在前面我们已经讲过RHCS集群管理apache,那么在这章我们来学习haproxy+pacemaker实现集群管理
实验环境
server1,server2:集群节点
server3,server4:后端服务器
一,配置haproxy
在server1:
安装haproxy,并配置主配置文件,安装我们在之前学习haproxy时已经学习过,这里就不多说了,我们直接来配置主配置文件
global
maxconn 10000
stats socket /var/run/haproxy.stat mode 600 level admin
log 127.0.0.1 local0
uid 200
gid 200
chroot /var/empty
daemon
defaults
mode http
log global
option httplog
option dontlognull
monitor-uri /monitoruri
maxconn 8000
timeout client 30s
option prefer-last-server
retries 2
option redispatch
timeout connect 5s
timeout server 5s
stats uri /admin/stats
# The public 'www' address in the DMZ
frontend public
bind 172.25.77.100:80 #添加虚拟ip
#bind *:80 name clear
#bind 192.168.1.10:443 ssl crt /etc/haproxy/haproxy.pem
#use_backend static if write
#use_backend dynamic if read
default_backend static
#errorloc 403 http://172.25.77.1:8080/index.html
# the application servers go here
backend static ##后端
balance roundrobin
server web1 172.25.77.3:80 check inter 1000
server web2 172.25.77.4:80 check inter 1000
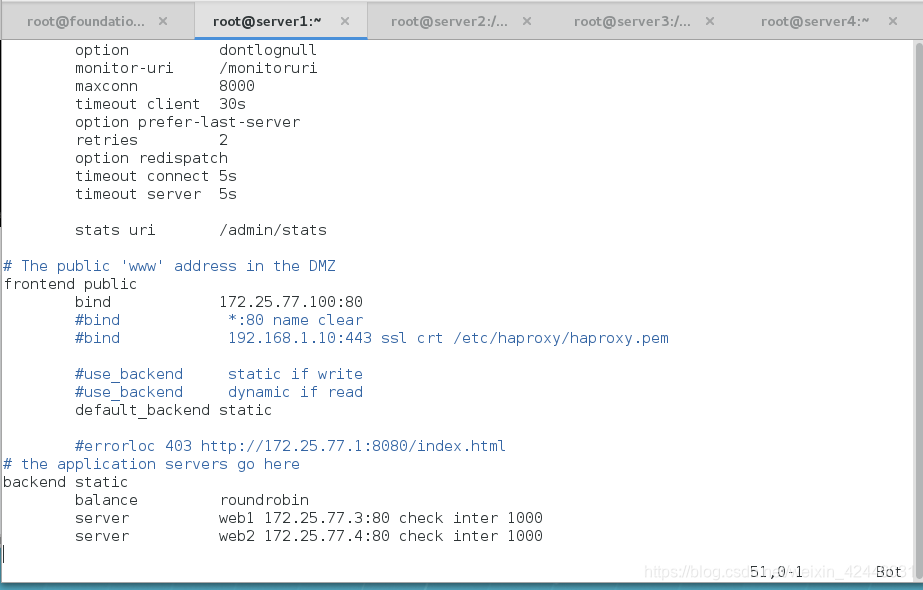
ip addr add 172.25.77.100/24 dev eth0 #添加虚拟ip
cat /etc/security/limits.conf | tail -n 1 #查看haproxy最大接收文件大小
/etc/init.d/haproxy start #开启haproxy
ip add #查看虚拟ip是否加上了
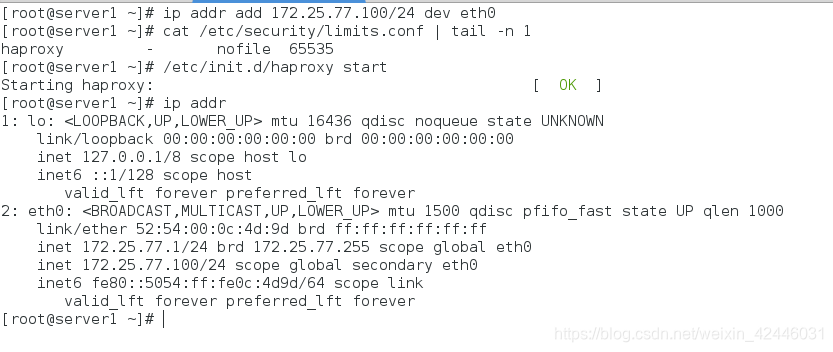
在server1上测试负载均衡(轮询调度)
首先配置server3,server4的httpd默认发布文件


测试:
二,配置pacemaker
Pacemaker是一个集群资源管理器。它利用集群基础构件
(OpenAIS 、heartbeat或corosync)提供的消息和成
员管理能力来探测并从节点或资源级别的故障中恢复,以实现
群集服务(亦称资源)的最大可用性。
在硬件层面我们可以看到多个节点上启用了不同服务,如数据库,
Apache服务等,这里你可以看到有个standby machine,这
台机器就是当前两个服务不能在它原来的节点上运行时提供备用
的。这样能保证如果某一台机器的Apache服务或者某一台机器
的数据库服务挂了,那么马上在另外一个节点上能够启动该服务。
当然首先这三个节点都是要默认安装这些服务并且做配置的。那
么这样看起来我们能够通过增加节点来提供高可用解决单点故障。
这也是HA要做的主要工作。
pacemaker作为linux系统高可用HA的资源管理器,位于HA集
群架构中的资源管理,资源代理层,它不提供底层心跳信息传递
功能。(心跳信息传递是通过corosync来处理的这个使用有兴
趣的可以在稍微了解一下,其实corosync并不是心跳代理的唯
一组件,可以用hearbeat等来代替)。pacemaker管理资源
是通过脚本的方式来执行的。我们可以将某个服务的管理通过
shell,python等脚本语言进行处理,在多个节点上启动相同
的服务时,如果某个服务在某个节点上出现了单点故障那么pacemaker
会通过资源管理脚本来发现服务在改节点不可用。
pacemaker只是作为HA的资源管理器,所以不要想当然理解它能够
直接管控资源,如果你的资源没有做脚本配置那么对于pacemaker
来说它就是不可管理的。
Corosync是集群管理套件的一部分,它在传递信息的时候可以
通过一个简单的配置文件来定义信息传递的方式和协议等。
传递心跳信息和集群事务信息,pacemaker工作在资源分配层,提供资
源管理器的功能,并以crmsh这个资源配置的命令接口来配置资源
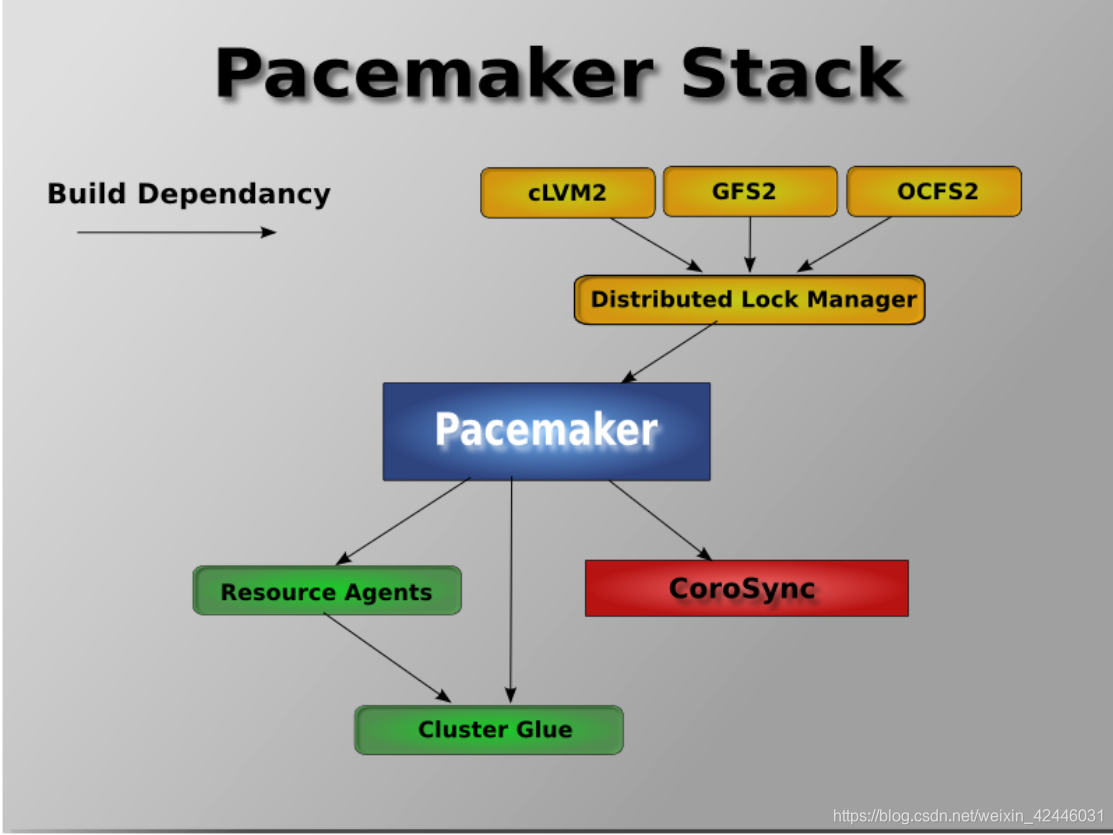
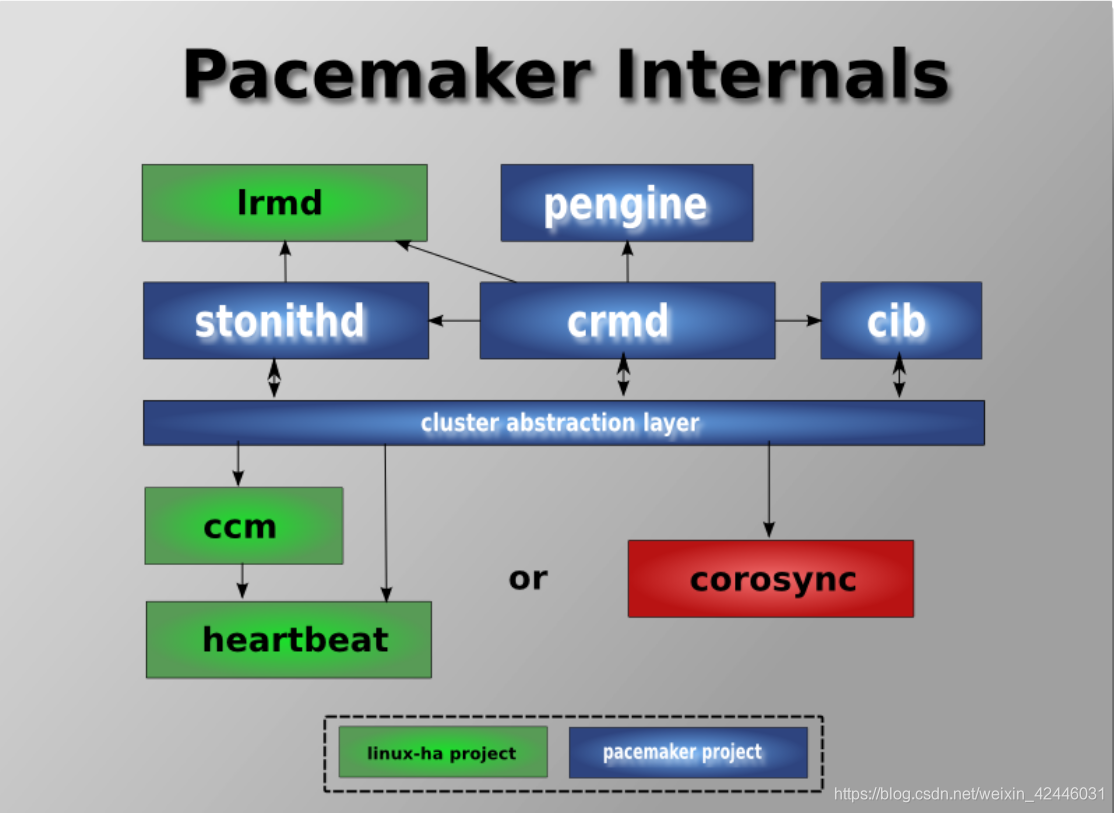
pacemaker内部组件
Pacemaker本身由四个关键组件组成:
•CIB (aka. 集群信息基础)
•CRMd (aka. 集群资源管理守护进程)
•PEngine (aka. PE or 策略引擎)
•STONITHd
在server1:
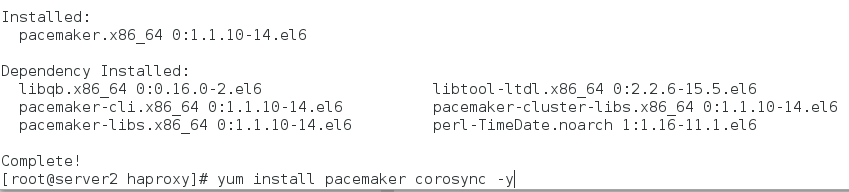
yum install pacemaker corosync -y 安装pacemaker
cp /etc/corosync/corosync.conf.example /etc/corosync/corosync.conf
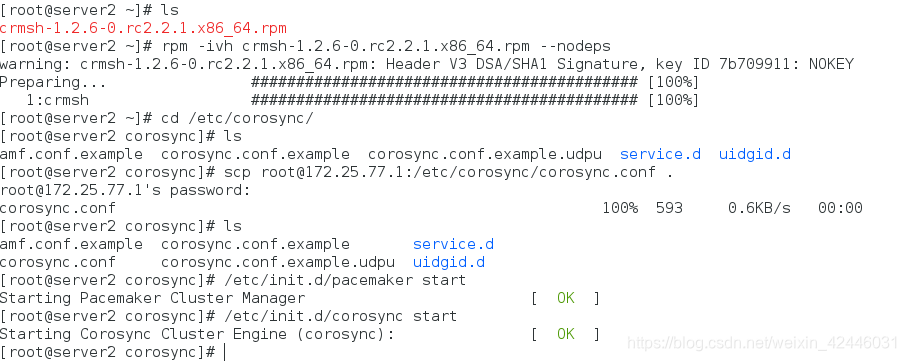
rpm -ivh crmsh-1.2.6-0.rc2.2.1.x86_64.rpm --nodeps 安装crm
rpm -ivh pssh-2.3.1-2.1.x86_64.rpm 安装组件pssh




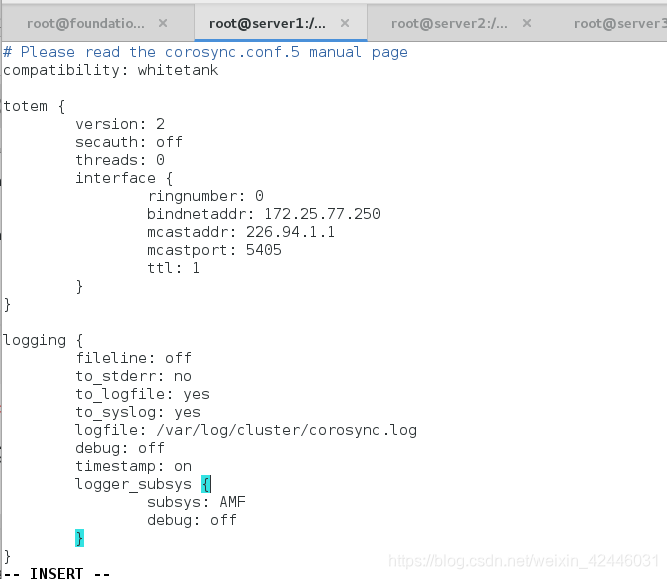
修改配置文件:vim /etc/corosync/corosync.conf

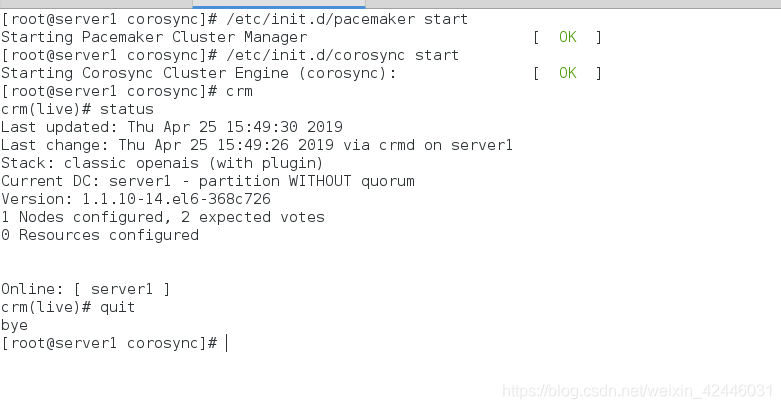
/etc/init.d/pacemaker start
/etc/init.d/corosync start
crm #打开集群管理控制
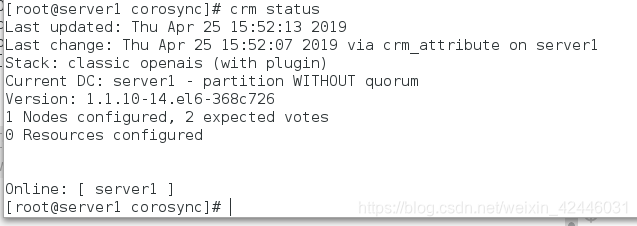
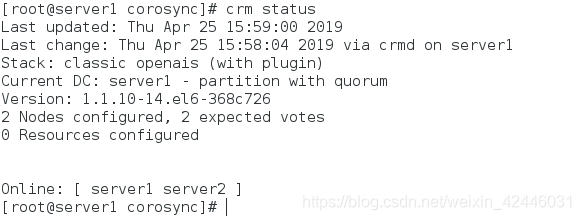
查看节点状态
在server2:
首先安装pacemaker和corosync,然后将server1的corosync配置文件导入本节点,然后启动相关服务
查看集群状态
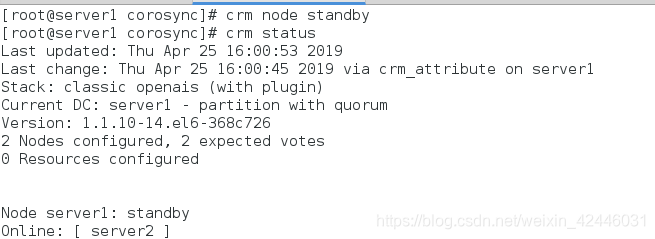
在server1上关闭节点server1
在server1上开启节点
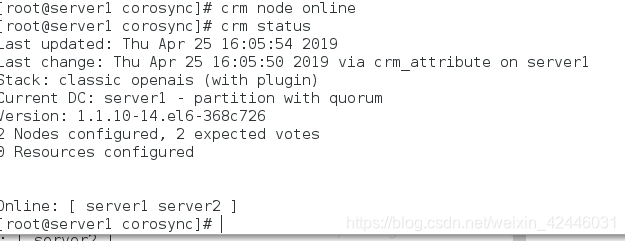
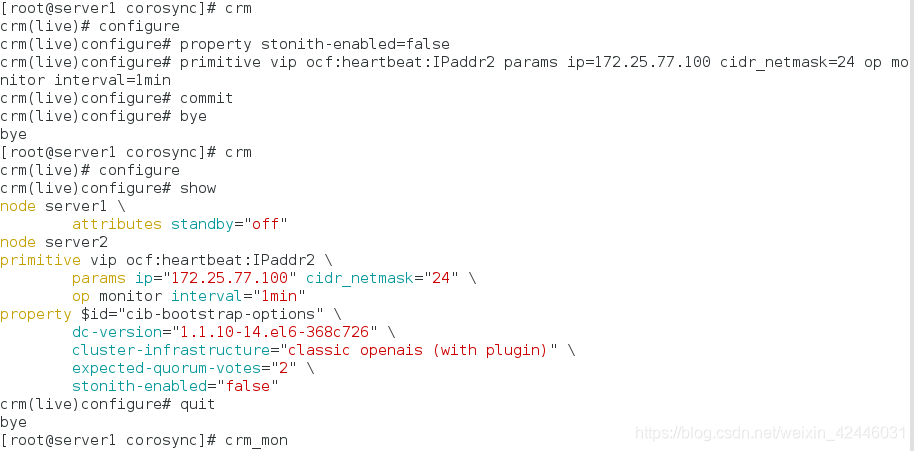
在server1上进行crm测试
[root@server1 corosync]# crm
crm(live)# configure
crm(live)configure# property stonith-enabled=false
crm(live)configure# primitive vip ocf:heartbeat:IPaddr2 params ip=172.25.77.100 cidr_netmask=24 op monitor interval=1min #添加vip
crm(live)configure# commit #保存
crm(live)configure# bye
bye
[root@server1 corosync]# crm
crm(live)# configure
crm(live)configure# show
node server1 \
attributes standby="off"
node server2
primitive vip ocf:heartbeat:IPaddr2 \
params ip="172.25.77.100" cidr_netmask="24" \
op monitor interval="1min"
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2" \
stonith-enabled="false"
crm(live)configure#
[root@server1 corosync]# crm_mon #监控
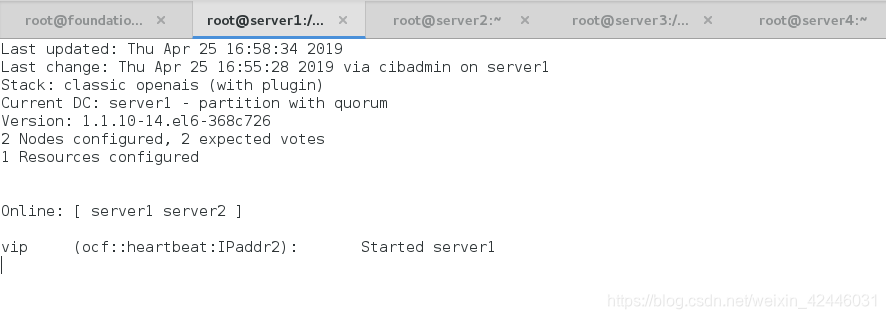
在server1的监控下看server2
检测语法错误:

没显示则表示没错误
查看vip是否添加

关闭server2的corosync查看server1的监控

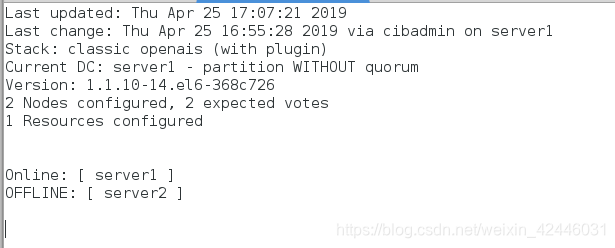
重新打开server2

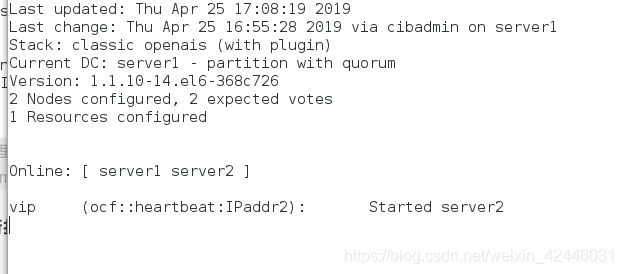
配置策略
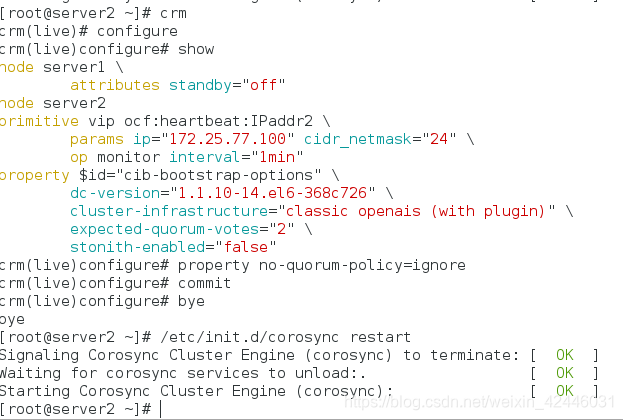
在server2上安装haproxy实现高可用
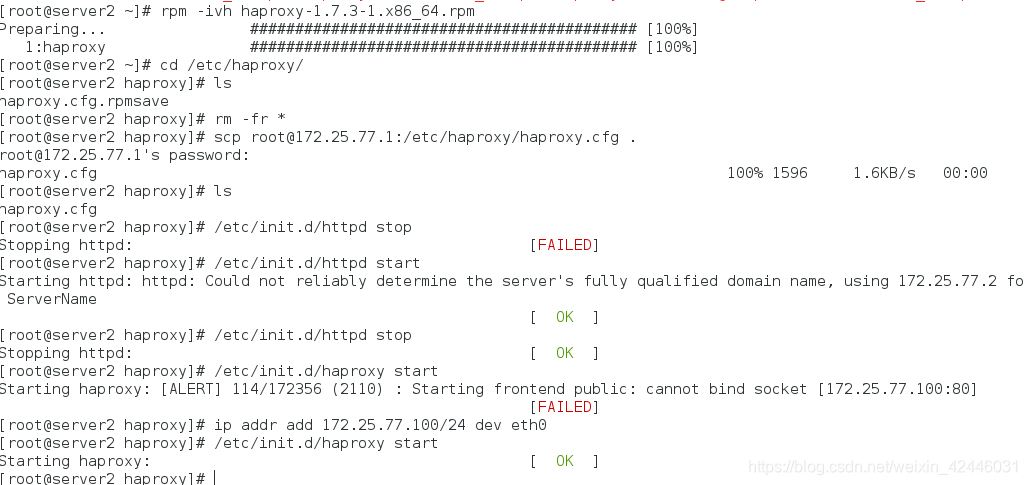
在server1上开启haproxy,并且配置crm
crm(live)configure# primitive haproxy lsb:haproxy op monitor interval=1min
crm(live)configure# group hagroup vip haproxy添加组防止同样的服务在不同的节点
crm(live)configure# commit 提交策略
crm(live)configure#
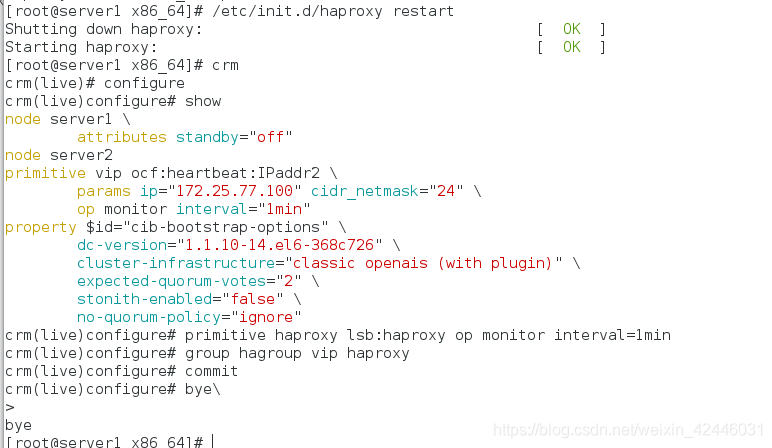
server2进行监控
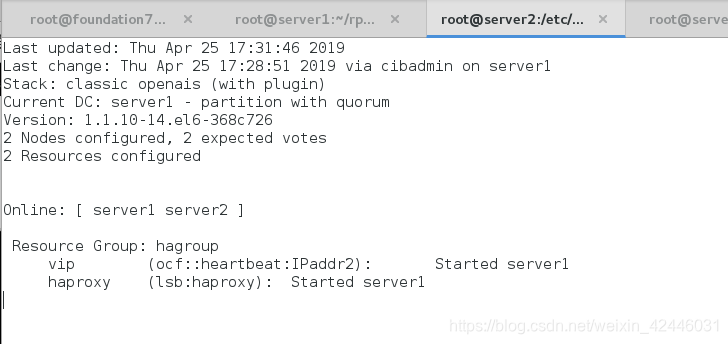
crm node standby将节点一挂掉然后查看监控
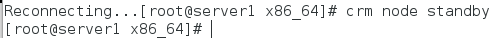
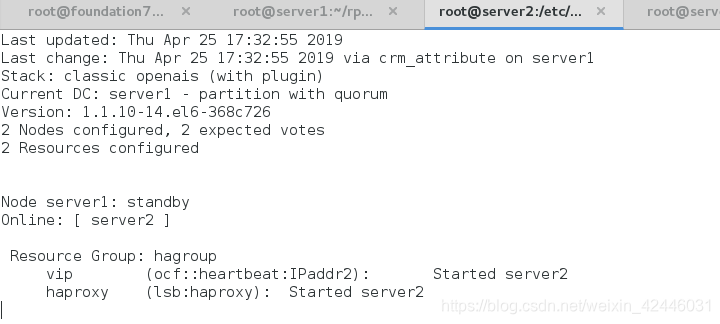
在重新打开节点一

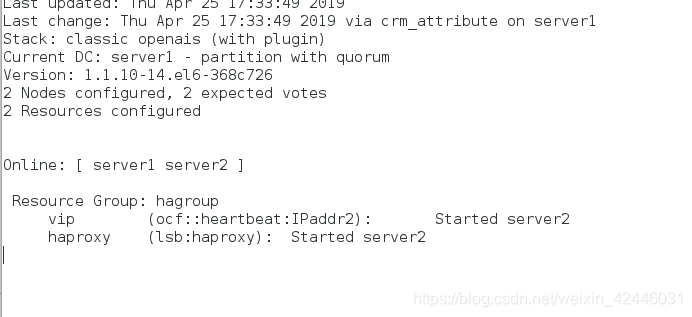
我们可以发现在server1挂了之server2节继续工作,不会出现单点故障问题,实现高可用
fence
我们在之前学习RHCS集群套件时了解过fence,那么我们的pacemaker也是有fence的
首先我们在物理机打开fence
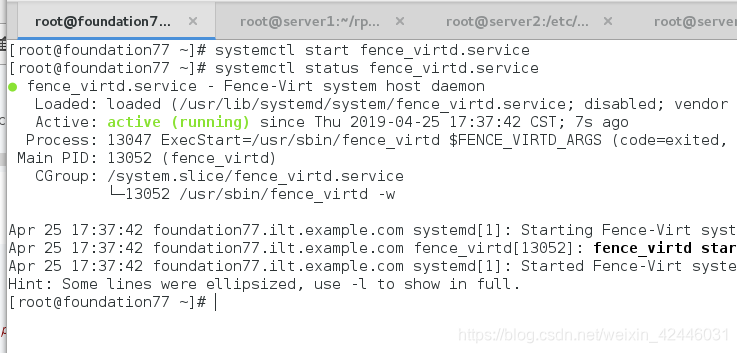
在server1查看fence的配置
注意:如果没有配置,查看博主的前面关于RHCS的配置里面有喜爱嗯西配置
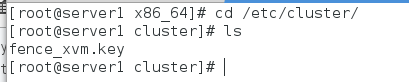
在server2查看fence配置
crm开启fence
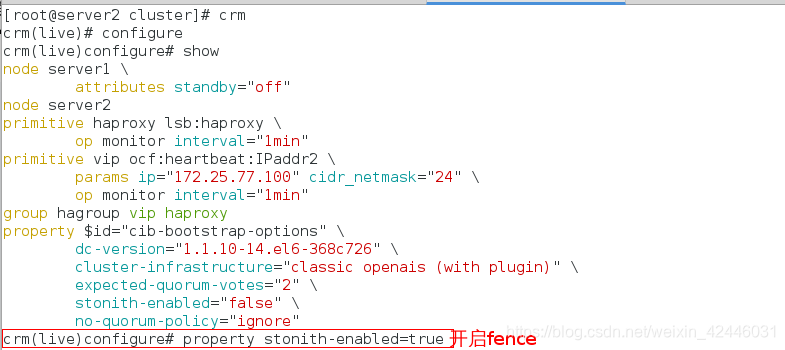
添加fence块
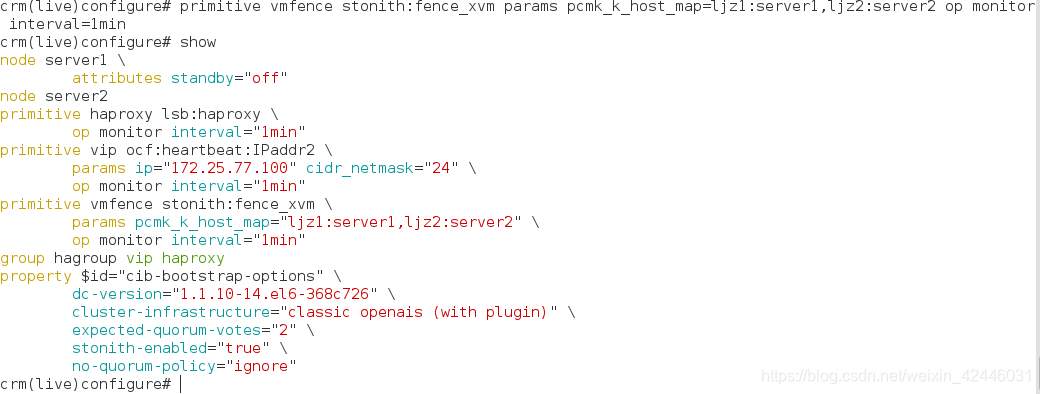
查看监控:
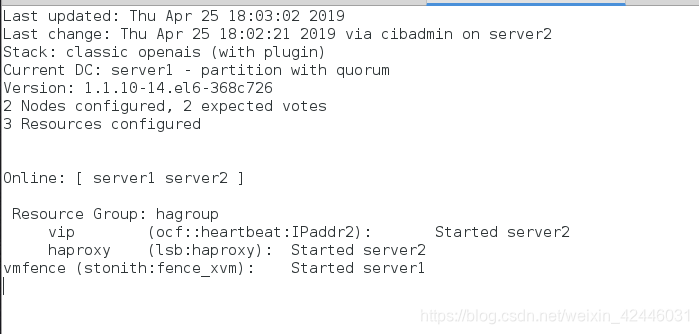
摧毁server1

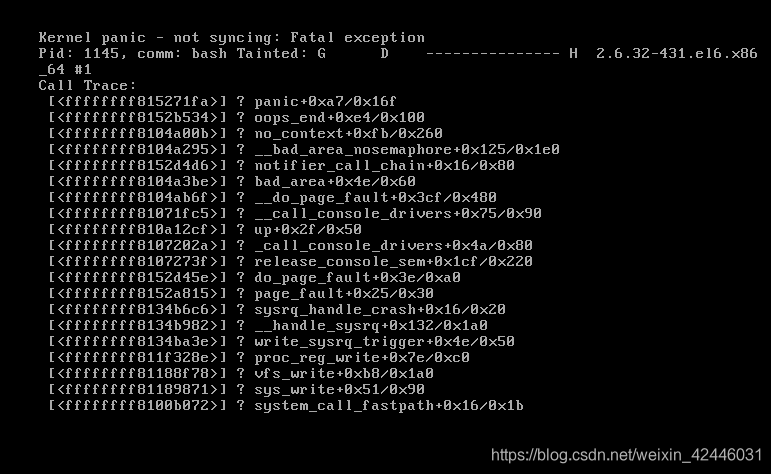
然后查看监控即可