对误差分类
问题一、什么是偏差和方差?
先看下面这幅图图:
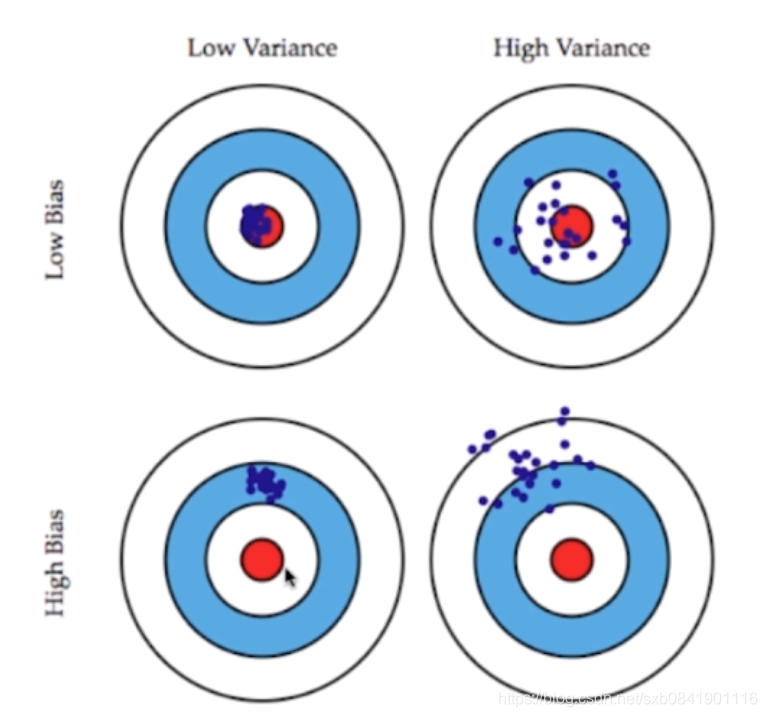
方差: 都是围着数据中心的,方差越大则表示距离数据中心分布的越分散,越小说明越近越集中
偏差: 偏离数据中心, 偏差越大,说明整个数据距离中心越远,偏差越小,说明距离数据中心越近。
这两者的关系通常是矛盾的,降低偏差会提高方差,降低方差会提高偏差。所有一个好的模型就是对这点的一个平衡。
二、模型误差来自于哪些?
模型误差 = 偏差(Bias)+ 方差(Variance) + 不可避免的误差
造成偏差的原因:
1、对本身问题的假设不正确 (比如:非线性数据使用模型回归)
2、选取的特征不对(比如评估学生的成绩选用的名字)
造成方差的原因:
1、数据的一点点抖动
2、通常情况,模型比较复杂(高阶线性回归)
三、哪些算法是高方差,哪些算法是高偏差?
3.1 有一些算法天生是高方差的算法,如KNN,因为KNN对数据的抖动比较明显
3.2 非参数学习通常都是高方差算法,因为不对数据进行任何假设
3.3 有一些算法天生是高偏差算法,比如线性回归。
3.4 参数学习通常是高偏差算法,因为堆数据有很强的假设。
问题四、在机器学习领域,主要学习的挑战主要来自于方差。那么如何降低方差呢?
4.1 降低模型的复杂度
4.2 降低数据维度,降噪
4.3 增加样本 (针对于多参数情况)
4.4 使用验证集
4.5 模型的正则化
问题五、什么是模型正则化(Regularization)?
问题五、什么是模型正则化(Regularization)?
首先我们看一下过拟合的曲线。 存在过拟合也就意味着特征值的前面参数可能过大。 为了避免这种情况,那么在模型训练的时候可以通过一些手段对于参数进行一些限制。 模型正则化就是要做这个事情,通过一些方法限制参数的大小。 换句话说,使某些系数的估计为0。主要用来解决 多重共线性问题(参数相关)
主要收缩方法主要包括 岭回归(ridge regression)和 LASSO回归
问题六、什么是岭回归?
首先看过拟合的情况:
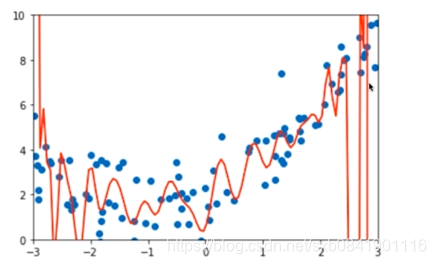
我们知道这种情况是由于过拟合,也就是计算的theta参数太大了。那我们自然就想到如何让theta的取值最小。 简单的办法就是让所有theta的平方和最小。损失函数有如下变化:

通过上面公式可以看出,就是在原来基础上添加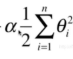 这部分函数。这种方式叫岭回归。 这个函数一般称为惩罚函数, 其中 alpha是一个超参数,这个参数越大就表示惩罚函数在目标函数中占得比例越大。
这部分函数。这种方式叫岭回归。 这个函数一般称为惩罚函数, 其中 alpha是一个超参数,这个参数越大就表示惩罚函数在目标函数中占得比例越大。
至于为什么要加入这个项,这里面涉及到一些线性代数的知识,大家可以参考下面文章。
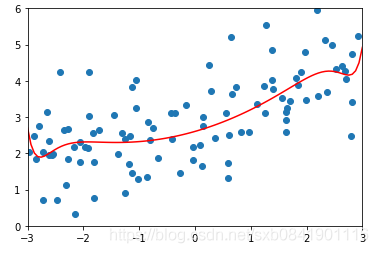
![]() 分别取0.0001, 1, 100的图形如下(从左到右):
分别取0.0001, 1, 100的图形如下(从左到右):
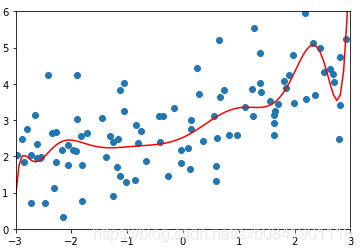
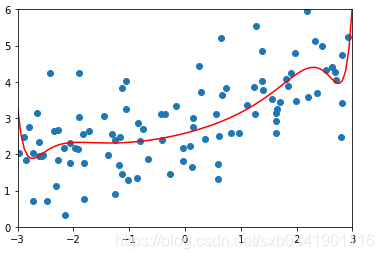
可以看出随着![]() 值越大,曲线越来越平滑。那么这个值多少是合适呢,这个要结合实际的数据看。一般而言,岭回归的参数在0.0001~1之间。在sklearn中默认的是1
值越大,曲线越来越平滑。那么这个值多少是合适呢,这个要结合实际的数据看。一般而言,岭回归的参数在0.0001~1之间。在sklearn中默认的是1
问题七、什么是LASSO回归?
什么是LASSO回归?
首先LASSO是Least Absolute Shrinkage and Selection Operator的缩写。 相对于岭回归的公式:
![]()
在岭回归的惩罚函数是均方差,而LASSO回归是绝对值。 岭回归就是调整参数前面的参数, 而LASSO回归就直接把引起共线的变量前面的参数设置为0. 对比岭回归:
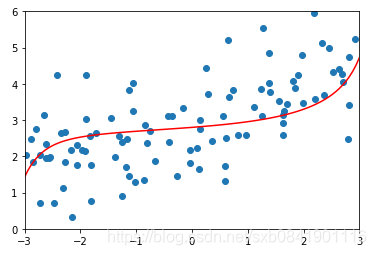
可以看到,Lasso回归最终会趋于一条直线,原因就在于好多θ值已经均为0,而岭回归却有一定平滑度,因为所有的θ值均存在。
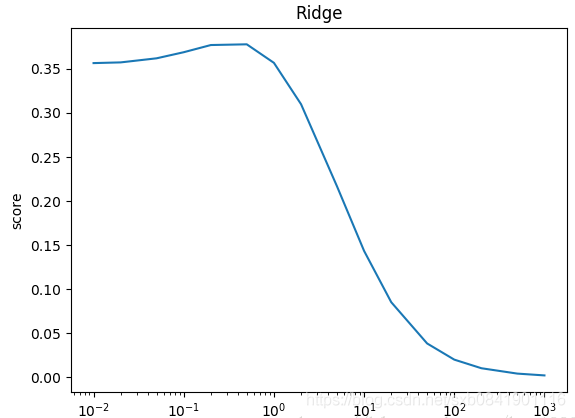
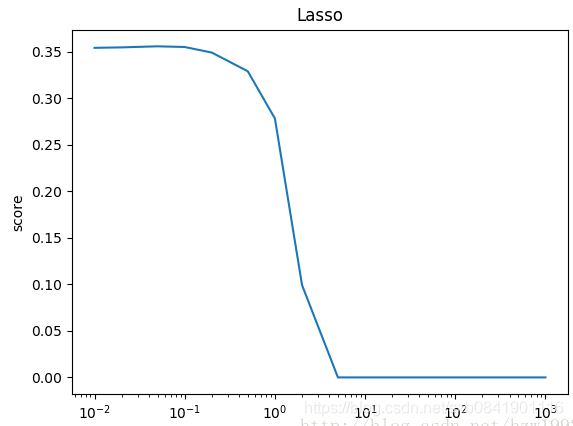
![]() 分别取0.01, 0.1, 1的图形如下(从左到右):
分别取0.01, 0.1, 1的图形如下(从左到右):
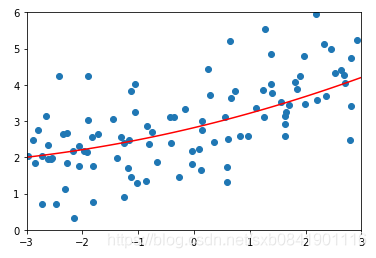
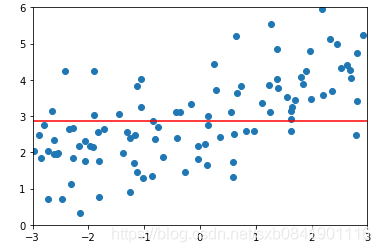
可以看出在LASSO回归中,![]() 取值一般偏小,mean_squared_error最小的时候在0.01.
取值一般偏小,mean_squared_error最小的时候在0.01.
问题八、LP范数与岭回归、LASSO回归有什么联系?
表达形式: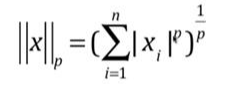 ,其中X是矩阵, 前面就是X的模。
,其中X是矩阵, 前面就是X的模。
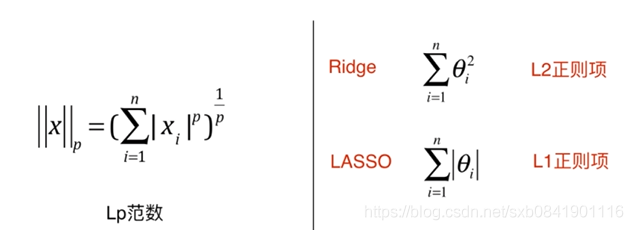
如果把这两种结合起来,就是弹性网, ElasticNet
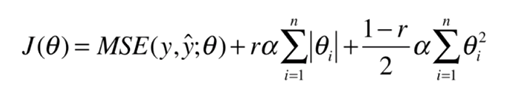
在实际应用中,一般首先尝试L2正则项, 但如果特征量太大了,那么计算会比较复杂,这个时候考虑使用弹性网。最后考虑LASSO,因为LASSO会把一些参数设置为0,容易形成计算错误,导致我们漏掉了一些重要的参数。
参考文章: