爬取腾讯招聘信息-Beautiful Soup
---------------------------------------
============================================
===========================================================

================================================
===================================================
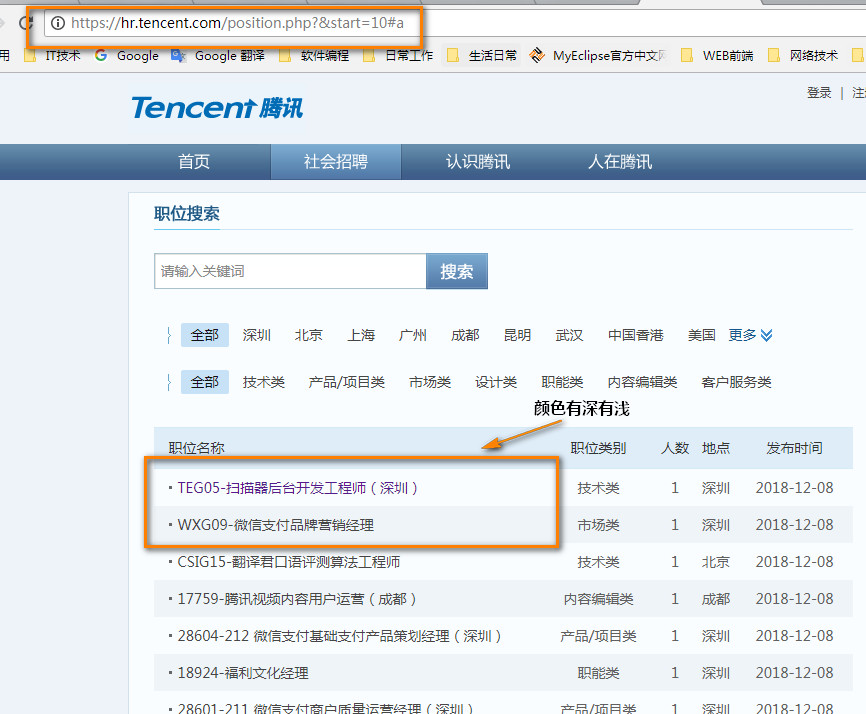
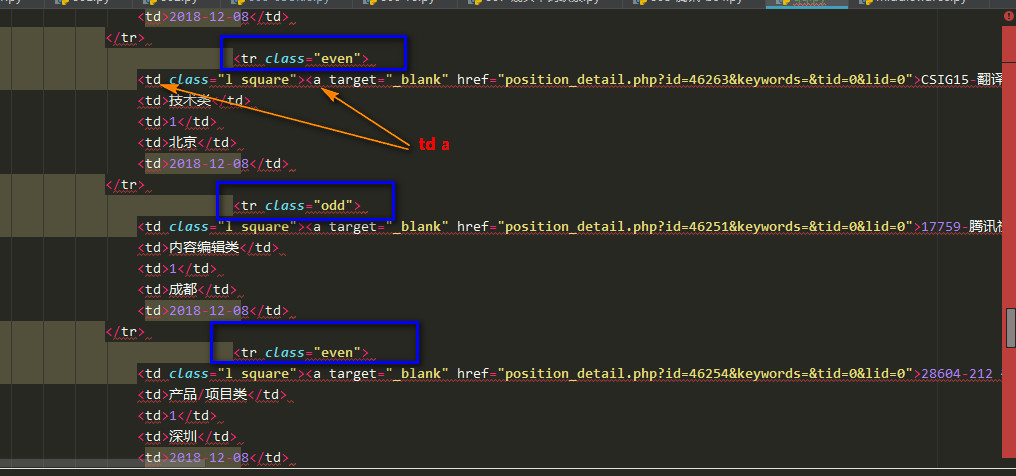
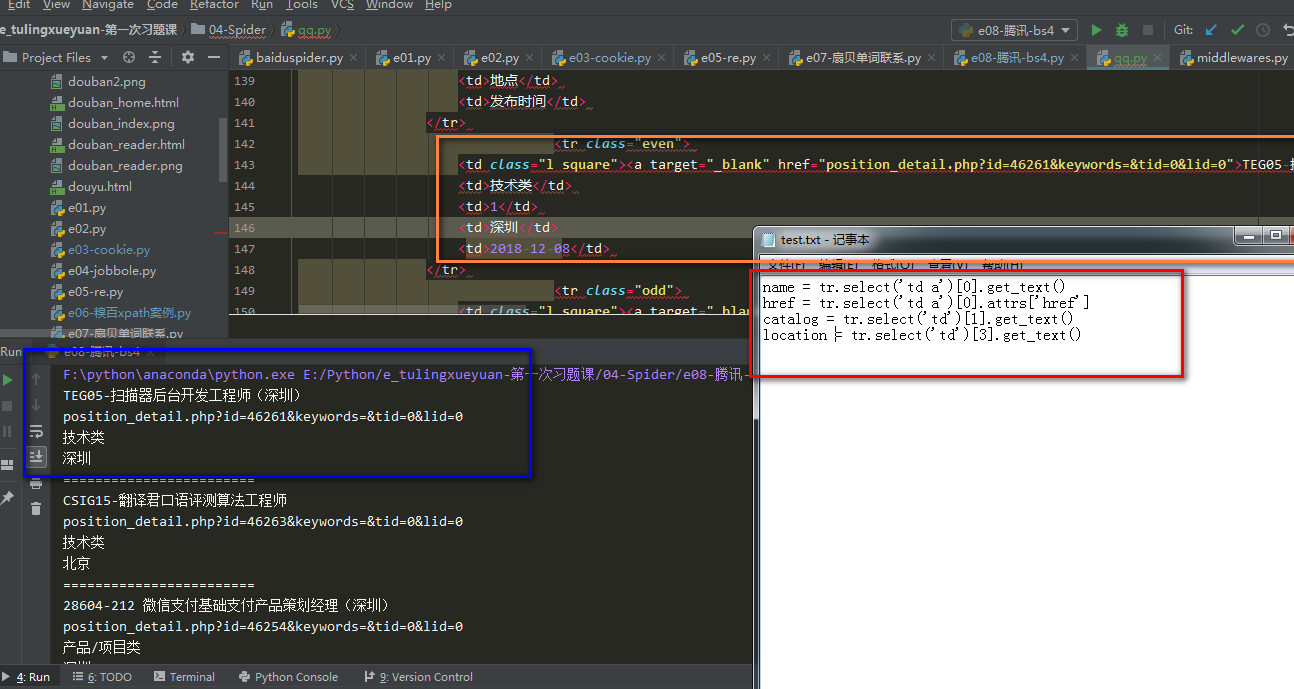
1 ''' 2 爬取腾讯招聘的网站 https://hr.tencent.com/position.php?&start=10#a 3 4 ''' 5 6 from bs4 import BeautifulSoup 7 from urllib import request 8 9 10 11 def qq(): 12 # 获取页面 13 url = 'https://hr.tencent.com/position.php?&start=10#a' 14 rsp = request.urlopen(url) 15 html = rsp.read() 16 17 18 # 提取数据 19 # 用bs解析,lxml驱动 20 soup = BeautifulSoup(html, 'lxml') 21 22 # 创建css选择器,得到相应的tags,even/odd,奇数偶数行,一行一个岗位信息,trs = tr1 + tr2 得到所有岗位信息 23 tr1 = soup.select("tr[class='even']") 24 tr2 = soup.select("tr[class='odd']") 25 trs = tr1 + tr2 26 27 for tr in trs: 28 name = tr.select('td a')[0].get_text() 29 print(name) 30 href = tr.select('td a')[0].attrs['href'] 31 print(href) 32 catalog = tr.select('td')[1].get_text() 33 print(catalog) 34 location = tr.select('td')[3].get_text() 35 print(location) 36 print("==" * 12) 37 38 if __name__ == '__main__': 39 qq()