原文地址:
https://blog.safe.com/2019/01/fme-does-computer-vision/
FME 2019包含一套新的计算机视觉转换器,可以识别图像中的物体。以下是如何训练FME识别大量传入栅格数据中的自定义对象,以及使用FME来识别停车标志的可下载示例。

你在这张照片上看到了什么?你可能对这个问题比对图像更感到困惑 ,你在这里看到一条狗,为什么我要问这样一个微不足道的问题呢?我们很容易看到图像上的物体,这些物体只是不同颜色像素的组合,我们的大脑在这些组合中做出了很好的理解。
教会机器在图像上找到物体是一个复杂的过程,但在过去几十年中,计算机视觉领域已经进行了大量研究。目前,专业软件库能够完成人类视觉系统可以完成的许多任务,例如对象识别、条件检测、文本阅读等。
现在,通过FME 2019,您还可以尝试识别图片上的狗、猫或道路标志。这听起来令人兴奋吗?让我们深入了解细节。
FME进行目标识别
在后台,FME使用OpenCV,一个计算机视觉和机器学习软件库。对于FME 2019,我们实现了对象检测功能,它被包装为一系列RasterObjectDetector *转换器:
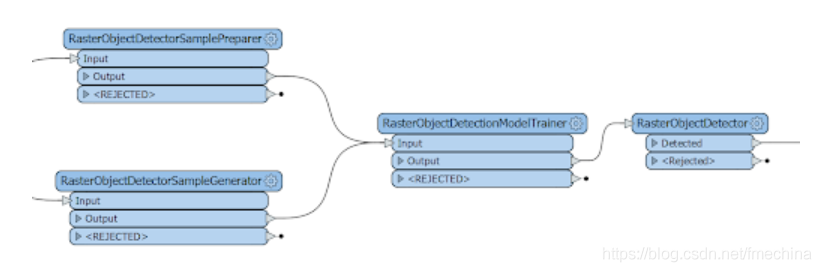
这里的机器学习办法是建议程序使用培训的图片数据,在这种情况下我们将识别我们感兴趣的对象,同时,我们将向FME显示那些不包含我们正在寻找的对象的照片。该程序在研究数据后,将学习如何在训练期间从未使用的新照片上判断是否存在需要的对象。RasterObjectDetector转换器附带了一些预定义的面部、身体部位、猫和其他用途的检测模型,但是自己建立一些训练模型用来识别适用于地理空间行业的东西,以便结果可以显示在地图上会非常有趣 。
示例:识别停止标志
实际上,找到合适的数据集可能是最大的问题。大多数人没有数百或数千个他们想要检测的物体的图像。

这里使用的训练数据包括100张带有停车标志(正面)的道路场景照片,以及100张没有标志(负面)的类似道路照片。利用场景所有必要的组件,可以训练FME识别新对象。
准备工作
第一步:绘制指示对象的矩形
首先需要在每个图像的停止标志周围画一个矩形。FME 2019附带了一个名为opencv_annotation.exe(OpenCV库的一部分)的实用程序,它从命令行运行,并提供一个简单的GUI,用于指定照片上标志(或多个标志)的位置。该实用程序位于FME 2019安装的plugins \ opencv \文件夹中。
使用这个程序制作命令行需要一些注意。以下是工作命令行的示例:
C:\ apps \ FME2019 \ plugins \ opencv \ opencv_annotation.exe --annotations =“C:\ Temp \ StopSignDataset \ annotations.txt” - images =“C:\ Temp \ StopSignDataset \ Positive \” - maxWindowHeight = 1000
“annotations”参数指示输出文件的位置。“图像”指定具有正片照片的文件夹。最后一个参数表示显示图像的最大高度,这对于高分辨率照片非常有用。
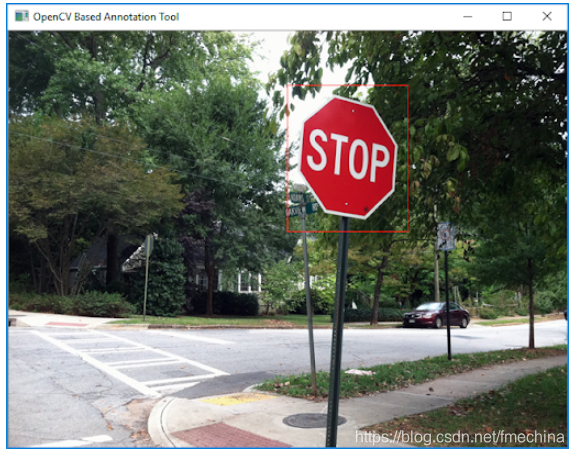
这项工作的结果是一个包含图像名称的注释文件(注意图像的路径必须相对于注释文件 - 您可能需要在第二步之前编辑文件)和图像上的符号的像素坐标:
Positive\ 1.jpg 1 217 2 114 110
Positive\ 10.jpg 1 288 352 552 546
Positive\ 11.jpg 1 330 60 404 418
Positive\ 38.jpg 2 511 64 58 70 849 199 146 147第二步:准备训练数据集
下一步,我们准备培训数据。asterObjectDetectorSamplePreparer将会使用带有和不带符号的照片,以及用于创建实际将参与训练的两个新文件的注释文件。
第三步:培训
培训的最后一步包括将这些文件发送到RasterObjectDetectionModelTrainer并设置训练的参数 - 模型类型(HAAR或LBP),级数,并行度和一些其他参数。“级数”参数增加了处理数据集所需的时间。它的值设置为20,我们的数据集培训几乎是即时的,而24个,大约需要30分钟。将值设置为更高的数字会导致处理时间过长且没有太大改进。输出结果是一个XML文件,这是一个经过训练的模型,足够智能检测照片上的停车标志。
分析
现在我们可以将图片提供到FME中。为了将视频分成帧,我使用SystemCaller,它运行FFmpeg程序(https://blog.safe.com/2017/11/fme-spatially-enabled-video-editor/)。对于使用有损压缩算法的JPEG图像,将图像质量设置为高(-qscale:v 2参数)非常重要。“”ffmpeg.exe“-i”C:\ temp \ video \ driving.mp4“-qscale:v 2 -vf fps = 1”C:\ temp \ images \ img_%05d.jpg“”
然后,图像可以直接进入RasterObjectDetector,它将尝试查找对象。
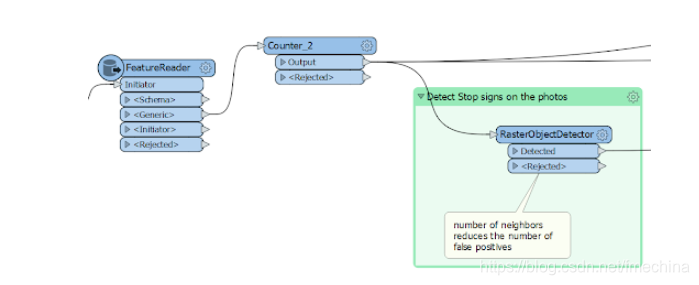
如果找到一个物体,转换器会在物体周围放置一个矩形,这就是转换器的输出结果。

提高质量
主要目标是:FME识别出大多数照片上的停车标志。如果提供的照片拍摄条件好一些,像是中午或阴天的时候拍摄,应该会返回更好的结果,在这种情况下,将“Minimum number of Neighbors”参数设置为更高的值将减少错误的数量,从而减少误报。
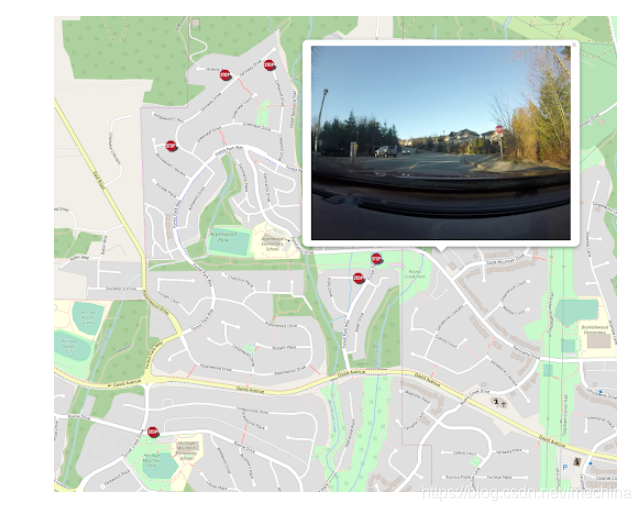
该过程的最后一步是将标志放在网络地图上。在“ https://www.safe.com/webinars/tools-for-visualizing-geospatial-data-in-a-web-browser/ ”中提到了使用FME和LeafletJS库创建简单的Web地图。简而言之,每个功能都是自己编写代码片段,然后使用Aggregator和AtttirbuteCreator,FME创建完整的HTML文件。
自己动手
工作空间,训练识别停止标志的模型,GPS轨道以及从视频中提取的图像可在以下地址中下载(https://hub.safe.com/templates/stopsigndetector#description)。请注意,训练模板(StopSignModelTrainer.fmwt)包含在主模板StopSignDetector.fmwt中。