今天是大年三十的前一晚,距离python二级考试还有一个多月的时间吧,虽然我在2018年下半年考试中已经及格通过了,但是我在这里呢还是为准备Python二级的同班同学还有学长,学弟学妹们写一篇关于python二级考试的注意事项,欢迎大家评论学习,大家共同进步,最后先拜个早年,祝愿全国各族各地的兄弟姐妹2019诸事顺利!
一.Python程序设计题
1.某自然数除它本身之外的所有因子之和等于该数,则该数被称为完数。请输出1000以内的完数。
'''某自然数除它本身之外的所有因子之和等于该数---完数
有如果想求一个数的整数因子,就是把这个数写成两个数的乘积的形式,
所有的可能的因子就是这个数的整数因子。'''
#1,3,5,15 这四个数是15的所有整数因子。
#主要思想:任何一个数 % 这个数的因子 == 0
for i in range(1,1001):
sum = 0
for j in range(1,i):
if i%j == 0:
sum += j
if sum == i:
print(i)

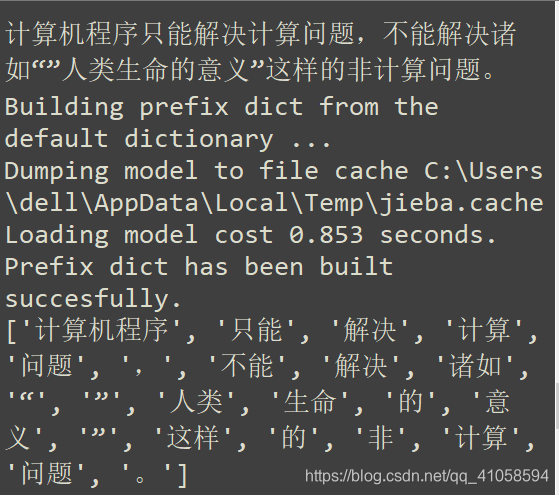
2.输入字符串,使用中文分词库输出精确模式的中文分词结果。
看到这个题目说是精准模式,那么Python分词库的精准模式函数就是:jieba.lcut
支持三种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
import jieba
Tempstr = input('输入你想输入的一段话:\n')
ls = jieba.lcut(Tempstr)
print(ls)
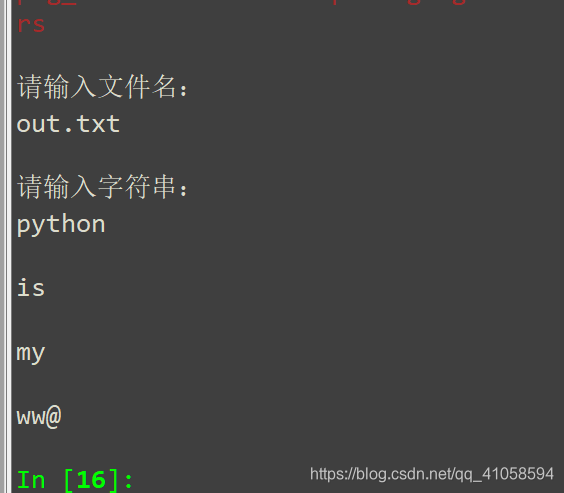
3.从键盘输入一些字符,逐个把它们写到指定的文件,直到输入一个@为止。
分析:输入字符串:用 Input ,写入指定文件先用open建立一个文件夹(名字依照题意建立)即:open(’***.txt’,‘w’)
filename = input("请输入文件名:\n")
with open(filename,"w") as fp:
ch = input("请输入字符串:\n")
while ch != '@':
if '@' in ch:
t = ch.find("@")
fp.write(ch[0:t])
break
else:
fp.write(ch + " ")
ch = input("")#me循环一次消除记录
fp.close()
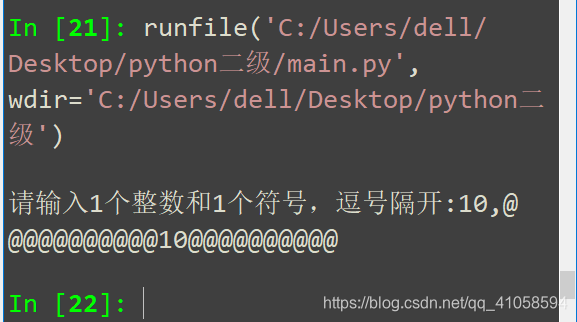
4.从键盘输入一个整数和一个字符,以逗号隔开,在屏幕上显示输出一条信息。
输入:
请输入1个整数和1个符号,逗号隔开:10,@
输出:
@@@@@@@@@@10@@@@@@@@@@
分析:【从键盘输入一个整数和一个字符,以逗号隔开以逗号分割】:input().split(’,’) (注意: —>这里面我用的是英文逗号);怎样实现数字在中间N个符号分别在该数字的两边呢?---->字符串的操作方法center str.center(x,y) 会用字符串str构造一个新的字符串,新的字符串长度是x, 两边填充y。
ls= input('请输入1个整数和1个符号,逗号隔开:').split(',')
print(ls[0].center(eval(ls[0])*2+len(ls[0]),ls[1]))
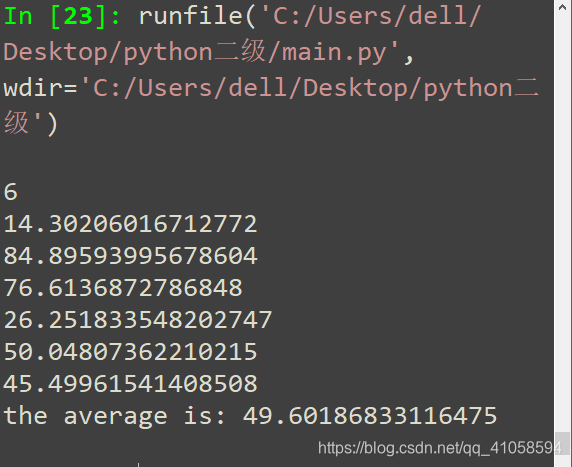
5.输入一个正整数n,自动生成n个1-100范围内的随机浮点数,计算输出每个随机数,并显示平均值。
分析:自动生成n个1-100范围内的随机浮点数 random.uniform(x, y)**(x – 随机数的最小值,包含该值。y – 随机数的最大值,不包含该值。 )**这里的n就用for循环!
import random
random.seed(1)
n = eval(input())
sum = 0
for i in range(n):
fl = random.uniform(1,100)
sum += fl
print(fl)
print('the average is:', sum/n)
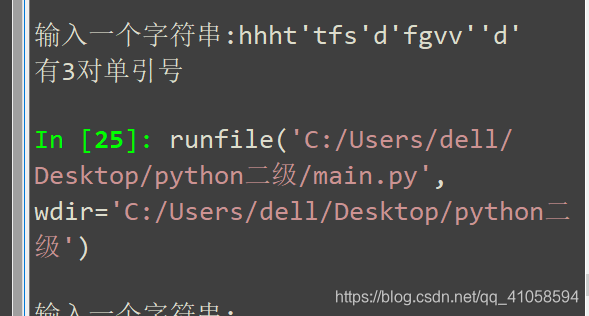
6.输入一个字符串,检查并统计字符串中包含的英文单引号的对数。如果没有找到单引号,就在屏幕上显示“没有单引号”;每统计到2个单引号,就算一对,如果找到2对单引号,就显示“找到了2对单引号”;如果找到3个单引号,就显示“有1对配对单引号,存在没有配对的单引号”。
st = input('输入一个字符串:')
pair = 0#记录单引号个数
count = 0#记录单引号对数
for s in st:
if s == "'":
pair += 1
if pair % 2 == 0:
count += 1
#根据题意判断
if pair == 0:
pro = "没有单引号"
elif pair % 2 == 0:
pro = "有{}对单引号".format(count)
else:
pro = "有{}对配对单引号,存在没有配对的单引号".format(count)
print(pro)
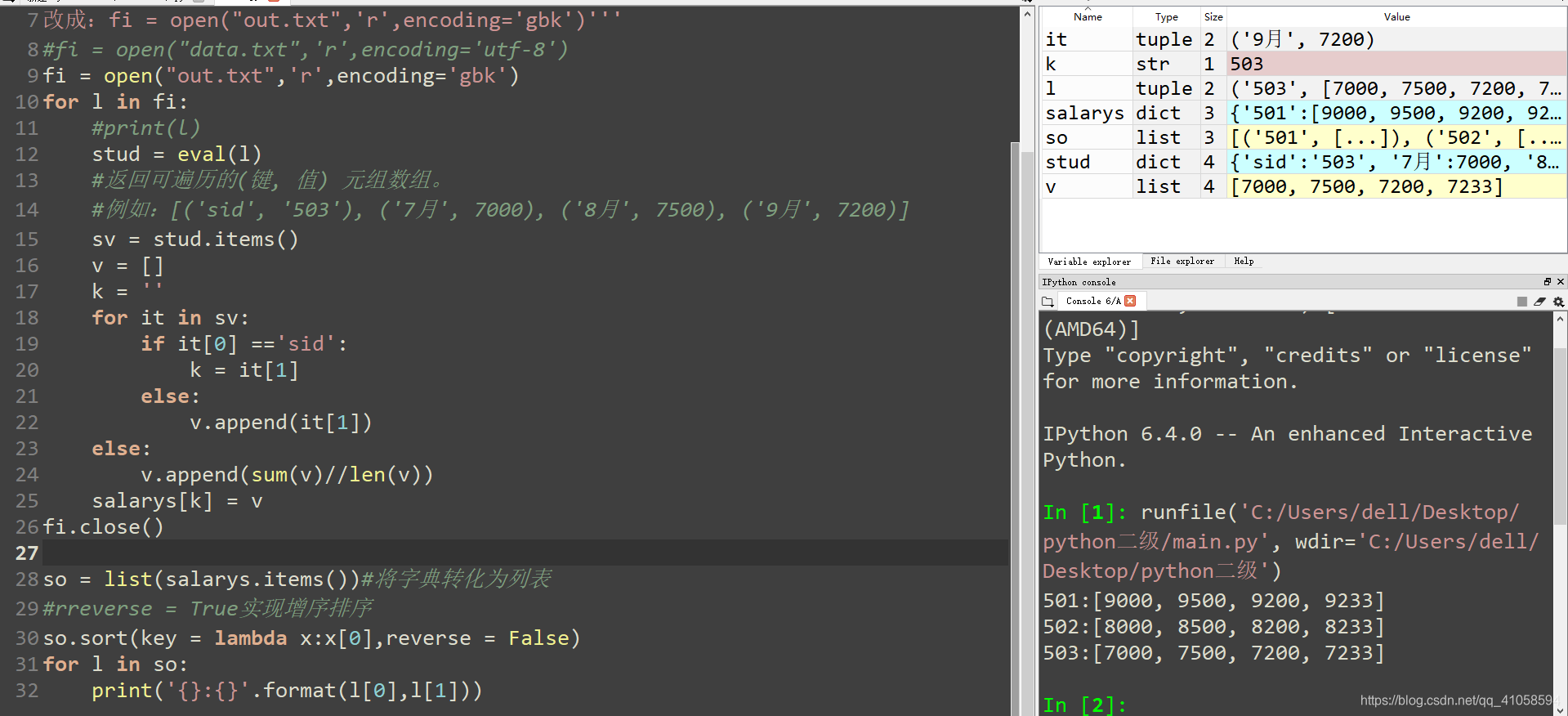
7.将文件的数据内容提取出来,计算每个人的平均工资,将其转化为字典salary,按照key的递增序在屏幕上显示输出score的内容,内容示例如下:
文件内容:{‘sid’:‘501’,‘7月’: 9000,‘8月’:9500,‘9月’:9200}
{‘sid’:‘502’,‘7月’: 8000,‘8月’:8500,‘9月’:8200}
{‘sid’:‘503’,‘7月’: 7000,‘8月’:7500,‘9月’:7200}
gaitxt文件命名为:data.txt
salarys = {}
'''fi = open("data.txt",'r',encoding='utf-8')
UnicodeDecodeError: 'utf-8' codec can't decode
byte 0xd4 in position 15:
invalid continuation byte
意思是:此程序执行之后出现错误,说是无法转成utf-8。
改成:fi = open("out.txt",'r',encoding='gbk')'''
#fi = open("data.txt",'r',encoding='utf-8')
fi = open("out.txt",'r',encoding='gbk')
for l in fi:
#print(l)
stud = eval(l)
#返回可遍历的(键, 值) 元组数组。
#例如:[('sid', '503'), ('7月', 7000), ('8月', 7500), ('9月', 7200)]
sv = stud.items()
v = []
k = ''
for it in sv:
if it[0] =='sid':
k = it[1]
else:
v.append(it[1])
else:
v.append(sum(v)//len(v))
salarys[k] = v
fi.close()
so = list(salarys.items())#将字典转化为列表
#rreverse = True实现序排序
so.sort(key = lambda x:x[0],reverse = False)
for l in so:
print('{}:{}'.format(l[0],l[1]))
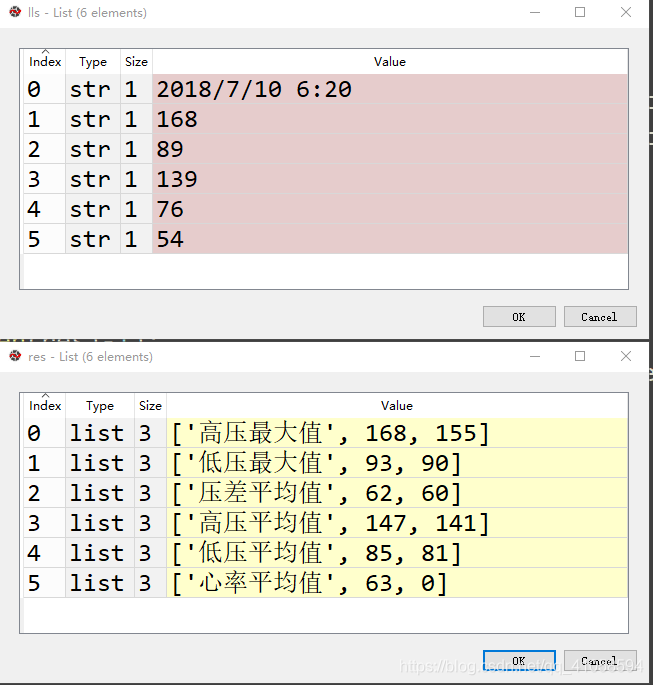
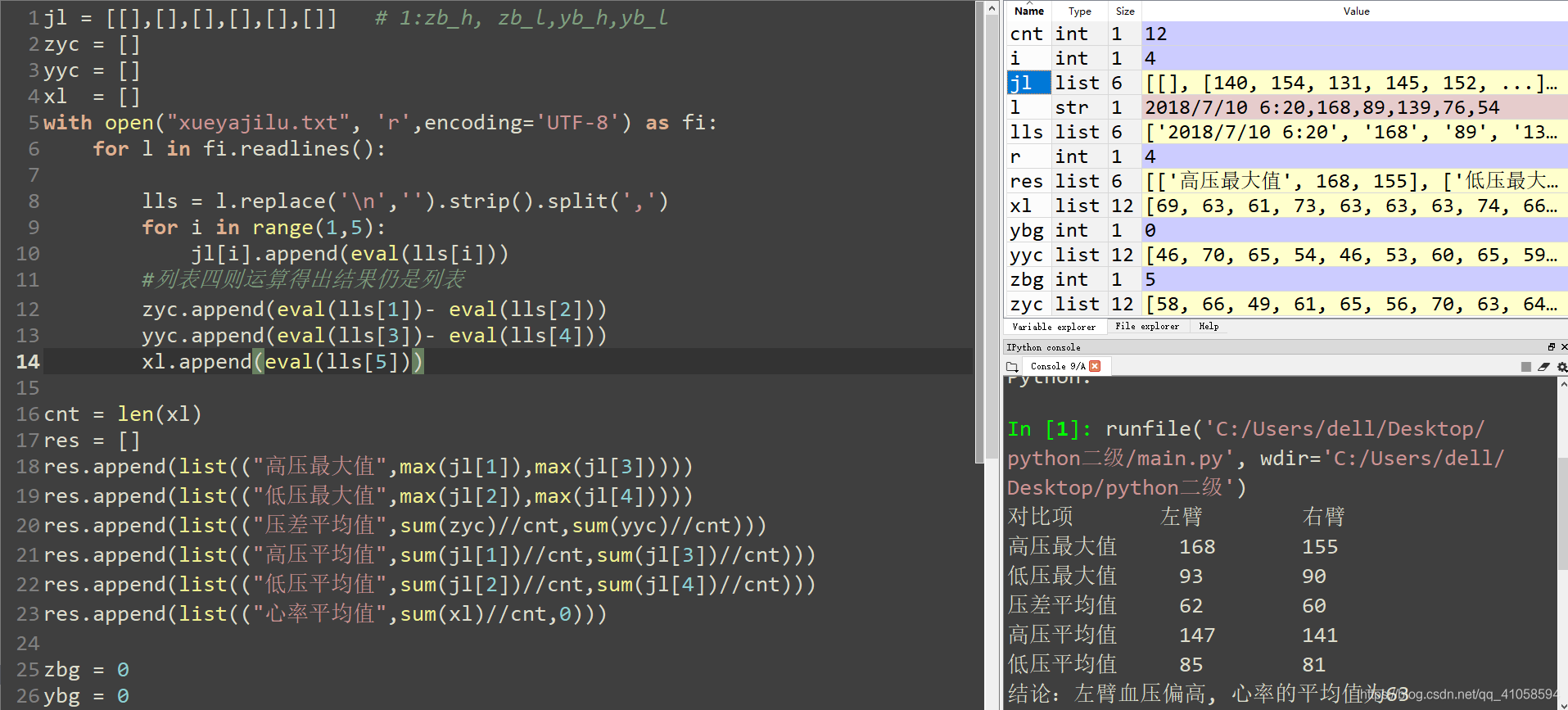
8.老王的血压有些高,医生让家属给老王测血压。老王的女儿记录了一段时间的血压测量值,在文件 xueyajilu.txt 中,内容示例如下:
2018/7/2 6:00,140,82,136,90,69
2018/7/2 15:28,154,88,155,85,63
2018/7/3 6:30,131,82,139,74,61
2018/7/3 16:49,145,84,139,85,73
2018/7/4 5:03,152,87,131,85,63
文件内各部分含义如下:
测量时间,左臂高压,左臂低压,右臂高压,右臂低压,心率
使用字典和列表类型进行数据分析,获取老王的
- 右臂的血压平均值
- 左臂和右臂的高压最高值、低压最高值
- 左臂和右臂的高/低压差平均值
- 心率的平均值
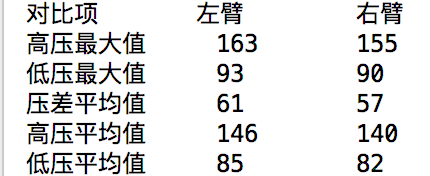
给出左臂和右臂血压情况的对比表,输出到屏幕上,请注意每行三列对齐。示例如下:
jl = [[],[],[],[],[],[]] # 1:zb_h, zb_l,yb_h,yb_l
zyc = []
yyc = []
xl = []
with open("xueyajilu.txt", 'r',encoding='UTF-8') as fi:
for l in fi.readlines():
lls = l.replace('\n','').strip().split(',')
for i in range(1,5):
jl[i].append(eval(lls[i]))
#列表四则运算得出结果仍是列表
zyc.append(eval(lls[1])- eval(lls[2]))
yyc.append(eval(lls[3])- eval(lls[4]))
xl.append(eval(lls[5]))
cnt = len(xl)
res = []
res.append(list(("高压最大值",max(jl[1]),max(jl[3]))))
res.append(list(("低压最大值",max(jl[2]),max(jl[4]))))
res.append(list(("压差平均值",sum(zyc)//cnt,sum(yyc)//cnt)))
res.append(list(("高压平均值",sum(jl[1])//cnt,sum(jl[3])//cnt)))
res.append(list(("低压平均值",sum(jl[2])//cnt,sum(jl[4])//cnt)))
res.append(list(("心率平均值",sum(xl)//cnt,0)))
zbg = 0
ybg = 0
print('{:<10}{:<10}{:<10}'.format("对比项", "左臂", "右臂"))
for r in range(len(res)-1):
print('{:<10}{:<10}{:<10}'.format(res[r][0],res[r][1],res[r][2]))
if res[r][1]> res[r][2]:
zbg += 1
else:
ybg += 1
if zbg > ybg:
print('结论:左臂血压偏高',end ='')
elif zbg == ybg:
print('结论:左臂血压与右臂血压相当',end ='')
else:
print('结论:右臂血压偏高',end ='')
print(', 心率的平均值为{}'.format(res[5][1]))
9.新年python词云玩法拜年!
# coding: utf-8
from wordcloud import WordCloud
import cv2
import jieba
import matplotlib.pyplot as plt
with open('data.txt','r') as f:
text = f.read()
cut_text =" ".join(jieba.cut(text))
color_mask = cv2.imread('zhu.jpg')
cloud = WordCloud(
#设置字体
font_path=" C:\\Users\\dell\\Desktop\\STXINGKA.TTF",
#设置背景色
background_color='black',
#词云形状
mask=color_mask,
#允许最大词汇
max_words=2000,
#最大号字体
max_font_size=20
)
wCloud = cloud.generate(cut_text)
wCloud.to_file('cloud.jpg')
plt.imshow(wCloud, interpolation='bilinear')
plt.axis('off')
plt.show()

通过这八个Python程序设计题,我个人感觉如果将这八个题目如果做熟练,看题目自己去写代码的话,那么二级肯定会过,重点是第8题,需要注意的地方和重点很多,学习编写程序设计我们注重的是思路,总之多敲多练,今天八道题,明天再八道,那么我个人感觉python二级就这16道题目就完全KO!谢谢各位,多多评论,互相学习!!