一.初识HBase
HBase其实就是Hadoop的database,它是一种分布式的,面向列的开源数据库,类似 Google Bigtable 利用 GFS 作为其文件存储系统,HBase 利用 Hadoop HDFS 作为其文件存储系统;Google 运行 MapReduce 来处理 Bigtable 中的海量数据,HBase 同样利用 Hadoop MapReduce 来处理 HBase 中的海量数据;Google Bigtable 利用 Chubby 作为协同服务,HBase 利用 Zookeeper 作为对应。,目前是Apache的顶级项目,它不同于一般的关系型数据库,适合存储半结构化的数据。
Hbase一般具有以下特点:
(1)线性扩展:当存储空间不足时,可以通过简单的增加节点的方式进行扩展——通过增加 RegionServer 进行扩展,而且只需要将它可以放到普通的服务器中即可。
(2)面向列:与关系型数据库——诸如Mysql不同的是,HBase面向列族来存储数据,即同一个列族里的数据在逻辑上存储在同一个文件中。
(3)大表:百万级甚至亿级的行和列。
(4)稀疏:列可以动态增加,由于数据的多样性,整体上会有非常多的列,但每一行数据可能只对应少数的列,一般情况下,一行数据中,只有少数的列有值,HBase并不存储,因此表可以设计地非常稀疏。
(5)面向海量数据:Hbase适合处理大数量级的数据。
(6)高读写场景:HBase适合批量大数据高速写入数据库。
二.HBase表视图
1.概念视图
一般关系型数据:列的属性在使用前定义好,而行可以动态扩展。
HBase:列族必须在使用前定义好,列,时间戳和行都能动态扩展。

Table(表):HBase table由多个row组成。
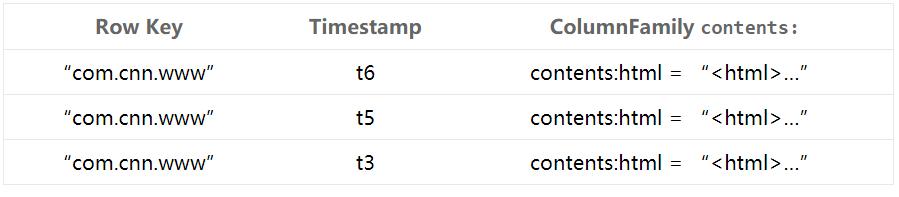
Row(行):每一row代表着一个数据对象,每一row都是以一个rowkey(行键)和一个或者多个column组成。rowkey是每个数据对象的唯一标识的,按字母顺序排序,即row也是按照这个顺序来进行存储的。所以,rowkey的设计相当重要(rowkey设计学问之深我都感觉可以专门搞一个学科来研究了),一个重要的原则是,相关的row要存储在接近的位置。比如网站的域名,rowkey就是域名,在设计时要将域名反转(例如org.apache.www、org.apache.mail、org.apache.jira),这样的话,Apache相关的域名在table中存储的位置就会非常接近的。
Column(列):column由column family和column qualifier组成,由冒号(:)进行进行间隔。比如family:qualifier。
Column Family(列族):在 HBase,column family是一些column的集合。一个column family所有column成员是有着相同的前缀。比如,courses:history和courses:math都是courses的成员。冒号(:)是column family的分隔符,用来区分前缀和列名。column前缀必须是可打印的字符,剩下的部分列名可以是任意字节数组。column family必须在table建立的时候声明。column随时可以新建。在逻辑上,一个的column family成员在文件系统上都是存储在一起。因为存储优化都是针对column family级别的,这就意味着,一个column family的所有成员的是用相同的方式访问的。
Column Qualifier(列限定符):column family中的数据通过column qualifier来进行映射。column qualifier也没有特定的数据类型,以二进制字节来存储。比如某个column family “content”,其 column qualifier可以设置为"content:html" 和 "content:pdf"。虽然column family是在table创建时就固定了,但column qualifier是可变的,可能在不同的row之间有很大不同。
Cell(单元格):cell是row、column family和column qualifier的组合,包含了一个值和一个timestamp,用于标识值的版本。
Timestamp(时间戳):每个值都会有一个timestamp,作为该值特定版本的标识符。默认情况下,timestamp代表了当数据被写入RegionServer的时间,但你也可以在把数据放到cell时指定不同的timestamp。
2.物理视图

三.HBase物理存储模型
HBase的底层实现如下图所示:

它由相关服务和文件组成 ,HBase主要有两种文件——WAL和Hfile,由于它们均以HDFS作为底层实现,在实际的存储中,会划分成更小的文件块——因此,我们无从得知,也没有那个精力及必要去思考某张表具体存储在哪些datanode中。
1.Client
客户端用于提交管理或读写请求,采用RPC与HMaster和HRegionserver进行通信。它还会缓存查询信息,这样如果随后有相似的请求,可以直接通过缓存定位,而不用再次查找meta表。
2.Zookeeper
为HBase提供协同管理服务,当HRegionserver上线时会将自己注册到Zookeeper中——起到监控的作用,当某个HRegionserver死掉时,能及时通知HMaster进行处理。Zookeeper提供目录表的位置——hbase:meta,此表同样按照rowkey排序——我们在找到一个rowkey时,就能找到相邻的rowkey,篇幅有限,这里就不详细介绍hbase:meta表结构了。
3.HMaster
在实际的集群中,该进程多运行在namenode中 ,它负责监控HRegionserver:
(1)操作表
(2)分配新的Region
(3)HRegionserver挂掉之后重新为Region分配HRegionserver(不一定是在原HRegionserver)
HBase同样可以实现多HMaster,但同一时刻只能有一个HMaster处于活跃状态——当某个HMaster突然暴毙或者租期到了(当该HMaster被激活时,Zookeeper会给它一个租期)之时,就会启动另一个HMaster。
4.HRegionserver
它负责参与具体的Region的管理,直接响应客户端的读写请求,HRegionserver运行在datanode,一般来说一个datanode运行一个HRegionserver。
5.HRegion
HRegion是对表进行划分的基本单元,一个表在创建的时候只有一个Region,但随着记录地增加会越来越大,到达某个阈值之后会被Split——按行健进行划分——每个Region包含表的所有列族——某一行的数据完全可以在某个Region中全部获取——但是默认的切分常常会产生数据倾斜,实际开发中采用预分区的方式。Split之后,HMaster会重新分配HRegionserver,然后更新Hbase:meta表。
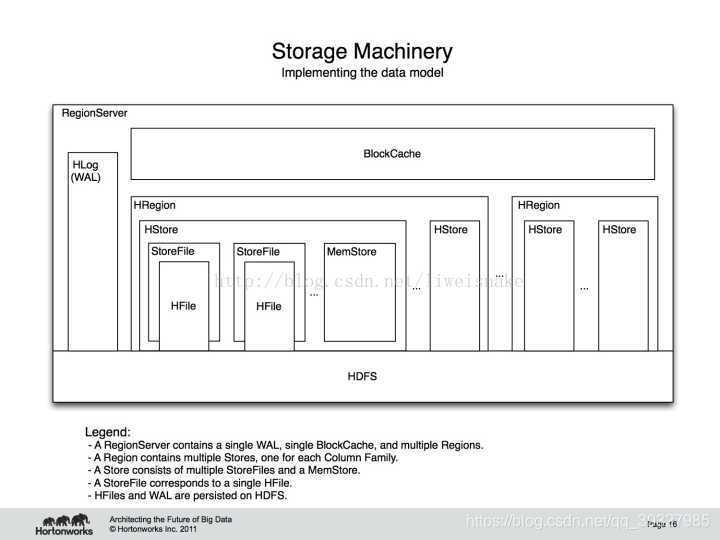
(1)HStore
每一个HRegion包含若干Stores,每个Store对应一个HBase表中的列族——面向列族进行存储这一说法就是来源于此,一个表足够大时,会被划分成若干Split,每个Split对应一个Region。
关于Region的切分细节如下:
在HBase0.94版本~2.0版本IncreasingToUpperBoundRegionSplitPolicy 是默认的split策略,这个策略中,最小的分裂大小和table的某个region server的region 个数有关,当store file的大小大于如下公式得出的值的时候就会split,公式如下:
Min (R^2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”) R为同一个table中在同一个region server中region的个数。

hbase.hregion.memstore.flush.size 
hbase.hregion.max.filesize hbase.hregion.memstore.flush.size 默认值 128MB。
hbase.hregion.max.filesize默认值为10GB 。
如果初始时R=1,那么Min(128MB,10GB)=128MB,也就是说在第一个flush的时候就会触发分裂操作。
当R=2的时候Min(2*2*128MB,10GB)=512MB ,当某个store file大小达到512MB的时候,就会触发分裂。
如此类推,当R=9的时候,store file 达到10GB的时候就会分裂,也就是说当R>=9的时候,store file 达到10GB的时候就会分裂。
Store的存储过程是HBase存储的核心过程,每个Store包含一个MemStore(内存中的缓存)和若干StoreFiles(磁盘上的文件HFile)。当在HBae中插入数据时,会先存到MemStore中;查询数据时也会先从MemStore查看,找不到时再到HFile中查找,若在HFile中找到了结果,会将结果缓存到MemStore中,当MemStore中的数据到达阈值时,会执行Flush操作,将MemStore写成一个单独的StoreFile,当StoreFile到达一定个数时,会触发Compact操作——合并为一个大的StoreFile。
(2)合并
StoreFile的合并有两种方式,分别是minor和major。minor时把最新生成的几个StoreFile进行合并,每次进行Flush操作之后,都会触发合并,或者由单独的进程定期触发合并检查。minor合并的文件由以下四个参数决定:
hbase.hstore.compaction.min 最小文件合并数 必须大于1 默认是3
hbase.hstore.compaction.max 最大文件合并数 默认是10
hbase.hstore.compaction.min.size 最小合并文件大小 设置为Flush的阈值
hbase.hstore.compaction.max.size 最大合并文件大小

hbase.hstore.compaction.max
合并检查时,会查看当前的StoreFile是否符合条件。最小合并文件数不要设置的太大,这样不仅会延迟minor合并操作,还会增加每次合并时的资源消耗和执行时间。最小合并文件大小设置为MenStore Flush的阈值,这样每个新生成的StoreFile都符合条件,因为设置了最大合并文件的大小,当合并后的文件大于这个大小时,那么再执行合并检查就会被排除在外,这样设计的好处是,每次进行minor合并的文件都是比较新和比较小的文件。
major合并是把所有的StoreFile合并成一个单独的StoreFile,进行合并检查时会事先检查从上次执行major合并到现在是否达到hbase.hregion.majorcompaction制定的阈值(我看的那本书上是24h,但我查的官网7天),若达到这个时间,则进行major合并操作。

hbase.hregion.majorcompaction
除了由Flush之后和线程定期地触发合并检查之外,还可以有相应的shell命令(compact,major_compact)和API(majorCompact())触发。
Flush触发条件:
1.Regionserver全局的memstore大小,超过该大小会触发Flush,默认为heap的40%。

hbase.regionserver.global.memstore.size 2.内存中的文件在自动刷新之前能够存活的最长时间,默认为1h。

hbase.regionserver.optionalcacheflushinterval 3.单个Region里的menstore的缓存大小,默认为128M
hbase.hregion.memstore.flush.size
(3)修改和删除记录
HBase中修改和删除操作均是以追加的形式执行的,并不会立即定位到该文件进行相应操作。修改和删除操作均是添加一行新的纪录,修改操作就是添加一行新版本地数据,删除则是在所添加的记录上打上了删除标记,表示要删除某条记录,这些操作均会先存入MemStore,Flush侯成为StoreFile,在StoreFile合并时,同时对数据版本进行合并,舍弃多余的数据版本和具有删除标记的记录。
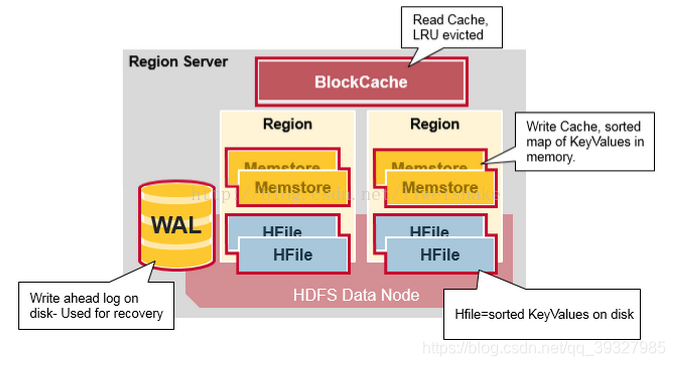
6.WAL
WAL是HBase的预写日志文件——对应于磁盘中实际存储为HLogFile,记录用户对数据的所有操作,存储在/hbase/WALs目录中,它的存在是为了防止HRegionserver突然死掉之后MenStore中数据出现丢失——用户在写入操作时,记录会由RegionServer先行写入WAL中,由图可以看出,某个RegionSever中的WAL被该RegionSever中所有的Region共享,对比同时写入多个文件而言,减少了机械硬盘的寻址次数,加快了数据的处理素速度,但这样看来也有一个不可忽视的缺点——当恢复数据时,需要为WAL中"乱成一团"的记录"找到自己的家"(即我这条记录作用于哪条Region)——因此,每一行记录在写入之前都应该附带自己的"家庭地址",不然我咋知道你住哪儿。HLogFile每个存储单元均包含两部分——HLogKey和KeyValue,HLogKey中记录了写入数据所隶属的表(Table)以及Region写入时间(TimeStamp)及序列编号;KeyValue则对应StoreFile的物理内存HFile中的KeyValue元数据。
四.HBase读写流程
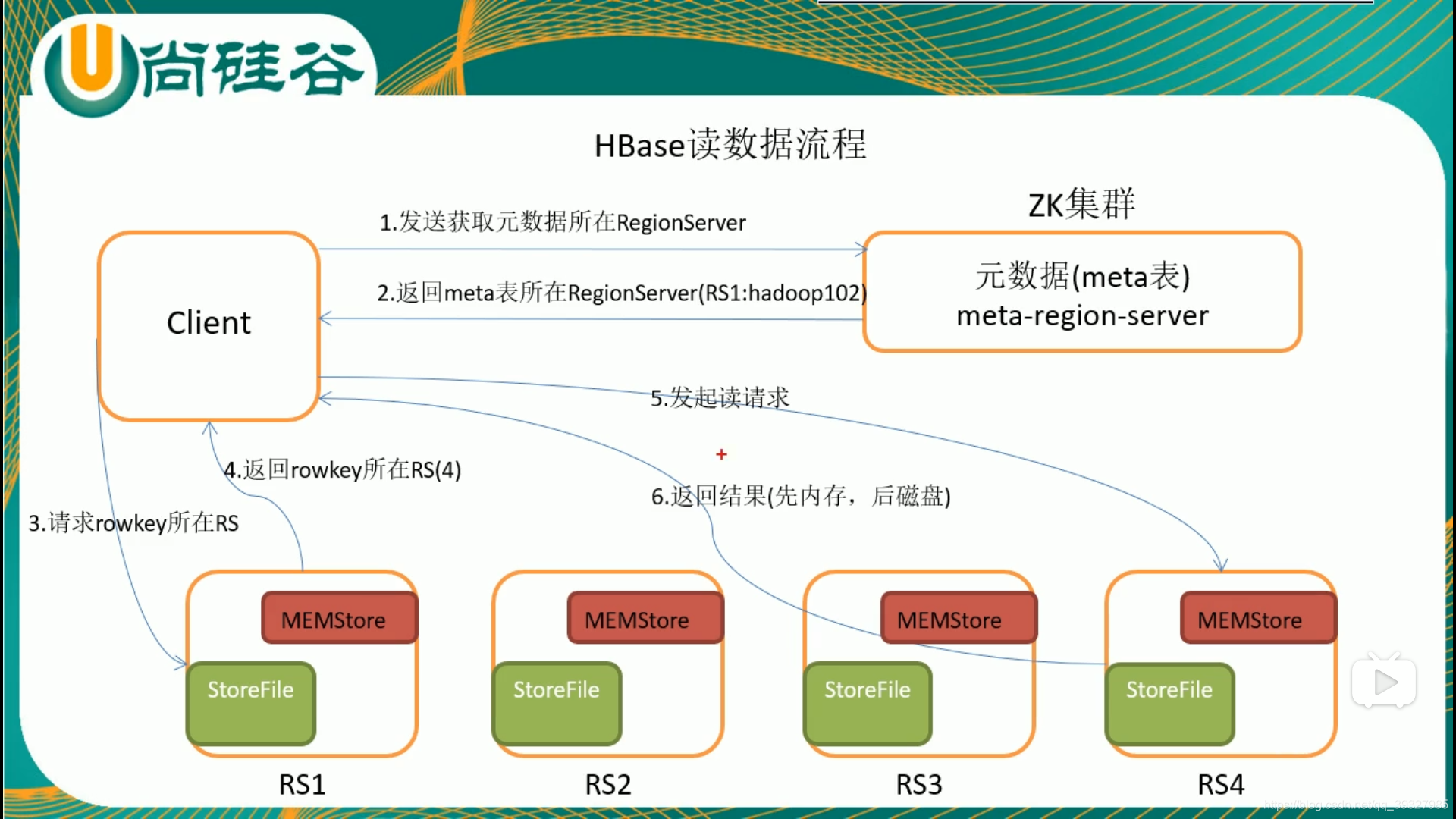
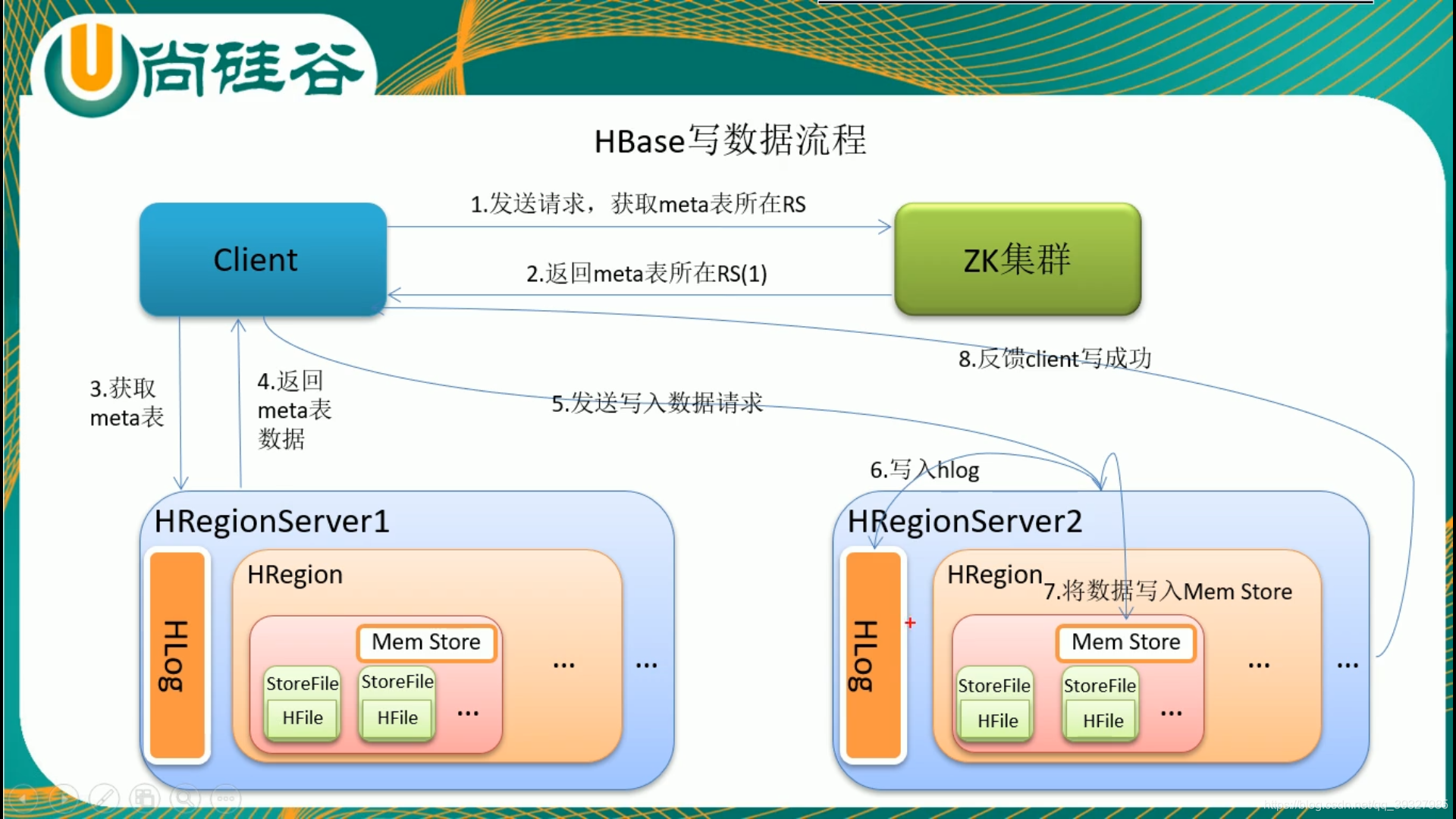
由于memstore的存在,HBase的写会比读快。
参考:《Hadoop大数据 处理技术基础与实践》
https://blog.csdn.net/liweisnake/article/details/78086262
http://www.importnew.com/21958.html
https://www.cnblogs.com/niurougan/p/3976519.html
部分图片来源: https://blog.csdn.net/liweisnake/article/details/78086262
http://www.importnew.com/21958.html
某知名培训机构