转载:https://blog.csdn.net/dufufd/article/details/78621158
OLAP介绍
一、发展背景
60年代,关系数据库之父E.F.Codd提出了关系模型,促进了联机事务处理(OLTP)的发展(数据以表格的形式而非文件方式存储)。1993年,E.F.Codd提出了OLAP概念,认为OLTP已不能满足终端用户对数据库查询分析的需要,SQL对大型数据库进行的简单查询也不能满足终端用户分析的要求。用户的决策分析需要对关系数据库进行大量计算才能得到结果,而查询的结果并不能满足决策者提出的需求。因此,E.F.Codd提出了多维数据库和多维分析的概念,即OLAP。
为了解决大型企业虽然拥有大量业务数据但难以及时有效的提取经营管理者所需要的信息这一问题,数据仓库技术应运而生。如何有效的组织大量数据,维护数据的一致性,方便用户访问,这只是数据仓库技术的一个方面。 数据仓库技术的另一个方面是如何为经营管理人员提供有效的使用信息,使他们能够使用数据仓库系统,对企业的经营管理作出正确的决策,从而为企业带来经济效益。要达到这个目的,就要借助OLAP技术。
OLAP技术主要通过多维的方式来对数据进行分析、查询和生成报表,它不同于传统的OLTP处理应用。OLTP应用主要是用来完成用户的事务处理,如民航订票系统和银行的储蓄系统等,通常要进行大量的更新操作,同时对响应的时间要求比较高。而OLAP系统的应用主要是对用户当前的及历史数据进行分析,扶助领导决策,其典型的应拥有对银行信用卡风险的分析与预测和公司市场营销策略的制定等,主要是进行大量的查询操作,对时间的要求不太严格。
在数据仓库应用中,OLAP应用一般是数据仓库应用的前端工具,同时OLAP工具还可以同数据挖掘工具、统计分析工具配合使用,增强决策分析功能。
二、什么是OLAP?
定义1 :OLAP(联机分析处理)是针对特定问题的联机数据访问和分析。通过对信息(维数据)的多种可能的观察形式进行快速、稳定一致和交互性的存取,允许管理决策人员对数据进行深入观察。
定义2 :OLAP(联机分析处理) 是使分析人员、管理人员或执行人员能够从多种角度对从原始数据中转化出来的、能够真正为用户所理解的、并真实反映企业维特性的信息进行快速、一致、交互地存取,从而获得对数据的更深入了解的一类软件技术。(OLAP委员会的定义)
OLAP的目标是满足决策支持或多维环境特定的查询和报表需求,它的技术核心是“维”这个概念,因此OLAP也可以说是多维数据分析工具的集合。
OLTP与OLAP的区别:
联机事务处理OLTP(on-line transaction processing)
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
联机分析处理OLAP(On-Line Analytical Processing)
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。OLAP采用多维报表和统计图形,查询提出以及数据输入直观灵活,用户可以方便的逐层细化,切块,切片,数据旋转
下表列出了OLTP与OLAP之间的比较:
|
|
OLTP |
OLAP |
| 用户 |
面向操作人员,支持日常操作 |
面向决策人员,支持管理需要 |
| 功能 |
日常操作处理 |
分析决策 |
| DB 设计 |
面向应用,事务驱动 |
面向主题,分析驱动 |
| 数据 |
当前的,最新的细节的,二维的分立的 |
历史的,聚集的,多维的,集成的,统一的 |
| 存取 |
可更新,读/写数十条记录 |
不可更新,但周期性刷新,读上百万条记录 |
| 工作单位 |
简单的事务 |
复杂的查询 |
| DB 大小 |
100MB-GB |
100GB-TB |
总的来说,OLTP就是面向我们的应用系统数据库的,OLAP是面向数据仓库的。
三、相关基本概念
1.维:是人们观察数据的特定角度,是考虑问题时的一类属性,属性集合构成一个维(时间维、地理维等)。
2.维的层次:人们观察数据的某个特定角度(即某个维)还可以存在细节程度不同的各个描述方面(时间维:日期、月份、季度、年)。
3.维的成员:维的一个取值。是数据项在某维中位置的描述。(“某年某月某日”是在时间维上位置的描述)
4.多维数组:维和变量的组合表示。一个多维数组可以表示为:(维1,维2,…,维n,变量)。(时间,地区,产品,销售额)
5.数据单元(单元格):多维数组的取值。(2000年1月,上海,笔记本电脑,$100000)
四、OLAP特性
(1)快速性:用户对OLAP的快速反应能力有很高的要求。系统应能在5秒内对用户的大部分分析要求做出反应。
(2)可分析性:OLAP系统应能处理与应用有关的任何逻辑分析和统计分析。
(3)多维性:多维性是OLAP的关键属性。系统必须提供对数据的多维视图和分析,包括对层次维和多重层次维的完全支持。
(4)信息性:不论数据量有多大,也不管数据存储在何处,OLAP系统应能及时获得信息,并且管理大容量信息。
五、OLAP多维数据结构
1.超立方结构(Hypercube)
超立方结构指用三维或更多的维数来描述一个对象,每个维彼此垂直。数据的测量值发生在维的交叉点上,数据空间的各个部分都有相同的维属性。(收缩超立方结构。这种结构的数据密度更大,数据的维数更少,并可加入额外的分析维)。
2.多立方结构(Multicube)
即将超立方结构变为子立方结构。面向某一特定应用对维进行分割, 它具有很强的灵活性,提高了数据(特别是稀疏数据)的分析效率。
六、OLAP多维数据分析
1.切片和切块(Slice and Dice)
在多维数据结构中,按二维进行切片,按三维进行切块,可得到所需要的数据。如在“城市、产品、时间”三维立方体中进行切块和切片,可得到各城市、各产品的销售情况。
2.钻取(Drill)
钻取包含向下钻取(Drill-down)和向上钻取(Drill-up)/上卷(Roll-up)操作, 钻取的深度与维所划分的层次相对应。
3.旋转(Rotate)/转轴(Pivot)
通过旋转可以得到不同视角的数据。
七、OLAP分类
按照存储方式:
ROLAP: relational olap,即关系olap。代表产品有Informix Metacube、Microsoft SQL Server OLAP Services。
MOLAP:multidimensional olap,即多维olap。代表产品有Hyperion(原Arbor Software) Essbase、Showcase Strategy等。
HOLAP(混合型olap hybrid olap)
按照处理地点:
Server OLAP:数据在服务器端的多维分析。代表产品有Microsoft SQL Server OLAP Services。
Client OLAP:把部分数据下载到本地,为用户提供本地的多维分析。代表产品有Brio Designer,Business Object。
以下是ROLAP、MOLAP与HOLAP三者之间优缺点对比:
|
|
优势 |
缺点 |
| ROLAP |
没有大小限制 |
一般比MDD响应速度慢 |
| MOLAP |
性能好、响应速度快 |
增加系统复杂度,增加系统培训与维护费用 |
| HOLAP |
基于混合数据组织的OLAP实现,如低层是关系型的,高层是多维矩阵型的。这种方式具有更好的灵活。holap结构不应该是molap与rolap结构的简单组合,而是这两种结构技术优点的有机结合,能满足用户各种复杂的分析请求。 |
迄今为止,对holap还没有一个正式的定义 |
八、OLAP评价准则
准则1 OLAP模型必须提供多维概念模型
准则2 透明性准则
准则3 存取能力准则
准则4 稳定的报表性能
准则5 客户/服务器体系结构
准则6 维的等同性准则
准则7 动态稀疏矩阵处理准则
准则8 多用户支持能力准则
准则9 非受限的跨维操作
准则10 直观的数据处理
准则11 灵活的报表生成
准则12 非受限的维与维的层次
九、、流行的OLAP工具介绍
OLAP产品:
Hyperion Essbase
Oracle Express
IBM DB2 OLAP Server
Sybase Power dimension
Informix Metacube
Microsoft Plato
Brio
Cognos
Business Object
MicroStrategy
OLAP产品涉及的业务操作:
由外部或内部数据源批量装入数据
由业务系统增量装入数据
沿数据层次汇总数据
对基于业务模型的新数据进行计算
时间序列分析
高复杂的查询
沿数据层次细化分析
随机查询
多个联机会话(多用户同时访问)
1. Hyperion Essbase
以服务器为中心的分布式体系结构
有超过100个的应用程序
有300多个用Essbase作为平台的开发商
具有几百个计算公式,支持多种计算
用户可以自己构件复杂的查询。
快速的响应时间,支持多用户同时读写
有30多个前端工具可供选择
支持多种财务标准
能与ERP或其他数据源集成
全球用户超过1500家
2. Oracle Express
Oracle DW支持GB~TB数量级
采用类似数组的结构,避免了连接操作,提高分析性能
提供一组存储过程语言来支持对数据的抽取
用户可通过Web和电子表格使用
灵活的数据组织方式,数据可以存放在Express Server内,也可直接在RDB上使用
有内建的分析函数和4GL用户自己定制查询
全球超过3000家
3. IBM DB2 OLAP Server
把Hyperion Essbase的OLAP引擎和DB2的关系数据库集成在一起。
与Essbase API完全兼容
数据用星型模型存放在关系数据库DB2中
4. Informix Metacube
采用metacube技术,通过OLE和ODBC对外开放,
采用中间表技术实现多维分析引擎,提高响应时间和分析能力
开放的体系结构可以方便地与其他数据库及前台工具进行集成
5. Sybase Power dimension
数据垂直分割(按“列”存储)
采用了突破性的数据存取方法------bit-wise索引技术
在数据压缩和并行处理方面有多到之处
提供有效的预连接(Pro-Jion)技术
十、OLAP发展
应用领域:
市场和销售分析(Marketing and Sales analysis)
电子商务分析(Clickstream analysis)
基于历史数据的营销(Database marketing)
预算(Budgeting)
财务报告与整合(Financial reporting and consolidation)
管理报告(Management reporting)
利益率分析(Profitability analysis)
质量分析(Quality analysis)
OLAP标准APB-1(AQT-Analytical Query Time作为统计指标)
从联机分析处理到联机分析挖掘(OLAM/OLAP挖掘)
将联机分析处理与数据挖掘以及在多维数据库中发现知识集成在一起。
联机分析挖掘提供在不同的数据子集和不同的抽象层上进行数据挖掘的工具.
联机分析挖掘为用户选择所期望的数据挖掘功能动态修改挖掘任务提供了灵活性 。
超立方体计算与传统挖掘算法的结合
先进行立方体计算,后进行数据挖掘
先对多维数据作数据挖掘,然后再利用立方体计算算法对挖掘结果分析
立方体计算与数据挖掘同时进行
回溯特性
OLAP基于Web的应用
静态方法 静态HTML报表
动态方法 通过HTML模板及元数据动态生成报表
改进方法 使用Java或ActiveX
十一、 OLAP展望
面向对象的联机分析处理
O3LAP(Object-Oriented OLAP)
对象关系的联机分析处理
OROLAP (Object Relational OLAP)
分布式联机分析处理
DOLAP (Distributed OLAP)
时态联机分析处理
TOLAP (Temporal OLAP)
OLAP基础
联机实时分析(OnlineAnalytical Processing, OLAP (/ˈoʊlæp/))技术是快速响应多维分(Multidimensionalanalysis, MDA)的一种解决方案。
首先,解释下什么是多维分析:多维分析是一种数据分析过程,在此过程中,将数据分成两类:维度(dimensions)和度量(metrics/measurements)。维度和度量的概念都出自于图论(graph theory),维度指能够描述某个空间中所有点的最少坐标(coordinate)数,即空间基数;度量指的是无向图中顶点(vertices)间的距离。在多维分析领域,维度一般包括字段值为字符类或者字段基数值较少且作为约束条件的离散数值类型;而度量一般包括基数值较大且可以参与运算的数值类字段,一般也称为指标。
OLAP技术可以看作是广义概念上的商业智能(Business Intelligence, BI)的一部分,而传统的OLAP分析应用通常包含了关系型数据库(relational database)、商业报告(business reporting)以及数据挖掘(data mining)等方面。
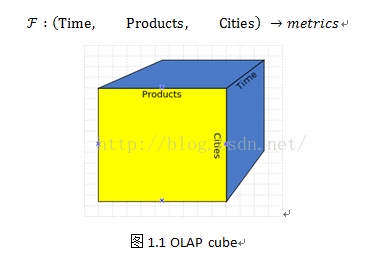
1.1 OLAP cube

OLAP cube可以简单描述为“多维数据集”。cube,我们可以想象为数据指标根据多维度封装成的一个立方体结构(以三维空间为例,如果维度数超过3,我们则称为“Hypercube”),如图1.1所示,图中的Time、Products、Cities就是OLAP分析中提取的三个维度,而这个立方体封闭区域所代表的含义就是在这三种维度下,某项指标的度量值,根据上述映射关系可以描述为:
1.2 维度模型
维度模型的概念出自于数据仓库领域,是数据仓库建设中的一种数据建模方法。维度模型主要由事实表和维度表这两个基本要素构成。
事实表是维度模型的基本表,用于存放大度量值,术语“事实”代表了一个度量值。举一个例子:查询某个客户在某个机构下某个产品合约账户的某个币种的某个时点余额,在各维度值(客户、产品合约、账户、机构、币种、日期)的交点处就可以得到一个度量值。维度值的列表定义了事实表的粒度,同时又确定了度量值的取值范围。
事实表的一行对应一个度量值,事实表的所有度量值必须具有相同的粒度。而事实可能是半加性质的,也可能是非加性质的,半加性事实表示度量值可以沿着某些维度由子类维度向父类维度进行聚合;非加性事实则完全不能相加,比如状态事实,对于这种非加性事实,我们只能采用计数或者求平均值,或者打印出全部事实行的方法进行分析。
所有事实表有两个或者两个以上的外关键字(如图1.2中FK符号标记的部分),外关键字用于连接到维度表的主关键字。例如,事实表中的“产品合约关键字”总是匹配产品合约这个维度表的一个特定“产品合约关键字”。如果事实表中的所有关键字都能分别与对应维度表中的主关键字正确匹配,就可以说这些表满足引用完整性的要求。事实表要通过与之相连的维度表进行存取。

维度表是进入事实表的入口。丰富的维度属性给出了丰富的分析切割能力。维度给用户提供了使用数据仓库的接口。最好的属性是文本的和离散的。属性应该是真正的文字而不应是一些编码简写符号。应该通过用更为详细的文本属性取代编码,力求最大限度地减少编码在维度表中的使用。
最后简单说明下维度表和事实表的融合。二者的融合也就是“维度模型”,“维度模型”一般采用“星型模式”或者“雪花模式”,如图1.4所示为“星型模式”,而“雪花模式”可以看作是“星型模式”的拓展,表现为在维度表中,某个维度属性可能还存在更细粒度的属性描述,即维度表的层级关系。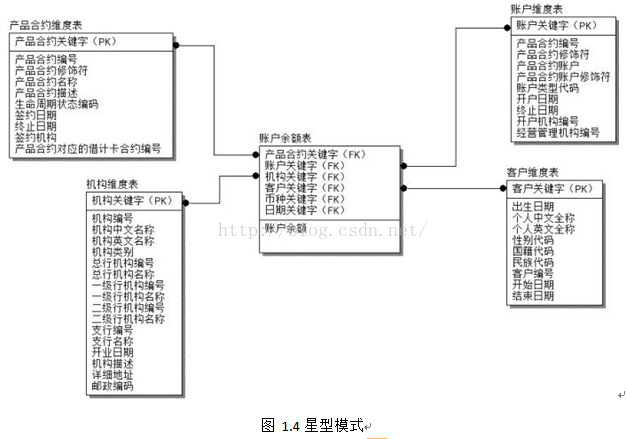
1.3 基本分析操作
OLAP允许用户从多种角度分析多维数据,主要包括以下五种基本操作:上卷(consolidation/roll-up)、下钻(drill-down)、切片(slice)、切块(dice)和旋转(pivot)。
1.3.1 上卷(consolidation/Roll-up)
上卷表示沿着某一维度按照一定的规则(rule)对数据进行聚合(aggregation)操作,沿着某一维度,即按照层级关系从子类维度向父类维度作聚合。
1.3.2 下钻(Drill-down)
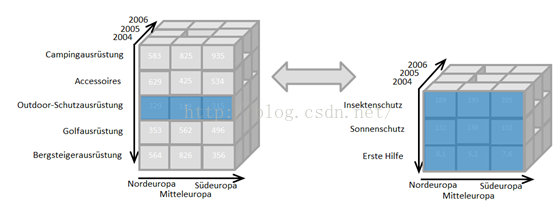
下钻和上卷正好相反,允许用户从已聚合的数据集中提取出所关注的细节。下图表示了从“Outdoor-Schutzausrüstung”这个父类维度中抽取出三个子类维度的下钻过程。
1.3.3 切片(Slice)
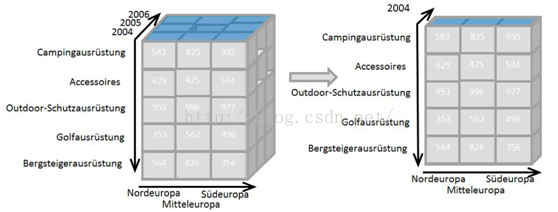
切片表示通过选择某个维度的单一值(value),从OLAP cube中抽取出一个分片的过程。下图表示了从原始OLAP cube中抽取出time = 2004分片的过程。
1.3.4 切块(Dice)
切块表示通过选择多个维度的某些值(或者区间),从OLAP cube中抽取出子cube的过程。下图表示了从原始OLAP cube中抽取某个维度中多值对应的子cube的过程。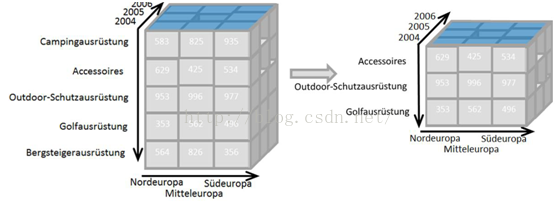
1.3.5 旋转(pivot)
旋转操作允许用户通过旋转(rotate)OLAP cube,重新选择目标分析维度,通常表现为交换坐标轴操作。在下图中,原始的OLAP cube的X轴是产品名称,Y轴是地区名称,Z轴是年份;经过旋转操作后cube表示了每个产品在不同年份、不同地区的统计情况。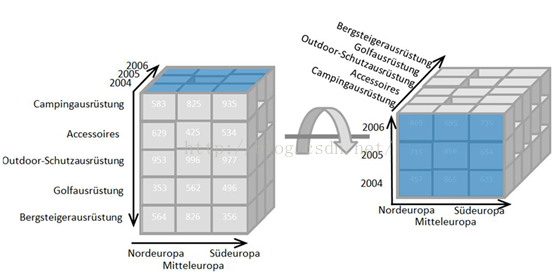
1.4 OLAP 与OLTP的区别

1.5 OLAP技术路线分类
常见的OLAP系统可以分为以下三类:关系型联机实时分析系统(Relational-OLAP,ROLAP),多维联机实时分析系统(Multidimensional-OLAP,MOLAP),混合型联机实时分析系统(Hybrid-OLAP,HOLAP)。
1.5.1 关系型联机实时分析(ROLAP)
ROLAP的核心依赖于关系型数据库,允许用户使用维度模型进行数据分析,将维度值存储在维度表中,将度量值存储在事实表中,通过关系型数据库访问数据,使用SQL进行查询分析。ROLAP的一般使用模式概括如下:根据用户的需求,对不同维度进行分析后,将分析数据导入到另一张数据库表中。
ROLAP的优势:
(1)处理高基数列具有更好的扩展性;
(2)擅长处理非聚合类的原始数据,生态圈内用于原始数据入库的ETL工具众多,同时比MOLAP入库速率更高;
(3)由于数据存储在关系型数据库中,所以支持标准SQL接口,查询便捷;
ROLAP的劣势:
(1)根据OLAP survey(http://www.olapreport.com/survey.htm)在2001-2006年连续6年的调研显示,工业界普遍认为ROLAP的性能要低于MOLAP。但也有人提出质疑,争议包含两方面:ROLAP的用户数是MOLAP的7倍多,那么抱怨产品性能差的比例自然更高;其他因素的影响,上述调研报告并没有将ROLAP产品和MOLAP产品放在同一个维度模型上进行比较,所以该报告结论并不具有权威性;
(2)处理已聚合的数据,需要使用定制的ETL工具,开发量大且不具有通用性;如果采用原始数据入库,将非常影响查询性能,如果想要提升查询性能,需要将已入库的原始数据重新聚合后再导入到新的表中进行查询分析;
(3)ROLAP的性能很大程度上依赖于使用的关系型数据库的查询与缓存性能;同时对于所有分析操作,都依赖于SQL语句,对于重计算类的分析模型,转换后的SQL就会变得复杂,对分析者的SQL语句的调优要求较高,而在某些无法使用SQL的场景下,ROLAP类产品则变得无能为力。
1.5.2 多维联机实时分析(MOLAP)
MOLAP是OLAP的经典使用模式,所以经常用MOLAP来指代OLAP。MOLAP和ROLAP具有一定的相似性,二者都可以使用维度模型进行数据分析,但是MOLAP并不将数据存储在维度表或者事实表中,而是对原始数据进行预计算(比如聚合操作),将计算结果存储在OLAP cube中。
MOLAP的优势:
(1)由于MOLAP不采用关系型数据库进行数据存储,所以必须采用特殊的存储手段,例如:压缩存储、索引(例如位图索引)以及缓存技术等,查询速率更快;
MOLAP的劣势:
(1)数据导入较慢,需要使用定制的ETL入库工具;
(2)由于没有维度表和事实表,所以对于更新操作以及明细查询,效率要比ROLAP低很多。
1.5.3 混合型联机实时分析(HOLAP)
HOLAP充分利用了ROLAP与MOLAP的各自优势,从纵向角度,既允许用户将部分数据(比如聚合类数据)使用MOLAP进行存储,从而获得更快的查询性能;又允许部分数据(比如原始数据)使用ROLAP进行存储,使用户能够查看细粒度数据。从横向角度,使用MOLAP存储最近较热的数据,从而提升查询性能;而使用ROLAP存储历史较冷的数据。
什么是OLAP
最近由于很多人问我什么是OLAP,从而发现目前OLAP对大多数人来说还是个新名词,这里我来简单讲讲OLAP(联机分析)。
联机分析(OLAP)是由关系数据库之父E.F.Codd于1993年提出的一种数据动态分析模型,它允许以一种称为多维数据集的多维结构访问来自商业数据源的经过聚合和组织整理的数据。以此为标准,OLAP作为单独的一类产品同联机事务处理(OLTP)得以明显区分。
有点深奥是不是?其实并不复杂,OLAP最基本的概念其实只有三个:多维观察、数据钻取、CUBE运算。
从动态的多维角度分析数据
我们在平时工作中,会遇到各种问题,在分析问题的时候,同样的现象,我们会从多个角度去分析考虑,并且有时候我们还会从几个角度综合起来进行分析。这就是OLAP分析最基本的概念:从多个观察角度的灵活组合来观察数据,从而发现数据内在规律。
OLAP将数据分为两种特征,一种为表现特征,比如一个销售分析模型中的销售额、毛利等;还有一种为角度特征,比如销售分析中的时间周期、产品类型、销售模式、销售区域等。前者是被观察的对象,OLAP术语称之为“度量数据”,后者为观察视角,OLAP术语称之为“维数据”。
如果建立这样一个模型,我们就可以根据业务需求,从产品类型角度去观察各个销售地区的销售额数据(以产品类型和销售地区为维、以销售额为度量);或者我们还可以从销售模式的角度去观察各个销售地区的销售额数据(以销售模式和销售地区为维、以销售额为度量)。
对数据进行钻取,以获得更为精确的信息
在分析过程中,我们可能需要在现有数据基础上,将数据进一步细化,以获得更为精确的认识。这就是OLAP中数据钻取的概念。
比如,在销售分析中,当我们以产品类型和销售地区为维、以销售额为度量进行分析的时候,可能希望进一步观察某类产品的不同销售模式在各个销售地区的表现,这时我们就可以在产品大类这个数据维下面,再加上一个销售模式维,从而获得相应的信息。
创建数据CUBE
那么,要满足上述运算,需要什么样的前提呢?
我们可以想像,和报表不同,OLAP分析所需的原始数据量是非常庞大的。一个分析模型,往往会涉及数百万条、数千万条、甚至更多;而分析模型中包含多个维数据,这些维又可以由浏览者作任意的提取组合。这样的结果就是大量的实时运算导致的时间延滞。我们可以设想,一个对于1000万条记录的分析模型,如果一次提取4个维度进行组合分析,那么实际的运算次数将达到4的1000次方的数量:这样的运算量将导致数十分钟乃至更长的等待时间。如果用户对维组合次序进行调整,或者增加减少某些维度的话,又将是一个重新的计算过程。
从上面分析,我们可以得出结论,如果不能解决OLAP运算效率问题的话,OLAP将是一个毫无实用价值的概念。那么,作为一个成熟产品是如何解决这个问题的呢?这就是OLAP中一个非常重要的技术:数据CUBE预运算。
一个OLAP模型中,度量数据和维数据我们应该实现确定,一旦两者确定下来,那么我们可以对数据进行预先的处理,在正式发布之前,将数据根据维进行最大限度的聚类运算,运算中会考虑到各种维组合情况,运算结果将生成一个数据CUBE,并保存在服务器上。这样,当最终用户在调阅这个分析模型的时候,就可以直接使用这个CUBE,在此基础上根据用户的维选择和维组合进行复运算,从而达到实时响应的这么一个效果。
补充说明
上面所说的,是OLAP最基本的概念,除此以外,OLAP通常包括的功能包括数据旋转(变换观察维组合顺序)、数据切片(过滤无关数据,对指定数据进行重点观察),以及对数据进行跨行列运算
https://www.2cto.com/database/201503/379650.html