本文讲解涉及到的核心思想:
机器学习与深度学习:
1:线性回归问题。
2:优化搜索时,步长选取的重要性。
3:为什么神经网络可以拟合任意的曲线函数。
4:图像识别网络中,为什么浅层网络只能识别出一些简单的线,面,随着网络的加深可以识别出十分复杂的图案。
1:线性回归问题:
(1)问题描述
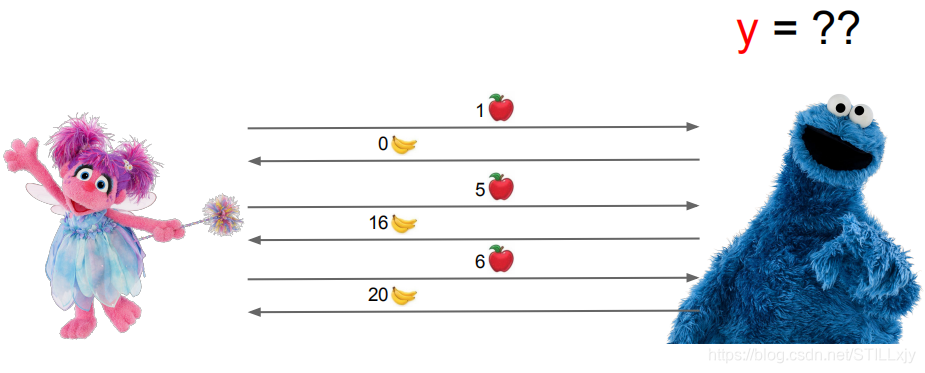
如上图所示,小红(左)和小蓝(右)在进行一个水果交换的游戏。
目前已经进行了三次交换:
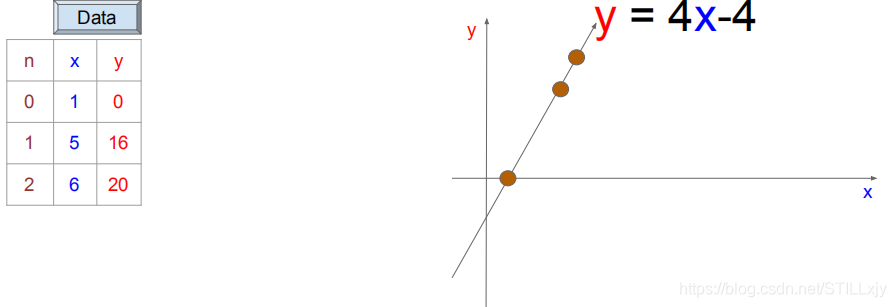
第一次:小红给小蓝1个苹果,小蓝因此给了小红0个香蕉
第二次:小红给小蓝5个苹果,小蓝因此给了小红16个香蕉
第三次:小红给小蓝6个苹果,小蓝因此给了小红20个香蕉
问题:现在小红想知道,将来小红给小蓝 x 个苹果,小蓝会因此给小红的香蕉数 y 的值是多少?
(2)问题建模:

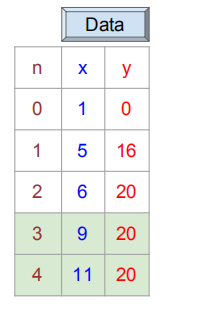
我们可以将上述问题按照上图所示进行建模,假设我们是使用一个线性函数y=wx+b来描述上述问题。将已知数据进行表格化:

我们现在的问题就是如何找到合适的w,b可以很好的解决我们的问题。
首先,我们观察两种w,b取值的情况,y^为根据w,b的取值,函数所得到的结果:
w=1, b=0时:

w=2, b=2时:
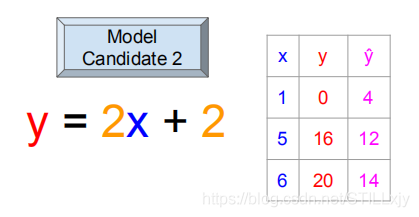
那么,到底哪一个w,b的取值比较好呢?那我们就需要引入代价函数C(w,b)了。

我们让代价函数C为真实值y与模型得到的值y^的差值平方和,于是我们知道,代价函数C值越小,表示模型得出的结果越好。我们可以根据代价函数C的值来评判两个预测函数的好坏。
由此可知,w=2, b=2时 比 w=1, b=0时更好。
那么我们如何才能找到更好的w,b使得代价函数值更小(最小)呢?
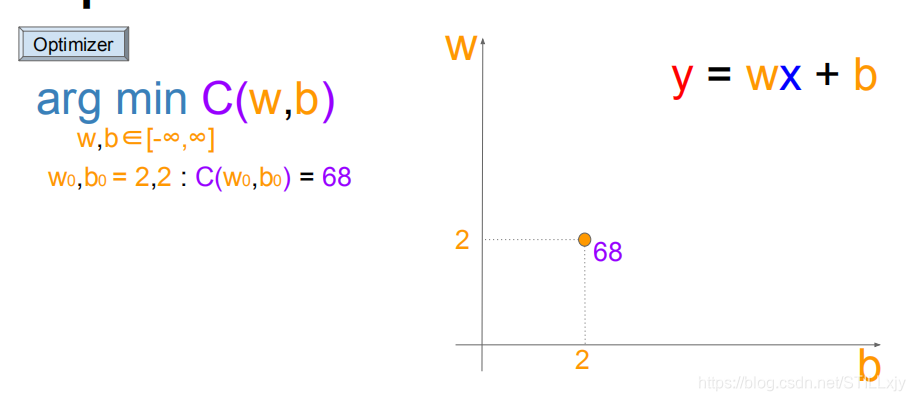
我们的目标就是搜索不同的w,b来最小化代价函数C

一种搜索的方案是:按照长度为1的大小,在w-b坐标系下进行上下左右的搜索:
起始位置:(w=2,b=2)
向上搜索到(w=3,b=2),由于代价函数值更小了,所以可以更新w,b的值
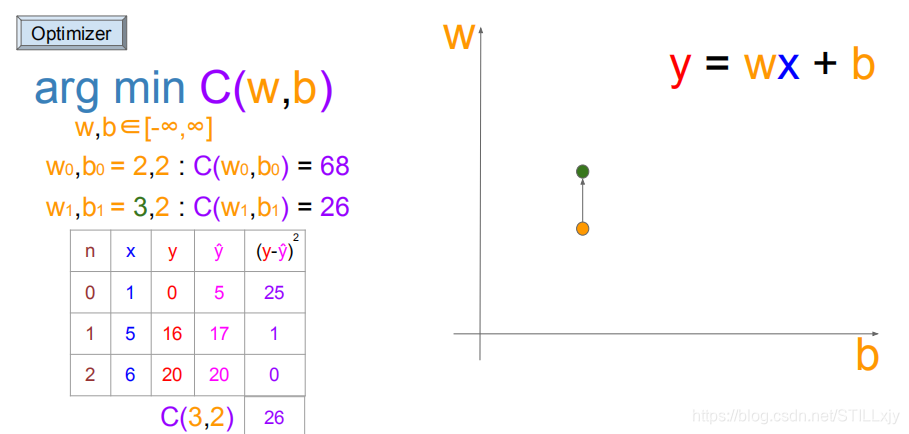
(w=3,b=2):继续向上搜索(w=4,b=2),由于代价函数值没有变小,则不更新
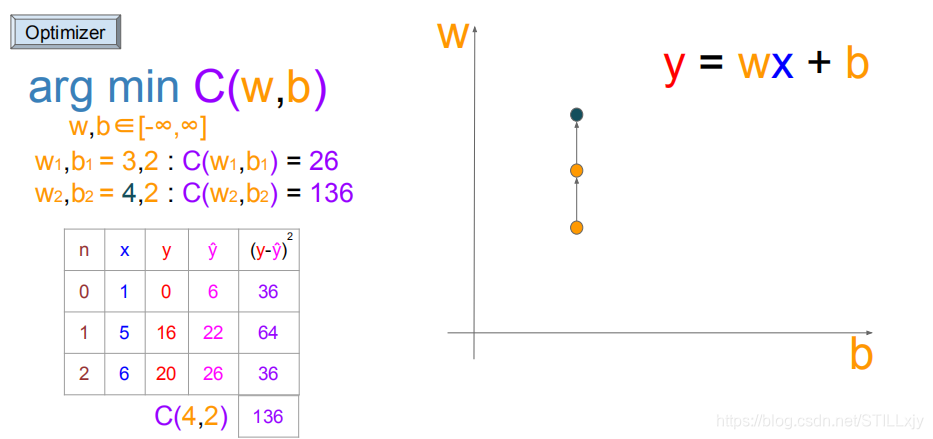
(w=3,b=2):继续向右搜索(w=3,b=3),由于代价函数值没有变小,则不更新
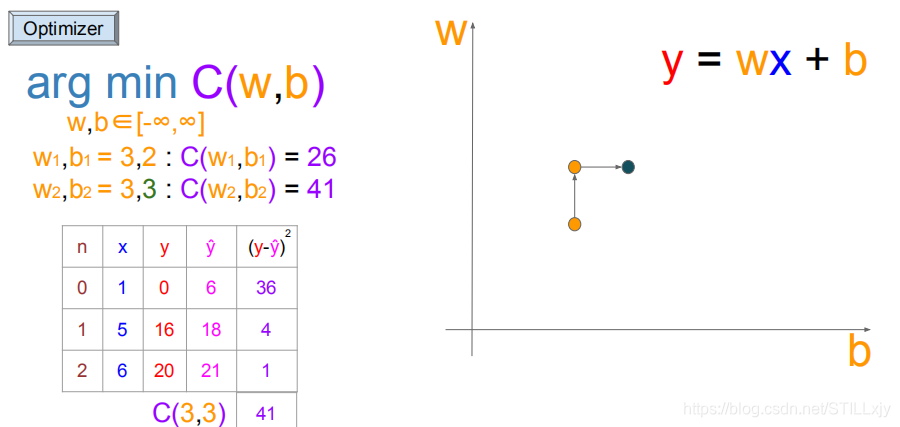
(w=3,b=2):继续向左搜索(w=3,b=1),由于代价函数值变小,更新w,b
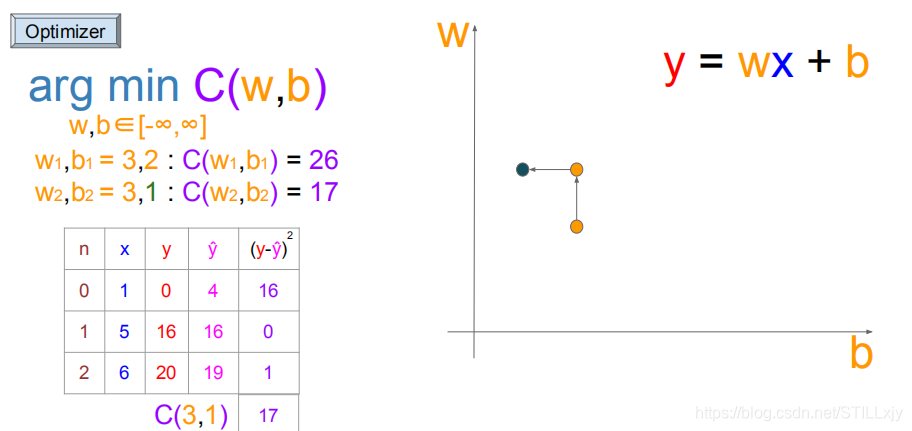
(w=3,b=1):继续向左搜索(w=3,b=0),代价函数变小,更新w,b
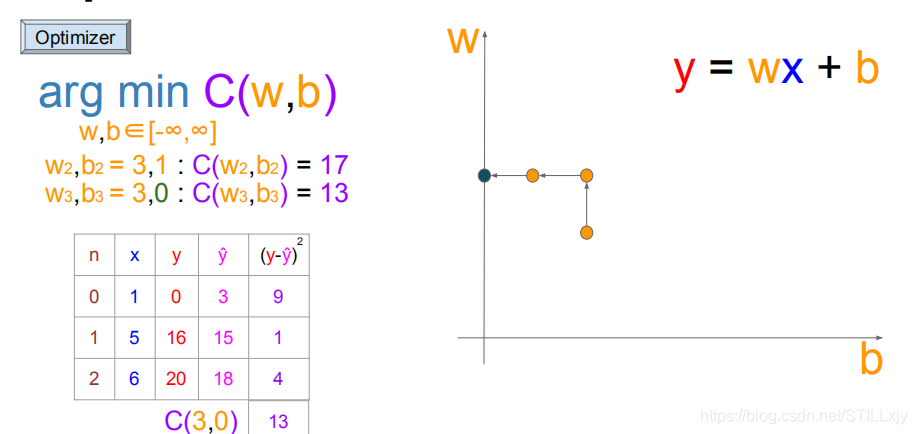
(w=3,b=0):继续搜索,在此处向上下左右四个方向搜索到无法使得代价函数值C变小,所以以长度为1的搜索方式结束了,找到了当前可以取到的最优w=3,b=0值。
对于上述问题,w=3,b=0就是最好的结果了吗?其实并不是,(w=4,b=-2)才是最优解。
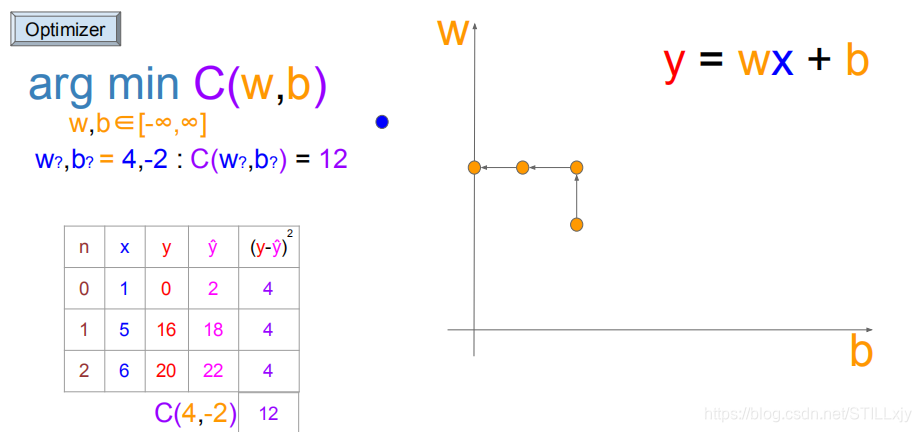
那为什么我们没有找到这个最优解呢?
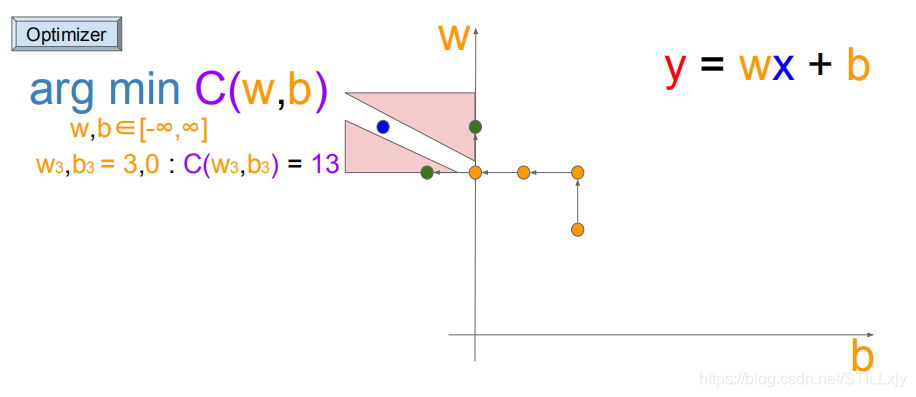
如上图所示,当(w=3,b=0)时,粉色三角形代表代价函数值C上升的区域,2个三角形之间的白色通道才是可以使得代价函数值C降低的区域。
由于我们的搜索长度为1,所以我们无法进入到白色通道中,当我们减小搜索长度时,我们就可以得到更好的优化结果了。
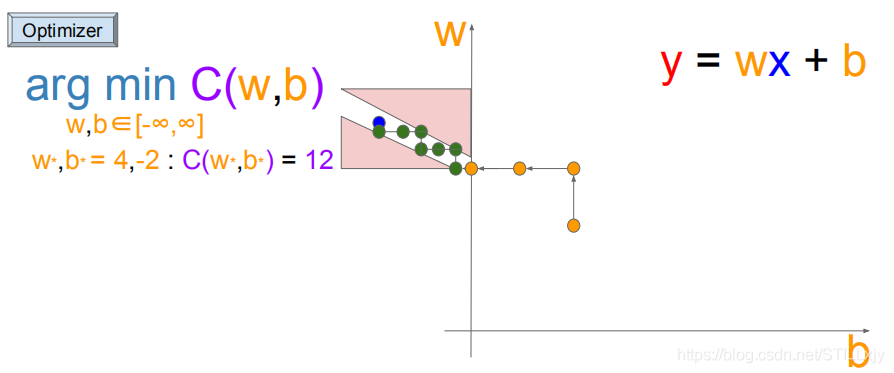
这就是机器学习进行梯度下降搜索时,更新步长选择的重要性
现在我们将问题进行进一步的复杂化:
小红和小蓝又进行了2次水果交换:
第四次:小红给小蓝9个苹果,小蓝因此给了小红20个香蕉
第五次:小红给小蓝11个苹果,小蓝因此给了小红20个香蕉
那么我们继续使用线性函数模型进行问题的求解优化,我们得到的最优解为:
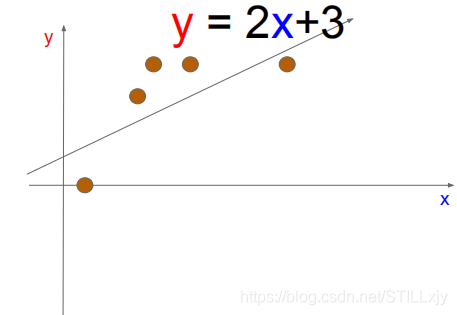
我们可以很容易的看出,随着问题的复杂化,线性函数模型已经无法较好的解决我们的问题了。真正我们想要的结果函数图像如下所示:
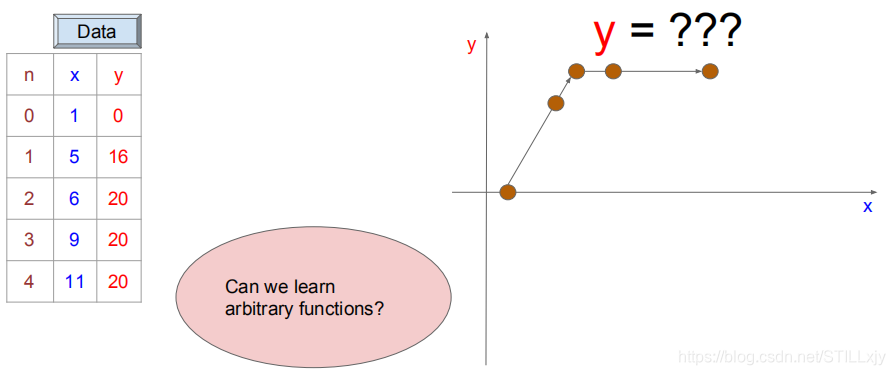
我们发现,该曲线可以被分为两个线性函数区域,所以我们可以使用两个线性函数的组合来表示,于是我们将函数模型变成如下模式:
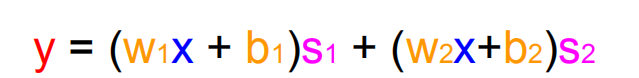
(w1,b1)用来表示上述斜线,(w2,b2)用来表示横线
所以我们只需s1,s2满足:
当x<=6时,s1=1,s2=0
当x>6时,s1=0,s2=1
只需满足上述条件,下面的函数就可以很好的解决我们的问题

那我们如何可以使得s1,s2满足上述条件呢?接下来我们提出非线性函数
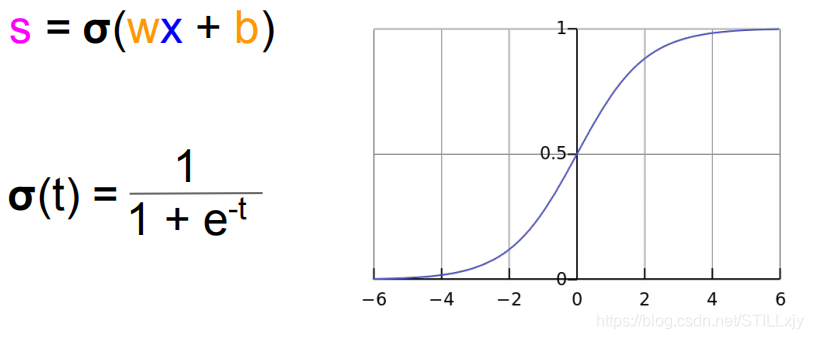
通过增加w可以使上述函数进行压缩,改变b的大小,可以将上述函数进行平移经过搜索我们可以得到下述函数,来解决我们的问题。
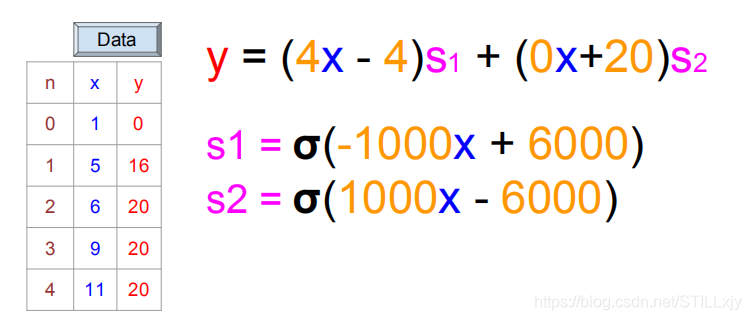
于是,通过增加线性函数的个数(神经元的个数)我们可以解决更加复杂的问题。
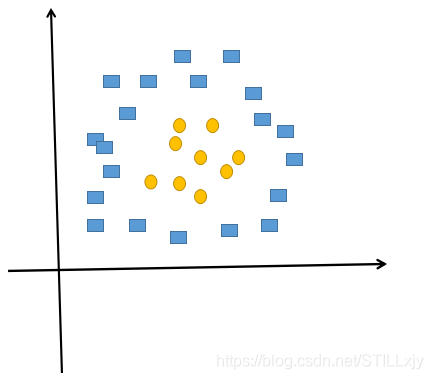
思考: 对于下面这个二分类问题,至少使用多少个神经元,可以较好的将矩形和圆形分开?
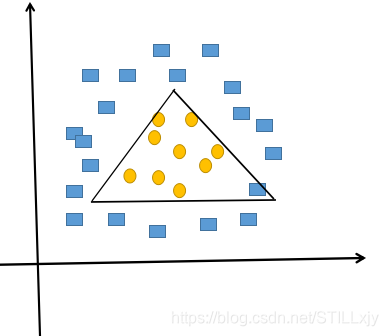
解答分析:
如下图所示,我们至少需要使用3条直线才能将矩形和圆形较好的分开,所以我们至少使用3个神经元。
现在,通过数据的添加(5和6),我们的问题又进一步复杂化了,如下所示:
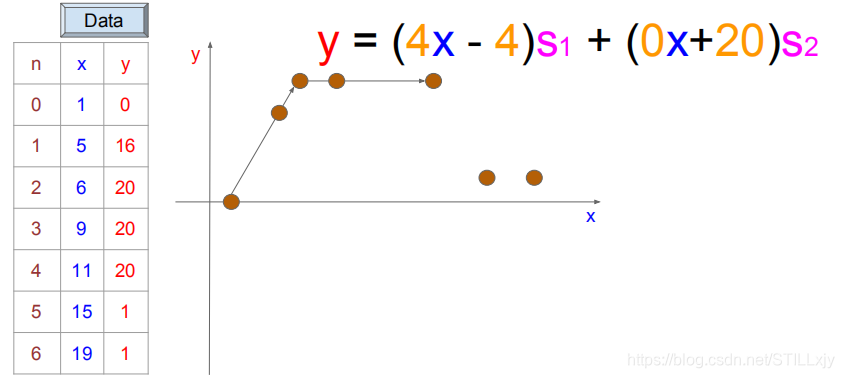
由之前的处理可知,我们可以使用下面这个模型进行问题的处理:
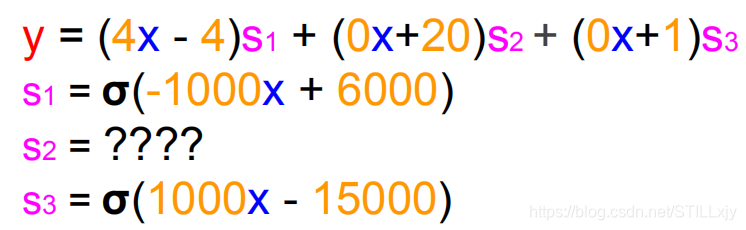
那么s2将如何表示呢?经过分析我们可以知道,当s1=0,s3=0时,s2=1就满足了我们的问题。即s2 = not s1 and not s3

函数模型如下所示:就是一个2层的神经网络
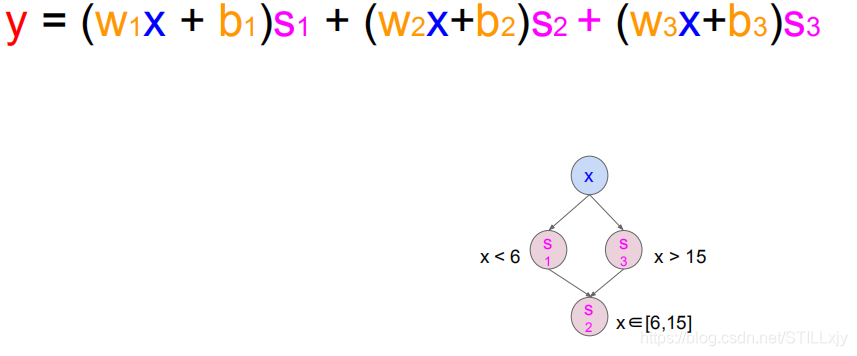
由此我们可以知道,对于复杂性不同的问题,我们可以通过改变(增加或减少)神经网络的神经元个数和网络的层数,来处理不同的问题。
总结:
1:优化搜索时,步长选取的重要性
由上述对最初问题的优化过程,我们可以知道,当更新步长较长时,我们可以很快的得到一个较好的结果,但是对于问题的最优解,可能由于步长过长而无法到达。通过缩小步长,我们可以得到更加优秀的解。
2:为什么说神经网络可以拟合任意的曲线函数。
如下某一复杂曲线而言,按照上述的解决方案,我们只需将该复杂的曲线,有限次的划分,然后分别使用线性函数来拟合不同的区域的弧线即可。
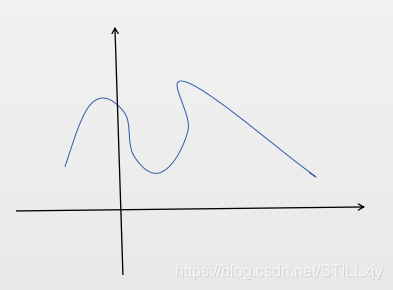
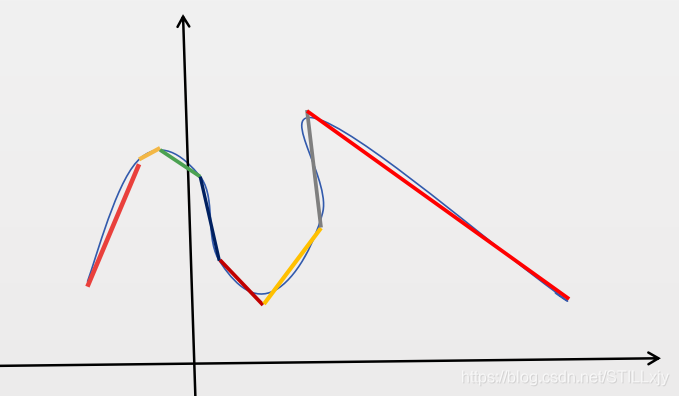
3:图像识别网络中,为什么浅层网络只能识别出一些简单的线,面,随着网络的加深可以识别出十分复杂的图案。
由2可知,浅层线性函数可以使用直线来拟合任意的曲线,所以在浅层网络中,主要是使用一些直线来对目标进行描述。随着网络层次的加深,会将折现变得更加光滑和复杂,因此可以用来对更加复杂的图形进行描述。