模块(Module):在python中,一个.py文件就称之为一个模块。模块共分为三种:python标准库、第三方模块和应用程序自定义模块
模块导入:
1. import 语句:import module1[, module2[,... moduleN]
2. from…import 语句:from modname import name1[, name2[, ... nameN]]
3. from…import* 语句模块导入的本质是通过
sys.path找到文件,然后执行该脚本(全部执行),然后将将变量名加载到名字空间
常用模块:datetime、time、random、os、sys、json、pickle、re、logging、configparse、hashlib
datatime模块
print(datetime.datetime.now())
#2018-09-03 17:07:03.651692
time模块
三种表达形式:
1.时间戳 time()
print(time.time())
#1535961077.9106913
2.结构化时间 localtime()、gmtime()
#----当地时间----
print(time.localtime())
#time.struct_time(tm_year=2018, tm_mon=9, tm_mday=3, tm_hour=15, tm_min=51, tm_sec=17, tm_wday=0, tm_yday=246, tm_isdst=0)
#----UTC----
print(time.gmtime())
#time.struct_time(tm_year=2018, tm_mon=9, tm_mday=3, tm_hour=7, tm_min=51, tm_sec=17, tm_wday=0, tm_yday=246, tm_isdst=0)
3.字符串时间 asctime()、ctime()
# asctime() 把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。如果没有参数,将会将time.localtime()作为参数传入。
print(time.asctime())
#Mon Sep 3 16:56:18 2018
#ctime()把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))
print(time.ctime())
#Mon Sep 3 16:59:20 2018
三种表现形式的相互转换:
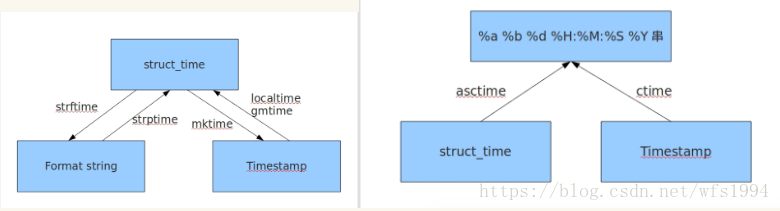
将结构化时间转化为时间戳 mktime()
print(time.mktime(time.localtime()))
#1535964519.0
将结构化时间转化为字符串时间 strftime()
print(time.strftime('%Y-%m-%d %X',time.localtime()))
#2018-09-03 16:48:39
将字符串时间转换为结构化时间 strptime()
print(time.strptime('2018-09-03 16:48:39','%Y-%m-%d %X'))
#time.struct_time(tm_year=2018, tm_mon=9, tm_mday=3, tm_hour=16, tm_min=48, tm_sec=39, tm_wday=0, tm_yday=246, tm_isdst=-1)
random模块
import random
print(random.random()) #0-1之间的随机数
print(random.randint(1,5)) #大于等于1小于等于5的整数
print(random.randrange(1,3)) #大于等于1小于3
print(random.choice([11,22,33])) #对一个可迭代对象的随机选取
print(random.sample([11,22,33],2)) #随机选取两个
print(random.uniform(1,3)) #1.2461267518206374
验证码:
checkcode = ''
for i in range(6):
num = random.randint(0,9)
alf = chr(random.randint(65,90))
res = random.choice([num,alf])
checkcode += str(res)
print(checkcode)
#3SC2Z7os模块
os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") #改变当前脚本工作目录;相当于shell下cd
os.curdir #返回当前目录: ('.')
os.pardir #获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') #可生成多层递归目录
os.removedirs('dirname1') #若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') #生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') #删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() #删除一个文件
os.rename("oldname","newname") #重命名文件/目录
os.stat('path/filename') #获取文件/目录信息
os.sep #输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep #输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n"
os.pathsep #输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name #输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") #运行shell命令,直接显示
os.environ #获取系统环境变量
os.path.abspath(path) #返回path规范化的绝对路径
os.path.split(path) #将path分割成目录和文件名二元组返回
os.path.dirname(path) #返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) #返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) #如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) #如果path是绝对路径,返回True
os.path.isfile(path) #如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) #如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) #返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) #返回path所指向的文件或者目录的最后修改时间
sys模块
sys.argv #命令行参数List,第一个元素是程序本身路径
sys.exit(n) #退出程序,正常退出时exit(0)
sys.version #获取Python解释程序的版本信息
sys.maxint #最大的Int值
sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform #返回操作系统平台名称
进度条
import sys,time
for i in range(10):
sys.stdout.write('#')
time.sleep(0.1)
sys.stdout.flush()
json & pickle
序列化和反序列化:我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json:
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
之前我们学习过用
eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
import json
#序列化
dic={'name':'alvin','age':23,'sex':'male'}
j = json.dumps(dic)
print(type(j)) # <class 'str'>
f = open('json_test','w')
f.write(j) # 等价于 json.dump(dic,f)
f.close()
#反序列化
f = open('json_test')
data = json.loads(f.read()) # 等价于data=json.load(f)
print(data)
#注意点
import json
# x = "{'name':'user'}"
# print(json.loads(x)) #报错,json不认单引号
x = '{"name":"user"}'
print(json.loads(x))
pickle:
import pickle
#序列化
dic={'name':'alvin','age':23,'sex':'male'}
j = pickle.dumps(dic)
print(type(j)) # <class 'bytes'>
f = open('pickle_test','wb') # 注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) # 等价于pickle.dump(dic,f)
f.close()
#反序列化
f = open('pickle_test','rb')
data = pickle.loads(f.read()) # 等价于data=pickle.load(f)
print(data)
re模块
常用方法:
re.findall() # 返回所有满足匹配条件的结果,放在列表里
re.finditer() # 同findall,将查询结果封装到迭代器中,返回的是一个可迭代对象,处理大数据量时非常有用
re.search() # 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
re.match() # 同search,不过尽在字符串开始处进行匹配
re.split() # 分割
re.sub() # 替换
re.subn()
re.compile()
用法示例:
>>> import re
>>> re.findall('\d+','abc123def456') #返回所有满足匹配条件的结果,放在列表里
['123', '456']
>>> re.finditer('\d+','abc123def456')
<callable_iterator object at 0x000000000286DAC8>
>>> ret = re.finditer('\d+','abc123def456')
>>> next(ret).group()
'123'
>>> next(ret).group()
'456'
>>> re.search('\d+','abc123def456') #函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> re.search('\d+','abc123def456').group() #该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
'123'
>>> re.match('\d+','abc123def456').group() #同search,不过尽在字符串开始处进行匹配
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>> re.match('\d+','111abc123def456').group()
'111'
>>> re.split('[ab]','abcd') #先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
['', '', 'cd']
>>> re.sub('\d+','AAA','123abc123def456')
'AAAabcAAAdefAAA'
>>> re.sub('\d+','AAA','123abc123def456',2)
'AAAabcAAAdef456'
>>> re.subn('\d+','AAA','123abc123def456')
('AAAabcAAAdefAAA', 3)
>>> obj = re.compile('\d{3}') #定义的规则可以使用多次
>>> obj.search('abc123def456')
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> obj.search('abc123def456').group()
'123'
>>> obj.search('abc456').group()
'456'
元字符:. ^ $ * + ? { } [ ] | ( ) \
正则表达式用法:https://blog.csdn.net/wfs1994/article/details/80889889
注意点:
1.*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
>>> re.findall('abc?','abcccc')
['abc']
>>> re.findall('abc*','abcccc')
['abcccc']
>>> re.findall('abc+','abcccc')
['abcccc']
>>> re.findall('abc+?','abcccc')
['abc']
>>> re.findall('abc*?','abcccc')
['ab']
2.在python解释器中\\等价于正则中的\
>>> re.findall('a\\\\k','a\k')
['a\\k']
>>> re.findall(r'a\\k','a\k')
['a\\k']
3.分组的特殊用法 (?P<group>pattern)
>>> re.search('(?P<name>[a-z]+)(?P<age>\d{2})','user22')
<_sre.SRE_Match object; span=(0, 6), match='user22'>
>>> ret = re.search('(?P<name>[a-z]+)(?P<age>\d{2})','user18')
>>> ret.group()
'user18'
>>> ret.group('name')
'user'
>>> ret.group('age')
'18'
4.?: 去优先级
>>> re.findall('www\.(baidu|163)\.com','abcwww.baidu.com123')
['baidu'] #findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
>>> re.findall('www\.(?:baidu|163)\.com','abcwww.baidu.com123')
['www.baidu.com']
logging模块
1.简单应用
import logging
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
输出:
WARNING:root:warning message
ERROR:root:error message
CRITICAL:root:critical message
#默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET),默认的日志格式为日志级别:Logger名称:用户输出消息。2.灵活配置日志级别,日志格式,输出位置
import logging
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='test.log',
filemode='w')
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
输出:
Fri, 14 Sep 2018 08:57:56 module_test.py[line:167] DEBUG debug message
Fri, 14 Sep 2018 08:57:56 module_test.py[line:168] INFO info message
Fri, 14 Sep 2018 08:57:56 module_test.py[line:169] WARNING warning message
Fri, 14 Sep 2018 08:57:56 module_test.py[line:170] ERROR error message
Fri, 14 Sep 2018 08:57:56 module_test.py[line:171] CRITICAL critical message
在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format: 指定handler使用的日志显示格式。
datefmt: 指定日期时间格式。
level: 设置rootlogger(后边会讲解具体概念)的日志级别
stream: 用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open('test.log','w')),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s 用户输出的消息
3.logger对象
上述几个例子中我们了解到了logging.debug()、logging.info()、logging.warning()、logging.error()、logging.critical()(分别用以记录不同级别的日志信息),logging.basicConfig()(用默认日志格式(Formatter)为日志系统建立一个默认的流处理器(StreamHandler),设置基础配置(如日志级别等)并加到root logger(根Logger)中)这几个logging模块级别的函数,另外还有一个模块级别的函数是logging.getLogger([name])(返回一个logger对象,如果没有指定名字将返回root logger)
import logging
logger = logging.getLogger()
#logger = logging.getLogger('mylogger')
#logger.setLevel(logging.INFO)
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler('test.log')
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(ch)
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
输出:
2018-09-14 09:03:57,566 - root - WARNING - logger warning message
2018-09-14 09:03:57,567 - root - ERROR - logger error message
2018-09-14 09:03:57,567 - root - CRITICAL - logger critical message
#Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical()输出不同级别的日志,只有日志等级大于或等于设置的日志级别的日志才会被输出。这里没有用logger.setLevel(logging.Debug)显示的为logger设置日志级别,所以使用默认的日志级别WARNIING,故结果只输出了大于等于WARNIING级别的信息。logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。
configparse模块
使用python生成类似mysql、haproxy配置文件这样的文档,以my.cny为例:
import configparser
config = configparser.ConfigParser()
config['client'] = {'port':3306,
'socket':'/var/lib/mysql/mysql.sock'}
config['mysqld'] = {'port':3306,
'socket':'/var/lib/mysql/mysql.sock',
'server_id':1,
'datadir':'/data/mydata',
'character_set_server':'utf8',
'innodb_file_per_table':'1',
'binlog_format':'mixed'}
config['mysqldump'] = {}
config['mysqldump']['max_allowed_packet'] = '16M'
config['myisamchk'] = {}
topsecret = config['myisamchk']
topsecret['key_buffer_size'] = '8M'
topsecret['sort_buffer_size'] = '8M'
with open('my.cnf','w') as configfile:
config.write(configfile)
生成结果:
[client]
port = 3306
socket = /var/lib/mysql/mysql.sock
[mysqld]
port = 3306
socket = /var/lib/mysql/mysql.sock
server_id = 1
datadir = /data/mydata
character_set_server = utf8
innodb_file_per_table = 1
binlog_format = mixed
[mysqldump]
max_allowed_packet = 16M
[myisamchk]
key_buffer_size = 8M
sort_buffer_size = 8M
增删查改:
import configparser
config = configparser.ConfigParser()
#-------查--------------
print(config.sections()) # []
config.read('my.cnf')
print(config.sections()) # ['client', 'mysqld', 'mysqldump', 'myisamchk']
print('mysqld' in config) # True
print('mysql' in config) # False
print(config['client']['port']) # 3306
print(config['mysqld']['binlog_format']) # mixed
for key in config['myisamchk']:
print(key)
#key_buffer_size
#sort_buffer_size
print(config.options('myisamchk')) # ['key_buffer_size', 'sort_buffer_size']
print(config.items('myisamchk')) # [('key_buffer_size', '8M'), ('sort_buffer_size', '8M')]
print(config.get('myisamchk','key_buffer_size')) # 8M
#---------------增、删、改(config.write(open('filename','w')))------------
config.read('my.cnf')
config.add_section('mysql') # 新增一个[mysql]标签段
config.remove_section('mysqldump') #删除[mysqldump]标签段
config.remove_option('client','port')
config.set('client','default-character-set','utf8')
config.write(open('my.cnf1','w'))
hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512, MD5 算法。
import hashlib
hash = hashlib.md5() # hash = hashlib.sha256()
hash.update('hello'.encode('utf8'))
print(hash.hexdigest()) # 5d41402abc4b2a76b9719d911017c592
hash.update('world'.encode('utf8'))
print(hash.hexdigest()) # fc5e038d38a57032085441e7fe7010b0
hash1 = hashlib.md5()
hash1.update('helloworld'.encode('utf8'))
print(hash1.hexdigest()) # fc5e038d38a57032085441e7fe7010b0
以上加密算法虽然依然非常厉害,但有时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
import hashlib
hash = hashlib.md5('salt'.encode('utf8'))
hash.update('hello'.encode('utf8'))
print(hash.hexdigest()) # 06decc8b095724f80103712c235586be
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密:
import hmac
h = hmac.new('salt'.encode('utf8'))
h.update('hello'.encode('utf8'))
print(h.hexdigest()) # 3a2484b4f0df4f4157d069598a334b31
参考链接:http://www.cnblogs.com/yuanchenqi/articles/5732581.html