转载:https://blog.csdn.net/hu948162999/article/details/78862573
搜索架构的探索之当前现状

蘑菇街搜索当前架构
如上图,是蘑菇街当前搜索架构,分为在线和离线两部分。在线部分主要职责是处理在线的搜索请求。离线部分的主要职责是处理数据流。

在线请求链路
如上图,是整个在线请求链路,主要分为topn->qr->引擎->精排->透出五个环节。
第一步,请求首先进入topn系统,做ab配置/业务请求链路配置。
第二步,请求进入QR改写系统做切词,同义词扩展,类目相关性,插件化等。
第三步,进入UPS用户个性化数据存储系统。
第四步,投放层得到UPS和QR两部分的数据后,放入搜索引擎做召回。搜索主要会经过一轮海选,海选的依据是文本相关性和商品质量,这样做是为确保召回的商品质量大致可靠。之后会经过多轮初选,过程中会应用到更复杂的算法模型,对海选的结果进行排序。搜索引擎得到粗排的结果约千级别。
第五步,粗排结果进入到精排系统,精排系统主要通过算法,做个性化排序、实时预测,精排和引擎类似,也支持多轮排序。经过精排系统之后,最终把结果透出给业务层。
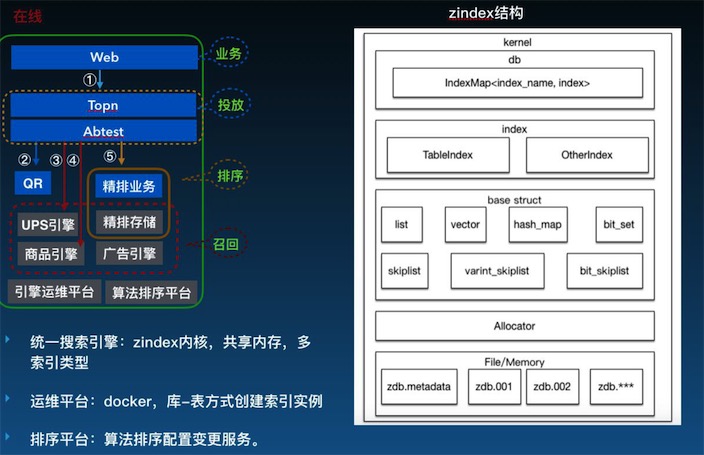
蘑菇街统一引擎系统
如上图,左侧红色框内是蘑菇街统一引擎系统,包含用户个性化存储系统、精排存储、商品引擎、广告引擎等。由于这样的形式维护成本特别高,故做了右图这个统一的Zindex内核架构。这个架构的最底层是共享内存分配器,再上层是可支持不同数据结构的各种引擎,再上层是索引管理。基于这个架构,不同的引擎可根据各自需求去创建自己的索引。
跟这个架构相关的,就是我们的运维平台,是基于公司Docker虚拟化技术做的一个运维平台,能够非常快的支持索引创建,包括创建之后整个索引数据的管理。还有就是排序平台,用来提供算法配置变更服务。

搜索架构离线部分的数据流程
如上图,是离线的数据流程的情况,主要职责是数据流的处理,完整的索引数据分为算法数据和业务数据。
算法数据参与排序,整个链路从最前端ACM打点、再落到整个数据仓库、经过清洗之后,在数据平台上跑训练脚本,得出的特征导到特征平台,再同步到线上。
业务数据的主要来源就是DB,DB中主要存储商品、店铺之间的数据,业务变更主要基于mysql bin-log事件监听,变更之后做全量和增量。全量每天定时索引操作、增量会流到MQ,再通过业务拼装推到线上。
搜索架构的探索之演变历程
蘑菇街搜索架构主要经历导购时期(~2013.11)、电商初期(2013.11~2014.11)、Solr主搜(2015.4~2016.3)、C++主搜(2015.8~2016.11)、平台化(2017.1~now)五大阶段。

蘑菇街搜索架构现状简化版
为了更清晰直观进行对比,我把当前搜索架构简化成如上图所示的业务、投放、排序、召回、数据流五大层。接下来我们来看看,我们从最早期,都经历哪些演变,一步步走到现在。

蘑菇街搜索架构导购时期架构
如上图,是~2013.11导购时期的架构,有用到放在PHP代码里的业务+投放、用Java搜索引擎Solr做的召回+排序和数据流三层。这个时期,排序需求不是很迫切,更多侧重的是商品整体的丰富度和新颖度。简单理解,热销排序等于喜欢乘10加上收藏乘50,基于Solr的改造来实现。
在电商转型初期(2013.11~2014.11),由于卖自己的商品,流量变得更值钱了,工程师会想法设法去提升流量的效率。同时用户行为也在增加,产生更多的数据。还有增量管理复杂,数据量大、Optimaize风险大、导购、广告和搭配等多类型商品透出等等。其中最明显挑战就是排序特征变多、数据变大、次数频繁。

蘑菇街搜索架构转型初期架构
面对这些挑战,当时的思路是把算法独立成单独Java工程做算分,但百万商品百种排序,算法排序达G级别,这些排序数据需要作用于搜索引擎,快速生效,问题是用增量的方式会引来索引碎片的增加,会给线上引擎稳定性带来波动。故另辟蹊径,用在Solr进程中设置堆外内存来管理这部分排序数据。
总结来说,转型初期整体的解决方案就是把算法独立出来单独去做,把部分分数尽快同步到引擎,进行生效。这样的方法,当时线上效果很显著,但随时间推移又有新问题出来:
- 规则排毒->LTR,算法排序需求多;
- 排序灵活性制约:计算好的分数离线推送到Solr;
- Solr内存压力:GC/段合并;
- 静态分,相关性差;
- 大促相关性问题:搜索“雨伞”,雨伞图案的连衣裙会排在前面;

Solr主搜整体架构
针对这些新问题,(2015.4)Solr主搜改造,支持Rank插件(Ranker->Scorer),配置化+动态化,整体架构如上图。应对相关性问题,新增QR系统、应对内存压力,做Solr升级(Docvalues),算法分走动态字段增量,同时投放方式也渐渐形成Topn系统,对外对接不同的搜索场景。
Solr架构解决相关性、算法变更线上排序等问题,但新问题在于虽用机器学习的排序做法,但那个时期主要是爆款模型,有很多个性化需求模型同时对不同人要有不同的排序结果,还有一些重排序或打散等更加复杂的需求。因Solr实现机制的限制,只能做一轮排序,想要改动比较难。另外,Solr整个索引结构非常复杂,二次开发成本高,内存、性能上也慢慢地暴露出很多问题,同时还有Java的GC也是不可逾越的鸿沟。
当时多轮排序的需求,除了做一些文本相关性,还相对商品做品牌加权,如想扶持某些品牌、做类目打散等,这些在单轮排序内做不到,原来的方式只能把多轮融合在一个排序中搞定,但效果会很差。

C++主搜架构
如上图,是C++主搜架构(2015.8~2016.11)上线,在整个性能和排序方面做了定制,可支持多轮排序、整个内存采用内存方式,由排序体系支撑。这个阶段整体来看,相对是完善的,每层,整个系统都成型,可数据流环节又出现了三个问题:
- 全量无调度,都要依靠流程制约
- 增量带来算法分数不可比,会带来一些线上排序的抖动
- 业务数据增量对服务接口压力过大(促销故障)

全量的整个链路
如上图,是全量的整个链路,算法序列的整个链路靠时间约定,数据容灾机制弱。所以大促时,前置任务延迟全量做不了,线上内存几乎撑爆,经常性全量延时,必须手动去处理。还有算法误导排序分,导致线上错乱,增量恢复时间长。
要解决这个问题,我们首要引入一个基于Zookeeper的调度系统,把整个数据流驱动起来同时支持错误报警。容灾部分的思路就是增加排序SOS字段、基于HBase定期生成全量快照,快速回档、单算法字段修复等。
两次算法增量分数不可比,增量生效特别慢。如时刻1算出商品是90分,时刻2是60分,就会引起线上排序抖动,主要因算法两次序列导致整个数据分布不同,特别到大促时期,不同时段成交数据变化特别快,商品排序的波动非常明显,增量数据同一批正常,但两次见就会出错。当0点大家在疯狂购物的时候,变更非常频繁,会导致排序错乱。算法数据出错后,生效时间也会比较慢。

如上图,我们的解决方案是通过小全量的方式把算法、分数单独拖到线上引擎本地,在引擎本地依次一次加载,直接切换的方式,让每一次算法增量数据的数据加速生效,容灾也会加快。

如上图,由于变更都是Doc级更新,每一个字段更新都会调用所有的接口去拼装成一条完整的数据去更新,这导致业务增量压力特别大。大促期间,增量QPS可以达到几千~上万,对下游40多个接口的压力非常大。

如上图,这个问题解决的思路是让引擎,包括数据流支持字段更新。只拼装变更字段、不需要拼装完整的数据,这需要引擎本身支持才能做到。当时上线,收益非常明显,关键接口QPS减少80%以上。
平台化(2017.1~now)是现在正在做的事情。面对UPS、广告、商品多套引擎系统与广告、搜索多套投放系统分别从不同团队合并过来, 维护成本问题。排序计算需求变得更加复杂,尝试用非线性模型等方面挑战,就有了现在整理的架构,思路就是平台化、统一化,把重复的系统整合、数据流做统一。
搜索架构的探索之经验总结
这一路走来,整个搜索架构的探索经验就是在发展前期要简单快速支持线上业务,之后在逐步演变,来满足算法的需求,最后在考虑整个利用平台化、统一化的思路去提升效率,降低成本。
不同阶段要有不同的选择,我们最早基于Solr改写,待团队、人员,包括技术储备上也有实力后,直接重写搜索引擎,覆盖算法的离线、在线链路,做体系化建设。
我们的后续规划是新架构整体平台化继续深入,算法方面加强学习,如深度学习、在线学习等。如深度学习框架的研究和使用,以及图搜工程体系的建设。
推荐架构的探索之发展概述
蘑菇街的推荐架构已经覆盖大部分的用户行为路径,从使用进入APP,到下单成交完成都会有推荐场景出现。推荐架构的整个发展分为发展早期(2103.11~2015.6)、1.0时期:从0到1(2015.6~2016.3)、2.0:投放+个性化(2016.3~2016.12)、3.0:平台化(2016.2~now)四大阶段。
发展早期(2103.11~2015.6)推荐的场景并不多,需求也比较简单,数据离线更新到Redis就好,当时明显的问题是没有专门的推荐系统来承载推荐场景、效果跟踪差、场景对接、数据导入等效率低等。

1.0时期的推荐架构
1.0时期:从0到1(2015.6~2016.3)把推荐系统搭建起来,包含Service层对接场景、推荐实时预测、自写的K-V的系统用来存储推荐结果。这里踩的一个坑是,把实时预测做到离线部分,但其实实时预测更多的是在线流程。
随着时间推移,场景类型(猜你喜欢、搜相似、店铺内)、相似场景(首页、购物车、详情页…)不断增加,算法方面需要实时排序,应对实时的点击、加购等,还有一些个性化排序需求,如店铺、类目、离线偏好等。1.0阶段主要面临三大问题:
- 多类型多场景:上线系统不一,缺少统一对接层,成本高;
- 场景配置化:场景算法一对一,重复代码拷贝,维护难;
- 个性化+实时:缺系统支持;

2.0时期的推荐架构
如上图,2.0时期的推荐架构(2016.3~2016.12)主要解决1.0的三大问题,增加投放层Prism,统一对外对接不同的业务场景,对Prism做动态配置和规则模板。个性化实时方面增加UPS与精排系统。

2.0时期推荐架构投放层配置化
如上图,2.0时期推荐架构投放层配置化思路是把不变的部分模板化,可变的部分配置化。系统提供召回组建、数据补全、格式化等模板。当时效果很明显,321大促运营位置个性化效果提升20%+,双11大促,会场楼层个性化提升100%+。
大促带来的巨大收益,给整个系统带来很正面的影响,后续推荐架构又面临更多的需求与挑战:
- 日益增长的资源位、直播、图像等场景和类型;
- 跟美的融合,跨团队跨地域的挑战;
- 工程算法用一套代码,整个策略的开发调试都非常复杂,包括工程部分的职责不清问题;
- 由于原来模板化的配置,导致一些简单场景复杂化。
针对这些问题,我们需要做的事情就是通用化、平台化。针对整套系统进行统一推荐方案,自动化整体算法对接核心业务流程、以及和算法人员的职责划分清晰,提升双方的工作效率。

3.0时期推荐架构
3.0时期推荐架构 (2016.2~now)与搜索架构类似,系统间职能更加明晰,统一和平台化,主要还是投放层做了改造。

3.0时期推荐架构投放层细节
如上图, 3.0时期推荐架构投放层重要的概念就是场景化,场景应对推荐业务,不同场景会对应不同的策略实现。
转载:https://blog.csdn.net/hu948162999/article/details/78862573
搜索架构的探索之当前现状
蘑菇街搜索当前架构
如上图,是蘑菇街当前搜索架构,分为在线和离线两部分。在线部分主要职责是处理在线的搜索请求。离线部分的主要职责是处理数据流。
在线请求链路
如上图,是整个在线请求链路,主要分为topn->qr->引擎->精排->透出五个环节。
第一步,请求首先进入topn系统,做ab配置/业务请求链路配置。
第二步,请求进入QR改写系统做切词,同义词扩展,类目相关性,插件化等。
第三步,进入UPS用户个性化数据存储系统。
第四步,投放层得到UPS和QR两部分的数据后,放入搜索引擎做召回。搜索主要会经过一轮海选,海选的依据是文本相关性和商品质量,这样做是为确保召回的商品质量大致可靠。之后会经过多轮初选,过程中会应用到更复杂的算法模型,对海选的结果进行排序。搜索引擎得到粗排的结果约千级别。
第五步,粗排结果进入到精排系统,精排系统主要通过算法,做个性化排序、实时预测,精排和引擎类似,也支持多轮排序。经过精排系统之后,最终把结果透出给业务层。
蘑菇街统一引擎系统
如上图,左侧红色框内是蘑菇街统一引擎系统,包含用户个性化存储系统、精排存储、商品引擎、广告引擎等。由于这样的形式维护成本特别高,故做了右图这个统一的Zindex内核架构。这个架构的最底层是共享内存分配器,再上层是可支持不同数据结构的各种引擎,再上层是索引管理。基于这个架构,不同的引擎可根据各自需求去创建自己的索引。
跟这个架构相关的,就是我们的运维平台,是基于公司Docker虚拟化技术做的一个运维平台,能够非常快的支持索引创建,包括创建之后整个索引数据的管理。还有就是排序平台,用来提供算法配置变更服务。
搜索架构离线部分的数据流程
如上图,是离线的数据流程的情况,主要职责是数据流的处理,完整的索引数据分为算法数据和业务数据。
算法数据参与排序,整个链路从最前端ACM打点、再落到整个数据仓库、经过清洗之后,在数据平台上跑训练脚本,得出的特征导到特征平台,再同步到线上。
业务数据的主要来源就是DB,DB中主要存储商品、店铺之间的数据,业务变更主要基于mysql bin-log事件监听,变更之后做全量和增量。全量每天定时索引操作、增量会流到MQ,再通过业务拼装推到线上。
搜索架构的探索之演变历程
蘑菇街搜索架构主要经历导购时期(~2013.11)、电商初期(2013.11~2014.11)、Solr主搜(2015.4~2016.3)、C++主搜(2015.8~2016.11)、平台化(2017.1~now)五大阶段。
蘑菇街搜索架构现状简化版
为了更清晰直观进行对比,我把当前搜索架构简化成如上图所示的业务、投放、排序、召回、数据流五大层。接下来我们来看看,我们从最早期,都经历哪些演变,一步步走到现在。
蘑菇街搜索架构导购时期架构
如上图,是~2013.11导购时期的架构,有用到放在PHP代码里的业务+投放、用Java搜索引擎Solr做的召回+排序和数据流三层。这个时期,排序需求不是很迫切,更多侧重的是商品整体的丰富度和新颖度。简单理解,热销排序等于喜欢乘10加上收藏乘50,基于Solr的改造来实现。
在电商转型初期(2013.11~2014.11),由于卖自己的商品,流量变得更值钱了,工程师会想法设法去提升流量的效率。同时用户行为也在增加,产生更多的数据。还有增量管理复杂,数据量大、Optimaize风险大、导购、广告和搭配等多类型商品透出等等。其中最明显挑战就是排序特征变多、数据变大、次数频繁。
蘑菇街搜索架构转型初期架构
面对这些挑战,当时的思路是把算法独立成单独Java工程做算分,但百万商品百种排序,算法排序达G级别,这些排序数据需要作用于搜索引擎,快速生效,问题是用增量的方式会引来索引碎片的增加,会给线上引擎稳定性带来波动。故另辟蹊径,用在Solr进程中设置堆外内存来管理这部分排序数据。
总结来说,转型初期整体的解决方案就是把算法独立出来单独去做,把部分分数尽快同步到引擎,进行生效。这样的方法,当时线上效果很显著,但随时间推移又有新问题出来:
- 规则排毒->LTR,算法排序需求多;
- 排序灵活性制约:计算好的分数离线推送到Solr;
- Solr内存压力:GC/段合并;
- 静态分,相关性差;
- 大促相关性问题:搜索“雨伞”,雨伞图案的连衣裙会排在前面;
Solr主搜整体架构
针对这些新问题,(2015.4)Solr主搜改造,支持Rank插件(Ranker->Scorer),配置化+动态化,整体架构如上图。应对相关性问题,新增QR系统、应对内存压力,做Solr升级(Docvalues),算法分走动态字段增量,同时投放方式也渐渐形成Topn系统,对外对接不同的搜索场景。
Solr架构解决相关性、算法变更线上排序等问题,但新问题在于虽用机器学习的排序做法,但那个时期主要是爆款模型,有很多个性化需求模型同时对不同人要有不同的排序结果,还有一些重排序或打散等更加复杂的需求。因Solr实现机制的限制,只能做一轮排序,想要改动比较难。另外,Solr整个索引结构非常复杂,二次开发成本高,内存、性能上也慢慢地暴露出很多问题,同时还有Java的GC也是不可逾越的鸿沟。
当时多轮排序的需求,除了做一些文本相关性,还相对商品做品牌加权,如想扶持某些品牌、做类目打散等,这些在单轮排序内做不到,原来的方式只能把多轮融合在一个排序中搞定,但效果会很差。
C++主搜架构
如上图,是C++主搜架构(2015.8~2016.11)上线,在整个性能和排序方面做了定制,可支持多轮排序、整个内存采用内存方式,由排序体系支撑。这个阶段整体来看,相对是完善的,每层,整个系统都成型,可数据流环节又出现了三个问题:
- 全量无调度,都要依靠流程制约
- 增量带来算法分数不可比,会带来一些线上排序的抖动
- 业务数据增量对服务接口压力过大(促销故障)
全量的整个链路
如上图,是全量的整个链路,算法序列的整个链路靠时间约定,数据容灾机制弱。所以大促时,前置任务延迟全量做不了,线上内存几乎撑爆,经常性全量延时,必须手动去处理。还有算法误导排序分,导致线上错乱,增量恢复时间长。
要解决这个问题,我们首要引入一个基于Zookeeper的调度系统,把整个数据流驱动起来同时支持错误报警。容灾部分的思路就是增加排序SOS字段、基于HBase定期生成全量快照,快速回档、单算法字段修复等。
两次算法增量分数不可比,增量生效特别慢。如时刻1算出商品是90分,时刻2是60分,就会引起线上排序抖动,主要因算法两次序列导致整个数据分布不同,特别到大促时期,不同时段成交数据变化特别快,商品排序的波动非常明显,增量数据同一批正常,但两次见就会出错。当0点大家在疯狂购物的时候,变更非常频繁,会导致排序错乱。算法数据出错后,生效时间也会比较慢。
如上图,我们的解决方案是通过小全量的方式把算法、分数单独拖到线上引擎本地,在引擎本地依次一次加载,直接切换的方式,让每一次算法增量数据的数据加速生效,容灾也会加快。
如上图,由于变更都是Doc级更新,每一个字段更新都会调用所有的接口去拼装成一条完整的数据去更新,这导致业务增量压力特别大。大促期间,增量QPS可以达到几千~上万,对下游40多个接口的压力非常大。
如上图,这个问题解决的思路是让引擎,包括数据流支持字段更新。只拼装变更字段、不需要拼装完整的数据,这需要引擎本身支持才能做到。当时上线,收益非常明显,关键接口QPS减少80%以上。
平台化(2017.1~now)是现在正在做的事情。面对UPS、广告、商品多套引擎系统与广告、搜索多套投放系统分别从不同团队合并过来, 维护成本问题。排序计算需求变得更加复杂,尝试用非线性模型等方面挑战,就有了现在整理的架构,思路就是平台化、统一化,把重复的系统整合、数据流做统一。
搜索架构的探索之经验总结
这一路走来,整个搜索架构的探索经验就是在发展前期要简单快速支持线上业务,之后在逐步演变,来满足算法的需求,最后在考虑整个利用平台化、统一化的思路去提升效率,降低成本。
不同阶段要有不同的选择,我们最早基于Solr改写,待团队、人员,包括技术储备上也有实力后,直接重写搜索引擎,覆盖算法的离线、在线链路,做体系化建设。
我们的后续规划是新架构整体平台化继续深入,算法方面加强学习,如深度学习、在线学习等。如深度学习框架的研究和使用,以及图搜工程体系的建设。
推荐架构的探索之发展概述
蘑菇街的推荐架构已经覆盖大部分的用户行为路径,从使用进入APP,到下单成交完成都会有推荐场景出现。推荐架构的整个发展分为发展早期(2103.11~2015.6)、1.0时期:从0到1(2015.6~2016.3)、2.0:投放+个性化(2016.3~2016.12)、3.0:平台化(2016.2~now)四大阶段。
发展早期(2103.11~2015.6)推荐的场景并不多,需求也比较简单,数据离线更新到Redis就好,当时明显的问题是没有专门的推荐系统来承载推荐场景、效果跟踪差、场景对接、数据导入等效率低等。
1.0时期的推荐架构
1.0时期:从0到1(2015.6~2016.3)把推荐系统搭建起来,包含Service层对接场景、推荐实时预测、自写的K-V的系统用来存储推荐结果。这里踩的一个坑是,把实时预测做到离线部分,但其实实时预测更多的是在线流程。
随着时间推移,场景类型(猜你喜欢、搜相似、店铺内)、相似场景(首页、购物车、详情页…)不断增加,算法方面需要实时排序,应对实时的点击、加购等,还有一些个性化排序需求,如店铺、类目、离线偏好等。1.0阶段主要面临三大问题:
- 多类型多场景:上线系统不一,缺少统一对接层,成本高;
- 场景配置化:场景算法一对一,重复代码拷贝,维护难;
- 个性化+实时:缺系统支持;
2.0时期的推荐架构
如上图,2.0时期的推荐架构(2016.3~2016.12)主要解决1.0的三大问题,增加投放层Prism,统一对外对接不同的业务场景,对Prism做动态配置和规则模板。个性化实时方面增加UPS与精排系统。
2.0时期推荐架构投放层配置化
如上图,2.0时期推荐架构投放层配置化思路是把不变的部分模板化,可变的部分配置化。系统提供召回组建、数据补全、格式化等模板。当时效果很明显,321大促运营位置个性化效果提升20%+,双11大促,会场楼层个性化提升100%+。
大促带来的巨大收益,给整个系统带来很正面的影响,后续推荐架构又面临更多的需求与挑战:
- 日益增长的资源位、直播、图像等场景和类型;
- 跟美的融合,跨团队跨地域的挑战;
- 工程算法用一套代码,整个策略的开发调试都非常复杂,包括工程部分的职责不清问题;
- 由于原来模板化的配置,导致一些简单场景复杂化。
针对这些问题,我们需要做的事情就是通用化、平台化。针对整套系统进行统一推荐方案,自动化整体算法对接核心业务流程、以及和算法人员的职责划分清晰,提升双方的工作效率。
3.0时期推荐架构
3.0时期推荐架构 (2016.2~now)与搜索架构类似,系统间职能更加明晰,统一和平台化,主要还是投放层做了改造。
3.0时期推荐架构投放层细节
如上图, 3.0时期推荐架构投放层重要的概念就是场景化,场景应对推荐业务,不同场景会对应不同的策略实现。