come from : https://www.cnblogs.com/justin-y-lin/p/5598305.html
什么是core dump?
分析core dump是Linux应用程序调试的一种有效方式,像内核调试抓取ram dump一样,core dump主要是获取应用程序崩溃时的现场信息,如程序运行时的内存、寄存器状态、堆栈指针、内存管理信息、函数调用堆栈信息等。
Core dump又称为“核心转储”,是Linux基于信号实现的。Linux中信号是一种异步事件处理机制,每种信号都对应有默认的异常处理操作,默认操作包括忽略该信号(Ignore)、暂停进程(Stop)、终止进程(Terminate)、终止并产生core dump(Core)等。通常以下信号会触发core dump:
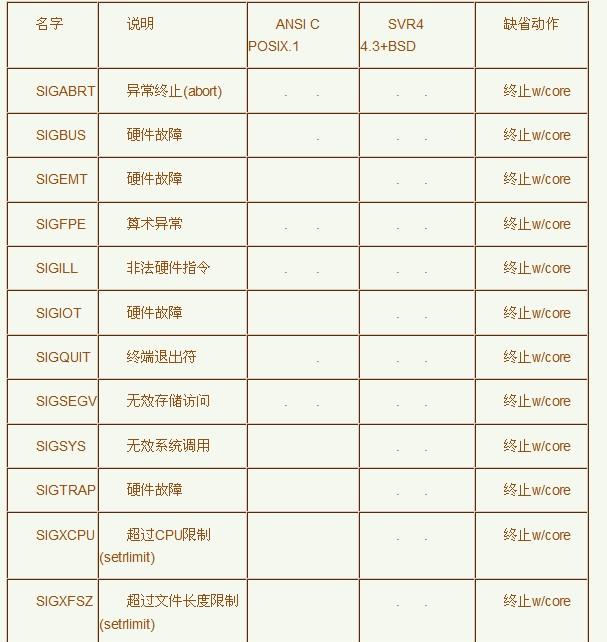
什么情况下会产生core dump呢?
以下情况会出现应用程序崩溃导致产生core dump:
- 内存访问越界 (数组越界、字符串无\n结束符、字符串读写越界)
- 多线程程序中使用了线程不安全的函数,如不可重入函数
- 多线程读写的数据未加锁保护(临界区资源需要互斥访问)
- 非法指针(如空指针异常或者非法地址访问)
- 堆栈溢出
怎么获取core dump呢?
Linux提供了一组命令来配置core dump行为:
1. ulimit –c 查看core dump机制是否使能,若为0则默认不产生core dump,可以使用ulimit –c unlimited使能core dump

2. cat /proc/sys/kernel/core_pattern 查看core文件默认保存路径,默认情况下是保存在应用程序当前目录下,但是如果应用程序中调用chdir()函数切换了当前工作目录,则会保存在对应的工作目录
3. echo “/data/xxx/<core_file>” > /proc/sys/kernel/core_pattern 指定core文件保存路径和文件名,其中core_file可以使用以下通配符:
%% 单个%字符
%p 所dump进程的进程ID
%u 所dump进程的实际用户ID
%g 所dump进程的实际组ID
%s 导致本次core dump的信号
%t core dump的时间 (由1970年1月1日计起的秒数)
%h 主机名
%e 程序文件名
4. ulimit –c [size] 指定core文件大小,默认是不限制大小的,如果自定义的话,size值必须大于4,单位是block(1block = 512bytes)
怎么分析core dump?
我们首先编写一个程序,人为地产生core dump并获取core dump文件。
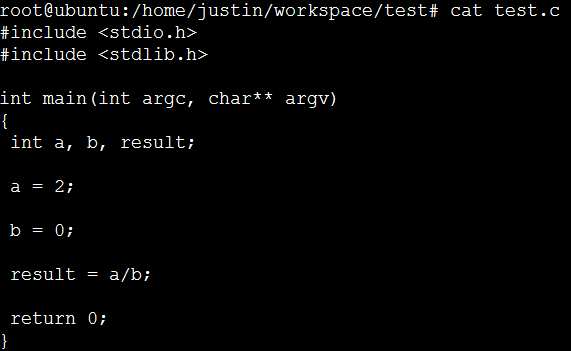
程序如上图,我们通过除零操作产生core dump

编译运行产生了浮点数异常,从而引发core dump (注:编译时必须添加-g参数,表示添加调试信息,这样才可以使用gdb进行调试)

当前目录下产生了core文件,使用file命令查看core文件类型

发现core文件类型为ELF格式,即可执行文件,使用readelf查看ELF文件头部信息如下
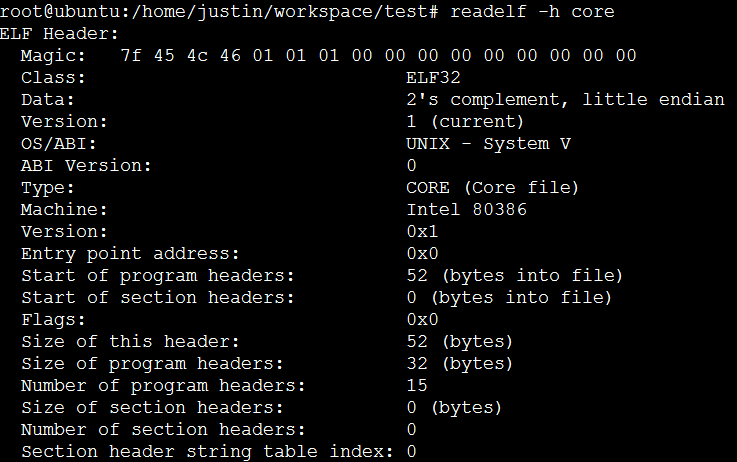
通过Type字段可以看到,该文件为core文件
前面我们讲到core dump可以查看应用程序崩溃时的现场信息,这里,我们需要gdb命令辅助实现,使用gdb test core(即test可执行文件和core文件)
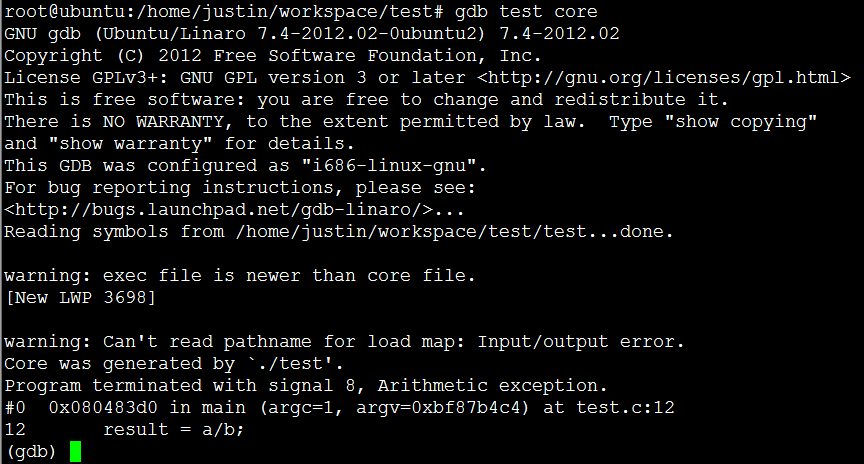
其中打印出导致core dump产生的原因,即Arithmetic exception,同时打印出了出问题的代码行result = a/b; 这里可以注意到当前还处在gdb调试环境中。可以通过bt –n (backtrace)显示函数调用栈信息,n表示显示的调用栈层数。因为test.c调试程序不涉及函数调用,所以我们只能看到main函数的栈信息,如果程序是在main函数的字函数中出错,则可以打印更多的调用栈信息。
通过disassemble命令可以打印出错时的汇编代码片段,其中箭头指向的是错误行。
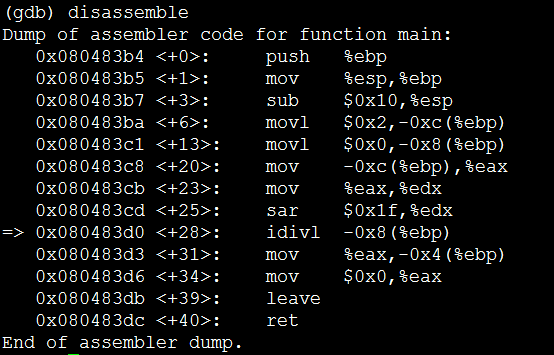
可以看到调用了div指令做除法操作,被除数是-0x8(%ebp),指当前栈基址向下偏移8个字节所在内存单元的数值,EBP是栈基址寄存器。同时我们可以看到前面通过movl $0x0, -0x8(%ebp)将0保存到该内存单元,证明被除数为0。