版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/86585753
1 Spark RDD 的五个特点
- 一系列的分片,类似 Hadoop 中的split;
- 在每个分片都有一个函数去迭代计算它;
- 一系列的依赖;
- 对于一个 K-V 的 RDD 可以指定一个 partition,告诉它如何分片,常用的有 hash,range
- 数据本地性;
2 Spark Shuffle
- shuffle -> re-distributing data
哪些操作会引起 shuffle
- 就有重新调整分区操作,eg:
repartition,coalesce - *BeyKey,eg:
groupByKey,reduceByKey - 关联操作:eg:
join,cogroup
3 Spark Scheduler
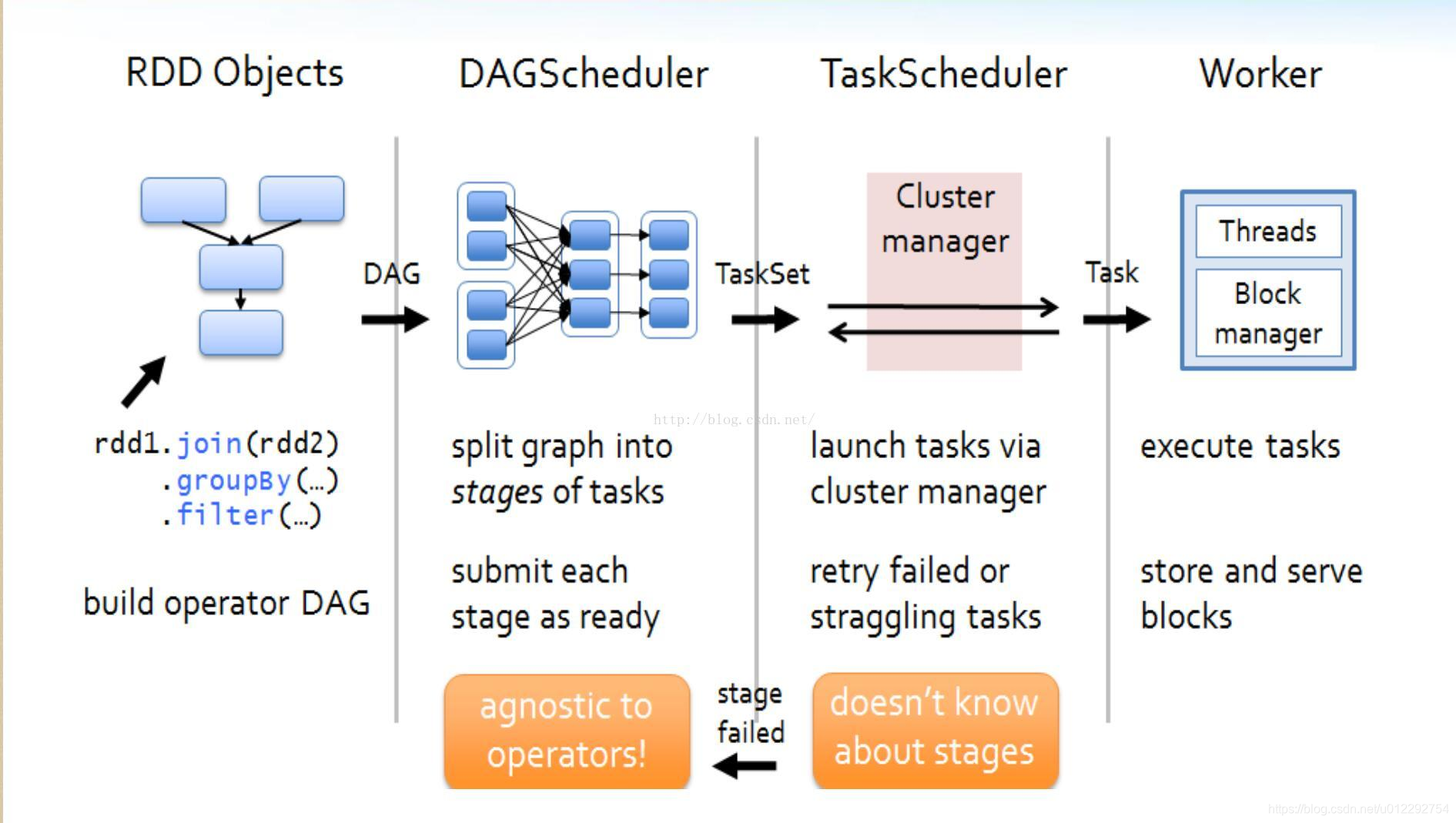
3.1 DAG Scheduler
- 接收用户提交的 job
- 构建 Stage,记录哪个 RDD 或者 Stage 输出被物化;
- 重新提交 shuffle 输出丢失的 stage
- 将 Taskset 传给底层调度器
3.2 TaskScheduler
- 提交 taskset 到集群运行并监控
- 为每一个 TaskSet 构建一个 TaskManager 实例管理这个 TaskSet 的生命周期
- 数据本地性决定每个 Task 最佳位置
- 推测执行,遇到 straggle 任务需要放到别的节点上重试出现 shuffle 输出 lost 要报告 fetch failed 错误
3.3 Task
- Task 是 Executor 中的执行单元
- Task 处理数据常见的两个来源:外部存储以及 shuffle 数据
- Task 可以运行在集群中的任意一个节点上;
- 为了容错,会将 shuffle 输出写到磁盘或者内存
4 Stage 划分的依据
- 有没有 Shuffle
5 Spark Core统计案例
5.1 案例1
类似MR中的二次排序
- 按照第一个字段进行分组
- 对分组的第二字段进行排序
- 获取每个分组 Top N
- 数据
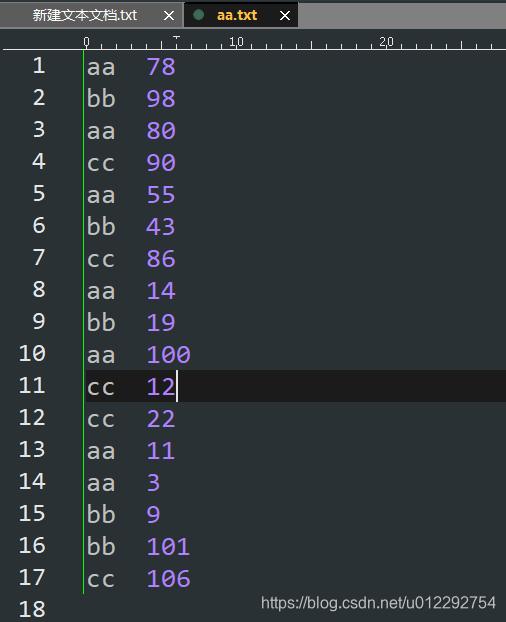
- 把数据上传到 HDFS

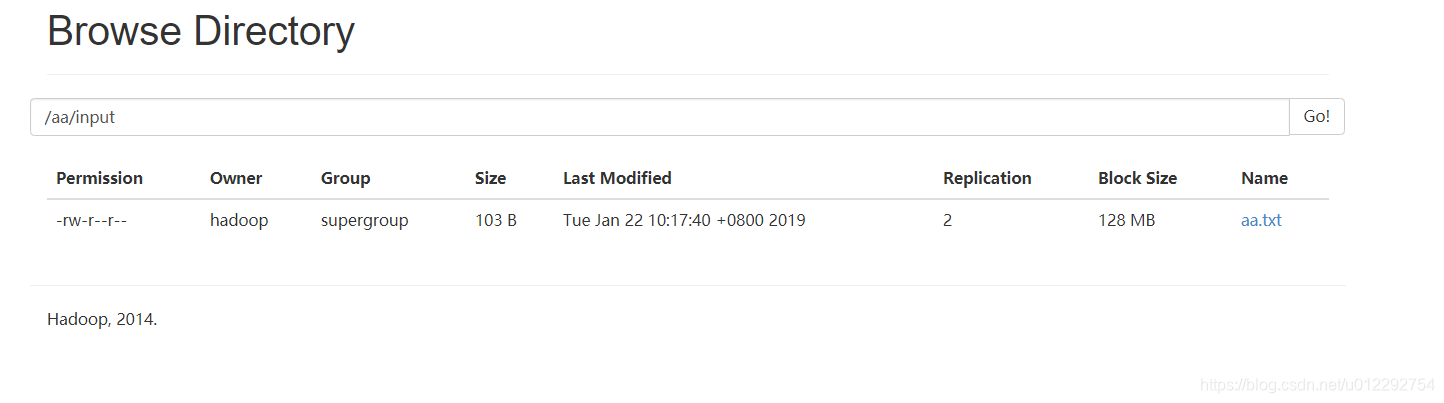
- 加载数据
scala> val rdd = sc.textFile("hdfs://node1:8020/aa/input")
rdd: org.apache.spark.rdd.RDD[String] = hdfs://node1:8020/aa/input MapPartitionsRDD[5] at textFile at <console>:24
scala> rdd.collect
res2: Array[String] = Array(aa 78, bb 98, aa 80, cc 90, aa 55, bb 43, cc 86, aa 14, bb 19, aa 100, cc 12, cc 22, aa 11, aa 3, bb 9, bb 101, cc 106)
scala> rdd.map(_.split("\t")).collect
res3: Array[Array[String]] = Array(Array(aa, 78), Array(bb, 98), Array(aa, 80), Array(cc, 90), Array(aa, 55), Array(bb, 43), Array(cc, 86), Array(aa, 14), Array(bb, 19), Array(aa, 100), Array(cc, 12), Array(cc, 22), Array(aa, 11), Array(aa, 3), Array(bb, 9), Array(bb, 101), Array(cc, 106))
scala> rdd.map(_.split("\t")).map(x =>(x(0),x(1))).collect
res4: Array[(String, String)] = Array((aa,78), (bb,98), (aa,80), (cc,90), (aa,55), (bb,43), (cc,86), (aa,14), (bb,19), (aa,100), (cc,12), (cc,22), (aa,11), (aa,3), (bb,9), (bb,101), (cc,106))
scala> rdd.map(_.split("\t")).map(x =>(x(0),x(1))).groupByKey.collect
res5: Array[(String, Iterable[String])] = Array((aa,CompactBuffer(100, 11, 3, 78, 80, 55, 14)), (bb,CompactBuffer(9, 101, 98, 43, 19)), (cc,CompactBuffer(12, 22, 106, 90, 86)))
scala> rdd.map(_.split("\t")).map(x =>(x(0),x(1))).groupByKey.map( x =>{
| val xx = x._1
| val yy = x._2
| yy.toList.map(_.toInt).sorted.reverse
| }).collect
res1: Array[List[Int]] = Array(List(100, 80, 78, 55, 14, 11, 3), List(101, 98, 43, 19, 9), List(106, 90, 86, 22, 12))
scala> rdd.map(_.split("\t")).map(x =>(x(0),x(1))).groupByKey.map( x =>{
| val xx = x._1
| val yy = x._2
| yy.toList.map(_.toInt).sorted.reverse.take(3)
| }).collect
res2: Array[List[Int]] = Array(List(100, 80, 78), List(101, 98, 43), List(106, 90, 86))
scala> rdd.map(_.split("\t")).map(x =>(x(0),x(1))).groupByKey.map( x =>{
| val xx = x._1
| val yy = x._2
| val yyy = yy.toList.map(_.toInt).sorted.reverse.take(3)
| (xx,yyy)
| }).collect
res3: Array[(String, List[Int])] = Array((aa,List(100, 80, 78)), (bb,List(101, 98, 43)), (cc,List(106, 90, 86)))
scala> val groupTopNRDD = rdd.map(_.split("\t")).map(x =>(x(0),x(1))).groupByKey.map( x =>{
| val xx = x._1
| val yy = x._2
| val yyy = yy.toList.map(_.toInt).sorted.reverse.take(3)
| (xx,yyy)
| })
groupTopNRDD: org.apache.spark.rdd.RDD[(String, List[Int])] = MapPartitionsRDD[21] at map at <console>:26
scala> groupTopNRDD.saveAsTextFile("hdfs://node1:8020/aa/out")
[hadoop@node1 ~]$ hdfs dfs -ls /aa/out
Found 3 items
-rw-r--r-- 2 hadoop supergroup 0 2019-01-22 11:15 /aa/out/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 69 2019-01-22 11:15 /aa/out/part-00000
-rw-r--r-- 2 hadoop supergroup 0 2019-01-22 11:15 /aa/out/part-00001
[hadoop@node1 ~]$ hdfs dfs -text /aa/out/part-00000
(aa,List(100, 80, 78))
(bb,List(101, 98, 43))
(cc,List(106, 90, 86))