第七章 数据库及数据库对象
SQL Server数据库分类
- 用户数据库
- 系统数据库,保存维护系统正常运行的信息
SQL Server系统数据库
- master :记录实例的所有系统级信息(元数据,端点,连接服务器和系统配置),记录其它数据库的存在、位置,初始化信息
- msdb:供代理服务调度报警和作业以及记录操作员时使用
- model:创建数据库的模板,创建数据库时将自动复制model的内容到新建的数据库中
- tempdb:临时数据库,用于保存临时对象或中间结果集
- Resource:只读数据库,包含了所有系统对象,不可见
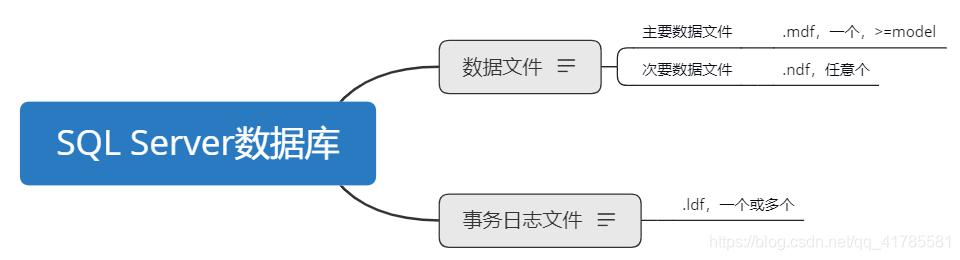
SQL Server数据库的组成
数据库存储空间的分配
- 创建数据库时,model数据库自动被复制到新建与用户的数据库中,而且时复制到主要数据文件中
- 数据存储分配的单位是数据页,一页是8KB(8060B为数据,132B为系统信息)的连续磁盘空间
- 不允许表中的一行数据存储在不同页上(varchar(max),nvarchar(max),text,ntext,varbinary(max)和image类型除外)
数据库文件组
- 主文件组,包含主要数据文件和任何没有明确分配给其它文件组的数据文件,系统表的所有页均分配在主文件组中
- 用户定义的文件组
注: - 日志文件不在文件组内,日志文件与数据空间是分开管理的
- 一个文件不能是多个文件组的成员
- 文件组被填满后会逐渐增长
数据库文件的属性
- 文件名及其位置:数据文件和日志文件都有一个逻辑文件名和物理文件名。
- 初始大小:指定每个数据文件和日志文件的初始大小。
- 增长方式:指定是否自动增长。默认为自动增长。
- 最大大小:文件增长的最大空间限制。默认情况无限制。
例:
/**
* 创建指定一个数据文件和一个日志文件的数据库。创建一个名为RShDB的数据库,该数据库由一个数据文件和一个日志文件组成。
* 数据文件只有主要数据文件,其逻辑文件名为RShDB_Data,物理文件名为RShDB_Data.mdf,存放在D:\RShDB_Data文件夹下,
* 初始大小为10MB,最大大小为30MB,自动增长时的递增量为5MB。日志文件的逻辑文件名为RShDB_log,物理文件名为
* RShDB_log.ldf,也存放在D:\RShDB_Data文件夹下,初始大小为3MB,最大大小为12MB,自动增长时的递增量为2MB。
*/
create database RShDB
on
(name=RShDB_Data,
filename='D:\RShDB_Data\RShDB_Data.mdf',
size=10,
maxsize=30,
filegrowth=5)
log on
(name=RShDB_log,
filename='D:\RShDB_Data\RShDB_log.ldf',
size=3,
maxsize=12,
filegrowth=2)
/**
* 创建具有文件组的数据库。创建一个名为Sales的数据库,该数据库除了主文件组PRIMARY外,还包括SalesGroup1
* 和SalesGroup2两个文件组
* 1. 主文件组包含Spri1_dat和Spri2_dat两个数据文件,这两个文件的FILEGROWTH均为当前文件大小的15%
* 2. SalesGroup1文件组包含SGrp1Fi1_dat和SGrp1Fi2_dat两个文件,这两个文件的FILEGROWTH均为5MB
* 3. SalesGroup2文件组包含SGrp2Fi1_dat和SGrp2Fil_dat两个文件,这两个文件的FILEGROWTH均为5MB
* 为简单起见,假设这些文件均存放在D:\Sales文件夹下,所有数据文件的初始大小都是10MB,最大大小都是50MB。
* 该数据库只包含一个日志文件Sales_log,该文件也存放在D:\Sales文件夹下,初始大小是5MB,最大大小是25MB,每次
* 每次增加5MB。
*/
create database Sales
on primary
(name=Spri1_dat,
filename='D:\Sales\Spri1_dat.mdf',
size=10MB,
maxsize=50MB,
filegrowth=15%),
(name=Spri2_dat,
filename='D:\Sales\Spri2_dat.ndf',
size=10MB,
maxsize=50MB,
filegrowth=15%),
filegroup SalesGroup1
(name=SGrp1Fi1_dat,
filename='D:\Sales\SGrp1Fi1_dat.ndf',
size=10MB,
maxsize=50MB,
filegrowth=5MB),
(name=SGrp1Fi2_dat,
filename='D:\Sales\SGrp1Fi2_dat.ndf',
size=10MB,
maxsize=50MB,
filegrowth=5MB),
filegroup SalesGroup2
(name=SGrp2Fi1_dat,
filename='D:\Sales\SGrp2Fi1_dat',
size=10MB,
maxsize=50MB,
filegrowth=5MB),
(name=SGrp2Fi2_dat,
filename='D:\Sales\SGrp2Fi2_dat',
size=10MB,
maxsize=50MB,
filegrowth=5MB)
log on
(name=Sales_log,
filename='D:\Sales\Sales_log.ldf',
size=5MB,
maxsize=25MB,
filegrowth=5MB)
修改数据库
问题:
- 如果数据空间不够,则不能再对数据库插入数据
- 如果日志空间不够,则不能再对数据库进行任何修改操作
扩大数据空间
/**
* 为RShDB数据库添加一个新的数据文件,逻辑文件名为RShDB_Data2,物理存储位置为E:\Data文件夹下,物理文件名为
* RShDB_Data2.ndf,初始大小为6MB,不自动增长。
*/
alter database RShDB_Data2
add file(
name=RShDB_Data2,
filename='E:\Data\RshDB_Data2.ndf',
size=6MB,
filegrowth=0)
/**
* 扩大数据库中students_data1文件的初始大小,将其初始大小改为8MB.
*/
alter database students
modify file(
name=students_data1,
size=8MB)
/**
* 为RShDB数据库添加一个新的日志文件,逻辑文件名为RShDB_log1,物理存储位置为E:\Data文件夹下,物理文件名为
* RShDB_log1.ldf,初始大小为4MB,每次增加1MB,最多增加到10MB.
**/
alter database RShDB
add log file(
name=RShDB_log1,
filename='E:\Data\RShDB_log1.ldf',
size=4MB,
maxsize=10MB,
filegrowth=1MB
)
收缩数据库大小
/**
* 收缩Students数据库,使该数据库中所有的文件都有20%的可用空间。
*/
dbcc shrinkDatabase(Students,20)
/**
* 将Students数据库中的students_data1文件收缩到4MB
*/
dbcc shrinkFile(students_data1,4)
添加和删除数据库文件
数据文件是按比例填充数据的。日志文件是填充到满。
/**
* 删除students数据库中的students_data1文件
*/
alter database students
remove file students_data1
/**
* 删除students数据库中的students_log1文件
*/
alter database students
remove file students_log1
分离数据库
删除数据库,但不删除数据库的数据文件和日志文件。
/**
* 分离Students数据库,并跳过“更新统计信息”
*/
exec sp_detach_db 'Students','true'
附加数据库
与分离数据库对应。
/**
* 附加之前已分离的Students数据库
*/
create database Students
on(filename='F:\Data\students_data1')
/**
* 假设已对Students数据库进行了分离操作,并将其中student_data2.ndf文件和student_data2.ldf文件均移动到了
* E:\NewData文件夹下。移动数据库文件后,附加该数据库。
*/
create database Students
on (filename='F:\Data\students_data1.mdf'),
(filename='E:\Data\students_data2.ndf'),
(filename='E:\NewData\students_log1.ldf')
架构
架构是数据库下的一个逻辑命名空间,可以存放表、视图等数据库对象,它是一个数据库对象的容器。类比:数据库–操作系统,架构–文件夹,对象–文件。因此,通过将同名表放置在不同架构中,使一个数据库可以包含同名的表。
定义架构
/**
* 为用户ZHANG定义一个架构,架构名为S_C。
*/
create schema S_C authorization ZHANG
/**
* 定义一个用隐含名字的架构。
*/
create schema authorization ZHANG
/**
* 在定义架构的同时定义表。
*/
create schema TEST authorization ZHANG
create table T1
(C1 int,
C2 char(10),
c3 smalldatetime,
c4 numeric(4,1))
删除架构
/**
* 删除架构S_C
*/
drop schema S_C
分区表
分区表是将表中的数据水平划分成不同的子集,这些数据子集存储在数据库的一个或多个文件组中。
一般选择分区的条件:
- 该表包含以多种不同方式使用的大量数据
- 数据是分段的,比如数据以年份间隔
分区表包括:
- 分区函数,告诉数据库管理系统以什么方式对表进行分区
- 分区方案,将分区函数生成的分区映射到文件组中
分区函数
CREATE PARTITION FUNCTION partition_function_name(input_parameter_type)
AS RANGE [LEFT|RIGHT]
FOR VALUES ([boundary_value[,…n]])
- partition_function_name:分区函数名。分区函数名必须在数据库中唯一。
- input_parameter_type:用于分区的列的数据类型。不可以是text、ntext、image、xml、timestamp、varchar(max)、nvarchar(max)、varbinary(max)和用户定义的数据类型。
- boundary_value:分区的边界值。
- LEFT|RIGHT:指定边界值归在左侧分区还是右侧分区。默认LEFT。
/**
* 在int列上创建左侧分区函数。下列分区函数将表分为四个分区。
*/
create partition function myRangePF1(int)
as range left for values(1,100,1000);
/**
* ---------------------------------------------------------------------------
* 分区 | 1 | 2 | 3 | 4 |
* ---------------------------------------------------------------------------
* 值 | col1<=1 | col1>1 AND col1<=100 | col1>100 AND col1<=1000 | col1>1000
* ---------------------------------------------------------------------------
*/
/**
* 在int列上创建右侧分区函数。下列分区函数将表分为四个分区。
*/
create partition function myRangePF2(int)
as range right for values(1,100,1000);
/**
* ---------------------------------------------------------------------------
* 分区 | 1 | 2 | 3 | 4 |
* ---------------------------------------------------------------------------
* 值 | col1<1 | col1>=1 AND col1<100 | col1>=100 AND col1<1000 | col1>=1000
* ---------------------------------------------------------------------------
*/
分区方案
CREATE PARTITION SCHEME partition_scheme_name
AS PARTITION partition_function_name
[ALL] TO(|file_group_name|[PRIMARY] | [,…n])
- partition_scheme_name:分区方案名。分区方案名在数据库中必须唯一
- partition_function_name:分区函数名。
- ALL:指定所有分区都映射到file_group_name中提供的文件组,或映射到主文件组(如果指定了PRIMARY)
- file_group_name|[PRIMARY] | [,…n]:指定分区对应的文件组名
/**
* 创建用于将每个分区映射到不同文件组的分区方案。下列代码首先创建一个分区函数,并将表分为四个分区。然后创建一个
* 分区方案,在其中指定拥有着四个分区中每一个分区的文件组。此示例假定数据库中已经存在文件组。
*/
create partition function myRangePF1(int)
as range left for values(1,100,1000);
go
create partition scheme myRangePS1
as partition myRangePF1
to(test1fg,test2fg,test3fg,test4fg);
/**
* ---------------------------------------------------------------------------
* 文件组 | test1fg | test2fg | test3fg | test4fg |
* ---------------------------------------------------------------------------
* 分区 | 1 | 2 | 3 | 4 |
* ---------------------------------------------------------------------------
* 值 | col1<=1 | col1>1 AND col1<=100 | col1>100 AND col1<=1000 | col1>1000
* ---------------------------------------------------------------------------
*/
/**
* 创建将所有分区映射到同一个文件组的分区方案。
*/
create partition function myRangePF3(int)
as range left for values(1,100,1000);
go
create partition scheme myRangePS3
as partition myRangePF3
all to (test1fg);
/**
* 首先创建一个分区函数,将表或索引分为四个分区。然后创建一个分区方案,最后创建使用此分区方案的表。
*/
create partition function myRangePF1(int)
as range left for values(1,100,100);
go
create partition scheme myRangePS1
as partition myRangePF1
to(test1fg,test2fg,test3fg,test4fg);
go
create table PartitionTable(
col1 int,
col2 char(10)
)on myRangePS1(col1);
索引
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED] INDEX index_name
ON (column [ASC|DESC] [,…n])
[INCLUDE(column_name[,…n])]
[WHERE<filter_predicate>]
[ON { partition_scheme_name(column_name)
| filegroup_name
| default
]
[FILESTREAM_ON {filestream_filegroup_name | partition_scheme_name | “NULL”}]
<object> ::=
{
[database_name.[schema_name].|schema_name.] table_or_view_name
}
- 默认索引为NONCLUSTERED
- 默认排序方式为ASC
/**
* 在Table_Customer表的Cname列上创建非聚集索引。
*/
create index Cname_ind on Table_Customer(Cname)
/**
* 在Table_Customer表的IdentityCard列上创建唯一性聚集索引。
*/
create unique clustered index ID_ind
on Table_Customer(IdentityCard)
/**
* 在Table_Customer表的IdentityCard列上创建一个非聚集索引,要求索引键值按Cname升序和CardID降序排序
*/
create index COMP_ind on Table_Customer(Cname asc,CardID desc)
/**
* 创建分区索引。本示例在TransactionHistory表的ReferenceOrderID列上为现有分区方案TransactionPS1创建
* 非聚集分区索引。
*/
create nonclustered index IX_TransactionHistory_ReferenceOrderID
on Transaction(ReferenceOrderID)
on TransactionsPS1(TransactionDate);
DROP INDEX {index_name ON <object>[,…n]}
/**
* 删除Table_Customer表中的Cname_ind索引
*/
drop index Cname_id
索引视图
普通的视图不保存结果集,而是在使用时执行查询语句。而索引视图的结果集是存储在数据库中的。建有唯一聚集索引的视图称为索引视图,也称为物化视图。
适合建立索引视图的条件:
- 很少更新基本表
- 基础数据以批处理的形式定期更新,但在更新之前主要作为只读数据进行处理,则可以考虑在更新前删除所有索引视图,然后再重建索引视图
索引视图可以提高下列查询类型的性能:
- 处理大量行的连接和聚合
- 许多查询经常执行的连接和聚合操作
索引视图通常不会提高下列查询类型的性能:
- 具有大量写操作的OLTP系统
- 具有大量更新操作的数据库
- 不涉及聚合或连接的查询
- GROUP BY列具有高基数度(查询后的数据量接近基本表中的总数据量)的数据聚合
定义索引视图的要求:
- 视图不能引用其它视图
- 视图引用的所有基本表必须位于同一个数据库中
- 必须使用 SCHEMABINDING选项创建视图
- 视图中的表达式引用的所有函数必须是确定的
- 对视图创建的第一个索引必须是唯一聚集索引,之后再创建其它的非聚集索引
/**
* 创建视图并为该视图创建一个唯一聚集索引,然后使用两个查询语句查询索引视图
*/
create view Sales.vOrders
with schemabinding
as
select sum(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) as Revenue,OrderDate,ProductID,COUNT_BIG(*) as COUNT
from Sales.SalesOrderDetail as od,Sales.SalesOrderHeader as o
where od.SalesOrderID=o.SalesOrderID
group by OrderDate,ProductID
go
create unique clustered index IDX_V1
on Sales.vOrders(OrderDate,ProductID);
go
select sum(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) as Rev,OrderDate,ProductID
from Sales.SalesOrderDetail as od
join Sales.SalesOrderHeader
on od.Sales.SalesOrderID=o.Sales.SalesOrderID
and ProductID between 700 and 800
and OrderDate>=convert(datetime,'05/01/2002',101)
group by OrderDate,ProductID
order by Rev desc
go
select OrderDate,sum(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) as Rev
from Sales.SalesOrderDetail as od
join Sales.SalesOrderHeader
on od.Sales.SalesOrderID=o.Sales.SalesOrderID
and datepart(month,OrderDate)=3
and datepart(year,OrderDate)=2002
group by OrderDate
order by OrderDate asc