RWTHLM(点击进行下载页面)的前4个文字指德国的亚琛工业大学,LM是语言模型。不同于我前面学习过的rnnlm, 这个开源工具提供了多种神经网络的结构,可以来构建语言模型。虽然本次主要目的是学习LSTM,但该开源工具又包含了rnn, feedforward的结构,索性的再学一遍吧。
这个开源工具是纯c++写的,很多用到了stl,以及boost库里面的东西,跟前面的rnnlm比起来,要高层得多。rnnlm很多东西基本功能全部是用c作者自己实现的,在rwthlm里面,可以看到很多东西都是用的stl的。这系列的文章我不打算像前面rnnlm那样把所有源码都注释放上来了,给出核心的代码的记录,以及自己的一些想法。自己的理解可能有很多不对的地方,欢迎看到的朋友指出~
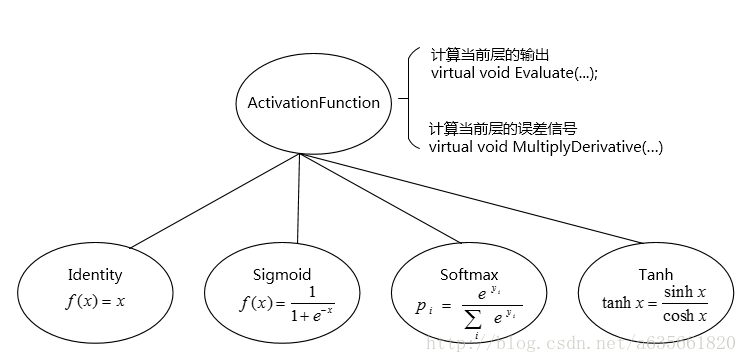
先从激活函数的类开始吧,rwthlm提供了4种激活函数类,如下:
- Identity 对应的实现与定义文件在identity.h, identity.cc
- Sigmoid 对应的实现与定义文件在sigmoid.h, sigmoid.cc
- Softmax 对应的实现与定义文件在softmax.h, softmax.cc
- Tanh 对应的实现与定义文件在tanh.h, tanh.cc
这4个类都继承于ActivationFunction类,关系可以用下图描述:
先看一下sigmoid激活函数的实现, dimension的含义是该层的大小,batch_size的含义是多少个sentence(详细见后面的文章),b_t表示当前层的输入
void Sigmoid::Evaluate(const int dimension, const int batch_size,
Real b_t[]) const {
//这里将for循环并行化处理
#pragma omp parallel for
for (int i = 0; i < batch_size; ++i) {
std::transform(b_t + i * dimension,
b_t + (i + 1) * dimension,
b_t + i * dimension,
[](const Real x){ if (x > 0) {
return 1. / (1. + exp(-x));
} else {
const Real expx = exp(x);
return expx / (expx + 1.);
} });
}
}
//上面等同于下面的代码:
/*
for (int i = 0; i < batch_size; ++i) {
for (int j=0; j<dimension; j++) {
Real *tmp_t = b_t + i * dimension;
if (tmp_t[j] > 0) {
tmp_t[j] = 1. / (1. + exp(-tmp_t[j]));
}
esle {
tmp_t[j] = exp(tmp_t[j]) / (1. + exp(tmp_t[j]));
}
}
}
*/
在sigmoid.cc文件里面,sigmoid函数实现有点奇怪, 如果用数学等式描述,是如下的:
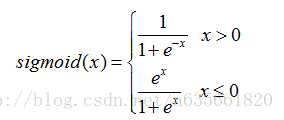
这两者其实是相等的,
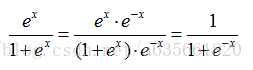
从上面可以看到,两者是相等的,我猜测是当x为负数时,计算exp(x)时会更快吧,不知道这里理解正确与否。另一个函数的实现如下,dimension,batch_size含义和上面相同,b_t[]表示当前层输出,delta_t表示流向当前层的误差,该函数计算当前层的误差信号,并且存放在delta_t
void Sigmoid::MultiplyDerivative(const int dimension, const int batch_size,
const Real b_t[], Real delta_t[]) const {
const int size = dimension * batch_size;
std::transform(b_t,
b_t + dimension * batch_size,
delta_t,
delta_t,
[](const Real x, const Real y) { return x * (1. - x) * y; });
}
//上面的transform这段等价于下面:
/*
int len = batch_size*dimension;
for (int i = 0; i < len; ++i) {
delta_t[i] *= b_t[i] * (1. - b_t[i]);
}
*/
其余的实现比如identity, tanh都是类似的。注意identity所指代的激活函数其实就是f(x) = x,另外在softmax的实现里面并不是按照常规那样实现的,会减去一个最大值,目的是防止溢出,代码及注释如下:
void Softmax::Evaluate(const int dimension, const int batch_size,
Real b_t[]) const {
#pragma omp parallel for
//这里softmax归一化,是先将里面最大的数减去
//这么做可以防止exp(x)中的x过大,导致溢出
for (int i = 0; i < batch_size; ++i) {
//FastMax函数在fast.h里面,找出最大的数
const Real max = FastMax(b_t + i * dimension, dimension);
//减去那个最大的数,原因是防止溢出
FastSubtractConstant(b_t + i * dimension,
dimension,
max,
b_t + i * dimension);
//求exp()
FastExponential(b_t + i * dimension, dimension, b_t + i * dimension);
//求和
const Real z = FastComputeSum(b_t + i * dimension, dimension);
//归一化后的结果,作为后验概率
FastDivideByConstant(b_t + i * dimension,
dimension,
z,
b_t + i * dimension);
}
}
上面是4个激活函数是程序比较频繁的用到的。下面看一下vocabulary是如何组织的,现在为了清楚的了解voc的组织情况,我们简化一下语料文件内容如下:
You do good .
No worry about that .
由于rwthlm可以指定单词的分类文件,我们假设上面语料中的单词分类如下,下面的内容是单独存放在一个文件的,第一列是word,第二列是类别号,两个word类别同号表示它们属于一类。当然分类的目的是为了加速计算。
You 1
that 1
No 1
do 2
worry 2
good 3
. 3
about 程序得到的最开始结果就是建立两个容器来装这些词语和分类结果,注意程序会自动添加一个句子的边界符号<sb>进入词库,结果如下:
注:容器index_by_word_是左边的图,class_by_index_map是右边的图
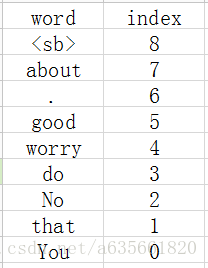
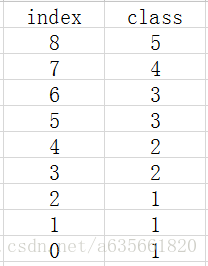
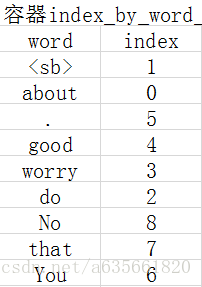
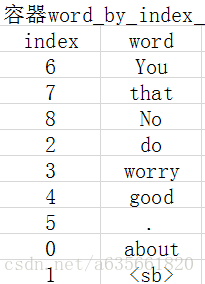
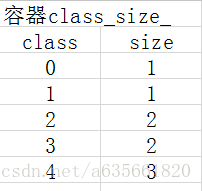
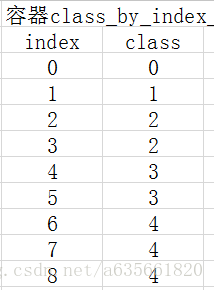
这部分是在vocabulary.cc, vocabulary.cc.h里面完成的,实现代码的注释如下:
class Vocabulary;
//下面两个typedef的是智能指针,作用有如同指针,但会记录有多少个shared_ptrs共同指向一个对象。
//这便是所谓的引用计数(reference counting)。
//一旦最后一个这样的指针被销毁,也就是一旦某个对象的引用计数变为0,这个对象会被自动删除
typedef std::shared_ptr<Vocabulary> VocabularyPointer;
typedef std::shared_ptr<const Vocabulary> ConstVocabularyPointer;
class Vocabulary {
public:
//vocab_file是vocabulary file的文件名
//该文件里面可以给定word,每行一个,或者加上类别,格式:word<TAB>class_number
//unk如果命令行中没指定--unk,则unk为空字串,否则为指定的字符串用来指定unknown token
//sb表示 the sentence boundary token,默认是<sb>
//--train所指定的文件名即train_file,unk,sb和上面一样
//这个函数的功能就是从给定的vocabulary file创建词库,并分类
//返回一个指向Vocabulary的智能指针 得到的一个结果就是把成员变量填充好了,如上图
static ConstVocabularyPointer ConstructFromVocabFile(
const std::string &vocab_file,
const std::string &unk,
const std::string &sb);
//这个函数的功能就是从给定的train file创建词库,并分类
//返回一个指向Vocabulary的智能指针 得到的一个结果就是把成员变量填充好了
static ConstVocabularyPointer ConstructFromTrainFile(
const std::string &train_file,
const std::string &unk,
const std::string &sb);
void Save(const std::string &file_name) const;
//查找word是否在index_by_word_里面
bool Contains(const std::string &word) const {
//用find函数来定位数据出现位置,它返回的一个迭代器,当数据出现时,它返回数据所在位置的迭代器
//如果map中没有要查找的数据,它返回的迭代器等于end函数返回的迭代器,程序说明
return index_by_word_.find(word) != index_by_word_.end();
}
//计算没有word的类别的数量
int ComputeShortlistSize() const {
int result = 0;
for (int size : class_size_) {
if (size > 1)
break;
++result;
}
return result;
}
//查找word的index,若word是oov,那么返回定义的unk的index
int GetIndex(const std::string &word) const {
const StringToInt::const_iterator it = index_by_word_.find(word);
if (it == index_by_word_.end()) {
assert(unk_ != "");
return index_by_word_.find(unk_)->second;
}
return it->second;
}
//根据index,返回word
std::string GetWord(const int index) const {
const IntToString::const_iterator it = word_by_index_.find(index);
assert (it != word_by_index_.end());
return it->second;
}
//根据index,返回word的类别
int GetClass(const int index) const {
assert(index >= 0 && index < GetVocabularySize());
return class_by_index_[index];
}
//返回类别clazz的所包含的word数
int GetClassSize(const int clazz) const {
return class_size_[clazz];
}
//获得类别中包含最多的word的数目
int GetMaxClassSize() const {
return *std::max_element(class_size_.begin(), class_size_.end());
}
// includes <sb> and <unk>
//返回所有word的数量
int GetVocabularySize() const {
return index_by_word_.size();
}
//返回class的数量
int GetNumClasses() const {
return class_size_.size();
}
//index_by_word_中是否存在unk
bool HasUnk() const {
const StringToInt::const_iterator it = index_by_word_.find(unk());
return it != index_by_word_.end();
}
//判断是否是句子的结束
bool IsSentenceBoundary(const std::string &word) const {
return word == sb_;
}
int sb_index() const {
return sb_index_;
}
std::string sb() const {
return sb_;
}
std::string unk() const {
return unk_;
}
private:
typedef std::unordered_map<std::string, int> StringToInt;
typedef std::unordered_map<int, std::string> IntToString;
typedef std::unordered_map<int, int> IntToInt;
//这是构造函数,初始化unk_, sb_
Vocabulary(const std::string &unk, const std::string &sb) :
unk_(unk), sb_(sb) {
};
//这个函数用来重新分类,但实际上和用户指定的vocabulary file分类其实是等价的
static void Remap(const IntToInt &class_by_index, VocabularyPointer v);
// vocabulary has to contain </sb> and may contain <unk>
const std::string unk_, sb_;
int sb_index_;
//各个成员变量含义如上图
StringToInt index_by_word_;
IntToString word_by_index_;
std::vector<int> class_by_index_;
std::vector<int> class_size_;
};