2. 工作流调度器azkaban
2.1 概述
2.1.1为什么需要工作流调度系统
- 一个完整的数据分析系统通常都是由大量任务单元组成:shell脚本程序,java程序,mapreduce程序、hive脚本等
- 各任务单元之间存在时间先后及前后依赖关系
- 为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;
例如,我们可能有这样一个需求,某个业务系统每天产生20G原始数据,我们每天都要对其进行处理,处理步骤如下所示:
- 通过Hadoop先将原始数据同步到HDFS上;
- 借助MapReduce计算框架对原始数据进行转换,生成的数据以分区表的形式存储到多张Hive表中;
- 需要对Hive中多个表的数据进行JOIN处理,得到一个明细数据Hive大表;
- 将明细数据进行复杂的统计分析,得到结果报表信息;
- 需要将统计分析得到的结果数据同步到业务系统中,供业务调用使用。
2.2 Azkaban介绍
Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
它有如下功能特点:
- Web用户界面
- 方便上传工作流
- 方便设置任务之间的关系
- 调度工作流
- 认证/授权(权限的工作)
- 能够杀死并重新启动工作流
- 模块化和可插拔的插件机制
- 项目工作区
- 工作流和任务的日志记录和审计
2. 3 Azkaban安装部署
1).准备工作
1. Azkaban Web服务器
azkaban-web-server-2.5.0.tar.gz
2. Azkaban执行服务器
azkaban-executor-server-2.5.0.tar.gz
3. mysql 脚本
MySQL
目前azkaban只支持 mysql,需安装mysql服务器,本文档中默认已安装好mysql服务器,并建立了 root用户,密码 123456
三个安装包:https://pan.baidu.com/s/1T4CXjs5Cf2DbZ9G413yUWg 提取码: a2x4
建一个文件夹 叫azkaban 然后将三个安装包都解压到azkaban目录下
命令:
tar –zxvf azkaban-executor-server-2.5.0.tar.gz -C azkaban
tar –zxvf azkaban-web-server-2.5.0.tar.gz -C azkaban
tar –zxvf azkaban-sql-script-2.5.0.tar.gz -C azkaban解压之后 将azkaban-web-server-2.5.0 修改名称 为 server, azkaban-executor-server-2.5.0 修改为 executor
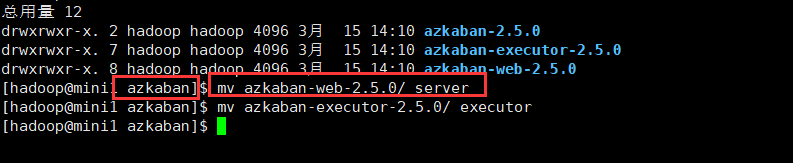
现在导入sql 脚本 启动mysql 数据库 在里面创建azkaban数据库 然后导入脚本 命令如下:
create database azkaban;
use azkaban;
source /home/hadoop/azkaban/azkaban-2.5.0/create-all-sql-2.5.0.sql;
show tables;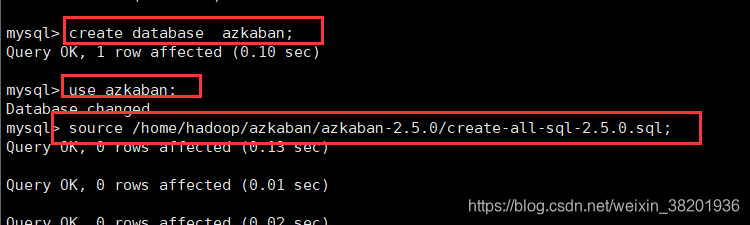
2)创建SSL配置
在azkaban文件下 执行命令 然后填写下面信息
keytool -keystore keystore -alias jetty -genkey -keyalg RSA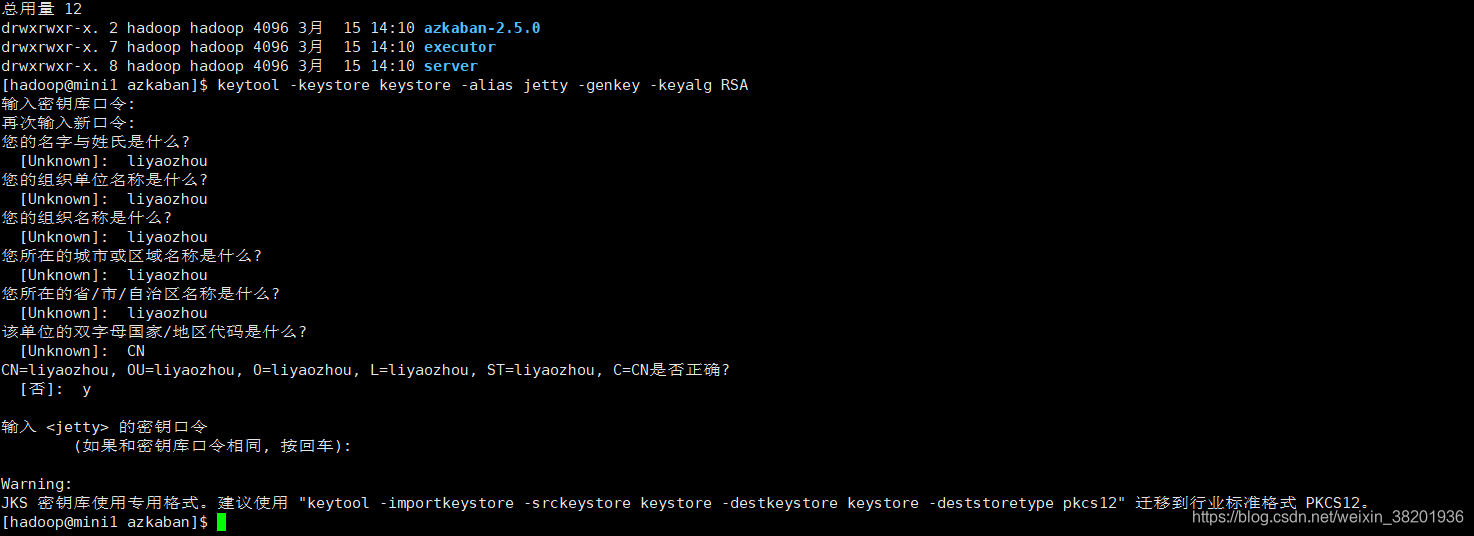
上面执行完之后 会在azkaban目录下生成 keystore 目录 然后将这个目录复制到sever 目录下:
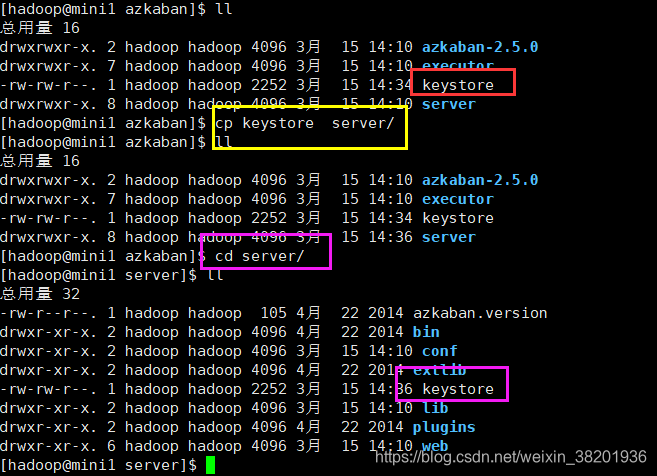
3)配置文件
执行完上面操作,现在需要配置服务器节点上的时区
- 先生成时区配置文件Asia/Shanghai,用交互式命令 tzselect 重开mini1虚拟机 在root用户下输入tzselect 然后根据提示选择数字
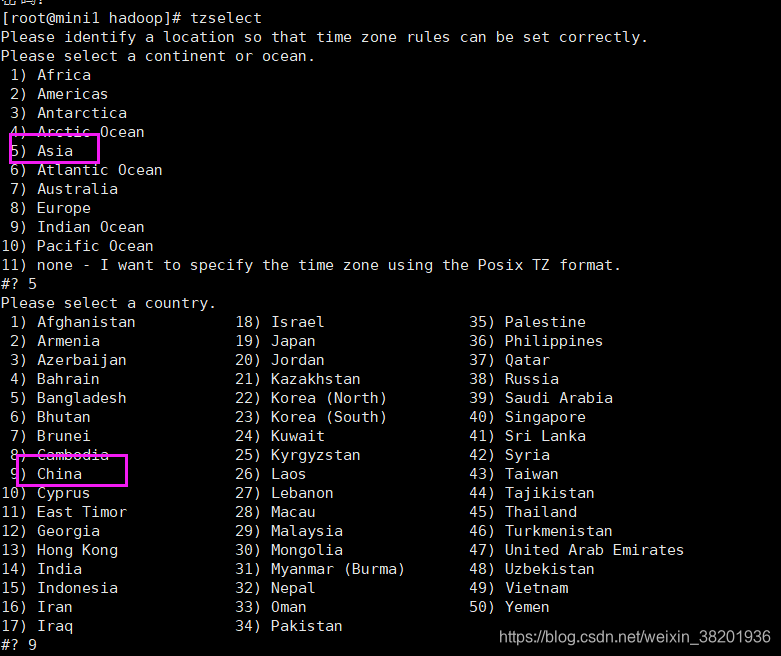
2.拷贝该时区文件,覆盖系统本地时区配置 在你的虚拟机上都覆盖一下
[root@mini1 hadoop]# cp /usr/share/zoneinfo/Asia/Shanghai/etc/localtime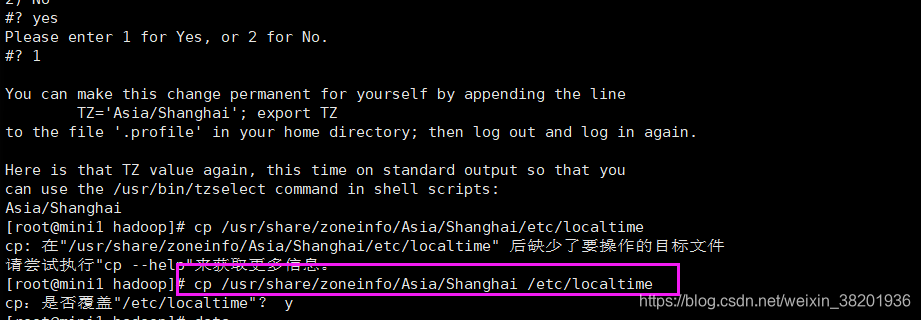
3. 覆盖之后,在root用户下 输入 date 查看虚拟机的计算机时间 如果不对,需要设置一下
设置时的命令为:
date -s '2019-03-19 15:16:30'
hwclock -w // 这句命令为直接将时间设置在硬件中,下次重启虚拟机后,时间就会同步

上述执行完之后,退回到hadoop 用户
现在需要修改几个文件
1 进入azkaban文件下,修改server/conf目录下 的azkaban.properties文件
命令如下:

需要修改的信息如下:1 修改地区 2 修改数据库用户名和密码 3刚才设置的keystore 设置的密码 我设置的是123456 修改完之后保存
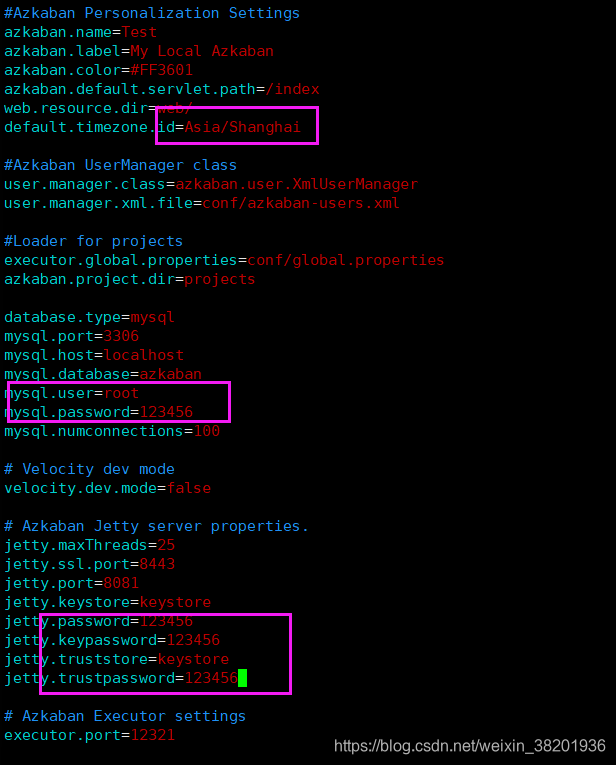
上面文件修改完之后 修改另一个文件
vi azkaban-users.xml然后在下面添加红框的内容 修改完之后 保存
<user username="admin" password="admin" roles="admin,metrics" />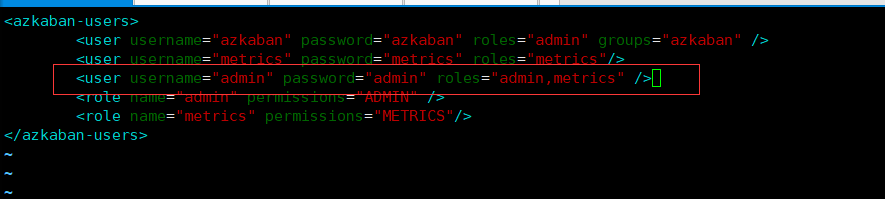
2 进入azkaban文件下,修改 executor/conf目录下 的azkaban.properties文件 修改内容如下面红框
vi azkaban.properties 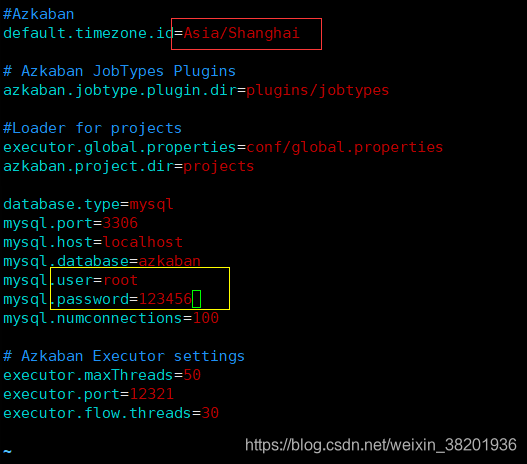
上述配置完之后,就可以启动服务器了 启动方式如下:
4)启动
1.启动web服务器 。 进入目录 azkaban/server下 输入 bin/azkaban-web-start.sh 如下图所示:
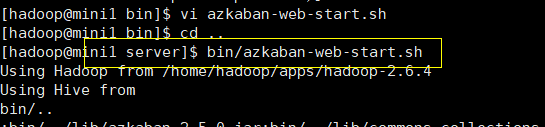
如果启动失败 是如下原因时:
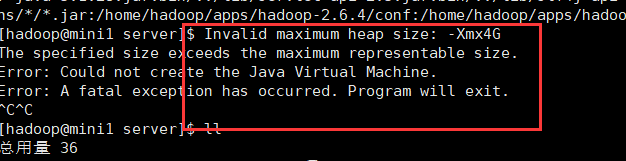
请修改azkaban-web-start.sh 启动文件 命令为:vi azkaban-web-start.sh
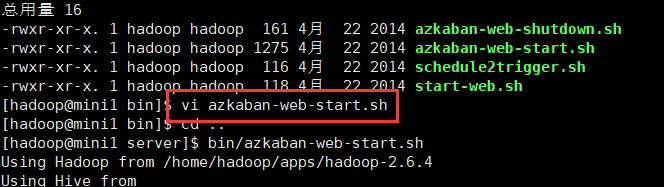
修改内容为:将AZKABAN_OPTS='-Xmx4G' 改为 AZKABAN_OPTS='-Xmx512M' 保存退出再重新启动就OK
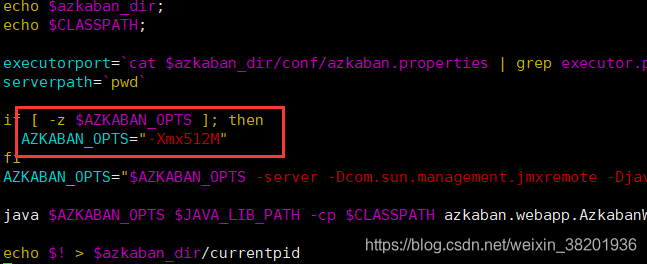
2.启动executor 。 进入目录 azkaban/executor下 输入 bin/azkaban-executor-start.sh 如果出现上述启动失败,同理修改就可以,最后再启动。
Web Server 和executor 都启动好了之后,在浏览器上输入https://mini1:8443 、这是输的是你的主机名,端口号是8443。