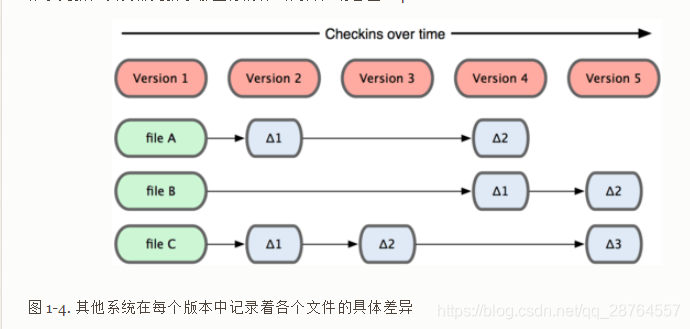
svn的记录方式。
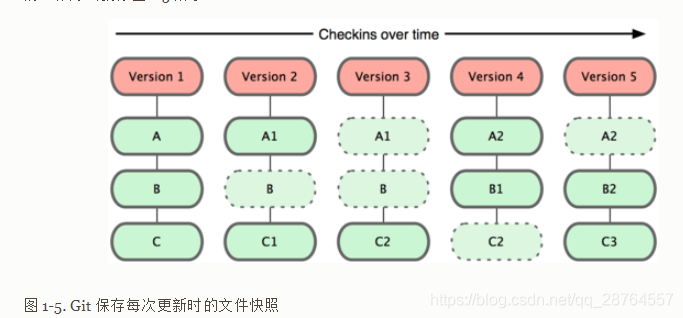
git的记录方式。
在 Git 中的绝大多数操作都只需要访问本地文件和资源,不用连网。因为 Git 在本地磁盘上就保存着所有当前项目的历史更新,所以处理起来速度飞快。但用 Git 的话,就算你在飞机或者火车上,都可以非常愉快地频繁提交更新,等到了有网络的时候再上传到远程仓库。同样,在回家的路上,不用连接 VPN 你也可以继续工作。在保存到 Git 之前,所有数据都要进行内容的校验和(checksum)计算,并将此结果作为数据的唯一标识和索引。Git 使用 SHA-1 算法计算数据的校验和,通过对文件的内容或目录的结构计算出一个 SHA-1 哈希值,作为指纹字符串。该字串由 40 个十六进制字符(0-9 及 a-f)组成,看起来就像是:
![]()
在 Git 内都只有三种状态:已提交(committed),已修改(modified)和已暂存(staged)。已提交表示该文件已经被安全地保存在本地数据库中了;已修改表示修改了某个文件,但还没有提交保存;已暂存表示把已修改的文件放在下次提交时要保存的清单中。
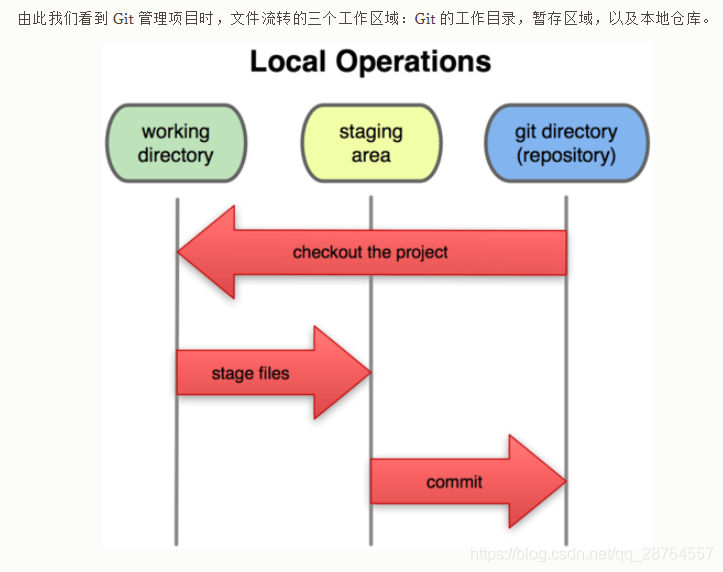
每个项目都有一个 Git 目录(译注:如果 git clone 出来的话,就是其中 .git 的目录。它是 Git 用来保存元数据和对象数据库的地方。该目录非常重要,每次克隆镜像仓库的时候,实际拷贝的就是这个目录里面的数据。从项目中取出某个版本的所有文件和目录,用以开始后续工作的叫做工作目录。这些文件实际上都是从 Git 目录中的压缩对象数据库中提取出来的,接下来就可以在工作目录中对这些文件进行编辑。所谓的暂存区域只不过是个简单的文件,一般都放在 Git 目录中。有时候人们会把这个文件叫做索引文件,不过标准说法还是叫暂存区域。
基本的 Git 工作流程如下:
- 在工作目录中修改某些文件。
- 对修改后的文件进行快照,然后保存到暂存区域。
- 提交更新,将保存在暂存区域的文件快照永久转储到 Git 目录中。
所以,我们可以从文件所处的位置来判断状态:如果是 Git 目录中保存着的特定版本文件,就属于已提交状态;如果作了修改并已放入暂存区域,就属于已暂存状态;如果自上次取出后,作了修改但还没有放到暂存区域,就是已修改状态。到第二章的时候,我们会进一步了解其中细节,并学会如何根据文件状态实施后续操作,以及怎样跳过暂存直接提交。
git的window安装网址:http://msysgit.github.com/
Git 提供了一个叫做 git config 的工具(译注:实际是 git-config 命令,只不过可以通过 git 加一个名字来呼叫此命令。),专门用来配置或读取相应的工作环境变量。而正是由这些环境变量,决定了 Git 在各个环节的具体工作方式和行为。
第一个要配置的是你个人的用户名称和电子邮件地址。这两条配置很重要,每次 Git 提交时都会引用这两条信息,说明是谁提交了更新,所以会随更新内容一起被永久纳入历史记录:
$ git config --global user.name "FandyWw"
$ git config --global user.email [email protected] 如果用了 --global 选项,那么更改的配置文件就是位于你用户主目录下的那个,以后你所有的项目都会默认使用这里配置的用户信息。如果要在某个特定的项目中使用其他名字或者电邮,只要去掉 --global选项重新配置即可,新的设定保存在当前项目的 .git/config 文件里。
要对现有的某个项目开始用 Git 管理,只需到此项目所在的目录,执行:
$ git init初始化后,在当前目录下会出现一个名为 .git 的目录,所有 Git 需要的数据和资源都存放在这个目录中。不过目前,仅仅是按照既有的结构框架初始化好了里边所有的文件和目录,但我们还没有开始跟踪管理项目中的任何一个文件。
如果想对某个开源项目出一份力,可以先把该项目的 Git 仓库复制一份出来,这就需要用到 git clone命令。如果你熟悉其他的 VCS 比如 Subversion,你可能已经注意到这里使用的是 clone 而不是 checkout。这是个非常重要的差别,Git 收取的是项目历史的所有数据(每一个文件的每一个版本),服务器上有的数据克隆之后本地也都有了。实际上,即便服务器的磁盘发生故障,用任何一个克隆出来的客户端都可以重建服务器上的仓库,回到当初克隆时的状态。
克隆仓库的命令格式为 git clone [url]。比如,要克隆 Ruby 语言的 Git 代码仓库 Grit,可以用下面的命令:
$ git clone git://github.com/schacon/grit.git这会在当前目录下创建一个名为grit的目录,其中包含一个 .git 的目录,用于保存下载下来的所有版本记录,然后从中取出最新版本的文件拷贝。如果进入这个新建的 grit 目录,你会看到项目中的所有文件已经在里边了,准备好后续的开发和使用。如果希望在克隆的时候,自己定义要新建的项目目录名称,可以在上面的命令末尾指定新的名字:
$ git clone git://github.com/schacon/grit.git mygrit注意这里是可以支持多种协议得。
要确定哪些文件当前处于什么状态,可以用 git status 命令。如
$ git status
On branch master
nothing to commit, working directory clean该命令还显示了当前所在的分支是 master,这是默认的分支名称,实际是可以修改的。
工作目录下面的所有文件都不外乎这两种状态:已跟踪或未跟踪。
现在让我们用 vim 创建一个新文件,保存退出后运行 git status 会看到该文件出现在未跟踪文件列表中:
$ vim README
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
README
nothing added to commit but untracked files present (use "git add" to track)使用命令 git add 开始跟踪一个新文件。所以,要跟踪 README 文件,运行:
$ git add README此时再运行 git status 命令,会看到 README 文件已被跟踪,并处于暂存状态:
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README注意:运行了 git add 之后又作了修订的文件,需要重新运行 git add把最新版本重新暂存起来
忽略某些文件注意要在一开始就设置忽略哪些文件:
$ cat .gitignore
*.[oa]
*~
# 此为注释 – 将被 Git 忽略
# 忽略所有 .a 结尾的文件
*.a
# 但 lib.a 除外
!lib.a
# 仅仅忽略项目根目录下的 TODO 文件,不包括 subdir/TODO
/TODO
# 忽略 build/ 目录下的所有文件
build/
# 会忽略 doc/notes.txt 但不包括 doc/server/arch.txt
doc/*.txt
# 忽略 doc/ 目录下所有扩展名为 txt 的文件
doc/**/*.txt提交更新:用 -m 参数后跟提交说明的方式,在一行命令中提交更新:
$ git commit -m "Story 182: Fix benchmarks for speed"强制更新:
git commit -a -m 'added new benchmarks'远程仓库得使用:
要查看当前配置有哪些远程仓库,可以用 git remote 命令,它会列出每个远程库的简短名字。
$ git clone git://github.com/schacon/ticgit.git
Cloning into 'ticgit'...
remote: Reusing existing pack: 1857, done.
remote: Total 1857 (delta 0), reused 0 (delta 0)
Receiving objects: 100% (1857/1857), 374.35 KiB | 193.00 KiB/s, done.
Resolving deltas: 100% (772/772), done.
Checking connectivity... done.
$ cd ticgit
$ git remote
origin 也可以加上 -v 选项(译注:此为 --verbose 的简写,取首字母),显示对应的克隆地址:
$ git remote -v
origin git://github.com/schacon/ticgit.git (fetch)
origin git://github.com/schacon/ticgit.git (push)$ cd grit
$ git remote -v
bakkdoor git://github.com/bakkdoor/grit.git
cho45 git://github.com/cho45/grit.git
defunkt git://github.com/defunkt/grit.git
koke git://github.com/koke/grit.git
origin [email protected]:mojombo/grit.git 要添加一个新的远程仓库,可以指定一个简单的名字,以便将来引用,运行 git remote add [shortname] [url]:
$ git remote
origin
$ git remote add pb git://github.com/paulboone/ticgit.git
$ git remote -v
origin git://github.com/schacon/ticgit.git
pb git://github.com/paulboone/ticgit.git 现在可以用字符串 pb 指代对应的仓库地址了。比如说,要抓取所有 Paul 有的,但本地仓库没有的信息,可以运行 git fetch pb:
$ git fetch pb
remote: Counting objects: 58, done.
remote: Compressing objects: 100% (41/41), done.
remote: Total 44 (delta 24), reused 1 (delta 0)
Unpacking objects: 100% (44/44), done.
From git://github.com/paulboone/ticgit
* [new branch] master -> pb/master
* [new branch] ticgit -> pb/ticgit在远程仓库抓取数据:
$ git fetch [remote-name]此命令会到远程仓库中拉取所有你本地仓库中还没有的数据。运行完成后,你就可以在本地访问该远程仓库中的所有分支,将其中某个分支合并到本地,或者只是取出某个分支,一探究竟。(我们会在第三章详细讨论关于分支的概念和操作。)
如果是克隆了一个仓库,此命令会自动将远程仓库归于 origin 名下。所以,git fetch origin 会抓取从你上次克隆以来别人上传到此远程仓库中的所有更新(或是上次 fetch 以来别人提交的更新)。有一点很重要,需要记住,fetch 命令只是将远端的数据拉到本地仓库,并不自动合并到当前工作分支,只有当你确实准备好了,才能手工合并。
如果设置了某个分支用于跟踪某个远端仓库的分支(参见下节及第三章的内容),可以使用 git pull 命令自动抓取数据下来,然后将远端分支自动合并到本地仓库中当前分支。在日常工作中我们经常这么用,既快且好。实际上,默认情况下 git clone 命令本质上就是自动创建了本地的 master 分支用于跟踪远程仓库中的 master 分支(假设远程仓库确实有 master 分支)。所以一般我们运行 git pull,目的都是要从原始克隆的远端仓库中抓取数据后,合并到工作目录中的当前分支。
项目进行到一个阶段,要同别人分享目前的成果,可以将本地仓库中的数据推送到远程仓库。实现这个任务的命令很简单: git push [remote-name] [branch-name]。如果要把本地的 master 分支推送到 origin 服务器上(再次说明下,克隆操作会自动使用默认的 origin 和master 名字),可以运行下面的命令:
$ git push -u origin master分割线--------------------------------------------------------------------------------------------------------------------------------------------------------------
重要得知识点:
网址:https://git-scm.com/book/zh/v1/Git-%E5%88%86%E6%94%AF-%E4%BD%95%E8%B0%93%E5%88%86%E6%94%AF
仓库中的各个对象保存的数据和相互关系看起来如图 :

作些修改后再次提交,那么这次的提交对象会包含一个指向上次提交对象的指针(译注:即下图中的 parent 对象)。两次提交后,仓库历史会变成图:

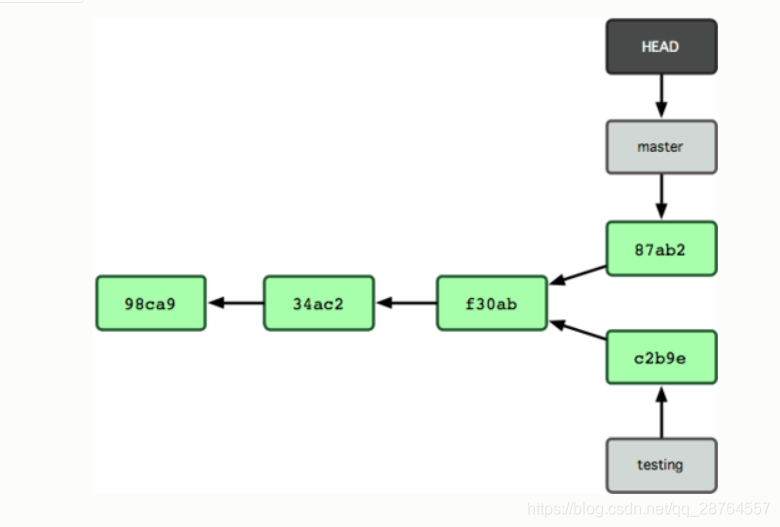
现在来谈分支。Git 中的分支,其实本质上仅仅是个指向 commit 对象的可变指针。Git 会使用 master 作为分支的默认名字。在若干次提交后,你其实已经有了一个指向最后一次提交对象的 master 分支,它在每次提交的时候都会自动向前移动。
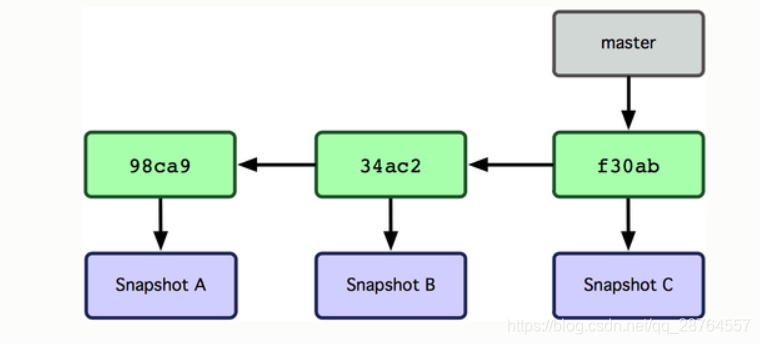
那么,Git 又是如何创建一个新的分支的呢?答案很简单,创建一个新的分支指针。比如新建一个 testing 分支,可以使用 git branch 命令:
$ git branch testing这会在当前 commit 对象上新建一个分支指针:
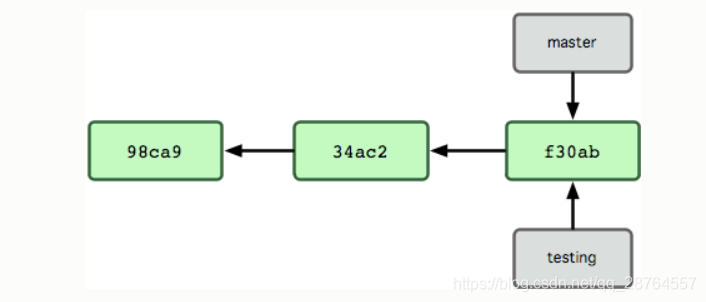
那么,Git 是如何知道你当前在哪个分支上工作的呢?其实答案也很简单,它保存着一个名为 HEAD 的特别指针。请注意它和你熟知的许多其他版本控制系统(比如 Subversion 或 CVS)里的 HEAD 概念大不相同。在 Git 中,它是一个指向你正在工作中的本地分支的指针(译注:将 HEAD 想象为当前分支的别名。)。运行 git branch 命令,仅仅是建立了一个新的分支,但不会自动切换到这个分支中去,所以在这个例子中,我们依然还在 master 分支里工作。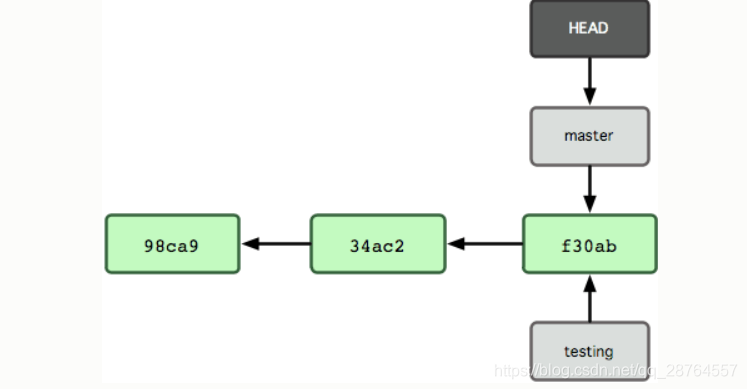
要切换到其他分支,可以执行 git checkout 命令。我们现在转换到新建的 testing 分支:
$ git checkout testing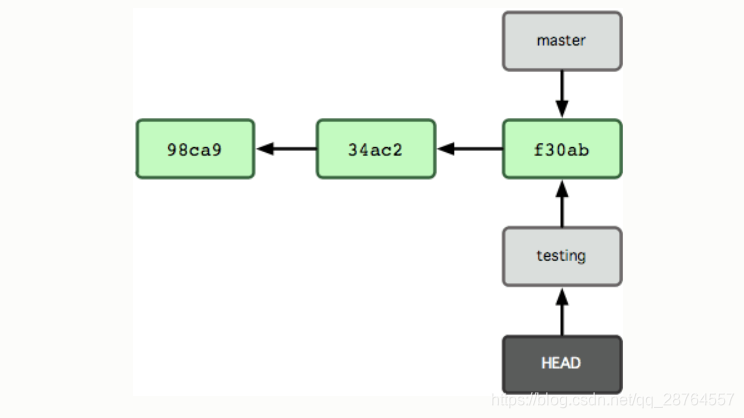
这样的实现方式会给我们带来什么好处呢?好吧,现在不妨再提交一次:
$ vim test.rb
$ git commit -a -m 'made a change'提交后的结果为:
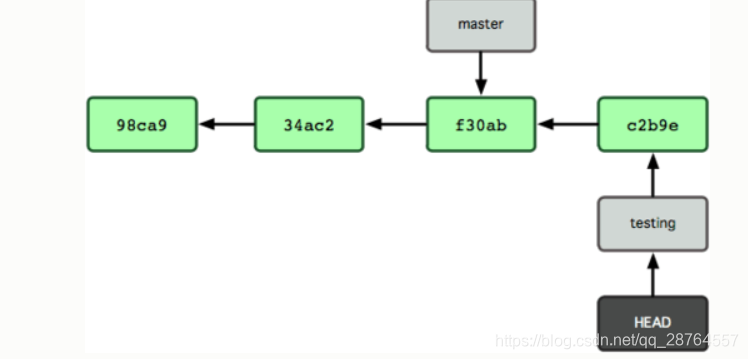
非常有趣,现在 testing 分支向前移动了一格,而 master 分支仍然指向原先 git checkout 时所在的 commit 对象。现在我们回到 master 分支看看:
$ git checkout master
这条命令做了两件事。它把 HEAD 指针移回到 master 分支,并把工作目录中的文件换成了 master 分支所指向的快照内容。也就是说,现在开始所做的改动,将始于本项目中一个较老的版本。它的主要作用是将 testing 分支里作出的修改暂时取消,这样你就可以向另一个方向进行开发。
我们作些修改后再次提交:
$ vim test.rb
$ git commit -a -m 'made other changes' 现在我们的项目提交历史产生了分叉(如图 3-9 所示),因为刚才我们创建了一个分支,转换到其中进行了一些工作,然后又回到原来的主分支进行了另外一些工作。这些改变分别孤立在不同的分支里:我们可以在不同分支里反复切换,并在时机成熟时把它们合并到一起。而所有这些工作,仅仅需要 branch 和 checkout 这两条命令就可以完成。
由于 Git 中的分支实际上仅是一个包含所指对象校验和(40 个字符长度 SHA-1 字串)的文件,所以创建和销毁一个分支就变得非常廉价。说白了,新建一个分支就是向一个文件写入 41 个字节(外加一个换行符)那么简单,当然也就很快了。
这和大多数版本控制系统形成了鲜明对比,它们管理分支大多采取备份所有项目文件到特定目录的方式,所以根据项目文件数量和大小不同,可能花费的时间也会有相当大的差别,快则几秒,慢则数分钟。而 Git 的实现与项目复杂度无关,它永远可以在几毫秒的时间内完成分支的创建和切换。同时,因为每次提交时都记录了祖先信息(译注:即 parent 对象),将来要合并分支时,寻找恰当的合并基础(译注:即共同祖先)的工作其实已经自然而然地摆在那里了,所以实现起来非常容易。Git 鼓励开发者频繁使用分支,正是因为有着这些特性作保障。