MPI 的 manpages 需要在线查看,或者在 Linux 系统中用 man 查看,不方便。这里我做了一些对常用函数的分类总结。
文章目录
基本结构:启动和终止
#include <mpi.h> // ******************1
#include <stdio.h>
int main(int argc, char** argv) {
MPI_Init(NULL, NULL); // ******************2
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
char processor_name[MPI_MAX_PROCESSOR_NAME];
int name_len;
MPI_Get_processor_name(processor_name, &name_len);
printf("Hello world from processor %s, rank %d out of %d processors\n",
processor_name, world_rank, world_size);
MPI_Finalize(); // ******************3
}
MPI_Init
MPI_Init(
int* argc,
char*** argv)
所有 MPI 的全局变量或者内部变量都会被创建。举例来说,一个通讯器 communicator 会根据所有可用的进程被创建出来(进程是我们通过 mpi 运行时的参数指定的),然后每个进程会被分配独一无二的秩 rank
MPI_Finalize
MPI_Finalize()
用来清理 MPI 环境的。这个调用之后就没有 MPI 函数可以被调用了。
MPI_Comm_size
MPI_Comm_size(
MPI_Comm communicator,
int* size)
返回 communicator 的大小,也就是 communicator 中可用的进程数量。
MPI_Comm_rank
MPI_Comm_rank(
MPI_Comm communicator,
int* rank)
返回 communicator 中当前进程的 rank。 communicator 中每个进程会以此得到一个从 0 开始递增的数字作为 rank 值。rank 值主要是用来指定发送或者接受信息时对应的进程。
MPI_Get_processor_name
MPI_Get_processor_name(
char* name,
int* name_length)
得到当前进程实际跑的时候所在的处理器名字。
点对点的通信:发送和接收
MPI_Send
MPI_Send(
void* data,
int count,
MPI_Datatype datatype,
int destination,
int tag,
MPI_Comm communicator)
本端点发送包含 count 个 datatype 类型的数据 *data 给 rank 为 destination 的目标端点,数据标签为 tag,通讯器为 communicator(通常为 MPI_COMM_WORLD)。
该方法会阻塞直到发送缓存可以被回收。这意味着当网络可以缓冲消息时,该方法就可以返回;如果网络不可以缓存消息,就会一直阻塞至遇到匹配的接受方法。
datatype 取值有:
| MPI datatype | C equivalent |
|---|---|
| MPI_SHORT | short int |
| MPI_INT | int |
| MPI_LONG | long int |
| MPI_LONG_LONG | long long int |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short int |
| MPI_UNSIGNED | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_UNSIGNED_LONG_LONG | unsigned long long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_BYTE | char |
MPI_Recv
MPI_Recv(
void* data,
int count,
MPI_Datatype datatype,
int source,
int tag,
MPI_Comm communicator,
MPI_Status* status)
本端点接受 rank 为 source (不限制时用 MPI_ANY_SOURCE )的源端点传来的,标签为 tag (不限制时用 MPI_ANY_TAG),类型为 datatype 的数据,数据保存在 *data 中,最大长度为 count,实际接受的数据长度和 tag 保存在 status 中,status.MPI_SOURCE 为实际接受的源 rank,status.MPI_TAG 为实际接受的 tag,通讯器为 communicator。
该方法会阻塞来接受匹配 source 和 tag 的数据。
MPI_Get_count
参考资料:http://mpitutorial.com/tutorials/dynamic-receiving-with-mpi-probe-and-mpi-status/
MPI_Get_count(
MPI_Status* status,
MPI_Datatype datatype,
int* count)
根据 status 和 datatype,查询实际接受到了数据个数保存在 *count 中。
MPI_Probe
MPI_Probe(
int source,
int tag,
MPI_Comm comm,
MPI_Status* status)
可以作为 MPI_Recv 的预热,通过 status 确定收到的数据大小之后,再分配准确的内存来用 MPI_Recv 接受数据。
示例:
MPI_Status status;
// Probe for an incoming message from process zero
MPI_Probe(0, 0, MPI_COMM_WORLD, &status);
// When probe returns, the status object has the size and other
// attributes of the incoming message. Get the size of the message.
MPI_Get_count(&status, MPI_INT, &number_amount);
// Allocate a buffer just big enough to hold the incoming numbers
int* number_buf = (int*)malloc(sizeof(int) * number_amount);
// Now receive the message with the allocated buffer
MPI_Recv(number_buf, number_amount, MPI_INT, 0, 0, MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
笛卡尔拓扑
MPI_Cart_create
int MPI_Cart_create(MPI_Comm comm_old, int ndims, const int dims[],
const int periods[], int reorder, MPI_Comm *comm_cart)
- ndims:指定拓扑结构的维度
- dims[]数组:指定每个维度的大小([3,2] 表示维度 0 的坐标为 0-2,维度 1 的坐标为 0-1)
- periods[]数组:指定拓扑结构中是否有环绕连接,非0表示有,0表示无
- reorder:确定新通信器中的进程是否需要重新排序
获取属于通信器 comm_old 的一组进程,创建一个虚拟进程结构。指定的进程数不能大于通信器 comm_old 中的进程总数。不是笛卡尔结构的组成部分的进程获得的 comm_cart 值为 MPI_COMM_NULL。
MPI_Cart_coords
int MPI_Cart_coords(MPI_Comm comm, int rank, int maxdims,
int coords[])
通常先用 MPI_Comm_rank 获得当前进程在笛卡尔通信器中的等级,再用 MPI_Cart_coords 获得进程的笛卡尔坐标。
MPI_Cart_shift
int MPI_Cart_shift(MPI_Comm comm, int direction, int disp,
int *rank_source, int *rank_dest)
- direction:指定维度
- disp:指定通信的方向和距离,负数表示负方向
- rank_source:通信的源进程的等级
- rank_dest:通信的目的进程的等级
计算在数据交换操作中源进程和目标进程的等级。
集体通信:广播和规约
MPI_Barrier (同步点)
MPI_Barrier(MPI_Comm communicator)
(Barrier,屏障)- 这个方法会构建一个屏障,任何进程都没法跨越屏障,直到所有的进程都到达屏障。
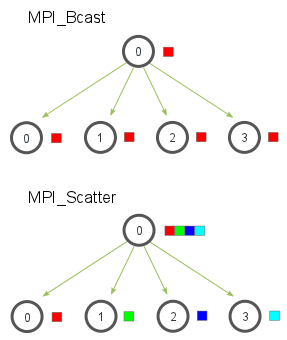
MPI_Bcast (广播)
MPI_Bcast(
void* data,
int count,
MPI_Datatype datatype,
int root,
MPI_Comm communicator)
一个广播发生的时候,一个进程会把同样一份数据传递给一个 communicator 里的所有其他进程。根节点调用 MPI_Bcast 函数的时候,data 变量里的值会被发送到其他的节点上。当其他的节点调用 MPI_Bcast 的时候,data 变量会被赋值成从根节点接受到的数据。
实现使用了一个树形广播算法来获得比较好的网络利用率。
MPI_Scatter
MPI_Scatter(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)
root 进程执行该函数时,接收一个数组 send_data,并把元素按进程的秩分发出去,给每个进程发送 send_count 个元素。其他进程包括(root)执行该函数时,收到 recv_count 个 revc_datatype 类型的数据,存放在数组 recv_data 中。
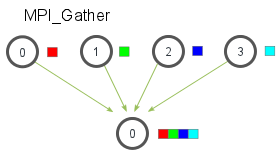
MPI_Gather
MPI_Gather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)
所有进程执行该函数时,从 send_datatype 类型的数组 send_data 中取出前 send_count 个元素,发送给 root 进程。root 进程同时还会将从每个进程中收集到的 recv_count 个数据,存放在 recv_data 数组中。
MPI_Gatherv
int MPI_Gatherv(
const void* sendbuf, int sendcount, MPI_Datatype sendtype,
void* recvbuf, const int recvcounts[], const int displs[],
MPI_Datatype recvtype, int root, MPI_Comm comm)
当每个节点传递的数据长度不一时,采用这个函数。
- IN sendbuf: starting address of send buffer (choice)
- IN sendcount: number of elements in send buffer (non-negative integer)
- IN sendtype: data type of send buffer elements (handle)
- OUT recvbuf: address of receive buffer (choice, significant only at root)
- IN recvcounts: non-negative integer array (of length group size) containing the number of elements that are received from each process (significant only at root)
- IN displs: integer array (of length group size). Entry i specifies the displacement relative to recvbuf at which to place the incoming data from process i (significant only at root)
MPI_Allgather (多对多)
MPI_Allgather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
MPI_Comm communicator)
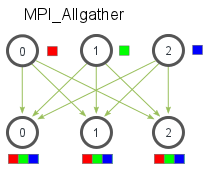
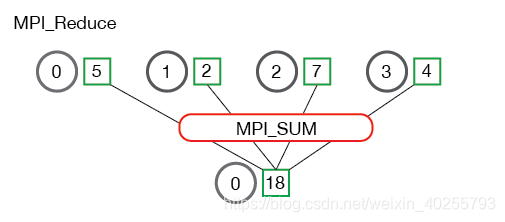
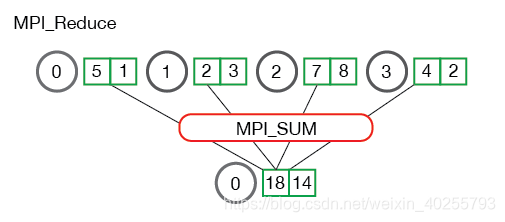
MPI_Reduce
MPI_Reduce(
void* send_data,
void* recv_data,
int count,
MPI_Datatype datatype,
MPI_Op op,
int root,
MPI_Comm communicator)
每个进程发送容量为 count 的数组 send_data,root 进程收到后进行 op 操作,存放在容量也为 count 的数组 recv_data 中。
MPI_Op 操作类型有:
MPI_MAX- 最大MPI_MIN- 最小MPI_SUM- 求和MPI_PROD- 乘积MPI_LAND- 逻辑与MPI_LOR- 逻辑或MPI_BAND- 位运算的“与”MPI_BOR- 位运算的“或”MPI_MAXLOC- 最大值和拥有该值的进程的 rankMPI_MINLOC- 最小值和拥有该值的进程的 rank
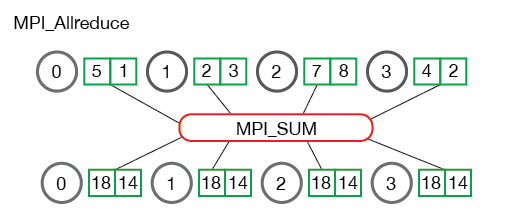
MPI_Allreduce
MPI_Allreduce(
void* send_data,
void* recv_data,
int count,
MPI_Datatype datatype,
MPI_Op op,
MPI_Comm communicator)
Groups 和 Communicators
警告
- MPI 一次可创建的对象是有数量限制的,如果用完了可分配的对象,而不释放,可能导致运行时错误。
- 新建的
MPI_Comm需要用MPI_Comm_free(MPI_Comm *comm)来释放,该函数不能用MPI_COMM_NULL做参数 - 新建的
MPI_Group需要用MPI_Group_free(MPI_Group *group)来释放
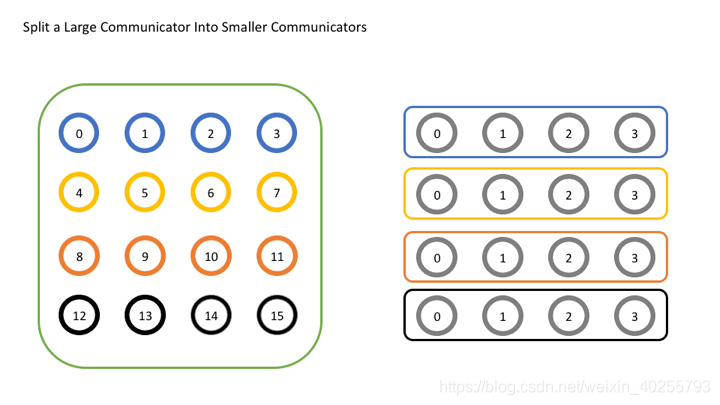
MPI_Comm_split
MPI_Comm_split(
MPI_Comm comm,
int color,
int key,
MPI_Comm* newcomm)
将 comm 中的进程分到新的 newcomm 中,color 相同的进程被分到同一个 newcomm,且根据 key 的大小进行排序,最小的为 0。
MPI_Comm_create
MPI_Comm_create(
MPI_Comm comm,
MPI_Group group,
MPI_Comm* newcomm)
group 是 comm 的组的子集,利用这个组创建一个新的通讯器 newcomm。非该组内的进程执行函数得到的 newcomm 为 MPI_COMM_NULL。释放资源时要注意!!!
MPI_Comm_group
MPI_Comm_group(
MPI_Comm comm,
MPI_Group *group)
获得通讯器 comm 对应的组 *group。
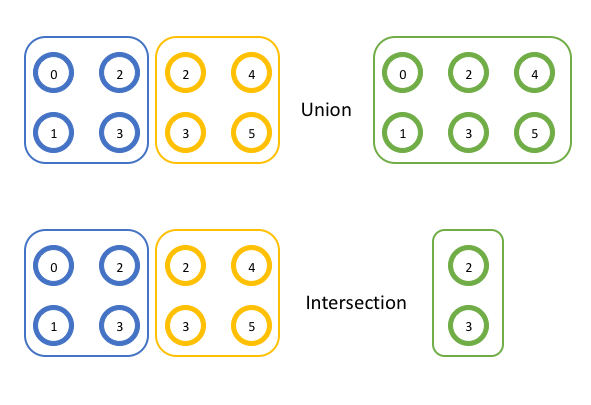
MPI_Group_union
MPI_Group_union(
MPI_Group group1,
MPI_Group group2,
MPI_Group* newgroup)
MPI_Group_intersection
MPI_Group_intersection(
MPI_Group group1,
MPI_Group group2,
MPI_Group* newgroup)
MPI_Comm_create_group
MPI_Comm_create_group(
MPI_Comm comm,
MPI_Group group,
int tag,
MPI_Comm* newcomm)
)
group 是通讯器 comm 对应的组的子组,利用这个组创建一个新的通讯器 newcomm。不在这个组内的进程,调用此方法时得到的 newcomm 为 MPI_COMM_NULL。释放资源时要注意!!!
MPI_Group_incl
MPI_Group_incl(
MPI_Group group,
int n,
const int ranks[],
MPI_Group* newgroup)
ranks 数组中有 n 个元素,代表了 group 中的部分进程,用这些进程来创建一个新的组 newgroup。
版权声明
本文主要内容来自 A Comprehensive MPI Tutorial Resource,一个简洁的 MPI 入门教程,部分有中文翻译。
附录 A 延伸阅读
- How to code parallel stuff in C/C++ using MPI with CLion on Windows,介绍了如何在 Windows 上配置 CLion 来编写 MPI 程序,并可以运行!(膜拜大佬)
- How to compile and run a simple MS-MPI program ,介绍了如何利用 Microsoft Visual Studio 来编译运行 MPI 项目。(膜拜微软)
- 劳伦斯利弗莫尔国家实验室的 MPI 教程:https://computing.llnl.gov/tutorials/mpi/
附录 B OpenMPI 的配置
bash 的环境变量在载入过程中,会依次执行 /etc/profile -> ~/bash_profile(-> ~/.bashrc)。所以我们可以把 OpenMPI 的变量写在 ~/.bashrc 的末尾。
export PATH=/opt/openmpi/1.10.7/bin/:$PATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/openmpi/1.10.7/lib
最后记得载入环境变量:
source ~/.bashrc