简介
TensorFlow使用数据流图将计算表示为独立的指令之间的依赖关系。这可生成低级别的编程模型,在该模型中,您首先定义数据流图,然后创建TensorFlow会话,以便在一组本地和远程设备上运行图的各个部分。
如果您计划直接使用低级别编程模型,,本指南将是您最实用的参考资源。较高阶的API(例如tf.estimator.Estimator和Keras)会向最终用户隐去图和会话的细节内容,但如果您希望理解这些API的实现方式,本指南仍会对你有所帮助。
为什么使用数据流图?
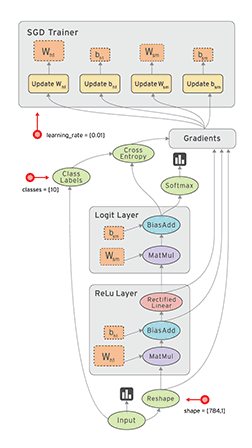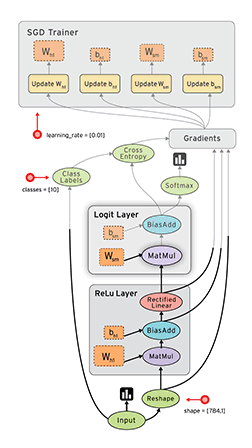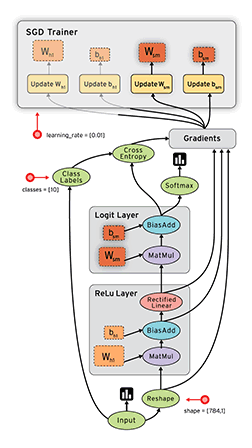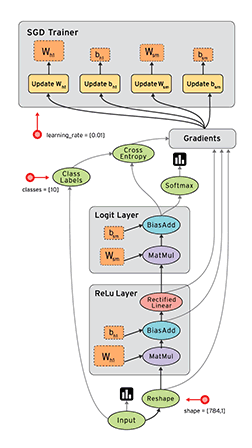
数据流是一种用于并行计算的常用编程模型。在数据流图中,节点表示计算单元,边表示计算使用或产生的数据。例如,在TensorFlow图中,tf.matmul操作对应于单个节点,该节点具有两个传入边(要相乘的矩阵)和一个传出边(乘法的结果)。
在执行您的程序时,数据流可以为TensorFlow提供多项优势:
- 并行处理。通过使用明确的边来表示操作之间的依赖关系,系统可以轻松识别能够并行执行的操作。
- 分布式执行。通过使用明确的边来表示操作之间流动的值,TensorFlow可以将您的程序划分到连接至不同机器的多台设备(CPU、GPU和TPU)。TensorFlow将在这些设备之间进行必要的通信和协调。
- 编译。TensorFlow的XLA编译器可以使用数据流图的信息生成更快的代码,例如将相邻的操作融合到一起。
- 可移植性。数据流图是一种不依赖于语言的模型代码表示法。您可以使用Python构建数据流图,将其存储在SaveModel中,并使用C++程序进行恢复,从而实现低延迟的推理。
什么是tf.Graph?
tf.Graph包含两类相关信息:
- 图结构。图的节点和边缘,表示各个操作组合在一起的方式,但不规定它们的使用方式。图结构与汇编代码类似:检查图结构可以传达一些有用的信息,但它不包含源代码传达的所有实用上下文信息。
- 图集合。TensorFlow提供了一种在tf.Graph中存储元数据集合的通用机制。tf.add_collection函数允许您将对象列表与一个键关联(其中tf.GraphKeys定义了部分标准键),tf.get_collection允许您查询与某个键关联的所有对象。TensorFlow库的许多部分会使用此设施资源:例如,当您创建tf.Variable时,系统会默认将其添加到表示“全局变量”和“可训练变量”的集合中。当您后续创建 tf.train.Saver或 tf.train.Optimizer时,这些集合中的变量将做默认参数。
创建tf.Graph
大多数TensorFlow程序都以数据流图构建阶段开始。在此阶段,您会调用TensorFlow API函数,这些函数可以构建新的tf.Operation(节点)和tf.Tensor(边)对象并将它们添加到tf.Graph实例中。TensorFlow提供了默认图,此图是同一上下文中的所有API函数的明确参数。例如:
- 调用tf.constant(42.0)可创建一个tf.Operation,该操作可以生成值42.0,将该值添加到默认图中,并返回表示常量值的tf.Tensor。
- 调用tf.matmul(x,y)可创建单个tf.Operation,该操作会将tf.Tensor对象x和y的值相乘,将其添加到默认图中,并返回表示乘法结果的tf.Tensor。
- 执行 v=tf.Variable(0)可向图添加一个tf.Operation,该操作可以存储一个科协入的张量,该值在多个 tf.Session.run调用之间保持恒定。tf.Variable对象会封装此操作,并可以像张量一样使用,即读取以存储值的当前值。tf.Variable对象也具有 assign 和 assign_add 等方法,这些方法可以创建 tf.Operation对象,这些对象在执行时更新已存储的值。
- 调用 tf.train.Opitimizer.minimize 可将操作和张量添加到计算梯度的默认图中,并返回一个tf.Operation,该操作在运行时会将这些梯度应用到一组变量上。
大多数程序仅依赖默认图。尽管如此,请参阅处理多个图了解更加高级的用例。高阶API(比如 tf.estimator.Estimator API)可替您管理默认图,并且还具有其它功能,例如创建不同的图以用于训练和评估。
注意:调用 TensorFlow API 中的大多数函数只会将操作和张量添加到默认图中,而不会执行实际计算。您应编写这些函数,直到拥有表示整个计算(例如执行梯度下降法的一步)的 tf.Tensor 或 tf.Operation,然后将该对象传递给 tf.Session 以执行计算。更多详情请参阅“在 tf.Session 中执行图”部分。
命名指令
tf.Graph 对象会定义一个命名空间(为其包含的 tf.Operation对象)。TensorFlow会自动为您的图中的每个指令选择一个唯一名称,但您也可以指定描述性名称,使您的程序阅读和调试起来更轻松。TensorFlow API提供两种方法来覆盖操作名称:
- 如果API函数会创建新的 tf.Operation或返回新的 tf.Tensor,则会接受可选 name 参数。例如,tf.constant(42.0,name="answer")会创建一个新的 tf.Operation(名为“answer”)并返回一个 tf.Tensor(名为"answer:0")。如果默认图已包含名为“answer”的操作,则TensorFlow会在名称上附加“_1”、“_2”等字符,以便让名称具有唯一性。
- 借助 tf.name_scope函数,您可以向在特定上下文中创建的所有操作添加名称作用域前缀。 当前名称作用域前缀是一个用 “/” 分割的名称列表,其中包含所有活跃 tf.name_scope 上下文管理器的名称。如果某个名称作用域已在当前上下文中被占用,TensorFlow将在该作用域上附加 “_1”、“_2”等字符。例如:
1 c_0 = tf.constant(0, name="c") # => operation named "c" 2 3 # Already-used names will be "uniquified". 4 c_1 = tf.constant(2, name="c") # => operation named "c_1" 5 6 # Name scopes add a prefix to all operations created in the same context. 7 with tf.name_scope("outer"): 8 c_2 = tf.constant(2, name="c") # => operation named "outer/c" 9 10 # Name scopes nest like paths in a hierarchical file system. 11 with tf.name_scope("inner"): 12 c_3 = tf.constant(3, name="c") # => operation named "outer/inner/c" 13 14 # Exiting a name scope context will return to the previous prefix. 15 c_4 = tf.constant(4, name="c") # => operation named "outer/c_1" 16 17 # Already-used name scopes will be "uniquified". 18 with tf.name_scope("inner"): 19 c_5 = tf.constant(5, name="c") # => operation named "outer/inner_1/c"
图可视化工具使用名称范围来为指令分组并降低图的视觉复杂性。更多信息请参阅可视化您的图
请注意,tf.Tensor对象以输出张量的 tf.Operation明确命名。张量名称的形式为 “<OP_NAME>:<i>”,其中:
- <OP_NAME> 是生成该张量的操作的名称
- <i> 是一个整数,表示该张量在操作的输出中的索引。
将操作放置到不同的设备上
如果您希望TensorFlow程序使用多台不同的设备,则可以使用 tf.device函数轻松地请求在特定上下文中创建的所有操作放置到同一设备(或同一类型的设备)上。
设备规范具有以下形式:
1 /job:<JOB_NAME>/task:<TASK_INDEX>/device:<DEVICE_TYPE>:<DEVICE_INDEX>
其中:
- <JOB_NAME> 是一个字母数字字符串,并且不以数字开头。
- <TASK_INDEX> 是一个非负整数,表示名为<JOB_NAME>的作业中的任务的索引。请参阅 tf.train.ClusterSpec 了解作业和任务的说明。
- <DEVICE_TYPE> 是一种注册设备类型(例如GPU或CPU)。
- <DEVICE_INDEX> 是一个非负整数,表示设备索引,例如用于区分同一进程中使用的不同GPU设备。
您无需指定设备规范的每个部分。例如,如果您在单个GPU的单机器配置中运行,您可以使用 tf.device 将一些操作固定到CPU和GPU上:
1 # Operations created outside either context will run on the "best possible" 2 # device. For example, if you have a GPU and a CPU available, and the operation 3 # has a GPU implementation, TensorFlow will choose the GPU. 4 weights = tf.random_normal(...) 5 6 with tf.device("/device:CPU:0"): 7 # Operations created in this context will be pinned to the CPU. 8 img = tf.decode_jpeg(tf.read_file("img.jpg")) 9 10 with tf.device("/device:GPU:0"): 11 # Operations created in this context will be pinned to the GPU. 12 result = tf.matmul(weights, img)
如果您在典型的分布式配置中部署TensorFlow,您可以指定作业名称和任务ID,以便将变量放到参数服务器作业(“/job:ps”)中的任务上,并将其它操作放置到工作器作业(“job/worker”)中的任务上:
1 with tf.device("/job:ps/task:0"): 2 weights_1 = tf.Variable(tf.truncated_normal([784, 100])) 3 biases_1 = tf.Variable(tf.zeroes([100])) 4 5 with tf.device("/job:ps/task:1"): 6 weights_2 = tf.Variable(tf.truncated_normal([100, 10])) 7 biases_2 = tf.Variable(tf.zeroes([10])) 8 9 with tf.device("/job:worker"): 10 layer_1 = tf.matmul(train_batch, weights_1) + biases_1 11 layer_2 = tf.matmul(train_batch, weights_2) + biases_2
借助 tf.device,您可以高度灵活地选择单个操作或TensorFlow图地各个区域的放置方式。在很多情况下,简单的启发法具有良好的效果。例如,tf.train.replica_device_setter API可与tf.device 结合使用,以针对数据分布式训练放置操作。例如,以下代码段展示了 tf.train.replica_device_setter如何将不同放置策略应用于 tf.Variable对象和其它操作:
1 with tf.device(tf.train.replica_device_setter(ps_tasks=3)): 2 # tf.Variable objects are, by default, placed on tasks in "/job:ps" in a 3 # round-robin fashion. 4 w_0 = tf.Variable(...) # placed on "/job:ps/task:0" 5 b_0 = tf.Variable(...) # placed on "/job:ps/task:1" 6 w_1 = tf.Variable(...) # placed on "/job:ps/task:2" 7 b_1 = tf.Variable(...) # placed on "/job:ps/task:0" 8 9 input_data = tf.placeholder(tf.float32) # placed on "/job:worker" 10 layer_0 = tf.matmul(input_data, w_0) + b_0 # placed on "/job:worker" 11 layer_1 = tf.matmul(layer_0, w_1) + b_1 # placed on "/job:worker"
类似于张量的对象
许多TensorFlow操作都会接受一个或多个 tf.Tensor对象作为参数。例如,tf.matmul 接受两个tf.Tensor对象,tf.add_n 接受一个具有n个 tfTensor对象的列表。为了方便起见,这些函数将接受类张量对象来取代tf.Tensor,并将它明确转换为tf.Tensor(通过tf.convert_to_tensor 方法)。类张量对象包括以下类型的元素:
- tf.Tensor
- tf.Variable
- numpy.ndarray
- list(以及类似于张量的对象的列表)
- 标量Python类型:bool、float、int、str
您可以使用 tf.register_tensor_conversion_function 注册其它类张量类型。
注意:默认情况下,每次您使用同一个类张量对象时,TensorFlow 将创建新的 tf.Tensor。如果类张量对象很大(例如包含一组训练样本的 numpy.ndarray),且您多次使用该对象,则可能会耗尽内存。要避免出现此问题,请在类张量对象上手动调用 tf.convert_to_tensor 一次,并使用返回的 tf.Tensor。
在以下会话中执行图:tf.Session
TensorFlow 使用tf.Session 类来表示客户端程序(通常为Python程序,但也提供了其它语言的类似接口)与C++运行时之间的连接。tf.Session对象使得我们能够访问本地机器中的设备和使用分布式TensorFlow运行时的远程设备。它还可以缓存关于 tf.Graph的信息,使您能够多次高效地运行同一计算。
创建 tf.Session
如果您使用的是低阶TensorFlow API,您可以为当前默认图创建一个tf.Session,如下所示:
1 # Create a default in-process session. 2 with tf.Session() as sess: 3 # ... 4 5 # Create a remote session. 6 with tf.Session("grpc://example.org:2222"): 7 # ...
由于tf.Session拥有物理资源(例如GPU和网络连接),因此通常(在with代码块中)用作上下文管理器,并在您退出代码时自动关闭会话。您也可以在不使用 with 代码块的情况下创建会话,但应在完成会话时明确调用 tf.Session.close 以便释放资源。
注意:较高阶的 API(例如 tf.train.MonitoredTrainingSession 或 tf.estimator.Estimator)将为您创建和管理 tf.Session。这些 API 接受可选的 target 和 config 参数(直接接受,或作为 tf.estimator.RunConfig 对象的一部分),并具有相同的含义,如下所示。
tf.Session.init 接受三个可选参数:
- target。如果将此参数留空(默认设置),会话将仅使用本地机器中的设备。但是,您也可以指定 grpc:// 网址,以便指定TensorFlow服务器的地址,这使得会话可以访问该服务器控制的机器上的所有设备。请参阅 tf.train.Server以详细了解如何创建TensorFlow服务器。例如,在常见的图间复制配置中,tf.Session连接到tf.train.Server的流程与客户端相同。分布式TensorFlow部署指南介绍了其它常见情形。
- graph。在默认情况下,新的 tf.Session将绑定到当前的默认图,并且能够在当前的默认图中运行操作。如果您在程序中使用了多个图(更多详情请参阅使用多个图进行编程),则可以在构建会话时指定明确的 tf.Graph。
- config。此参数允许您指定一个控制会话行为的 tf.ConfigProto。例如,部分配置选项包括:
- allow_soft_placement。将此参数设置为 True 可启用“软”设备放置算法,该算法会忽略尝试将仅限CPU的操作分配到GPU上的 tf.device注解,并将这些操作放置到CPU上
- cluster_def。使用分布式TensorFlow时,此选项允许你指定要在计算中使用的机器,并提供作业名称、任务索引和网络地址之间的映射。详情请参阅 tf.train.ClusterSpec.as_cluster_def。
- graph_option.optimizer_options。在执行图之前使您能够控制TensorFlow对图实施的优化。
- gpu_options.allow_growth。此参数设置为 True 可更改GPU内存分配器,使该分配器逐渐增加分配的内存量,而不是在启动时分配大多数内存。