YOLO全称You Only Look Once,是一个端到端(end-to-end)的目标检测算法,现在已经发展到第三个版本。由于第三个版本已经比较复杂,我们选学习第一个版本。
github上有个同学实现了一个pytorch的版本:https://github.com/xiongzihua/pytorch-YOLO-v1
我基于他的源码学习,学习过程中的代码修改放在:https://git.dev.tencent.com/zzpu/yolov1.git
1 数据集介绍
训练使用的数据集是voc2012,测试使用的数据集是voc2007test,关于数据集的介绍可以看
https://blog.csdn.net/wenxueliu/article/details/80327316
数据集子文件夹存放内容如下:
.
└── VOCdevkit #根目录
└── VOC2012 #不同年份的数据集,这里只下载了2012的,还有2007等其它年份的
├── Annotations #存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等
├── ImageSets #该目录下存放的都是txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本
│ ├── Action
│ ├── Layout
│ ├── Main
│ └── Segmentation
├── JPEGImages #存放源图片
├── SegmentationClass #存放的是图片,分割后的效果,见下文的例子
└── SegmentationObject #存放的是图片,分割后的效果,见下文的例子
但是作者做了一些处理,将图片标签信息打包进一个txt文件,适应目标检测训练任务需求:
文件内容如下,格式是【图片文件名 物体1信息(左上角X1, 左上 角Y1,右下角X2,右下角Y2,物体类别) ,物体2信息(左上角X1, 左上 角Y1,右下角X2,右下角Y2,物体类别)...】

看下源码中是如何处理的
train_dataset = yoloDataset(root=file_root,list_file=['voc2012.txt'],train=True,transform = [transforms.ToTensor()] )
train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=4)
# test_dataset = yoloDataset(root=file_root,list_file='voc07_test.txt',train=False,transform = [transforms.ToTensor()] )
test_dataset = yoloDataset(root=file_root,list_file='voc2007test.txt',train=False,transform = [transforms.ToTensor()] )
test_loader = DataLoader(test_dataset,batch_size=batch_size,shuffle=False,num_workers=4)
载入训练数据集和测试数据集
class yoloDataset(data.Dataset):
image_size = 448
def __init__(self,root,list_file,train,transform):
print('data init')
self.root=root
self.train = train
self.transform=transform
self.fnames = [] #图片文件名
self.boxes = [] #图片中物体坐标集合
self.labels = [] #图片中物体类别集合
self.mean = (123,117,104)#RGB
if isinstance(list_file, list):
# Cat multiple list files together.
# This is especially useful for voc07/voc12 combination.
#将voc2007和voc2012两个数据集的标签整合为一个
tmp_file = '/tmp/listfile.txt'
os.system('cat %s > %s' % (' '.join(list_file), tmp_file))
list_file = tmp_file
with open(list_file) as f:
lines = f.readlines()
for line in lines:
splited = line.strip().split()
self.fnames.append(splited[0]) #文件名
num_boxes = (len(splited) - 1) // 5 #运算符执行地板除法(向下取整除),它会返回整除结果的整数部分
box=[]
label=[]
for i in range(num_boxes):
x = float(splited[1+5*i]) #左上角
y = float(splited[2+5*i])
x2 = float(splited[3+5*i]) #右下角
y2 = float(splited[4+5*i])
c = splited[5+5*i] #分类
box.append([x,y,x2,y2])
label.append(int(c)+1) #图片中物体类别集合
self.boxes.append(torch.Tensor(box))
self.labels.append(torch.LongTensor(label))
#图片中物体数
self.num_samples = len(self.boxes)可以看到代码中先将两个数据集的标签整合为一个文件,然后一行一行的读入,用三个列表存储图片文件路径,图片中物体集合和物体类别集合,初始化中并没有做过多处理
self.fnames = [] #图片文件名
self.boxes = [] #图片中物体坐标集合
self.labels = [] #图片中物体类别集合2 YOLO输出适配
YOLO论文中,论文作者训练采用的输入图像分辨率是448x448,S=7,B=2;采用VOC 20类标注物体作为训练数据,C=20。因此输出向量为7*7*(20 + 2*5)=1470维。作者开源出的YOLO代码中,全连接层输出特征向量各维度对应内容如下:
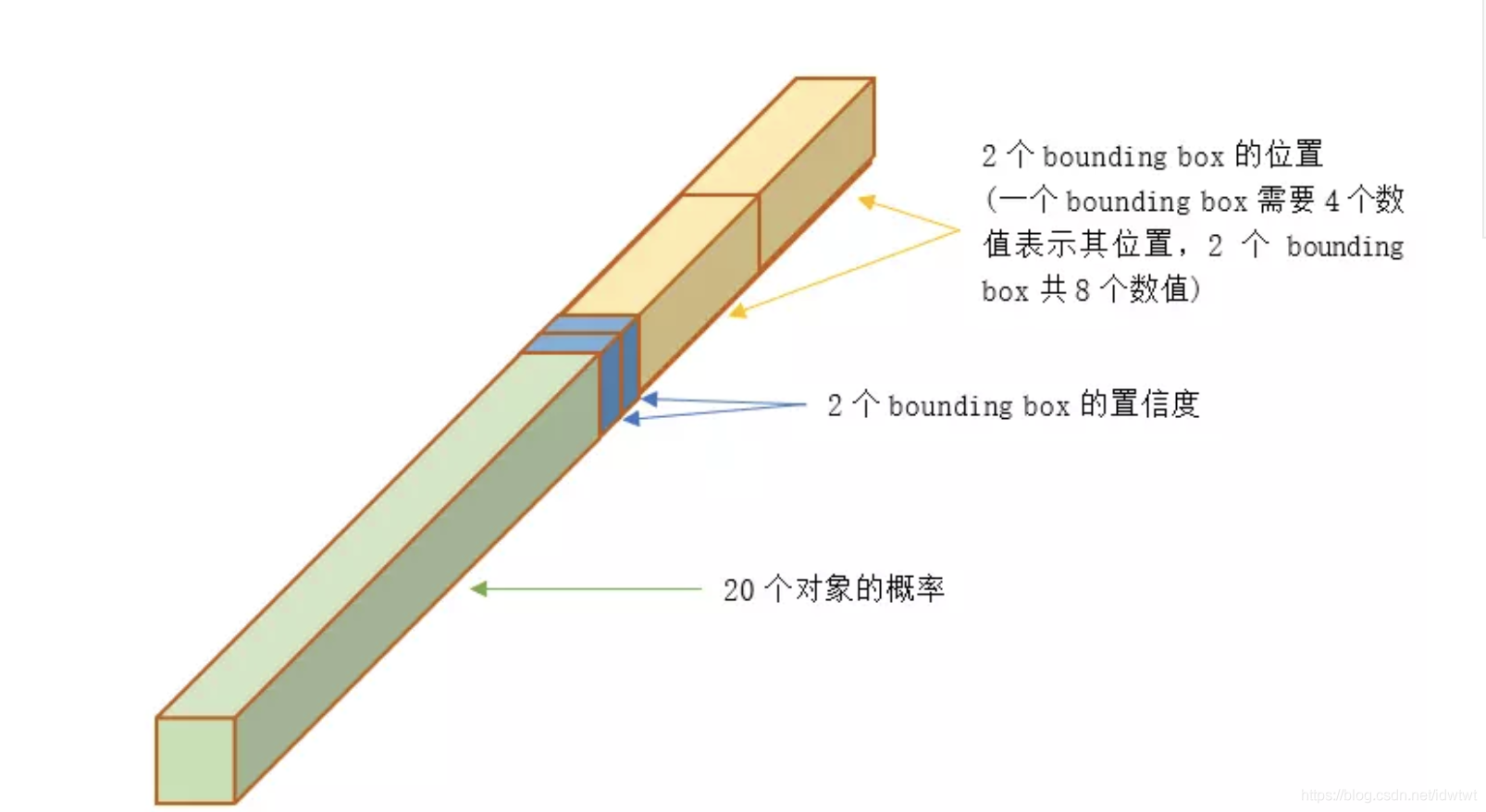
数据集的图片标签也要适配到这种格式,处理过程主要是在函数encoder中完成的:
def __getitem__(self,idx):
fname = self.fnames[idx]
#读取jpg图片---是BGR格式
img = cv2.imread(os.path.join(self.root+fname))
#每张图的标签
boxes = self.boxes[idx].clone()
labels = self.labels[idx].clone()
if self.train:
#img = self.random_bright(img)
#左右翻转
img, boxes = self.random_flip(img, boxes)
#伸缩变形
img,boxes = self.randomScale(img,boxes)
#图片预处理
#平滑处理
img = self.randomBlur(img)
#亮度调节
img = self.RandomBrightness(img)
#色度调节
img = self.RandomHue(img)
#饱和度调节
img = self.RandomSaturation(img)
img,boxes,labels = self.randomShift(img,boxes,labels)
img,boxes,labels = self.randomCrop(img,boxes,labels)
# #debug
# box_show = boxes.numpy().reshape(-1)
# print(box_show)
# img_show = self.BGR2RGB(img)
# pt1=(int(box_show[0]),int(box_show[1])); pt2=(int(box_show[2]),int(box_show[3]))
# cv2.rectangle(img_show,pt1=pt1,pt2=pt2,color=(0,255,0),thickness=1)
# plt.figure()
# # cv2.rectangle(img,pt1=(10,10),pt2=(100,100),color=(0,255,0),thickness=1)
# plt.imshow(img_show)
# plt.show()
# #debug
h,w,_ = img.shape
#坐标归一化处理
boxes /= torch.Tensor([w,h,w,h]).expand_as(boxes)
img = self.BGR2RGB(img) #because pytorch pretrained model use RGB
img = self.subMean(img,self.mean) #减去均值
#调整图片尺寸为448*448(因为voc的图片大小不一)
img = cv2.resize(img,(self.image_size,self.image_size))
#将图片标签编码到7x7*30的向量
target = self.encoder(boxes,labels)# 7x7x30
for t in self.transform:
img = t(img)
return img,target
def __len__(self):
return self.num_samples
def encoder(self,boxes,labels):
'''
boxes (tensor) [[x1,y1,x2,y2],[]]
labels (tensor) [...]
return 7x7x30
'''
grid_num = 14
target = torch.zeros((grid_num,grid_num,30))
cell_size = 1./grid_num
#右下坐标-左上坐标
#x2,y2 # x1,y1
wh = boxes[:,2:]-boxes[:,:2]
#物体中心坐标集合
cxcy = (boxes[:,2:]+boxes[:,:2])/2
for i in range(cxcy.size()[0]):
#物体中心坐标
cxcy_sample = cxcy[i]
#指示落在那网格,如[0,0]
ij = (cxcy_sample/cell_size).ceil()-1 #
# 0 1 2 3 4 5 6 7 8 9
#[中心坐标,长宽,置信度,中心坐标,长宽,置信度, 20个类别] x 7x7
target[int(ij[1]),int(ij[0]),4] = 1 #第一个框的置信度
target[int(ij[1]),int(ij[0]),9] = 1 #第二个框的置信度
target[int(ij[1]),int(ij[0]),int(labels[i])+9] = 1 #类别
#xy为归一化后网格的左上坐标---->相对整张图
xy = ij*cell_size
#物体中心相对左上的坐标 ---> 坐标x,y代表了预测的bounding box的中心与栅格边界的相对值
delta_xy = (cxcy_sample -xy)/cell_size
#(1) 每个小格会对应B个边界框,边界框的宽高范围为全图,表示以该小格为中心寻找物体的边界框位置。
#(2) 每个边界框对应一个分值,代表该处是否有物体及定位准确度
#(3) 每个小格会对应C个概率值,找出最大概率对应的类别P(Class|object),并认为小格中包含该物体或者该物体的一部分。
target[int(ij[1]),int(ij[0]),2:4] = wh[i] #坐标w,h代表了预测的bounding box的width、height相对于整幅图像width,height的比例
target[int(ij[1]),int(ij[0]),:2] = delta_xy
#每一个网格有两个边框
target[int(ij[1]),int(ij[0]),7:9] = wh[i] #长宽
target[int(ij[1]),int(ij[0]),5:7] = delta_xy #中心坐标偏移
return target这里有一个地方需要注意的是,在YOLOv1中一个每个格子两个bounding box,但是但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体,所以代码中将拟合的两个目标bounding box,都设置为一样,而且置信度都为1(一个格子一个物体,没有其他)。
3 图片的预处理
图片预处理在上面中提到的__getitem__函数中做的,主要做一些平滑,亮度随机调节等,然后是将图片大小都调整为448*448,因为YOLOv1的输入图片尺寸要求为448*448,而数据集中的图片大小是不一的。