哈哈,本章的学习小结与以往小结不同,本次小结将任选本章一道题目,来写下解决该题的心得体会.
本章的学习内容是串和数组,而在串的学习过程中,老师带我们认识了两种算法-----BF算法和KMP算法,这也是我本章学习小结想要介绍的内容。
下面是一道关于串的模式匹配的题目
当我第一次做这道题目时,我采用的是BF算法,那什么是BF算法呢,简单概括一下啊,那就是暴力匹配,就是按照人的常规思维去匹配字符串,拿子串(P)的第一个字符去和主串(S)比较,S从左往右看,一看,第一个不对,后边就不用比较了。所以,这一次比较,S中第一个字符开头是匹配串就不可能了,然后就拿P的第一个字符,去和S中第二个字符开头的比较,如果对上了就再往后看,全对上了,那么恭喜你,程序结束了,没对上,也不要气馁,开始看S的第三个字符开头的字符串……如此一遍遍重复,直到找到匹配串。该算法暴力,简单,但复杂度高----O(n2),一次就找到算你幸运,但是,形如“0000000001”的串S和形如“000001”的匹配起来就麻烦了,每次移动一个,看到P串的最后一个才发现不行,直到P串移动到最后。所以这种算法的小缺点也导致了我在PTA上提交的程序不能够拿到满分。
没办法,只能够去使用KMP算法了,可是对于我而言,KMP算法在课上没有弄懂,于是我便上网查询一些资料,才对KMP算法有了一定的了解。KMP算法于BF算法不同的是,BF算法是每次匹配结束后让P串简单地往后移动一个,而KMP算法却可以移动k个。因为,我们每次比较时,前若干字符在上一次比较中的情况已经知道了,所以我们在下一次比较时,可以利用上一次比较的结果,不用再去做无用功了。这是KMP算法相较于BF算法的优势吧。而为什么可以移动k次还可以不错过正确部分,我认为应该是由串P的前缀和后缀的重复性决定的。
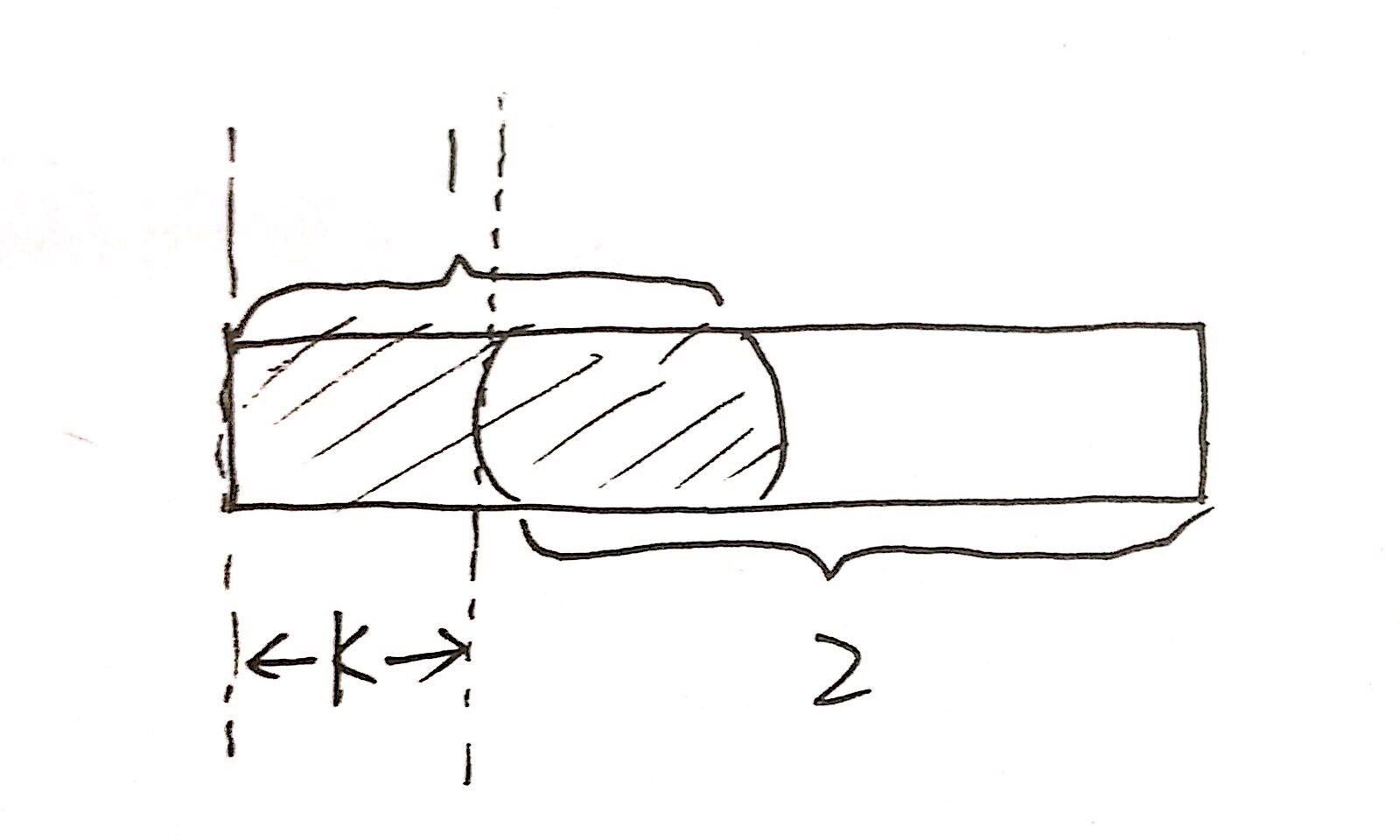
那什么是前缀和后缀呢,举个简单的例子,字符串“ababa” 的所有前缀为“a”、“ab”、“aba”、“abab”,就是以第一个字符开头,不包含最后一个字符的所有子串。同理,所有后缀就是“a”、“ba”、“aba”、“baba”,就是以最后一个字符结尾,不包含第一个字符的所有子串。接下来我要介绍的重复性,是指前缀和后缀之间重复的部分,只有搞清楚这些重复的部分,才可以在向后移动的时候,把前面一部分直接拿来用,下面是一张网上的资料图帮助理解,可以看到1部分和2部分有重复的,而1部分又已经匹配过了,那么k部分无需再检测匹配了,即移动k个开始匹配2部分,所以可以得到前进的k=已经匹配的字符串长度-前缀和后缀最长公共部分
以上就是我本章的学习小结,在这章的学习当中,我参考了网站https://www.cnblogs.com/wktwj/p/4880888.html ,这是对KMP算法的理解,希望以后可以更好地用好KMP算法。