图像检索与相关应用
一。基于内容的图像检索

分开展开:
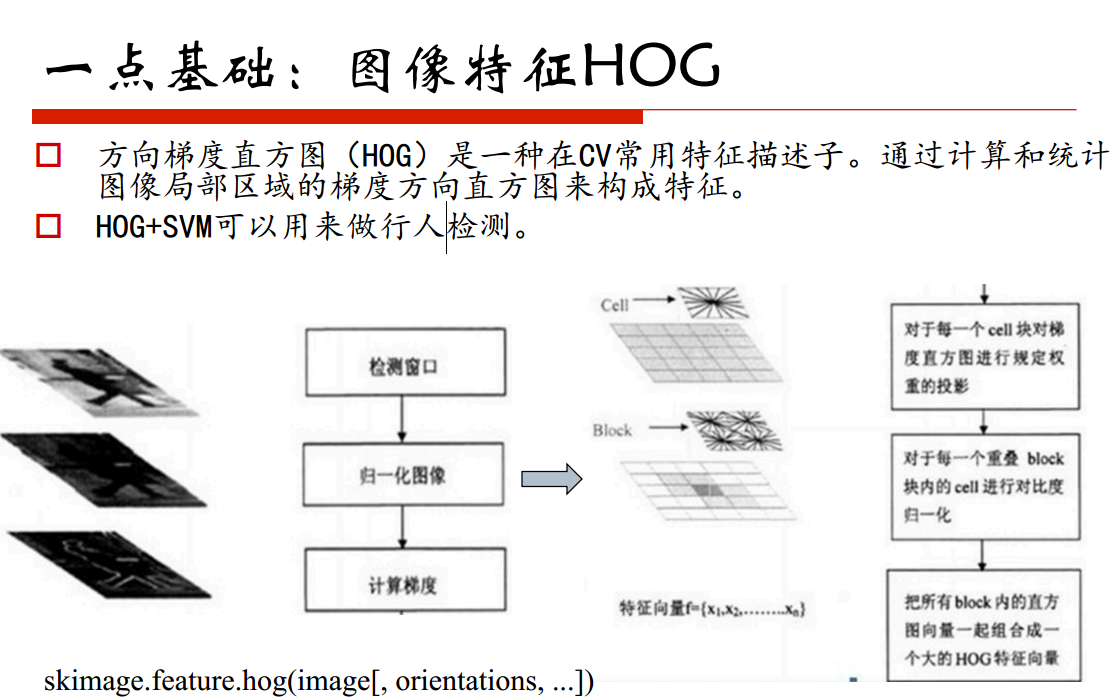
HOG
SIFT:

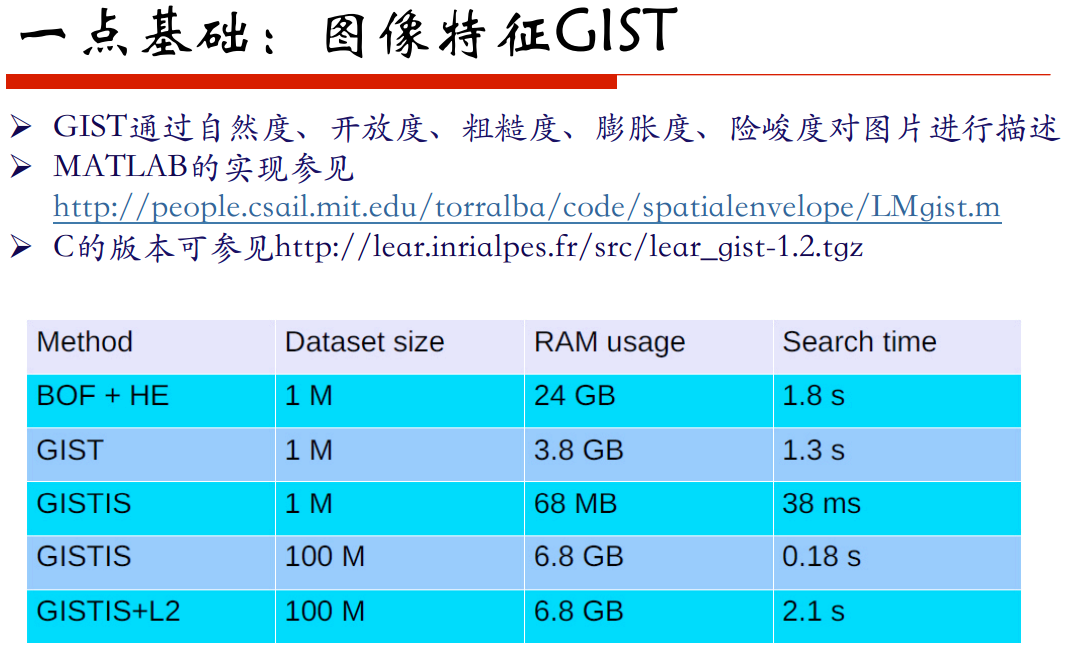
GIST:
CNN:

最近邻问题:
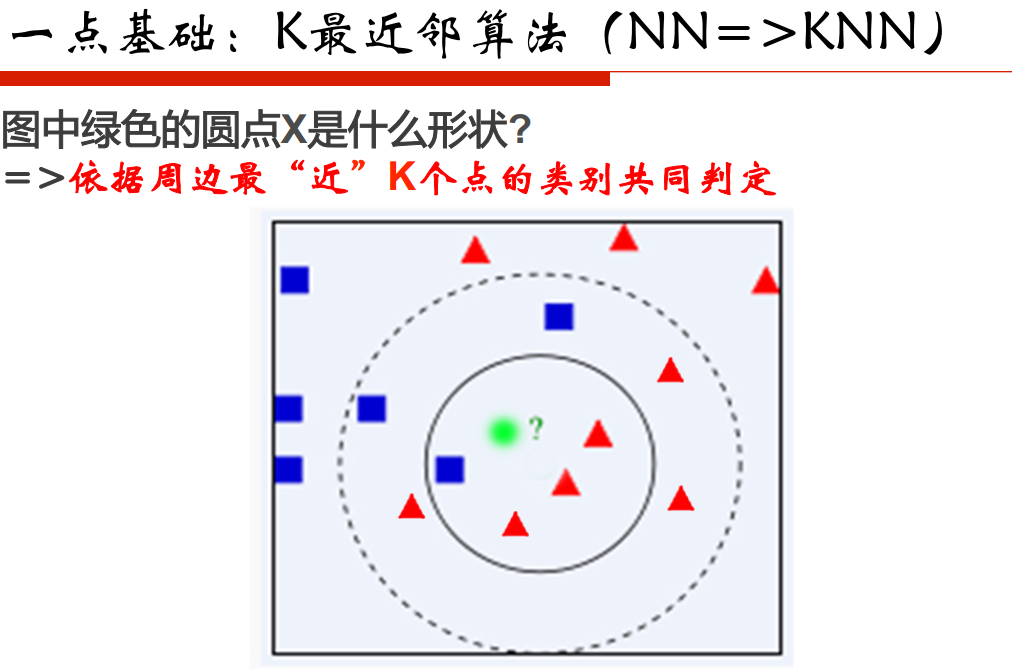


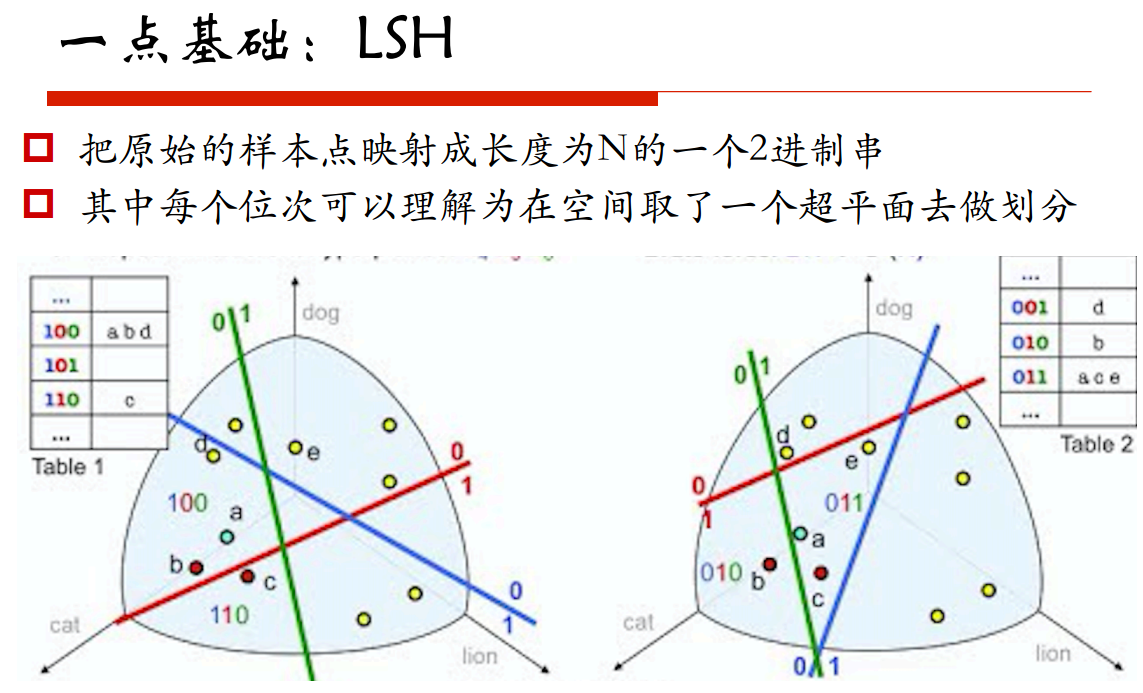
局部敏感的哈希:在高维空间和低维空间去保持距离


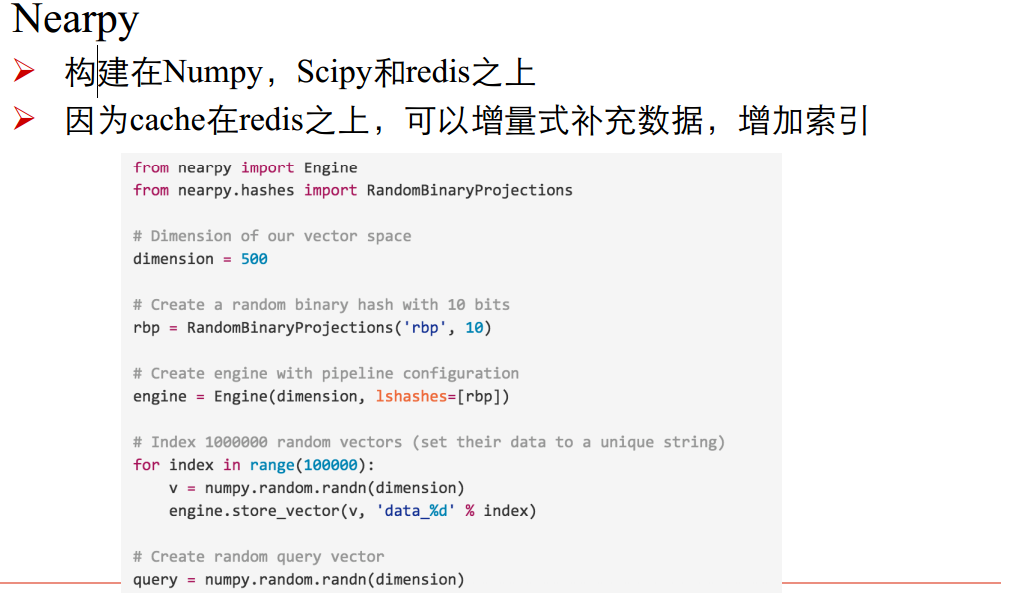
ANN库:



串起来完成一个CBIR系统,进行分类。
二。 如何去让我们的CBIR系统更快?
卷积神经网络进行找到图像的去处?
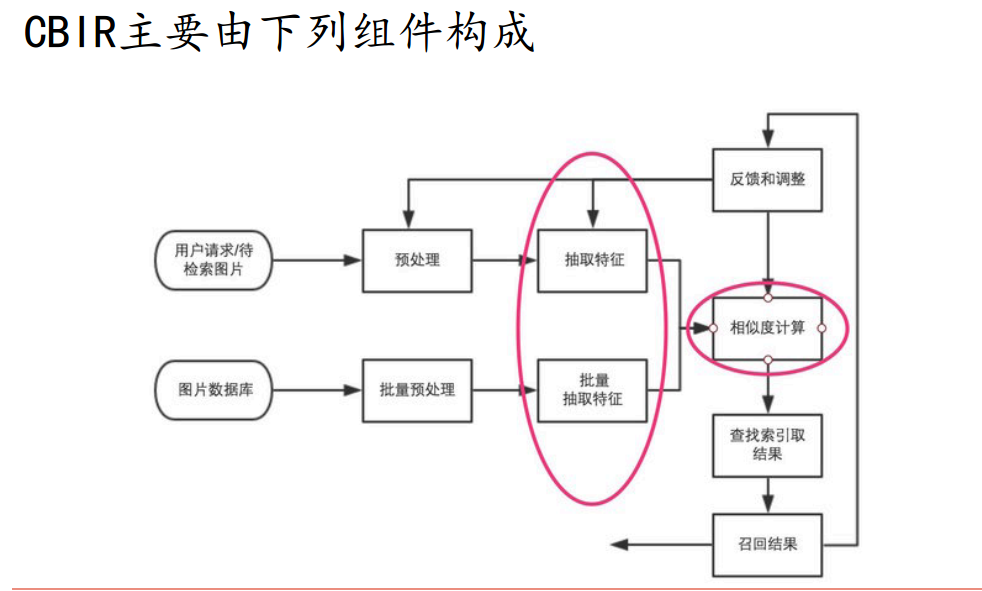
图像检索过程简单说来就是对图片数据库的每张图片抽取特征(一般形式为特征向量),存储于数据库中,对于待检索图片,抽取同样的特征向量,然后并对该向量和数据库中向量的距离,找出最接近的一些特征向量,其对应的图片即为检索结果。
基于内容的图像检索系统最大的难点在上节已经说过了,其一为大部分神经网络产出的中间层特征维度非常高,比如Krizhevsky等的在2012的ImageNet比赛中用到的AlexNet神经网,第7层的输出包含丰富的图像信息,但是维度高达4096维。4096维的浮点数向量与4096维的浮点数向量之间求相似度,运算量较大,因此Babenko等人在论文Neural codes for image retrieval中提出用PCA对4096维的特征进行PCA降维压缩,然后用于基于内容的图像检索,此场景中效果优于大部分传统图像特征。同时因为高维度的特征之间相似度运算会消耗一定的时间,因此线性地逐个比对数据库中特征向量是显然不可取的。大部分的ANN技术都是将高维特征向量压缩到低维度空间,并且以01二值的方式表达,因为在低维空间中计算两个二值向量的汉明距离速度非常快,因此可以在一定程度上缓解时效问题。ANN的这部分hash映射是在拿到特征之外做的,本系统框架试图让卷积神经网在训练过程中学习出对应的『二值检索向量』,或者我们可以理解成对全部图先做了一个分桶操作,每次检索的时候只取本桶和临近桶的图片作比对,而不是在全域做比对,以提高检索速度。
论文是这样实现『二值检索向量』的:在Krizhevsky等2012年用于ImageNet中的卷积神经网络结构基础上,在第7层(4096个神经元)和output层之间多加了一个隐层(全连接层)。隐层的神经元激励函数,可以选用sigmoid,这样输出值在0-1之间值,可以设定阈值(比如说0.5)之后,将这一层输出变换为01二值向量作为『二值检索向量』,这样在使用卷积神经网做图像分类训练的过程中,会『学到』和结果类别最接近的01二值串,也可以理解成,我们把第7层4096维的输出特征向量,通过神经元关联压缩成一个低维度的01向量,但不同于其他的降维和二值操作,这是在一个神经网络里完成的,每对图片做一次完整的前向运算拿到类别,就产出了表征图像丰富信息的第7层output(4096维)和代表图片分桶的第8层output(神经元个数自己指定,一般都不会很多,因此维度不会很高)。
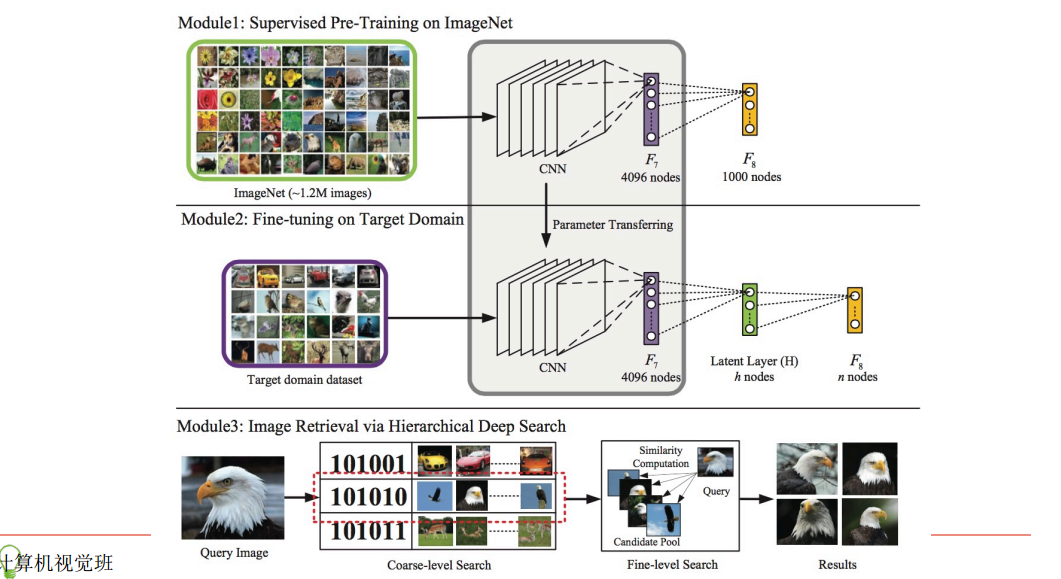
上方图为ImageNet比赛中使用的卷积神经网络;中间图为调整后,在第7层和output层之间添加隐层(假设为128个神经元)后的卷积神经网络,我们将复用ImageNet中得到最终模型的前7层权重做fine-tuning,得到第7层、8层和output层之间的权重。下方图为实际检索过程,对于所有的图片做卷积神经网络前向运算得到第7层4096维特征向量和第8层128维输出(设定阈值0.5之后可以转成01二值检索向量),对于待检索的图片,同样得到4096维特征向量和128维01二值检索向量,在数据库中查找二值检索向量对应『桶』内图片,比对4096维特征向量之间距离,做重拍即得到最终结果。图上的检索例子比较直观,对于待检索的"鹰"图像,算得二值检索向量为101010,取出桶内图片(可以看到基本也都为鹰),比对4096维特征向量之间距离,重新排序拿得到最后的检索结果。
可参考去一下:
Ø 可参考《基于deep learning的快速图像检索系统》
http://blog.csdn.net/han_xiaoyang/article/details/50856583
Ø https://github.com/HanXiaoyang/image_retrieval
三。项目:
怎样针对电商做图像检测?