本文原文连接: http://blog.csdn.net/bluishglc/article/details/7612811 ,转载请注明出处!
1.XA
XA是由X/Open组织提出的分布式事务的规范。XA规范主要定义了(全局)事务管理器(Transaction Manager)和(局部)资源管理器(Resource Manager)之间的接口。XA接口是双向的系统接口,在事务管理器(Transaction Manager)以及一个或多个资源管理器(Resource Manager)之间形成通信桥梁。XA之所以需要引入事务管理器是因为,在分布式系统中,从理论上讲(参考Fischer等的论文),两台机器理论上无法达到一致的状态,需要引入一个单点进行协调。事务管理器控制着全局事务,管理事务生命周期,并协调资源。资源管理器负责控制和管理实际资源(如数据库或JMS队列)。下图说明了事务管理器、资源管理器,与应用程序之间的关系:
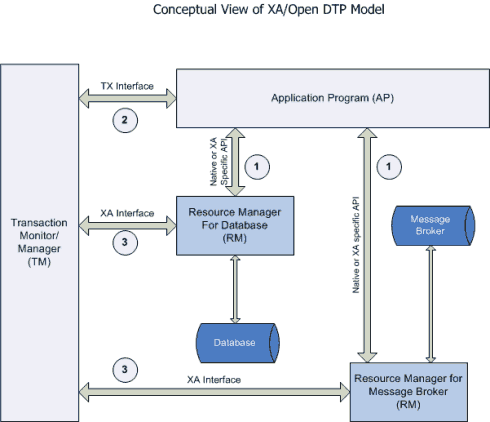
图1.XA规范下的分布式事务各类参与者之间的关系
2.JTA
作为Java平台上事务规范JTA(Java Transaction API)也定义了对XA事务的支持,实际上,JTA是基于XA架构上建模的,在JTA 中,事务管理器抽象为javax.transaction.TransactionManager接口,并通过底层事务服务(即JTS)实现。像很多其他的java规范一样,JTA仅仅定义了接口,具体的实现则是由供应商(如J2EE厂商)负责提供,目前JTA的实现主要由以下几种:
1.J2EE容器所提供的JTA实现(JBoss)
2.独立的JTA实现:如JOTM,Atomikos.这些实现可以应用在那些不使用J2EE应用服务器的环境里用以提供分布事事务保证。如Tomcat,Jetty以及普通的java应用。
3.两阶段提交
所有关于分布式事务的介绍中都必然会讲到两阶段提交,因为它是实现XA分布式事务的关键(确切地说:两阶段提交主要保证了分布式事务的原子性:即所有结点要么全做要么全不做)。所谓的两个阶段是指:第一阶段:准备阶段和第二阶段:提交阶段。
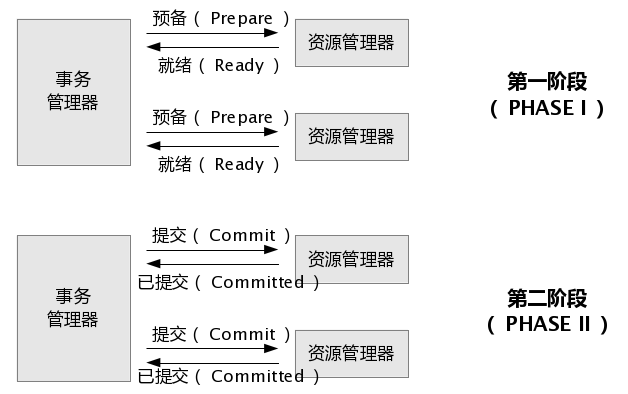
图2.两阶段提交示意图(摘自info发布的《java事务设计策略》一文)
1.准备阶段:事务协调者(事务管理器)给每个参与者(资源管理器)发送Prepare消息,每个参与者要么直接返回失败(如权限验证失败),要么在本地执行事务,写本地的redo和undo日志,但不提交,到达一种“万事俱备,只欠东风”的状态。(关于每一个参与者在准备阶段具体做了什么目前我还没有参考到确切的资料,但是有一点非常确定:参与者在准备阶段完成了几乎所有正式提交的动作,有的材料上说是进行了“试探性的提交”,只保留了最后一步耗时非常短暂的正式提交操作给第二阶段执行。)
2.提交阶段:如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。(注意:必须在最后阶段释放锁资源)
将提交分成两阶段进行的目的很明确,就是尽可能晚地提交事务,让事务在提交前尽可能地完成所有能完成的工作,这样,最后的提交阶段将是一个耗时极短的微小操作,这种操作在一个分布式系统中失败的概率是非常小的,也就是所谓的“网络通讯危险期”非常的短暂,这是两阶段提交确保分布式事务原子性的关键所在。(唯一理论上两阶段提交出现问题的情况是当协调者发出提交指令后当机并出现磁盘故障等永久性错误,导致事务不可追踪和恢复)
从两阶段提交的工作方式来看,很显然,在提交事务的过程中需要在多个节点之间进行协调,而各节点对锁资源的释放必须等到事务最终提交时,这样,比起一阶段提交,两阶段提交在执行同样的事务时会消耗更多时间。事务执行时间的延长意味着锁资源发生冲突的概率增加,当事务的并发量达到一定数量的时候,就会出现大量事务积压甚至出现死锁,系统性能就会严重下滑。这就是使用XA事务
4.一阶段提交(Best Efforts 1PC模式)
不像两阶段提交那样复杂,一阶段提交非常直白,就是从应用程序向数据库发出提交请求到数据库完成提交或回滚之后将结果返回给应用程序的过程。一阶段提交不需要“协调者”角色,各结点之间不存在协调操作,因此其事务执行时间比两阶段提交要短,但是提交的“危险期”是每一个事务的实际提交时间,相比于两阶段提交,一阶段提交出现在“不一致”的概率就变大了。但是我们必须注意到:只有当基础设施出现问题的时候(如网络中断,当机等),一阶段提交才可能会出现“不一致”的情况,相比它的性能优势,很多团队都会选择这一方案。关于在spring环境下如何实现一阶段提交,有一篇非常优秀的文章值得参考:http://www.javaworld.com/javaworld/jw-01-2009/jw-01-spring-transactions.html?page=5
5.事务补偿机制
像best efforts 1PC这种模式,前提是应用程序能获取所有的数据源,然后使用同一个事务管理器(这里指是的spring的事务管理器)管理事务。这种模式最典型的应用场景非数据库sharding莫属。但是对于那些基于web service/rpc/jms等构建的高度自治(autonomy)的分布式系统接口,best efforts 1PC模式是无能为力的,此类场景下,还有最后一种方法可以帮助我们实现“最终一致性”,那就是事务补偿机制。关于事务补偿机制是一个大话题,本文只简单提及,以后会作专门的研究和介绍。
6.在基于两阶段提交的标准分布式事务和Best Efforts 1PC两者之间如何选择
一般而言,需要交互的子系统数量较少,并且整个系统在未来不会或很少引入新的子系统且负载长期保持稳定,即无伸缩要求的话,考虑到开发复杂度和工作量,可以选择使用分布式事务。对于时间需求不是很紧,对性能要求很高的系统,应考虑使用Best Efforts 1PC或事务补偿机制。对于那些需要进行sharding改造的系统,基本上不应再考虑分布式事务,因为sharding打开了数据库水平伸缩的窗口,使用分布式事务看起来好像是为新打开的窗口又加上了一把枷锁。
补充:关于网络通讯的危险期
由于网络通讯故障随时可能发生,任何发出请求后等待回应的程序都会有失去联系的危险。这种危险发生在发出请求之后,服务器返回应答之前,如果在这个期间网 络通讯发生故障,发出请求一方无法收到回应,于是无法判断服务器是否已经成功地处理请求,因为收不到回应可能是请求没有成功地发送到服务器,也可能是服务 器处理完成后的回应无法传回请求方。这段时间称为网络通讯的危险期(In-doubt Time)。很显然,网络通讯的危险期是分布式系统除单点可靠性之外需要考虑的另一个可靠性问题。
参考资料:
1.百度百科
2.http://en.wikipedia.org/wiki/Java_Transaction_API
3.http://www.nosqlnotes.NET/archives/62#more-62
4.http://hi.baidu.com/javaopensource/blog/item/0a2b764ec501b10cb3de05ba.html
-------------------------------------其他----------------------------------
一、二阶段提交算法描述
在分布式系统中,事务往往包含有多个参与者的活动,单个参与者上的活动是能够保证原子性的,而多个参与者之间原子性的保证则需要通过两阶段提交来实现,两阶段提交是分布式事务实现的关键。
很明显,两阶段提交保证了分布式事务的原子性,这些子事务要么都做,要么都不做。而数据库的一致性是由数据库的完整性约束实现的,持久性则是通过commit日志来实现的,不是由两阶段提交来保证的。至于两阶段提交如何保证隔离性,可以参考Large-scale Incremental Processing Using Distributed Transactions and Notifications中两阶段提交的具体实现。
两阶段提交的过程涉及到协调者和参与者。协调者可以看做成事务的发起者,同时也是事务的一个参与者。对于一个分布式事务来说,一个事务是涉及到多个参与者的。具体的两阶段提交的过程如下:
第一阶段:
首先,协调者在自身节点的日志中写入一条的日志记录,然后所有参与者发送消息prepare T,询问这些参与者(包括自身),是否能够提交这个事务;
参与者在接受到这个prepare T 消息以后,会根据自身的情况,进行事务的预处理,如果参与者能够提交该事务,则会将日志写入磁盘,并返回给协调者一个ready T信息,同时自身进入可提交状态;如果不能提交该事务,则记录日志,并返回一个not commit T信息给协调者,同时撤销在自身上所做的数据库改;
第二阶段:
协调者会收集所有参与者的意见。(1)如果收到参与者发来的not commit T信息,则标识着该事务不能提交,协调者会将Abort T 记录到日志中,并向所有参与者发送一个Abort T 信息,让所有参与者撤销在自身上所有的预操作;(2)如果协调者收到所有参与者发来prepare T信息,那么协调者会将Commit T日志写入磁盘,并向所有参与者发送一个Commit T信息,提交该事务。(3)若协调者迟迟未收到某个参与者发来的信息,则认为该参与者发送了一个VOTE_ABORT信息,从而取消该事务的执行。
参与者接收到协调者发来的Abort T信息以后,参与者会终止提交,并将Abort T 记录到日志中;如果参与者收到的是Commit T信息,则会将事务进行提交,并写入记录。
二、可能出现的问题
一般情况下,两阶段提交机制都能较好的运行,但可能出现下面三种问题:
(1)协调者不宕机,参与者宕机;
(2)协调者宕机,参与者不宕机;
(3)协调者宕机,参与者也宕机;
对于(1),当在事务进行过程中,有参与者宕机时,他重启以后,可以通过询问其他参与者或者协调者,从而知道这个事务到底提交了没有。当然,这一切的前提都是各个参与者在进行每一步操作时,都会事先写入日志。
对于(2),协调者宕机后,可以起新的协调者,然后查询所有参与者的状态是否有commit的,如果有,则继续commit,如果都没有,则abort。
对于(3),是唯一一个两阶段提交不能解决的困境是:当协调者在发出commit T消息后宕机了,而唯一收到这条命令的一个参与者也宕机了,这个时候这个事务就处于一个未知的状态,没有人知道这个事务到底是提交了还是未提交,从而需要数据库管理员的介入,防止数据库进入一个不一致的状态。当然,如果有一个前提是:所有节点或者网络的异常最终都会恢复,那么这个问题就不存在了,协调者和参与者最终会重启,其他节点也最终也会收到commit T的信息。
对于上面的困境,业界提出了三阶段提交的方法来此问题,即将二阶段提交的第二阶段再分为待定阶段(或预提交阶段)和确定阶段,从而变为三阶段;在待定阶段协调者log prepare_commit消息后向所有参与者发送prepare_commit消息, 待收到所有参与者回包(这里的回包结果只会成功)或超时时就进入第三段阶,log commit消息并向所有参与者发送commit消息。如果在待定阶段和确定阶段出现协调者和部分参与者同时宕机(即上面的困境),只要存活的协调者或参与者里有prepare_commit或commit消息,新的协调者可以继续进行commit消息,如果没有,就不commit消息,从而保证数据的一致性。
3 日志
数据库日志保证了事务执行的原子性和持久性,日志类型可以分为redo log,undo log,undo/redo log。
4 总结
二阶段提交和三阶段提交都是很好的分布式事务算法,三阶段提交是为解决二阶段提交未解决的问题(协调者宕机,参与者也宕机)而提出来的。不过这两种算法都只考虑一个协调者(主节点)的情况,没有考虑多个协调者和如何选出协调者的问题。而另一种知名分布式事务算法Paxos能解决多个协调者的情况,并提出了多数派的概念。
----------------------------------------其他----------------------------------