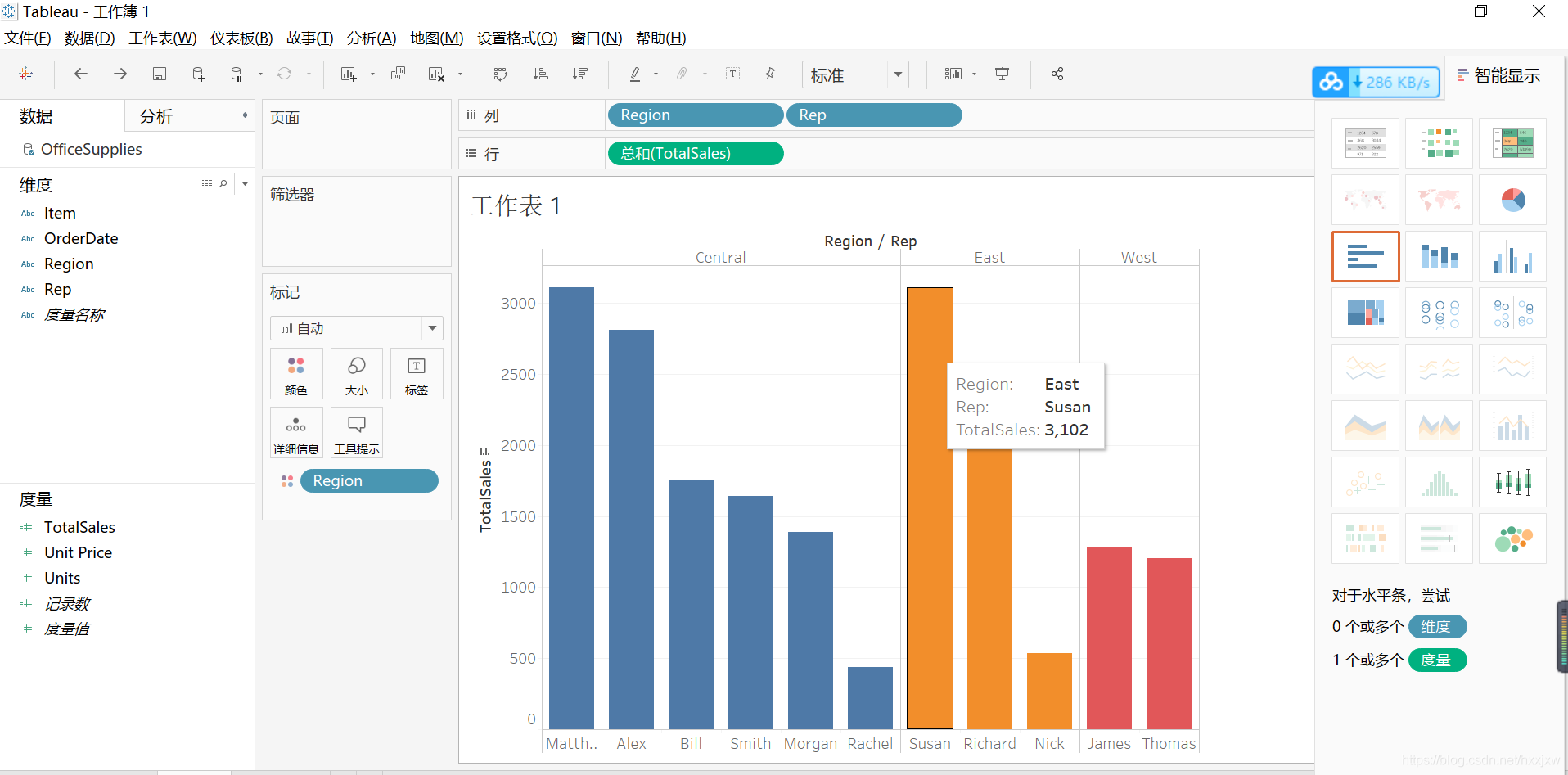
那么我们又发现,如果想要知道每个人卖的总数的话,必须要鼠标移动到上面才能看到,或者就是大概估算一下
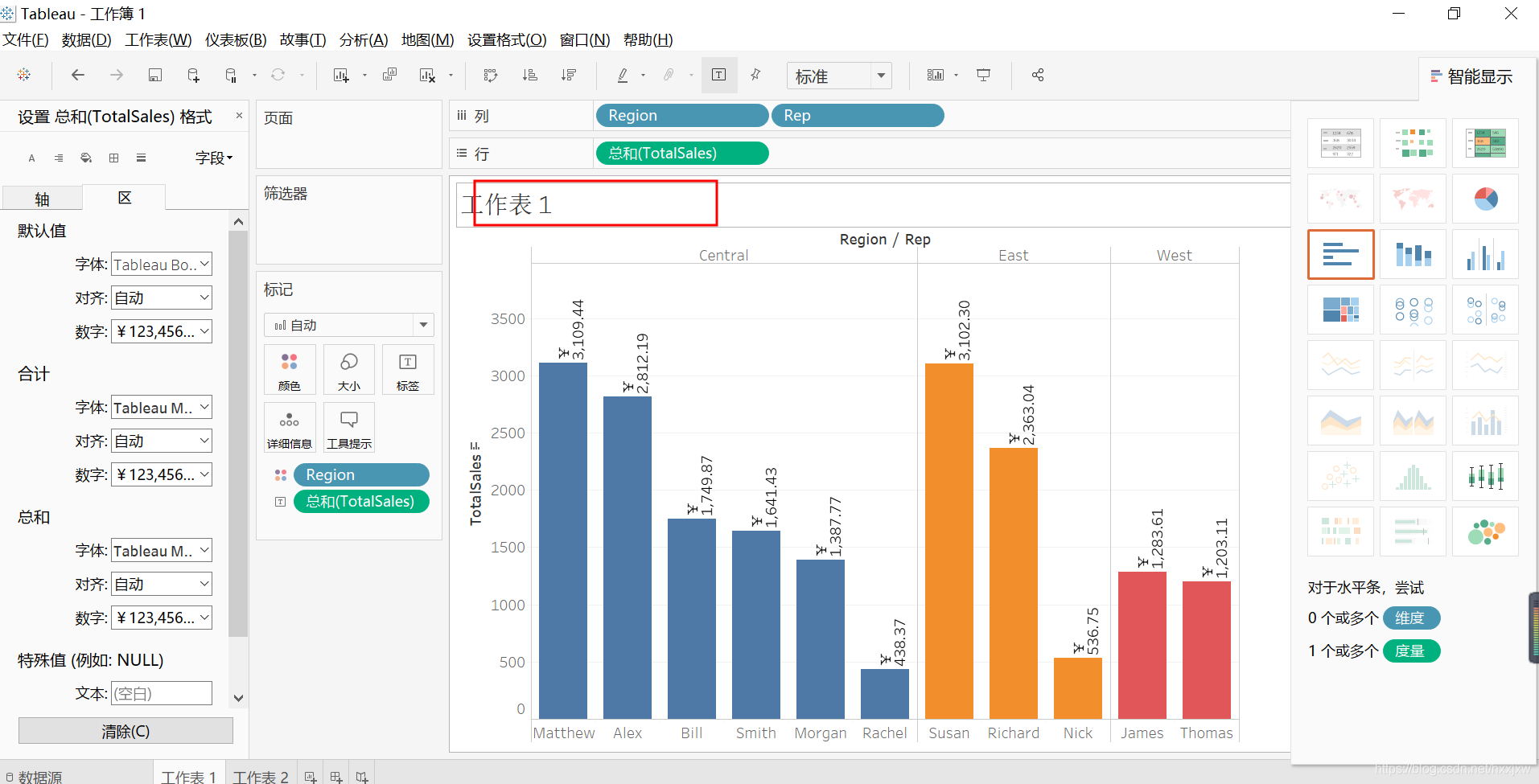
我们可以按住ctrl键,把totalsales拖到label上来
但是只有数字,我们需要加上单位才好
点击Totalsales -->设置格式
在右侧的数字选择货币格式
包括我们的y坐标轴也需要调整一下format
直接右键点击一下y轴选择设置格式
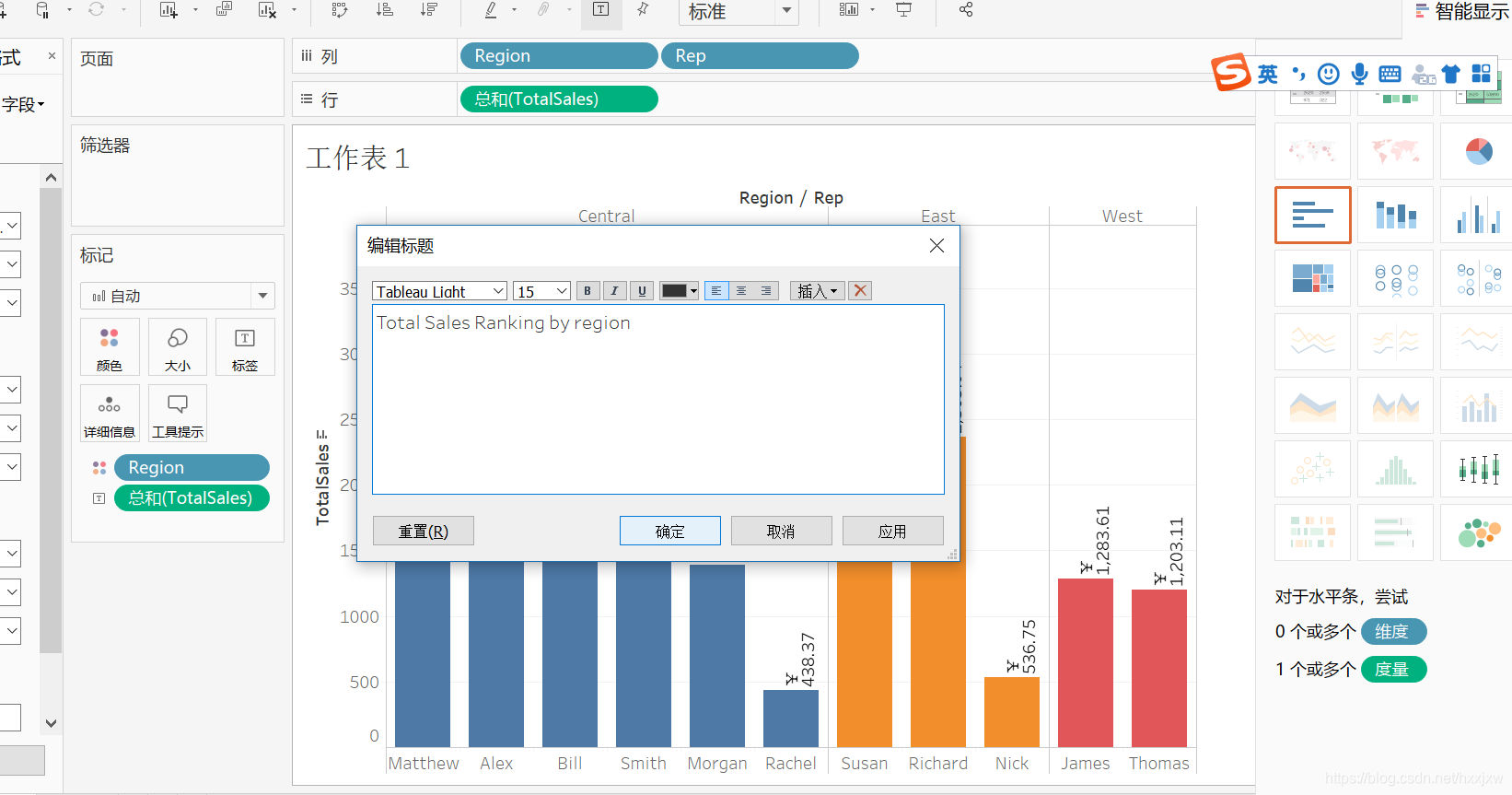
给表格命名
双击 工作表1 这里
导出图表
甚至还可以选择导出的时候留存什么信息
或者可以在图上右键,复制图标,这样就可以贴到ppt等地方去了
帮助文档
第二个数据集举例
这是一家欧洲的跨国商业银行,但是银行家们发现,最近几个月,在这个银行关户的人数有显著的上升,很多人都不跟这个银行做业务了,都把钱取出去了,把银行账户也关了。这就让银行的管理层感觉非常惶恐,于是他们找到了你,由你来分析一下到底发生了什么故事
对于数据的列,我们叫做feature(特征)
对于数据的行,我们叫做observation(观测)
geography是它的国籍
tenure是指在这个银行开户开了多久
balance是指银行的余额是多少
number of products是指在银行办了几种服务
isactivemember 是否是活跃用户
estimated salary预估的年薪
exited代表是否关户
我们就想用可视化的语言看看能不能帮助这个银行家分析出来到底是什么原因导致了这个人的关户
在之前大家可能更关注与时间序列,对空间信息关注的不够多。但最近两年有个趋势,大家呼吁应该对空间信息有更强的重视。
Tablue对地理的分析有非常好的支持
既然我们数据里面出现了国家,那我们就用国家进行一下地理分析这里前面带Abc的指的是字符串
我们可以这样告诉它这个这个东西不只是字符串,其实是代表国家与地区
它的图标也就自己换了
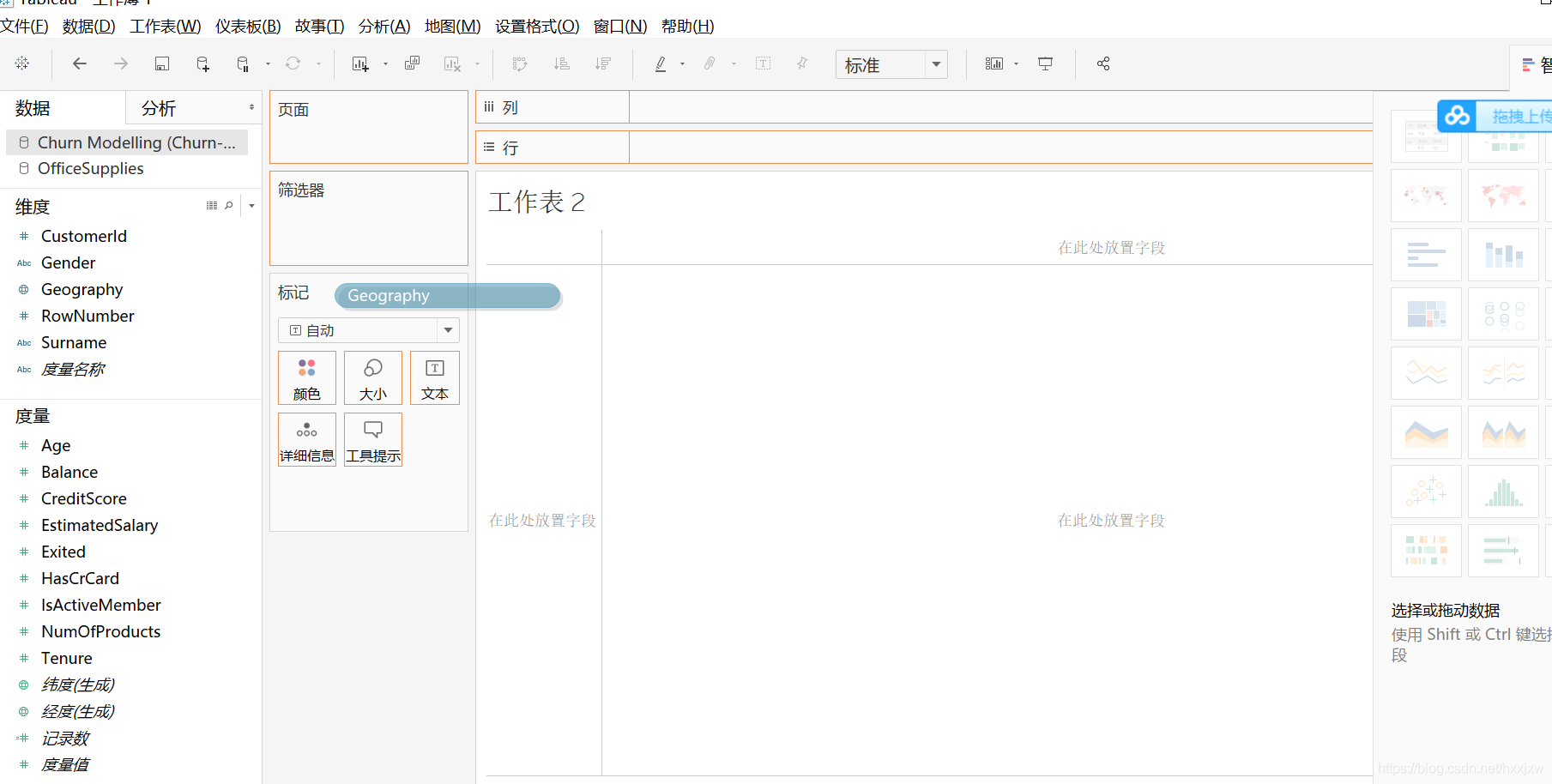
把geogrephy拖过来,拖到空白处
它就自己生成了一个地图
我们可以把numberofproducts拖到颜色上面来,Tableau就会根据每个国家用的产品人数的多少调整颜色
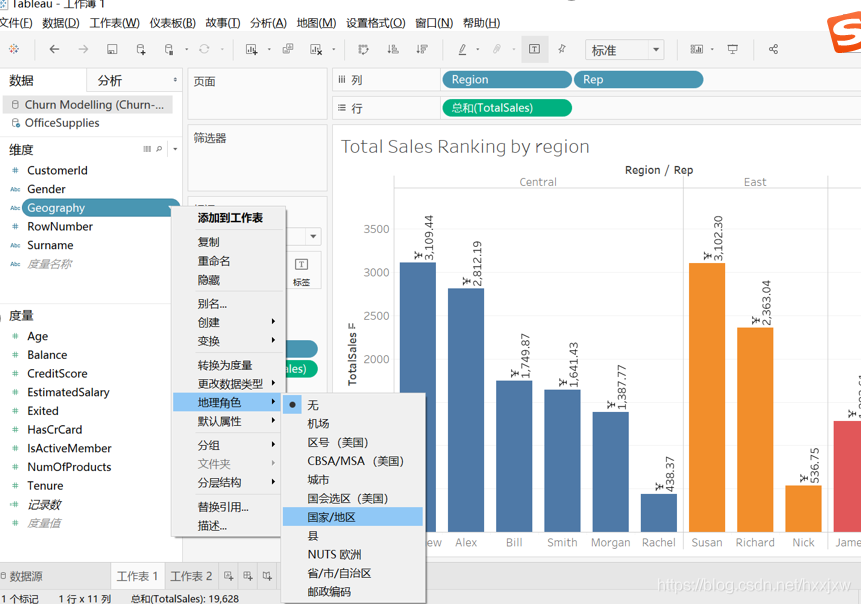
这里如果把国家名给打错了的话就会出问题了,(Tableau可能会有一定的纠错机制,但是也要高度匹配的前提下)
作为一个数据科学家,永远不要相信别人给你的数据。别人给你的数据非常有可能存在非常多的问题。、之前就发生过例子:别人给我的数据,告诉我已经处理好了,然后就非常信他们就直接拿来分析,然后发现这个模型怎样训练都得不到想要的结果。后来发现是数据错了。把数据进行清理的过程也是一个非常重要的环节(data cleaning)
数据分析都是先有一些猜想,看看能不能验证,能的话再进行统计上的一些计算,看它是否显著,然后发展为结论
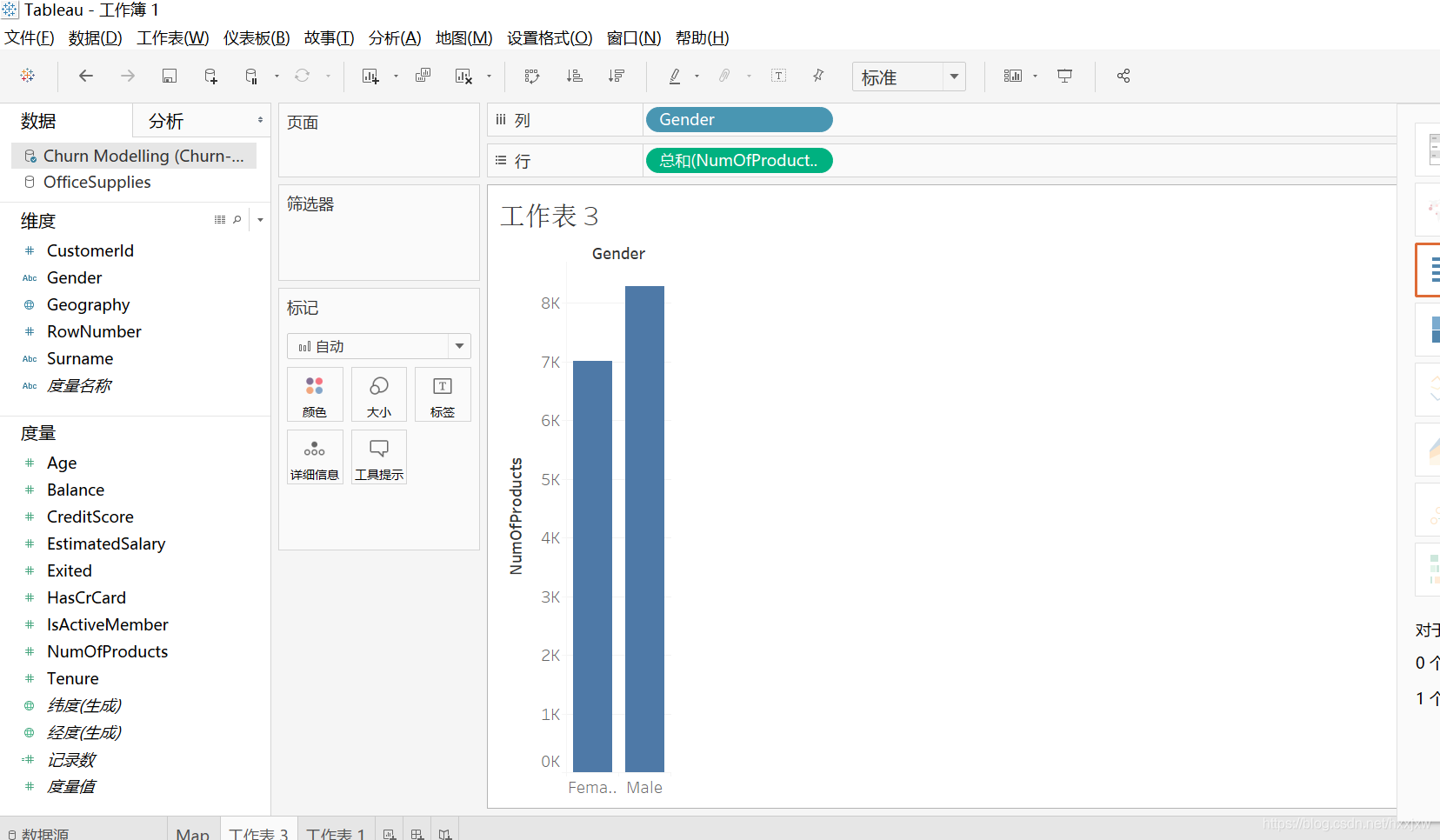
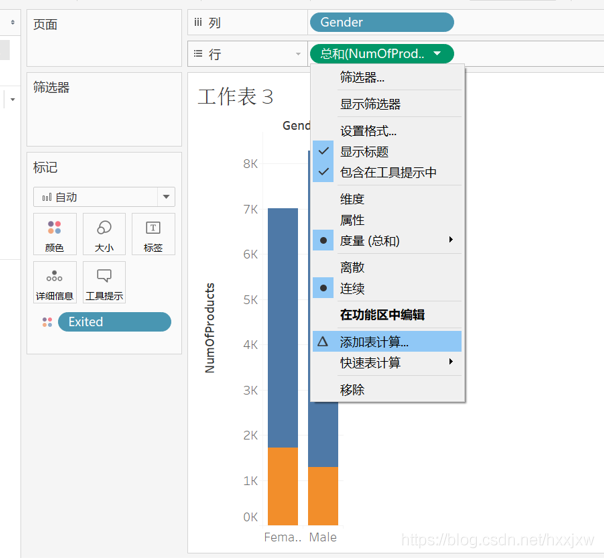
鉴于欧洲近期平权运动愈演愈烈,会不会是银行的老板发表了什么关于女性的言论导致很多用户关户呢?那我们就来看一下性别和关户数有没有关系(如果因为老板发表女性言论关户的话,肯定是女性关得多)我们就把gender拖到列,numberofproducts拖到行
然后我发现,退出与否(excited)是一个状态,但为什么会被归类到“度量”里面呢?因为退出与否是用01来标志状态的
我们可以直接把exited拖上去就ok,告诉它这是一个类别型变量
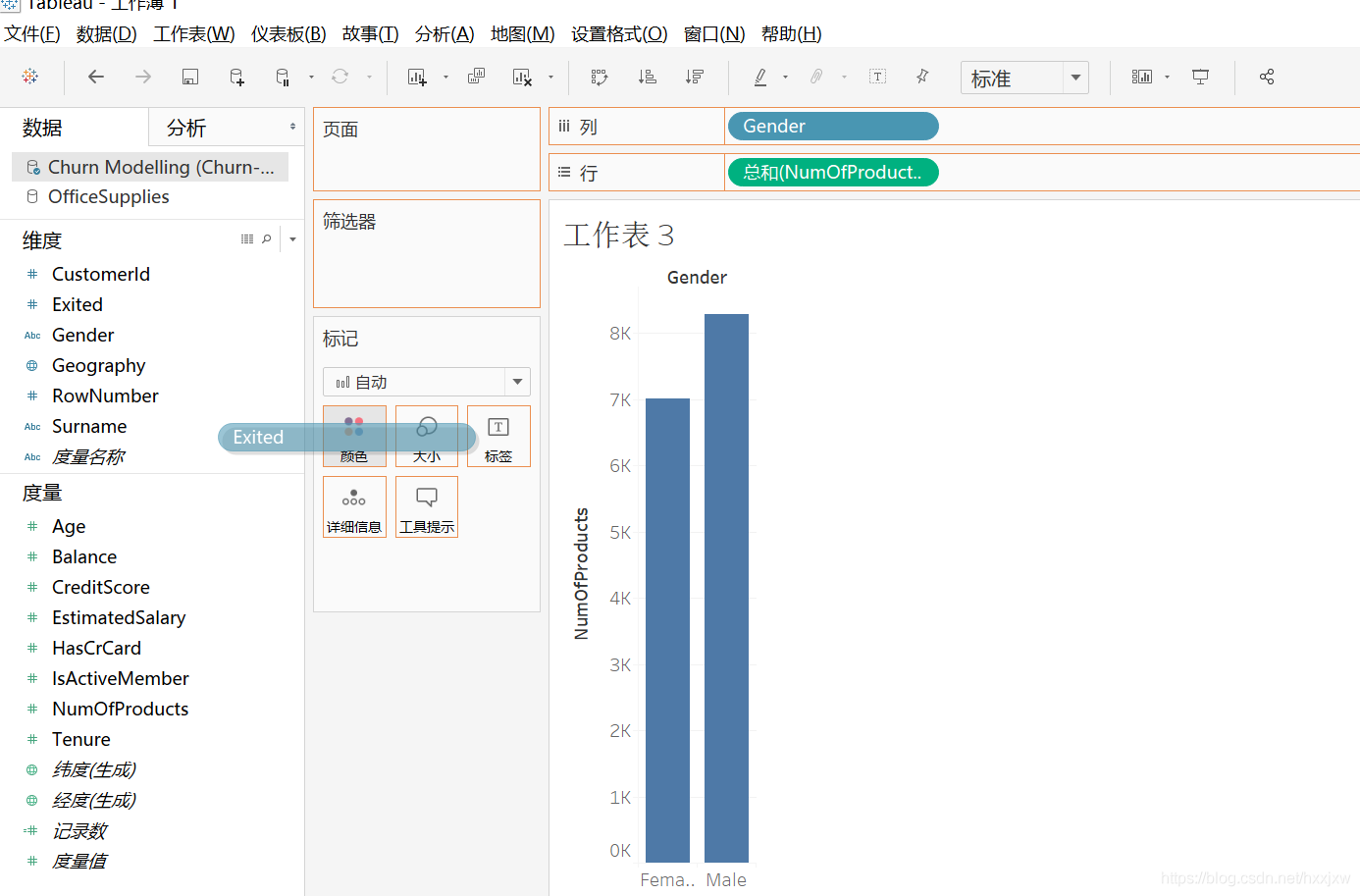
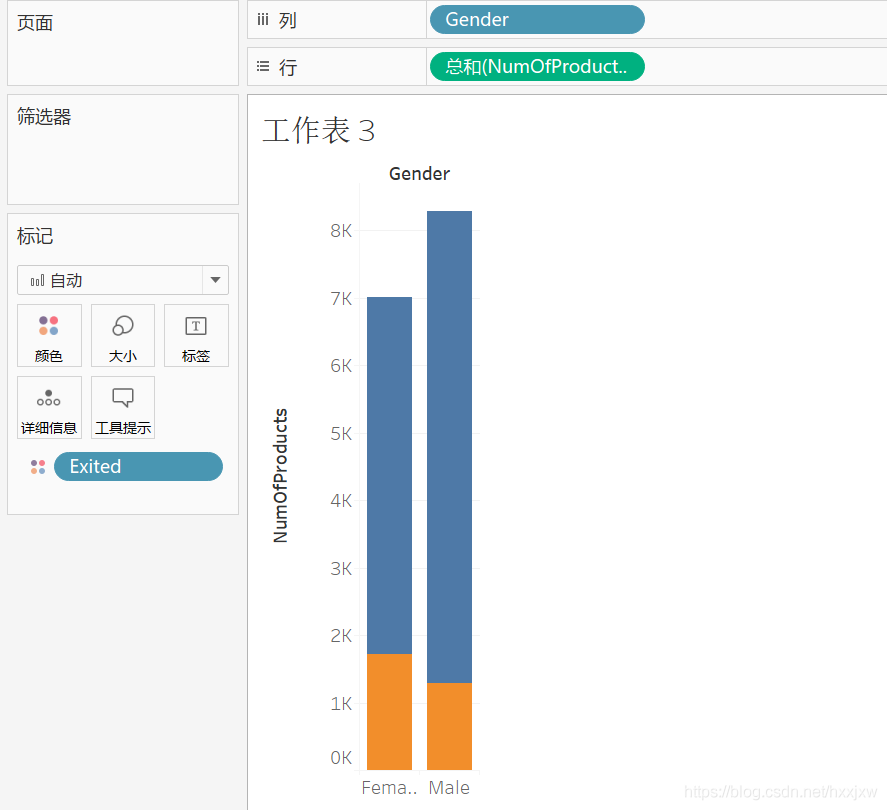
然后把exited拖到颜色上来
得到这样,所有退出的变成了橙色,没退出的变成了深蓝色
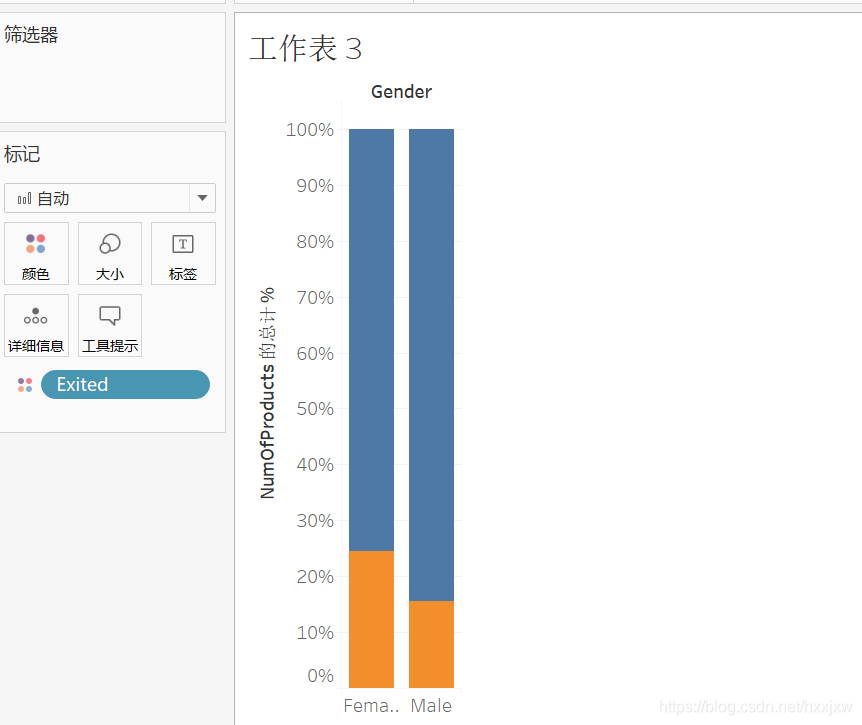
如果想看男女的分别退出人数占总人数的比重
计算类别选择合计百分比
然后就获得了一个百分比的占比
那我们想看国家,国家的不同是否有显著的退出(而不是性别了),只需要吧geography拖上去替换gender就行了
可以看出德国的退出率显著高于法国和西班牙
那对于各个国家是男是女有没有区别呢? 可以直接把gender拖到geo后面
在这个银行开了4种产品的竟然100%都退出了
在以后遇见100%的也要思虑一下,不要被100%骗了,直接觉得这事确保了,但是有可能类别是属于采样不够完整的类。假设说这个银行只有1个人他是有4个产品,可能这1个人退出了那就是100%。所以当看到百分比的时候一定要看一下它的采样数量
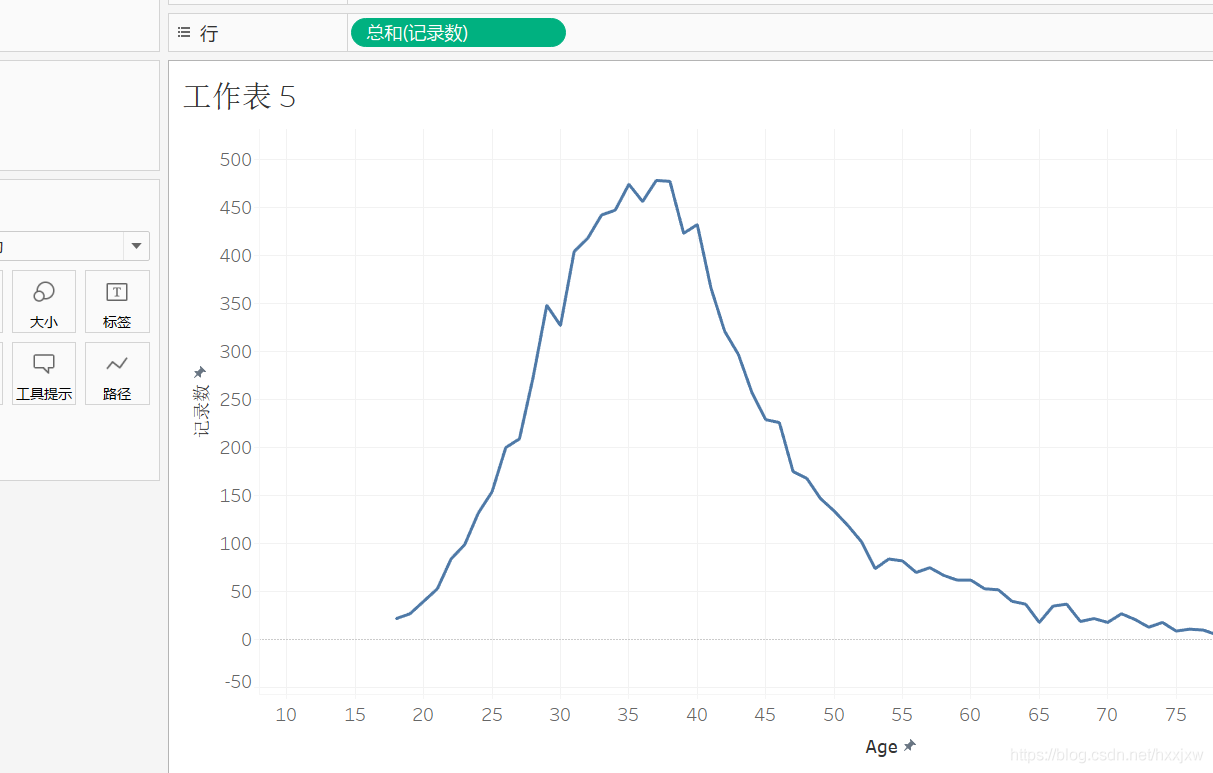
那银行用户和年龄有没有关系呢?
当把 “度量”拖到列的时候,它默认会以求和的形式显示,这时调整一下,选择维度就可以了
、
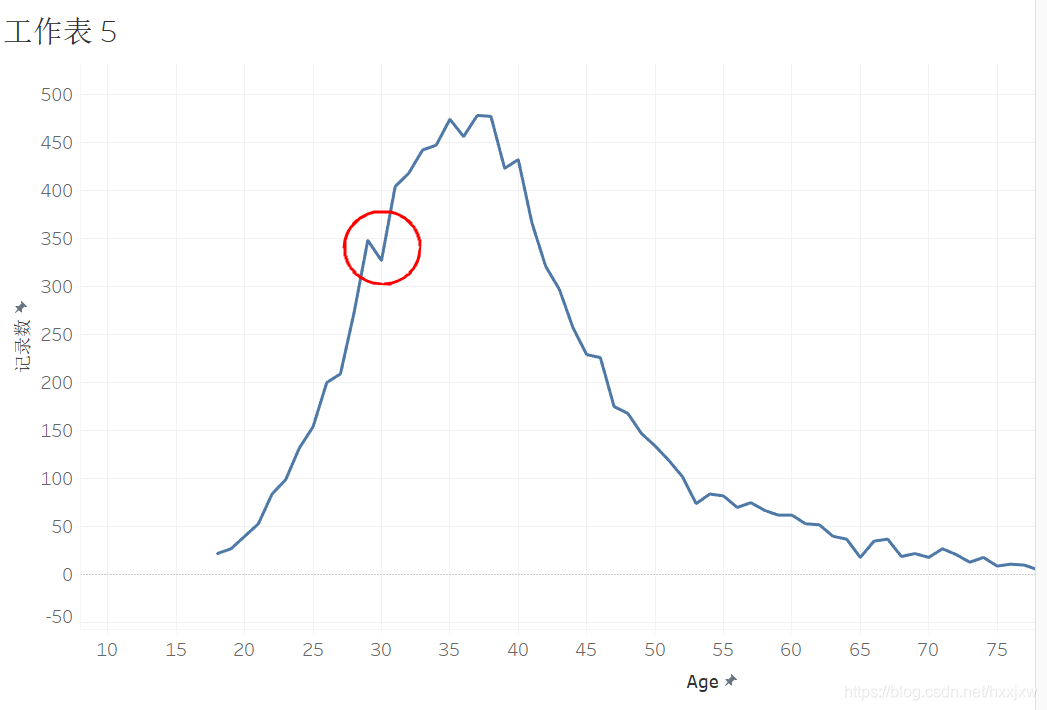
首先要处理一下噪音的问题
按理说并不应该降低,30岁会比29岁关户多并没有什么道理,可能就是随机性导致的
为了避免随机对我们分析产生的影响,我们往往在进行年龄分析的时候对它进行取段分析
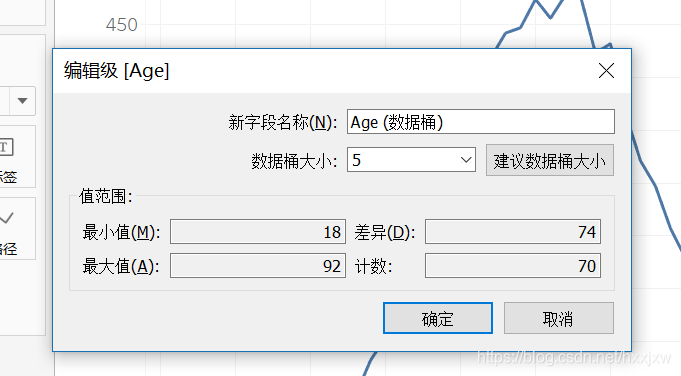
在右边的age选择创建-数据桶
设定大小为5
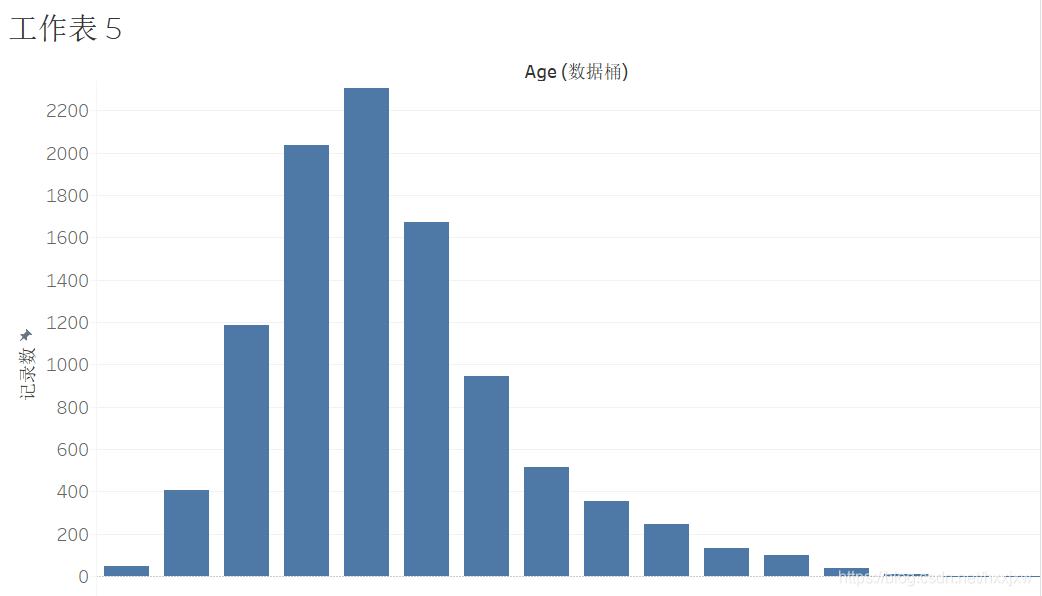
然后用age(数据桶)把列的age替换掉
刚才的噪音就已经都没有了
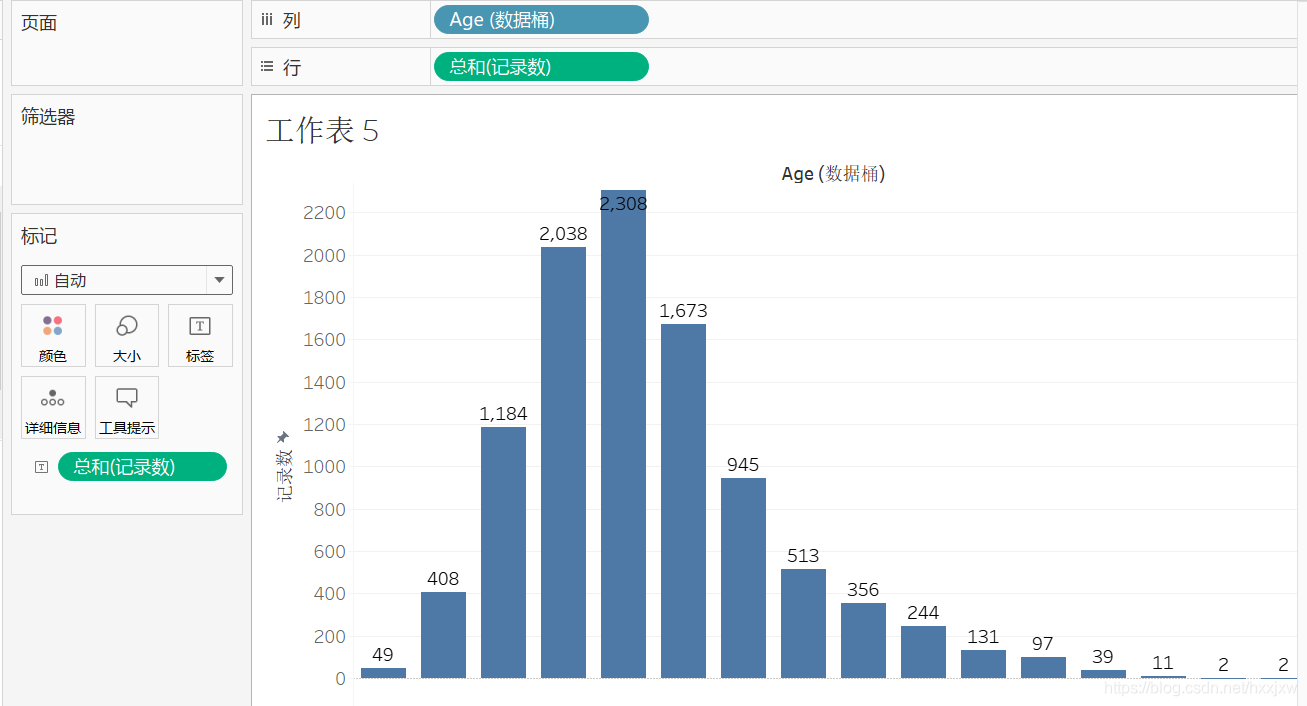
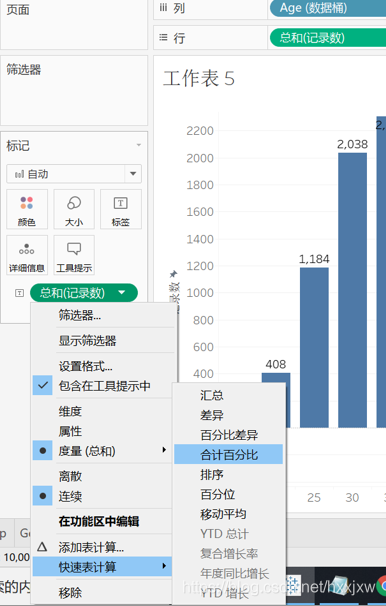
看一下各个年龄段占总体人数的多少,按住ctrl,将总和(记录数)拖到标签上
转换成百分比
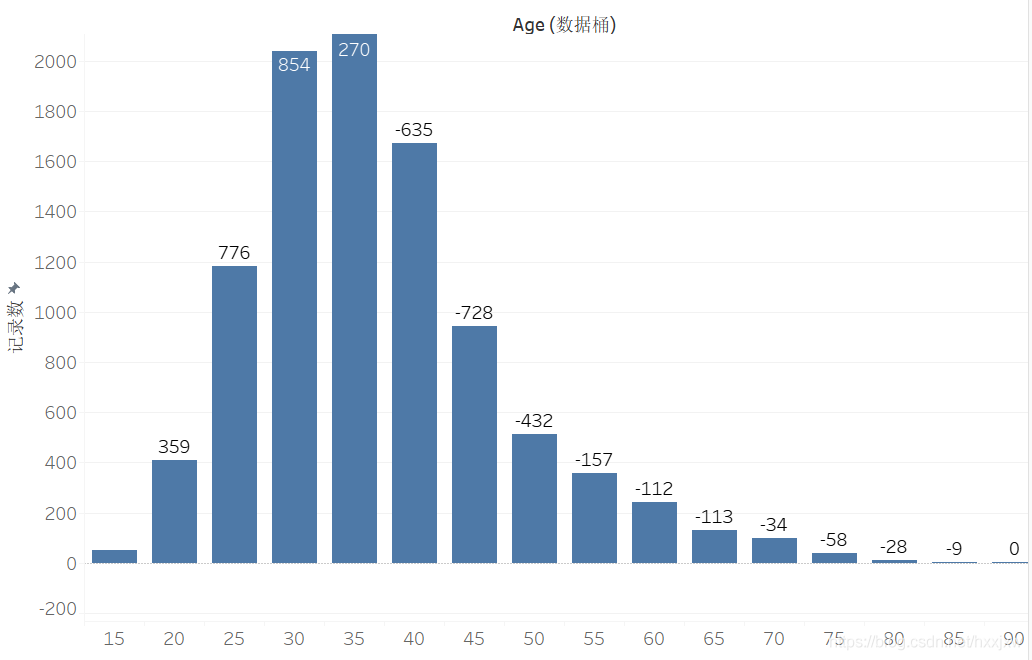
如果不选合计百分比选择差异的话,显示距离前一段的增长
Tableau的用法
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/hxxjxw/article/details/89403418













猜你喜欢
转载自blog.csdn.net/hxxjxw/article/details/89403418
今日推荐
周排行