列表List定义初始化:
list()->new empty list
list(iterable)->new list initialized from iterable’s items
列表不能一开始就定义大小
lst = list() --》 lst = lsit(range(5))
lst = [] --》 lst = [2,6,8,9,‘ab’]
列表常用方法实例:
列表索引访问:
- 索引,也叫下标
- 正索引:从左到右,从0开始,为列表中每一个元素编号
- 负索引:从右到左,从-1开始
- 正负索引不可以超界,否则引发异常Indexerror 为了理解方便,可以把列表理解为从左到右排列,头部是左,尾部是右,上界是右,下界是左
列表通过索引访问:
list[index] ,index就是索引,使用中括号访问
示例:
lst = ['sdfg',0, 1, 200, 1, 0, 700]
lst[1]
0
列表查询(要学会内存模型):
index(value,[start,[stop]])(一般不建议使用,效率低)
通过值value,从指定区间查找列表的元素是否匹配
匹配第一个就立即返回索引
匹配不到,抛出异常ValueError
index和count方法都是O(n) n=列表里所有的元素
随着列表数据规模的增大,而效率下降
示例:
lst.index(0)
2
count(value)
返回列表中匹配value的次数
时间复杂度
示例:
lst.count('sdfg')
1
insert(index,object)->None
在指定的索引index处插入元素object
返回None就意味着没有新的列表产生,就地修改
时间复杂度O(n)
索引能超上下界:
超越上界,尾部追加
超越下界,头部追加
示例:
lst.insert(-1000,'abcc')
['abcc','sdfg', 0, 1, 200, 1, 0, 700]
len(list)返回元素的个数
len不需要遍历所有相当于windows里面的属性
示例:
lst = ['abcc','sdfg',0, 1, 200, 1, 0, 700]
len(lst)
8
index
list[index] = value(给几号元素重新赋值)
索引不要超界
示例:
lst = ['abcc','sdfg',0, 1, 200, 1, 0, 700]
lst[0] = 'C'
['C', 'sdfg', 0, 1, 200, 1, 0, 700]
列表增加、插入元素
append(object)->None
列表尾部追加元素,返回None
返回None就意味着没有新的列表产生,就地修改
时间复杂度O(1)
示例:
lst = ['abcc','sdfg',0, 1, 200, 1, 0, 700]
lst.append('ddd')
['abcc', 'sdfg', 0, 1, 200, 1, 0, 700, 'ddd']
extend(iteratable)->None
将可迭代对象的元素追加进来,返回None
就地修改
示例:
lst.extend(range(5))
['abcc', 'sdfg', 0, 1, 200, 1, 0, 700, 'ddd', 0, 1, 2, 3, 4]
+ ->list
连接操作,将两个列表连接起来
产生新的列表,原列表不变
本质上调用的是_add_()方法
示例:
a = []
a.extend(range(5))
[0, 1, 2, 3, 4]
a+lst
[0, 1, 2, 3, 4, 'abcc', 'sdfg', 0, 1, 200, 1, 0, 700, 'ddd', 0, 1, 2, 3, 4]
*->list
重复操作,将本列表元素重复n次,返回新的列表
示例:
x = [['a','b','c','d']]*3
[['a', 'b', 'c', 'd'], ['a', 'b', 'c', 'd'], ['a', 'b', 'c', 'd']]
x[0][0] = 'h'
[['h', 'b', 'c', 'd'], ['h', 'b', 'c', 'd'], ['h', 'b', 'c', 'd']]
原理:
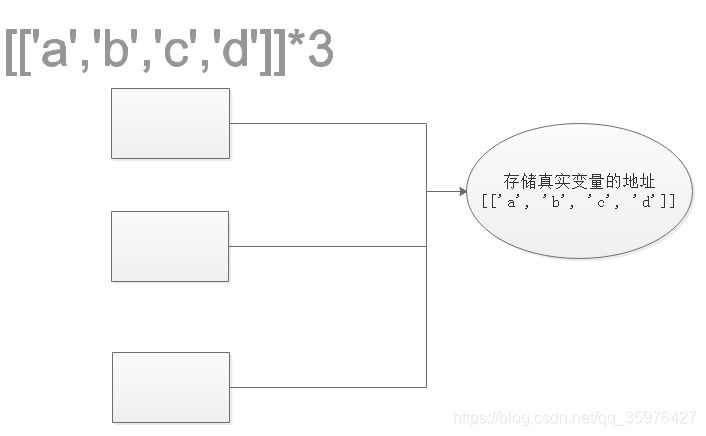
- list的*实际上指向的是同一地址,并不是开辟了新的内存地址
列表删除元素:
remove(value)->None
从左到右查找第一个匹配value的值,移除该元素,返回None
就地修改
效率O(n)
示例:
lst = ['abcc', 'sdfg', 0, 1, 200, 1, 0, 700, 'ddd', 0, 1, 2, 3, 4]
lst.remove('abcc')
['sdfg', 0, 1, 200, 1, 0, 700, 'ddd', 0, 1, 2, 3, 4]
pop([index])->item
不指定索引index,就从列表尾部弹出一个元素
指定索引index,就从索引处弹出一个元素,索引超界抛出IndexError错误
示例:
lst = ['abcc', 'sdfg', 0, 1, 200, 1, 0, 700, 'ddd', 0, 1, 2, 3, 4]
lst.pop(1)
['abcc', 0, 1, 200, 1, 0, 700, 'ddd', 0, 1, 2, 3, 4]
lst.pop()
4
lst
['abcc', 0, 1, 200, 1, 0, 700, 'ddd', 0, 1, 2, 3,]
clear()->None(轻易不要用,会清楚所有数据,大量元素引用计数为0时,会引发频繁GC)
清楚列表所有元素,剩下一个空列表
示例:
lst = ['abcc', 'sdfg', 0, 1, 200, 1, 0, 700, 'ddd', 0, 1, 2, 3, 4]
lst.clear()
[]
reverse()->None
将列表元素反转,返回None
就地修改(没有创建新的列表,反转后创建一个可迭代对象)
示例:
lst.reverse()
[4, 3, 2, 1, 0, 'ddd', 700, 0, 1, 200, 1, 0, 'sdfg', 'abcc']
in
[3,4]in[1,2,[3,4]]
for x in [1,2,3,4]
示例:
[3,4]in[1,2,[3,4]]
True
reversed() 是一个反转用的内建函数(迭代器就是可迭代对象)reversed返回可迭代对象(不是就地修改),一般用作for后面因为直接可以从
示例:
a = [i for i in range(10)]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
for i in reversed(a):
print(i)
9
8
7
6
5
4
3
2
1
0
列表排序
sort(key=None,reverse=False)->None
对列表元素进行排序,就地修改,默认升序
reverse为True,反转,降序
key一个函数,指定key如何排序
lst.sort(key=functionname)
#sort后面的填写key,如果不写key则默认是自己的类型
#排序时所有元素都要同类型
示例:
b = [669,560,70,20,324,6,7,4,23]
b.sort()
b
[4, 6, 7, 20, 23, 70, 324, 560, 669]
sorted(内建函数)对某一个可迭代对象进行排序,然后返回一个新的列表。
sorted(lst,key=str)
用内建函数的sorted排序不影响之前的可迭代对象用.sort排序会直接修改列表
示例:
sorted(b)
[4, 6, 7, 20, 23, 70, 324, 560, 669]
b
[669, 560, 70, 20, 324, 6, 7, 4, 23]
copy()->List
shadow copy返回一个新的列表
影子拷贝,也叫浅拷贝,遇到引用类型,只是复制了一个引用而已
示例:
lst1 = list(range(5))
lst2 = lst1.copy()
print(lst1 == lst2)
True
lst2[0]=10
print(lst1 == lst2)
False
- 乘法(*)和拷贝(.copy)方法,都是用浅拷贝。浅拷贝遇到引用类型的时候它只是把门牌号码(地址)拷贝过来而已。复杂类型只是复制的地址而已。
深拷贝
copy模块提供了deepcopy
示例:
from copy import deepcopy
lst0 = [1,[2,3,4],5]
lst5 = copy.deepcopy(lst0)
lst5[1][1] = 20
lst5 == lst0
Flase