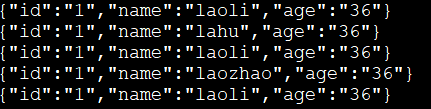
在flume接收数据时,有时候数据很杂乱,可以通过自定义拦截器,对数据进行拦截或者处理,这样就可以简单的对数据进行数据清洗了,下面是一个自定义的拦截器,把数据通过拦截器变成json格式的数据
在定义拦截器时可以参数官方给定的拦截器进行编写,比如TimestampInterceptor
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
public class JsonInterceptor implements org.apache.flume.interceptor.Interceptor {
private String[] schema; //元数据 id,name,age
private String separator;//数据的分割符
public JsonInterceptor(String schema,String separator){
this.separator = separator;
//字段名以 都逗号分割
this.schema = schema.split("[,]");
}
@Override
public void initialize() {
//什么都不做
}
@Override
public Event intercept(Event event) {
//传递引用,对数据进行修改在传给 events
Map<String,String> tuple = new LinkedHashMap<>(); //LinkedhashMap是有序的
String line = new String(event.getBody());
final String[] datas = line.split(separator);//对传的数据进行切分后再变换成json格式
for(int i= 0 ;i<schema.length;i++){
String key = schema[i];
String value = datas[i];
tuple.put(key,value);
}
//通过fastJson 把Map类型转换成Json格式的数据
final String json = JSONObject.toJSONString(tuple);
//重新复制event的Body
event.setBody(json.getBytes());
return event;
}
@Override
public List<Event> intercept(List<Event> events) { //这个方法是在source传数据 进行批量传输,一条一条传输会直接调用上面的方法
for(Event e : events){
intercept(e);//传递的是引用,所以此处的events中的改变了原数据,所以不用接收返回值
}
return events;//返回就是把对原始的event进行处理后返回
}
@Override
public void close() {
}
/*
Interceptor.builder的生名周期是
构造器 -> configure -> builder
*/
public static class Builder implements Interceptor.Builder{
private String fields;
private String separator;
@Override
public Interceptor build() {
//在build创建JsonInterceptor 的实例
return new JsonInterceptor(fields,separator);
}
/*configure 方法 读取配置文件
配置文件的属性
1、数据的分割符
2、字段的名字
3、数据的分割符
*/
@Override
public void configure(Context context) {
fields = context.getString("fields");
separator = context.getString("separator");
}
}
}
配置文件
#定义agent名, source、channel、sink的名称
a0.sources = r1
a0.channels = c1
#具体定义source
a0.sources.r1.type =exec
a0.sources.r1.command = tail -F /data/logs.txt
#拦截器,拦截器是配置在source后面的
a0.sources.r1.interceptors = i1
#$Builder 相当于一个内部类,new 一个内部类
a0.sources.r1.interceptors.i1.type = com.yt.flume.source.JsonInterceptor$Builder
#都有哪些字段名,字段名用什么分割
a0.sources.r1.interceptors.i1.fields = id,name,age
#分隔符是什么,数据的分割符
a0.sources.r1.interceptors.i1.separator = ,
a0.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a0.channels.c1.brokerList = bigdata01:9092,bigdata02:9092,bigdata03:9092
a0.channels.c1.zookeeperConnect=192.168.136.150:2181
a0.channels.c1.topic = userJson1
#false表示是以纯文本的形式写进入的,true是以event的形式写进入的,以event写进入时,会出现乱码, 默认是true
a0.channels.c1.parseAsFlumeEvent = false
a0.sources.r1.channels = c1
在flume中执行
/home/bigdata/install/apache-flume-1.5.0-cdh5.3.6-bin/bin/flume-ng agent --conf conf/ --name a0 --conf-file /home/bigdata/install/apache-flume-1.5.0-cdh5.3.6-bin/job/kafkacannel.conf -Dflume.root.logger==INFO,console
开启kafka的消费者
kafka-console-consumer.sh --bootstrap-server 192.168.136.150:9092,192.168.136.151:9092,192.168.136.152:9092 --topic userJson1 --from-beginning
手动增加文件内容
echo "1,laoli,36">> /data/logs.txt
可以看到如下结果