本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
主要应用场景有三类:
1.Event-driven Applications【事件驱动】
2.Data Analytics Applications【分析】
3.Data Pipeline Applications【管道式ETL】
3.1 Event-driven Applications
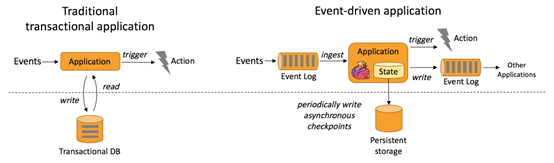
上图包含两块:Traditional transaction Application(传统事务应用)和Event-driven Applications(事件驱动应用)。
Traditional transaction Application执行流程:比如点击流Events可以通过Application写入Transaction DB(数据库),同时也可以通过Application从Transaction DB将数据读出,并进行处理,当处理结果达到一个预警值就会触发一个Action动作,这种方式一般为事后诸葛亮。
Event-driven Applications执行流程:比如采集的数据Events可以不断的放入消息队列,Flink应用会不断ingest(消费)消息队列中的数据,Flink 应用内部维护着一段时间的数据(state),隔一段时间会将数据持久化存储(Persistent sstorage),防止Flink应用死掉。Flink应用每接受一条数据,就会处理一条数据,处理之后就会触发(trigger)一个动作(Action),同时也可以将处理结果写入外部消息队列中,其他Flink应用再消费。
典型的事件驱动类应用:
1.欺诈检测(Fraud detection)
2.异常检测(Anomaly detection)
3.基于规则的告警(Rule-based alerting)
4.业务流程监控(Business process monitoring)
5.Web应用程序(社交网络)
3.2 Data Analytics Applications

Data Analytics Applications包含Batch analytics(批处理分析)和Streaming analytics(流处理分析)。
Batch analytics可以理解为周期性查询:比如Flink应用凌晨从Recorded Events中读取昨天的数据,然后做周期查询运算,最后将数据写入Database或者HDFS,或者直接将数据生成报表供公司上层领导决策使用。
Streaming analytics可以理解为连续性查询:比如实时展示双十一天猫销售GMV,用户下单数据需要实时写入消息队列,Flink 应用源源不断读取数据做实时计算,然后不断的将数据更新至Database或者K-VStore,最后做大屏实时展示。
3.3 Data Pipeline Applications

Data Pipeline Applications包含Periodic (周期性)ETL和Data Pipeline(管道)
Periodic ETL:比如每天凌晨周期性的启动一个Flink ETL Job,读取传统数据库中的数据,然后做ETL,最后写入数据库和文件系统。
Data Pipeline:比如启动一个Flink 实时应用,数据源(比如数据库、Kafka)中的数据不断的通过Flink Data Pipeline流入或者追加到数据仓库(数据库或者文件系统),或者Kafka消息队列。
3.4阿里Flink应用场景
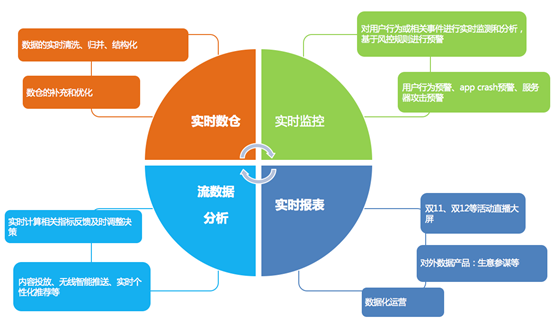
阿里在Flink的应用主要包含四个模块:实时监控、实时报表、流数据分析和实时仓库。
实时监控:
- 用户行为预警、app crash 预警、服务器攻击预警
- 对用户行为或者相关事件进行实时监测和分析,基于风控规则进行预警
实时报表:
- 双11、双12等活动直播大屏
- 对外数据产品:生意参谋等
- 数据化运营
流数据分析:
- 实时计算相关指标反馈及时调整决策
- 内容投放、无线智能推送、实时个性化推荐等
实时仓库:
- 数据实时清洗、归并、结构化
- 数仓的补充和优化
欺诈检测
背景:
假设你是一个电商公司,经常搞运营活动,但收效甚微,经过细致排查,发现原来是羊毛党在薅平台的羊毛,把补给用户的补贴都薅走了,钱花了不少,效果却没达到。
怎么办呢?
你可以做一个实时的异常检测系统,监控用户的高危行为,及时发现高危行为并采取措施,降低损失。
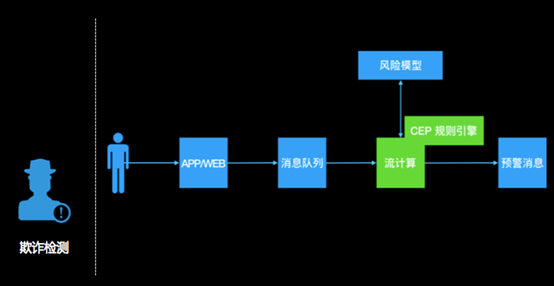
系统流程:
1.用户的行为经由app 上报或web日志记录下来,发送到一个消息队列里去;
2.然后流计算订阅消息队列,过滤出感兴趣的行为,比如:购买、领券、浏览等;
3.流计算把这个行为特征化;
4.流计算通过UDF调用外部一个风险模型,判断这次行为是否有问题(单次行为);
5.流计算里通过CEP功能,跨多条记录分析用户行为(比如用户先做了a,又做了b,又做了3次c),整体识别是否有风险;
6.综合风险模型和CEP的结果,产出预警信息。
