一、基础知识
1. JVM实例:JVM实例对应了一个独立运行的java程序,它是进程级别。
2. JVM执行引擎实例:JVM执行引擎实例则对应了属于用户运行程序的线程,它是线程级别的。
3. JVM生命周期:
- JVM实例的诞生:当启动一个Java程序时,一个JVM实例就产生了。
- JVM实例的运行: main()作为该程序初始线程的起点,任何其他线程均由该线程启动。
- JVM实例的消亡:当程序中的所有非守护线程都终止时,JVM才退出;若安全管理器允许,程序也可以使用Runtime类或者System.exit()来退出。
注: JVM内部有两种线程:守护线程和非守护线程,main()属于非守护线程,守护线程通常由JVM自己使用,java程序也可以标明自己创建的线程是守护线程。
任何一个拥有public static void main(String[] args)函数的class都可以作为JVM实例运行的起点
二、JVM结构
JVM可以由不同的厂商来实现。由于厂商的不同必然导致JVM在实现上的一些不同,然而JVM还是可以实现跨平台的特性,这就要归功于设计JVM时的体系结构了。
JVM体系结构包含三部分:
- 类加载器(Class Loader)子系统:类加载器(class loader)用来加载 Java 类到 Java 虚拟机中。一般来说,Java 虚拟机使用 Java 类的方式如下:Java 源程序(.java 文件)在经过 Java 编译器编译之后就被转换成 Java 字节代码(.class 文件)。类加载器负责读取 Java 字节代码,并转换成
java.lang.Class类的一个实例。每个这样的实例用来表示一个 Java 类。通过此实例的newInstance()方法就可以创建出该类的一个对象。实际的情况可能更加复杂,比如 Java 字节代码可能是通过工具动态生成的,也可能是通过网络下载的。但第二次实例化一个类时,就从对应Class类newInstance(),不用每次都读取.class文件。 - 执行引擎(Execution Engine)
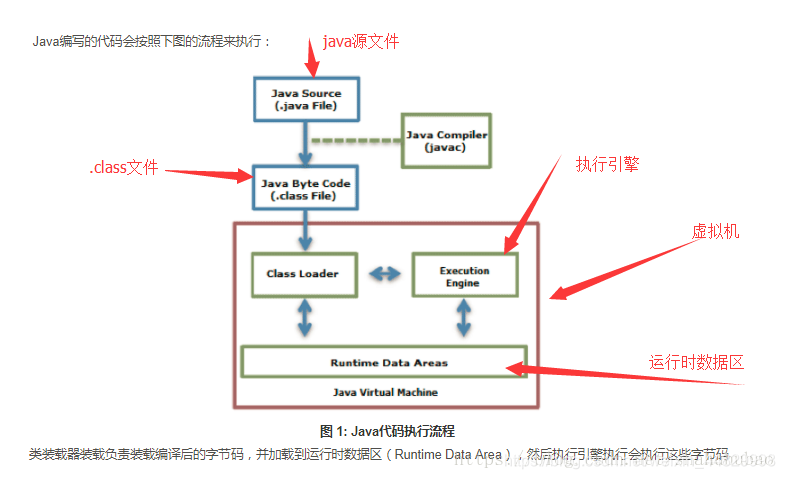
- 运行时数据区(Runtime Data Area):
Java程序执行过程
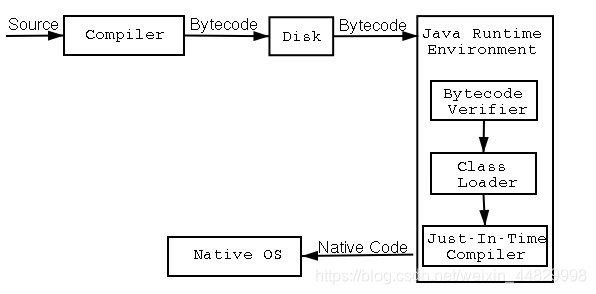
Java整个程序以及运行的过程相当繁琐,本文通过一个简单的程序来简单的说明整个流程。
如下图,Java程序从源文件创建到程序运行要经过两大步骤:1、源文件由编译器编译成字节码(ByteCode) 2、字节码由java虚拟机解释运行。因为java程序既要编译同时也要经过JVM的解释运行,所以说Java被称为半解释语言( "semi-interpreted" language)。

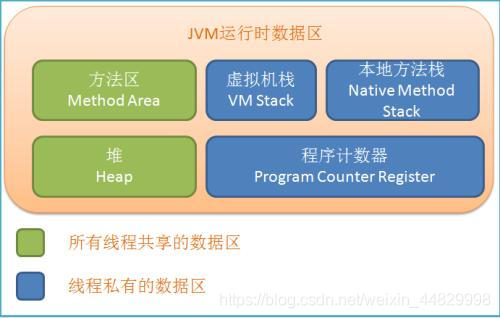
三、运行时数据区
程序计数器(Program Counter Register)、Java栈(VM Stack)、本地方法栈(Native Method Stack)、方法区(Method Area)、堆(Heap)
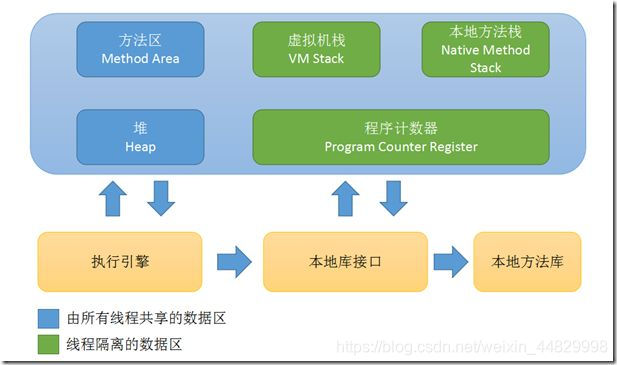
image.png
- 程序计数器(Program Counter Register)
- 程序计数器是一块较小的内存空间, 可以看作是当前线程所执行的字节码的行号指示器。 分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
- 由于Java 虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,我们称这类内存区域为 “线程私有” 的内存。
- 在JVM规范中规定,如果线程执行的是非native方法,则程序计数器中保存的是当前需要执行的指令的地址;如果线程执行的是native方法,则程序计数器中的值是undefined。
- 由于程序计数器中存储的数据所占空间的大小不会随程序的执行而发生改变,因此,对于程序计数器是不会发生内存溢出现象(OutOfMemory)的。
- Java栈(VM Stack)
Java栈也称作虚拟机栈(Java Vitual Machine Stack),是Java方法执行的内存模型。- Java栈中存放的是一个个的栈帧, 每个栈帧对应一个被调用的方法,在栈帧中包括局部变量表(Local Variables)、操作数栈(Operand Stack)、指向当前方法所属的类的运行时常量池(运行时常量池的概念在方法区部分会谈到)的引用(Reference to runtime constant pool)、方法返回地址(Return Address)和一些额外的附加信息。

image.png
- 当线程执行一个方法时,就会随之创建一个对应的栈帧,并将建立的栈帧压栈。当方法执行完毕之后,便会将栈帧出栈。
- 会有两种异常StackOverFlowError和 OutOfMemoneyError。当线程请求栈深度大于虚拟机所允许的深度就会抛出StackOverFlowError错误;虚拟机栈动态扩展,当扩展无法申请到足够的内存空间时候,抛出OutOfMemoneyError。
- 它是线程私有的,生命周期与线程相同。
- Java栈中存放的是一个个的栈帧, 每个栈帧对应一个被调用的方法,在栈帧中包括局部变量表(Local Variables)、操作数栈(Operand Stack)、指向当前方法所属的类的运行时常量池(运行时常量池的概念在方法区部分会谈到)的引用(Reference to runtime constant pool)、方法返回地址(Return Address)和一些额外的附加信息。
- 本地方法栈(Native Method Stack)
本地方法栈与Java栈的作用和原理非常相似。区别只不过是Java栈是为执行Java方法服务的, 而本地方法栈则是为执行本地方法(Native Method)服务的。- 在JVM规范中,并没有对本地方发展的具体实现方法以及数据结构作强制规定,虚拟机可以自由实现它。在HotSopt虚拟机中直接就把本地方法栈和Java栈合二为一。
- 与虚拟机栈一样,本地方法栈区域也会抛出StackOverflowError和OutOfMemoryError异常
- 方法区(Method Area)
JDK8之后-JVM运行时数据区域- JDK7及之前版本的方法区(Method Area)和Java堆一样, 是各个线程共享的内存区域,用于存储已经被虚拟机加载的类信息、常量、静态常量、即时编译器编译后的代码等数据。
- 在方法区中有一个非常重要的部分就是 运行时常量池 ,它是每一个类或接口的常量池的运行时表示形式, 在类和接口被加载到JVM后,对应的运行时常量池就被创建出来。当然并非Class文件常量池中的内容才能进入运行时常量池,在运行期间也可将新的常量放入运行时常量池中,比如String的intern方法。
package com.jvm;
import java.util.ArrayList;
import java.util.List;
/**
* -XX:MaxPermSize=20M 方法区最大大小20M
* Created by yulinfeng on 7/11/17.
*/
public class Test {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
int i = 0;
while (true) {
list.add(String.valueOf(i++).intern()); //不断创建线程
}
}
}
实际上对于以上代码,在JDK6、JDK7、JDK8运行结果均不一样。原因就在于字符串常量池在JDK6的时候还是存放在方法区(永久代)所以它会抛出OutOfMemoryError:Permanent Space;而JDK7后则将字符串常量池移到了Java堆中,上面的代码不会抛出OOM,若将堆内存改为20M则会抛出OutOfMemoryError:Java heap space;至于JDK8则是纯粹取消了方法区这个概念,取而代之的是”元空间(Metaspace)“,所以在JDK8中虚拟机参数”-XX:MaxPermSize”也就没有了任何意义,取代它的是”-XX:MetaspaceSize“和”-XX:MaxMetaspaceSize”等。
- 在JVM规范中,没有强制要求方法区必须实现垃圾回收。很多人习惯将方法区称为“永久代”,是因为HotSpot虚拟机以永久代来实现方法区,从而JVM的垃圾收集器可以像管理堆区一样管理这部分区域,从而不需要专门为这部分设计垃圾回收机制。不过自从JDK7之后,Hotspot虚拟机便将运行时常量池从永久代移除了。
- 堆(Heap)
- JVM中所管理内存中的最大的一块。在虚拟机启动时被创建。
- 唯一的目的是存放对象实例,几乎所有的对象实例和数组都是在这里分配内存。 (JVM规范中说的是所有的,但是随着JIT便编译器的发展和逃逸技术分析的成熟,一些实例可以不在这个区域分配内存)
- 程序员基本不用去关心空间释放的问题,Java的垃圾回收机制会自动进行处理,因此堆是垃圾收集管理的主要区域,所以也会被称为”GC堆“。
- 堆是被所有线程共享的,在JVM中只有一个堆。
- 浅堆和深堆
- 浅堆(Shallow Heap)和深堆(Retained Heap)是两个非常重要的概念,它们分别表示一个对象结构所占用的内存大小和一个对象被GC回收后,可以真实释放的内存大小。
- 浅堆(Shallow Heap)是指一个对象所消耗的内存。在32位系统中,一个对象引用会占据4个字节,一个int类型会占据4个字节,long型变量会占据8个字节,每个对象需要占用8个字节。
- 深堆(Retained Heap)的概念略微复杂。要理解深堆,首先需要了解保留集(Retained Set)。对象A的保留集指当对象A被垃圾回收后,可以被释放的所有对象集合(包括对象A本身),即对象A的保留集可以被认为是只能通过对象A被直接或间接访问到的所有对象的集合。通俗地说,就是指仅被对象A所持有的对象的集合。深堆是指对象的保留集中所有的对象的浅堆大小之和。
- 例如:对象A引用了C和D,对象B引用了C和E。那么对象A的浅堆大小只是A本身,不含C和D,而A的实际大小为A、C、D三者之和。而A的深堆大小为A与D之和,由于对象C还可以通过对象B访问到,因此不在对象A的深堆范围内。