文章目录
- 阅读第二章
- 2.1Jupyter Notebook 太棒了!GitHub 万岁!!!
- 2.2%matplotlib inline
- 2.3实用方法
- 2.4数据可视化
- 2.5寻找相关性
- 2.6试验不同属性之间的组合
- 2.7机器学习算法的数据准备
- 2.8Scikit-Learn 的设计
- 2.9处理文本和分类属性
- 2.10自定义转换器
- 2.11特征缩放
- 2.12转换流水线(相当有用的利器)
- 2.13使用交叉验证更好的进行评估
- 2.14保存好训练的模型
- 2.15微调模型
- 2.15.1网格搜索(适用于组合数量较少的情况)
- 使用GridSearchCV.best_params_方法获得最佳参数组合:
- 使用GridSearchCV.best_estimator_方法查看最好的估计器
- 参数refit
- 使用GridSearchCV.cv_results_方法查看评估分数
- 随机搜索
- 集成方法
- 分析最佳模型及其错误
- 通过测试集评估系统
- 启动、监控和维护系统
- 小总结
阅读第二章
时间:2019-04-28
可能这就是我想在书中看到的内容,同样的内容在《Python机器学习基础教程》这本书中并未像这样被列出。

2.1Jupyter Notebook 太棒了!GitHub 万岁!!!
begin时间:2019-04-29
因为书中的示例在Github上都有展示,并且都是ipynb格式,这意味着你只需要将其下载下来放到你的Jupyter Notebook工作目录下就可以对其进行直接的编辑、运行。
下面的是我的Jupyter Notebook
2.2%matplotlib inline
这本书不错!原以为不会有这个命令的讲解,没想到不仅有,而且讲的很详细。
Jupyter Notebook的前身是IPython Notebook,IPython起初是在console中使用的,而%matplotlib可以使所绘制的图形在console下自动被显示。
hist()方法依赖于Matplotlib,而Matplotlib又依赖于用户指
定的图形后端才能在屏幕上完成绘制。所以在绘制之前,你需要先指
定Matplotlib使用哪个后台。最简单的选择是使用Jupyter的神奇命
令%matplotlib inline。它会设置Matplotlib从而使用Jupyter自己的后
端,随后图形会在笔记本上呈现。需要注意的是,因为Jupyter在执行
每个单元格时会自动显示图形,所以在Jupyter笔记本中调用show()
是可选的。
ps:摘自书中
2.3实用方法
DataFrame.head() #显示数据框的前5行
DataFrame.info() #获取数据集的简单描述,information
DataFrame.hist() #绘制每个数值属性的直方图
scikit中的train_test_split() #拆分数据集为训练集和测试集,注意指定random_state
np.ceil(A) #取大于等于A的最小整数。
DataFrame.copy() #拷贝数据框
注意
1、数据窥探偏误(data snooping bias)
在这个阶段主动搁置部分数据听起来可能有点奇怪。毕竟,你才
只是简单浏览了一下数据而已,在决定用什么算法之前,当然还需要
了解更多的知识,对吧?没错,但是大脑是个非常神奇的模式检测系
统,也就是说它很容易过度匹配:如果是你本人来浏览测试集数据,
你很可能会跌入某个看似有趣的数据模式,进而选择某个特殊的机器
学习模型。然后当你再使用测试集对泛化误差率进行估算时,估计结
果将会过于乐观,该系统启动后的表现将不如预期那般优秀。这叫作
数据窥探偏误(data snooping bias)。
------------------------------------------------------------------->摘自书中
2、小心别造成抽样偏差。对于现实中成一定比例的数据,使用分层抽样将其性质保留下来。
3、在拷贝的数据集上进行操作。
2.4数据可视化
pyplot.plot 选项的一个用法
...
ax = housing.plot(kind="scatter",
x="longitude", y="latitude", figsize=(10,7),
s=housing['population']/100, #数据点的形状,每个圆的半径大小代表了每
#个地区的人口数量(选项s)
label="Population",
c="median_house_value", #数据点的颜色,颜色代表价格(选项c)
cmap=plt.get_cmap("jet"),
colorbar=False, alpha=0.4,
)
...
2.5寻找相关性
方法一:计算每对属性之间的标准相关系数(也称为皮尔逊相关系数)
相关系数的范围从-1变化到1。越接近1,表示有越强的正相关;
比如,当收入中位数上升时,房价中位数也趋于上升。当系数接近
于-1,则表示有强烈的负相关;注意看纬度和房价中位数之间呈现出
轻微的负相关(也就是说,越往北走,房价倾向于下降)。最后,系
数靠近0则说明二者之间没有线性相关性。
注意:相关系数仅测量线性相关性(“如果x上升,则y上升/下
降”)。所以它有可能彻底遗漏非线性相关性(例如“如果x接近于
零,则y会上升”)。
DataFrame.corr() #计算每对属性之间的标准相关系数(也称为皮尔逊相关系数)
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
效果:
median_house_value 1.000000
median_income 0.687160
total_rooms 0.135097
housing_median_age 0.114110
households 0.064506
total_bedrooms 0.047689
population -0.026920
longitude -0.047432
latitude -0.142724
Name: median_house_value, dtype: float64
方法二:使用Pandas的scatter_matrix函数,它会绘制出每个数值属性相对于其他数值属性的相关性
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))
save_fig("scatter_matrix_plot")
2.6试验不同属性之间的组合
多多尝试!
end
2.7机器学习算法的数据准备
begintime:2019-04-30
缺失数据的处理方法
pandas中的方法:

DataFrame.drop() #创建一个新副本的同时,丢弃指定的数据行/列(axis=0 行,axis=1 列)
Scikit-Learn中的方法:
Scikit-Learn提供了一个非常容易上手的教程来处理缺失值:
imputer。使用方法如下,首先,你需要创建一个imputer实例,指定
你要用属性的中位数值替换该属性的缺失值:
1、创建imputer实例
2、使用imputer.fit()方法将imputer实例适配到训练集
3、使用imputer.transform()方法处理数据。
try:
from sklearn.impute import SimpleImputer # Scikit-Learn 0.20+
except ImportError:
from sklearn.preprocessing import Imputer as SimpleImputer
imputer = SimpleImputer(strategy="median")
#由于中位数值只能在数值属性上计算,所以我们需要创建一个没
#有文本属性的数据副本ocean_proximity:
housing_num = housing.drop('ocean_proximity', axis=1)
# alternatively: housing_num = housing.select_dtypes(include=[np.number])
imputer.fit(housing_num)
X = imputer.transform(housing_num)
注意:
这里imputer仅仅只是计算了每个属性的中位数值,并将结果存
储在其实例变量statistics_中。
>>> imputer.statistics_
array([ -118.51 , 34.26 , 29. , 2119. , 433. , 1164. , 408. , 3.5414])
>>> housing_num.median().values
array([ -118.51 , 34.26 , 29. , 2119. , 433. , 1164. , 408. , 3.5414])
2.8Scikit-Learn 的设计
对scikit-learn有了更清晰的认识。
Scikit-Learn的设计 Scikit-Learn的API设计得非常好。其主要的设计原则是:一致性。所有对象共享一个简单一致的界面:
·估算器。能够根据数据集对某些参数进行估算的任意对象都可
以被称为估算器(例如,imputer就是一个估算器)。估算由fit()方
法执行,它只需要一个数据集作为参数(或者两个——对于监督式学
习算法,第二个数据集包含标签)。引导估算过程的任何其他参数都
算作是超参数(例如,imputer’s strategy),它必须被设置为一个实
例变量(一般是构造函数参数)。
·转换器。有些估算器(例如imputer)也可以转换数据集,这些
被称为转换器。同样,API也非常简单:由transform()方法和作为
参数的待转换数据集一起执行转换,返回的结果就是转换后的数据
集。这种转换的过程通常依赖于学习的参数,比如本例中的
imputer。所有的转换器都可以使用一个很方便的方法,即
fit_transform(),相当于先调用fit()然后再调用transform()(但
是fit_transform()有时是被优化过的,所以运行得要更快一些)。
·预测器。最后,还有些估算器能够基于一个给定的数据集进行
预测,这被称为预测器。比如,上一章的linearRegression就是一个预
测器:它基于一个国家的人均GDP预测该国家的生活满意度。预测器
的predict()方法会接受一个新实例的数据集,然后返回一个包含相
应预测的数据集。值得一提的还有一个score()方法,可以用来衡
量给定测试集的预测质量(以及在监督式学习算法里对应的标
签)。
·检查。所有估算器的超参数都可以通过公共实例变量(例如,
imputer.strategy)直接访问,并且所有估算器的学习参数也可以通过
有下划线后缀的公共实例变量来访问(例如,imputer.strategy_)。
·防止类扩散。数据集被表示为NumPy数组或是SciPy稀疏矩阵,
而不是自定义的类型。超参数只是普通的Python字符串或者数字。
·构成。现有的构件尽最大可能重用。例如,任意序列的转换器
最后加一个预测器就可以轻松创建一个流水线。
·合理的默认值。Scikit-Learn为大多数参数提供了合理的默认
值,从而可以快速搭建起一个基本的工作系统。
2.9处理文本和分类属性
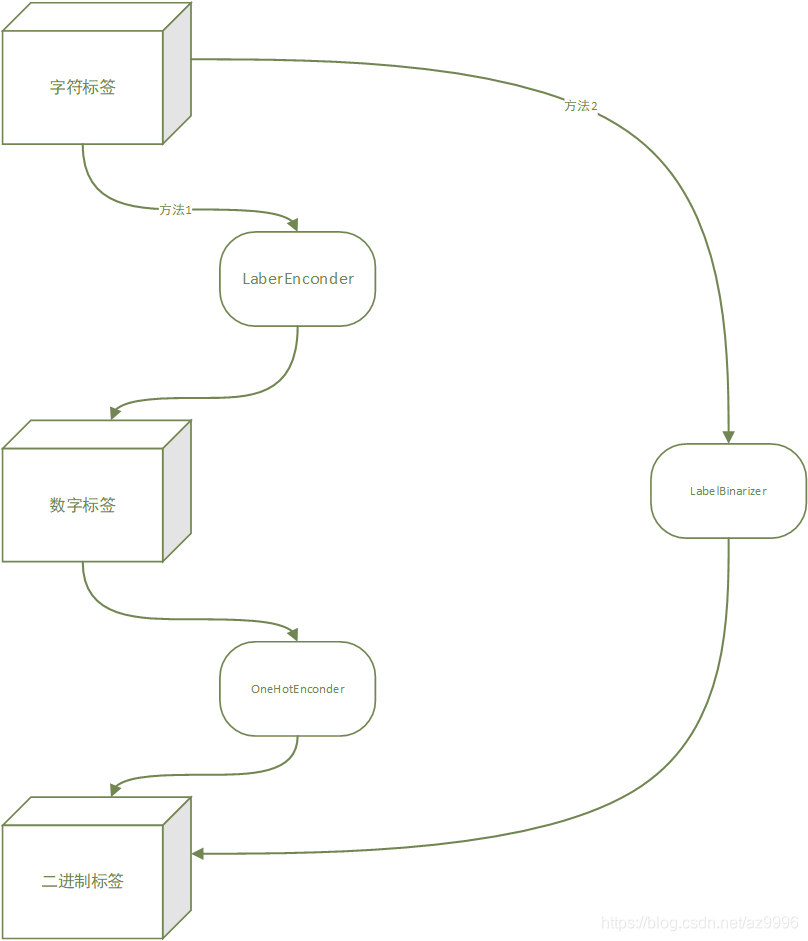
稀疏矩阵转密集矩阵:toarry()
2.10自定义转换器
虽然Scikit-Learn已经提供了许多有用的转换器,但是你仍然需要你当然希望让自己的转换器与Scikit-Learn自身的功能(比如流水线)无缝衔接,而由于Scikit-Learn依赖于鸭子类型(duck typing)的编译,而不是继承,所以你所需要的只是创建一个类,然后应用以下三个方法:fit()(返回自身)、transform()、fit_transform()。如果添加TransformerMixin作为基类,就可以直接得到最后一个方法。同时,如果添加BaseEstimator作为基类(并在构造函数中避免*args和kargs),你还能额外获得两个非常有用的自动调整超参数的方法(get_params()和set_params())**。
2.11特征缩放
这里讲的很好,讲解了为什么要进行特征缩放。
2.11.1最小-最大缩放(又叫作归一化)
很简单:将值重新缩放使其最
终范围归于0到1之间。实现方法是将值减去最小值并除以最大值和最
小值的差。对此,Scikit-Learn提供了一个名为MinMaxScaler的转换
器。如果出于某种原因,你希望范围不是0~1,你可以通过调整超参
数feature_range进行更改。
2.11.2标准化
标准化则完全不一样:首先减去平均值(所以标准化值的均值总
是零),然后除以方差,从而使得结果的分布具备单位方差。不同于
最小-最大缩放的是,标准化不将值绑定到特定范围,对某些算法而
言,这可能是个问题(例如,神经网络期望的输入值范围通常是0到
1)。但是标准化的方法受异常值的影响更小。例如,假设某个地区
的平均收入等于100(错误数据)。最小-最大缩放会将所有其他值从
0~15降到0~0.15,而标准化则不会受到很大影响。Scikit-Learn提供
了一个标准化的转换器StandadScaler。
2.12转换流水线(相当有用的利器)
from sklearn.pipeline import Pipeline
Pipeline构造函数会通过一系列名称/估算器的配对来定义步骤的序列。除了最后一个是估算器之外,前面都必须是转换器(也就是说,必须有fit_transform()方法)。至于命名,可以随意,你喜欢就好。
当调用流水线的fit()方法时,会在所有转换器上按照顺序依次调用fit_transform(),将一个调用的输出作为参数传递给下一个调用方法,直到传递到最终的估算器,则只会调用fit()方法。
流水线的方法与最终的估算器的方法相同。在本例中,最后一个估算器是StandardScaler,这是个转换器,因此Pipeline有transform()方法可以按顺序将所有的转换应用到数据中(如果不希望先调用fit()再调用transform(),也可以直接调用fit_transform()方法)。现在,你已经有了一个处理数值的流水线,接下来你需要在分类值上应用LabelBinarizer:不然怎么将这些转换加入单个流水线中?Scikit-Learn为此特意提供了一个FeatureUnion类。你只需要提供一个转换器列表(可以是整个转换器流水线),当transform()方法被调用时,它会并行运行每个转换器的transform()方法,等待它们的输出,然后将它们连结起来,返回结果(同样地,调用fit()方法也会调用每个转换器的fit()方法)。
endtime:12点06分
begintime:2019-05-01
from sklearn.pipeline import FeatureUnion
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
old_num_pipeline = Pipeline([
('selector', OldDataFrameSelector(num_attribs)),
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', FunctionTransformer(add_extra_features, validate=False)),
('std_scaler', StandardScaler()),
])
old_cat_pipeline = Pipeline([
('selector', OldDataFrameSelector(cat_attribs)),
('cat_encoder', OneHotEncoder(sparse=False)),
])
old_full_pipeline = FeatureUnion(transformer_list=[
("num_pipeline", old_num_pipeline),
("cat_pipeline", old_cat_pipeline),
])
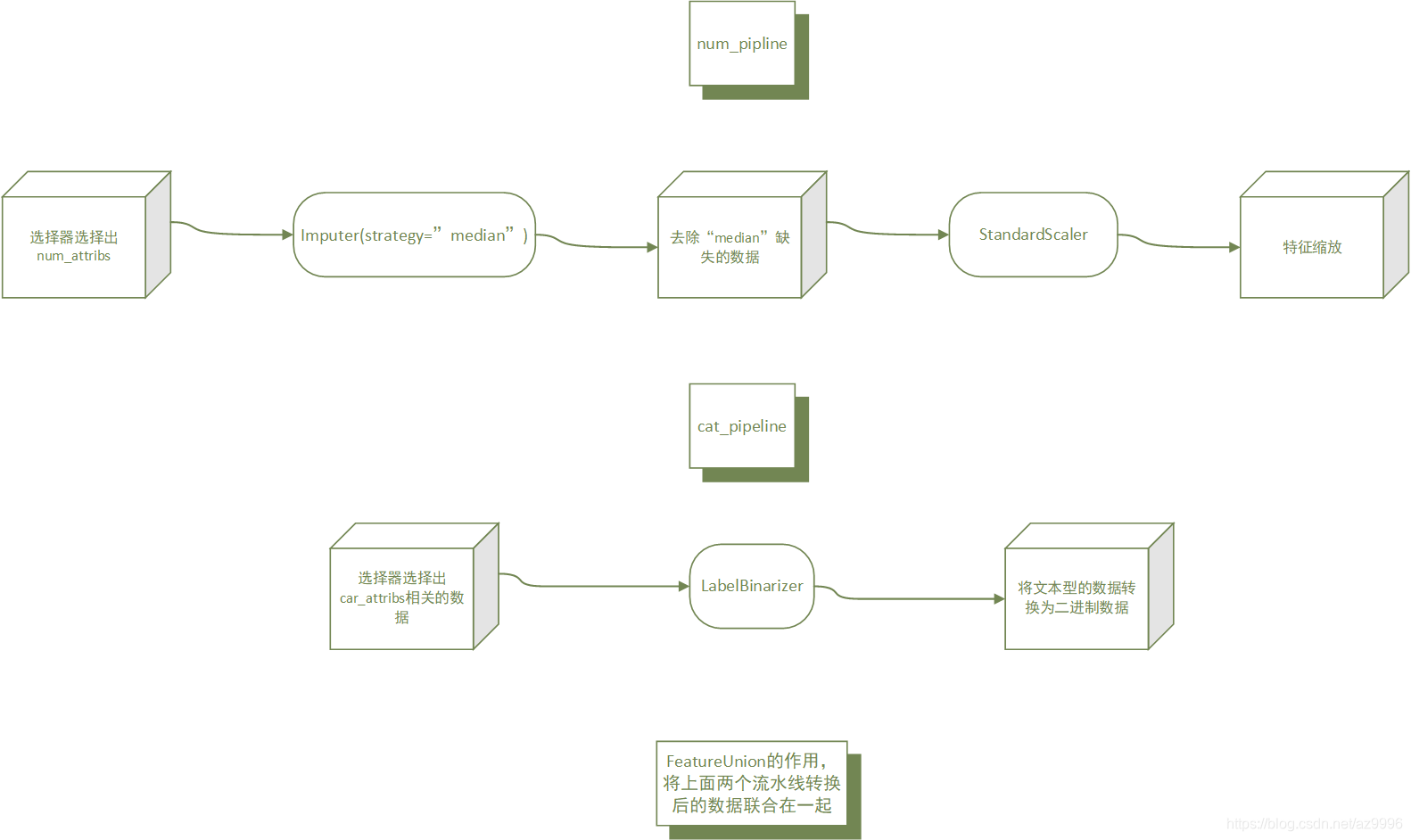
流水线的好处:将数据处理的流水线搭建起来后,只需将原始数据投入流水线即可获得处理过的数据,无论数据经历了几个处理阶段,对我们而言只是经历了一个流水线。并且自动化程度高。
some_data = housing.iloc[:5] #取房屋数据的前5行
some_labels = housing_labels.iloc[:5] #取标签数据的前5行
some_data_prepared = full_pipeline.transform(some_data) #将原始数据投入流水线,就获得了处理完毕的数据
print("Predictions:", lin_reg.predict(some_data_prepared))
这就是一个典型的模型对训练数据拟合不足的案例。这种情况发生时,通
常意味着这些特征可能无法提供足够的信息来做出更好的预测,或者
是模型本身不够强大。我们在上一章已经提到,想要修正拟合不足,
可以通过选择更强大的模型,或是为算法训练提供更好的特征,又或
者是减少对模型的限制等方法。我们这个模型不是一个正则化的模
型,所以就排除了最后那个选项。你可以试试添加更多的特征(例
如,人口数量的日志),但首先,让我们尝试一个更复杂的模型,看
看它到底是怎么工作的。
-----------摘自书中
2.13使用交叉验证更好的进行评估
评估决策树模型的一种方法是使用train_test_split函数将训练集分
为较小的训练集和验证集,然后根据这些较小的训练集来训练模型,
并对其进行评估。这虽然有一些工作量,但是不会太难,并且非常有
效。
另一个不错的选择是使用Scikit-Learn的交叉验证功能。以下是执
行K-折(K-fold)交叉验证的代码:它将训练集随机分割成10个不同
的子集,每个子集称为一个折叠(fold),然后对决策树模型进行10
次训练和评估——每次挑选1个折叠进行评估,使用另外的9个折叠进
行训练。产出的结果是一个包含10次评估分数的数组:
Scikit-Learn的交叉验证功能更倾向于使用效用函数(越大越
好)而不是成本函数(越小越好),所以计算分数的函数实际上是负
的MSE(一个负值)函数,这就是为什么上面的代码在计算平方根之
前会先计算出-scores。
sklearn.model_selection.cross_val_score(
estimator, #要评估的模型
X, #要测试的数据
y=None, #监督学习情况下为标签值
groups=None,
scoring=None, #评分器的类型,如果为None则使用默认,如果为"neg_mean_squared_error"则使用RMSE来进行评估。
cv=’warn’, #交叉验证的分割策略,有多种可能:如果为数字,指定(分层的)KFold中的折叠数;如果为None,使用默认的3倍交叉验证;(这里列出两种)
n_jobs=None,
verbose=0,
fit_params=None,
pre_dispatch=‘2*n_jobs’,
error_score=’raise-deprecating’)
显示评分:
def display_scores(scores):
print("Scores:", scores) #分数
print("Mean:", scores.mean()) #均值
print("Standard deviation:", scores.std()) #标准偏差
display_scores(tree_rmse_scores)
2.14保存好训练的模型
每一个尝试过的模型你都应该妥善保存,这样将来你可以轻
松回到你想要的模型当中。记得还要同时保存超参数和训练过的参
数,以及交叉验证的评分和实际预测的结果。这样你就可以轻松地对
比不同模型类型的评分,以及不同模型造成的错误类型。通过Python
的pickel模块或是sklearn.externals.joblib,你可以轻松保存Scikit-Learn
模型,这样可以更有效地将大型NumPy数组序列化:
from sklearn.externals import joblib
joblib.dump(my_model, "my_model.pkl")
# and later...
my_model_loaded = joblib.load("my_model.pkl")
endtime:17点36分
begintime:2019-05-02-09点15分
2.15微调模型
2.15.1网格搜索(适用于组合数量较少的情况)
一种微调的方法是手动调整超参数,找到一组很好的超参数值组
合。这个过程非常枯燥乏味,你可能坚持不到足够的时间来探索出各
种组合。
(在上一本书中采用的是这种方法,选择一组超参数的值和对应的模型评分,用可视化的方法绘出,然后判断哪一个超参数最佳。)
相反,你可以用Scikit-Learn的GridSearchCV来替你进行探索。你
所要做的只是告诉它你要进行实验的超参数是什么,以及需要尝试的
值,它将会使用交叉验证来评估超参数值的所有可能的组合。例如,
下面这段代码搜索RandomForestRegressor的超参数值的最佳组合:
在这本书中更注重介绍scikit-learn库中的方法。同时他也会讲解内部的原理。
from sklearn.model_selection import GridSearchCV
#网格参数,定制
#对于字典1:有3*4=12种情况
#对于字典2:有2*3=6种情况
#param_grid告诉Scikit-Learn,首先评估第一个dict中的
#n_estimator和max_features的所有3×4=12种超参数值组合(先不要担
#心这些超参数现在意味着什么,我们将在第7章中进行解释),接
#着,尝试第二个dict中超参数值的所有2×3=6种组合,但这次超参数
#bootstrap需要设置为False而不是True(True是该超参数的默认值)。
#总共18种,网格搜索会对18种情况分别进行K-折交叉验证,折的数量由参数cv制定。
param_grid = [
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor() #要验证的模型
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error' #模型的评分器设置为:回归均方误差评分器。
)
grid_search.fit(housing_prepared, housing_labels) #启动
当你不知道超参数应该赋什么值时,一个简单的方法是连续
尝试10的幂次方(如果你想要得到更细粒度的搜索,可以参考这个例
子中所示的n_estimators超参数)。
总而言之,网格搜索将探索RandomForestRegressor超参数值的12+6=18种组合,并对每个模型进行五次训练(因为我们使用的是5-折交叉验证)。换句话说,总共会完成18×5=90次训练!这可能需要相当长的时间,但是完成后你就可以获得最佳的参数组合:
使用GridSearchCV.best_params_方法获得最佳参数组合:
>>> grid_search.best_params_
{'max_features': 6, 'n_estimators': 30}
使用GridSearchCV.best_estimator_方法查看最好的估计器
>>> grid_search.best_estimator_
RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,
max_features=6, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=30, n_jobs=1, oob_score=False, random_state=None,
verbose=0, warm_start=False)
参数refit
如果GridSearchCV被初始化为refit=True(这也是默认值),那么一旦通过交叉验证找到了最佳估算器,它将在整个训练集上重新训练。这通常是个好方法,因为提供更多的数据很可能提升其性能。
使用GridSearchCV.cv_results_方法查看评估分数
>>> cvres = grid_search.cv_results_
... for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
... print(np.sqrt(-mean_score), params)
随机搜索
如果探索的组合数量较少——例如上一个示例,网格搜索是一个
不错的方法;但是当超参数的搜索范围(search space)较大时,通常
会优先选择使用RandomizedSearchCV。这个类用起来与GridSearchCV
类大致相同,但它不会尝试所有可能的组合,而是在每次迭代中为每
个超参数选择一个随机值,然后对一定数量的随机组合进行评估。这
个方法有两个显著特性:
·如果运行随机搜索1000个迭代,那么将会探索每个超参数的
1000个不同的值(而不是像网格搜索方法那样每个超参数仅探索少量
几个值)。
·通过简单地设置迭代次数,可以更好地控制要分配给探索的超
参数的计算预算。
集成方法
还有一种微调系统的方法是将表现最优的模型组合起来。组合
(或“集成”)方法通常比最佳的单一模型更好(就像随机森林比其所
依赖的任何单个决策树模型更好一样),特别是当单一模型会产生严
重不同类型的错误时更是如此
分析最佳模型及其错误
使用GridSearchCV.best_estimator_.feature_importances_方法查看每个属性的相对重要程度,一重要性分数的方式展示。
通过测试集评估系统
启动、监控和维护系统
小总结
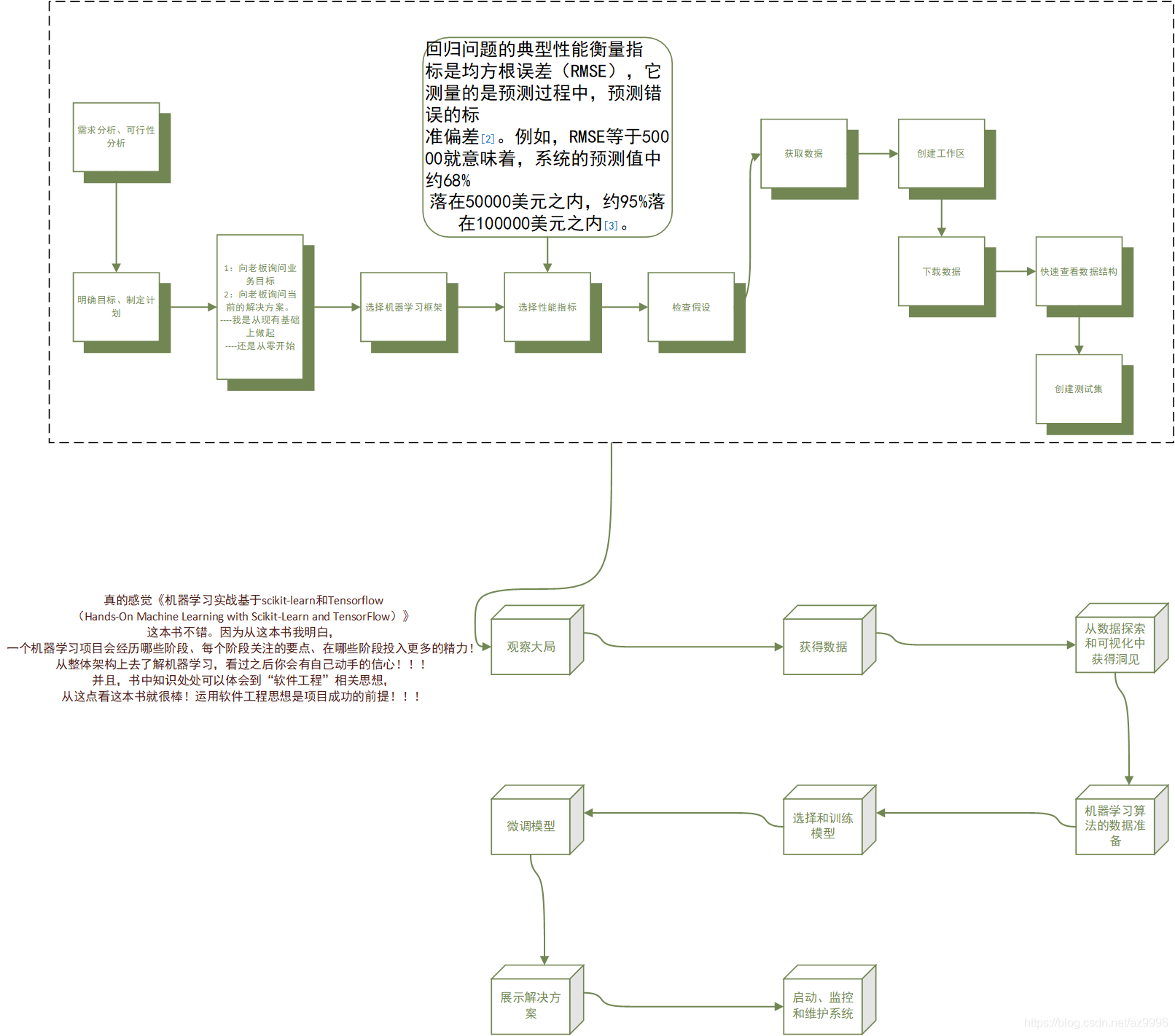
endtime:11点04分