首先我们在每次写代码的时候,先理清思路,知道每一步在干什么:
那么我们今天要用决策树来预测波士顿的房价那么我们首先需要的就是波士顿的数据
那么这个数据我们有两种方式可以进行测试,
1》可以从网上找到一个csv文件或者别的都可以
2》导包 from sklearn import datasets 在sklearn中自带数据,相对来书这个方法比较方便一点
博主用的是第二种方法
那么我们开始理清思路:
1》加载数据

这里我们的数据已经加载完毕,现在我们开始进行第二步:
2》分割数据集,分为训练集和测试集,一般我们的训练集和测试集都是2 8 分,训练集为8 测试集为2

这里我们用了train_test_split()这个函数,这个函数有四个参数,第一个是导入的数据中x轴的数据,第二个是y轴的数据
第三个参数是测试集一共分多少比例,这里博主分为2份
3》既然我们的数据准备好了,那么我们就开始简单的做一个模型

其中我们先导入决策树的包, from sklearn.tree import DecisionTreeRegressor
导入后,我们首先初始化模型,并且将我们之前分割好的数据放到模型中进行训练,
之前训练模型是,train_X这个是训练模型test_X是测试集的模型
现在讲训练集的数据放到模型中,这里面模型怎么训练的,或者模型是什么样子,我们不需要考虑
这不是我们考虑的,这些是底层复制的,我们复制怎么使用
现在模型训练完毕,可以预测模型是否准确,并且得分是什么情况
利用模型的名字.predict(test_X) 根据测试集的数据进行测试

然后打印分数
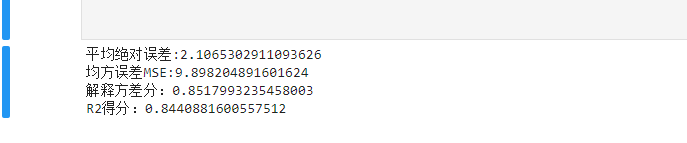
这个分数算稳定的分数,但是如果我们的误差很大,R2得分不高,我们怎么办呐?
开始决策树的优化:
优化有两个方法:
1》一般的,可以先从数据集上优化
2》是使用AdaBoost算法来增强模型的准确
但是由于本项目是比较成熟的项目,那第一种方法意义不大
这里采用第二种方法
AdaBoost的做法(以分类原理举例)
提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。
加权多数表决的方法,加大分类误差率小的弱分类器的权值,使其在表决中起较大作用,减小分类误差率大
的弱分类器的权值,使其在表决中起较小的作用。
其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强
的最终分类器(强分类器)
scikit-learn中Adaboost类库比较直接,就是AdaBoostClassifier和AdaBoostRegressor两个 。
整个过程如下所示(以分类原理举例)
1. 先通过对 N 个训练样本的学习得到第一个弱分类器 ;
2. 将分错的样本和其他的新数据一起构成一个新的N 个的训练样本,通过对这个样本的学习得到第二个弱分类
器;
3. 将 和 都分错了的样本加上其他的新样本构成另一个新的 N个的训练样本,通过对这个样本的学习得到第三个
弱分类器;
4. 如此反复,最终得到经过提升的强分类器。
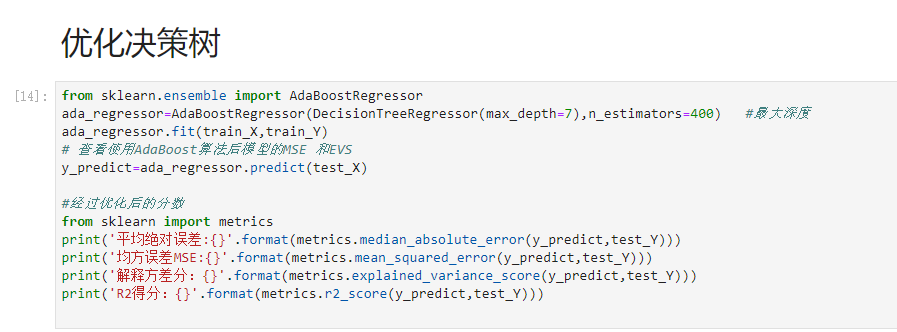
运行进行对比:


第一个是优化后,第二个是优化前,有明显的变化,这里这个demo就搞定了