AI系统构建流程2
首先,我们要弄清楚解决的是什么问题,然后针对这个问题去进行技术的预研究,预研的过程有可能需要反复修改问题。这两步都确定下来之后要开始收集数据、训练模型,去做相应的功能开发,最后进行产品化,产品化之后还要上线迭代,迭代过程中可能会产生问题,需要重新去构建模型开发。
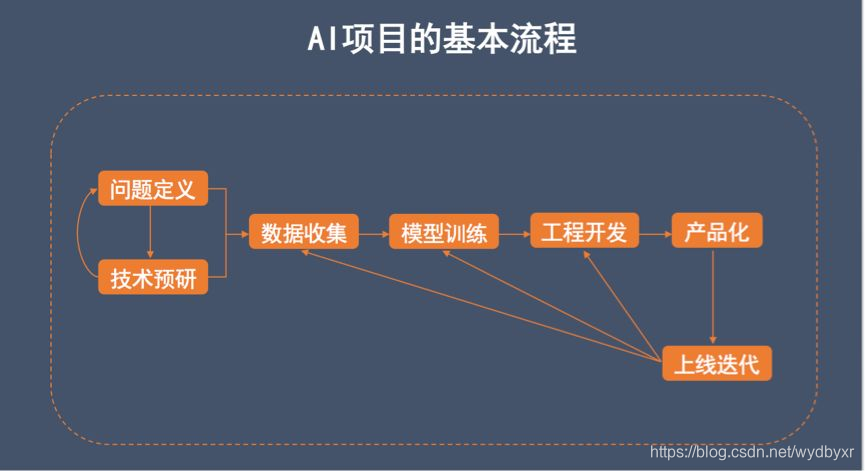
1. 问题定义:从产品出发,数据 A 到数据 B
现在大家讲到 AI 可能更多谈到的是深度学习技术里面的监督式学习技术,这类技术解决的问题就是把数据 A 映射到数据 B。比如人脸识别技术中,数据 A 是人脸图片,数据 B 就是这个人的 ID。这个问题就是要解决,通过人脸图片怎么知道这个人是谁。
现在所有的 AI 项目大概都可以归纳成这样一个问题。所以,首先要搞清楚数据 A 和数据 B 分别是什么。同时要从产品本身的需求出发,明确产品需要做到什么样的程度,比如门禁系统的人脸识别和手机上的人脸识别,数据、限定条件等都是有差别的,两个产品对技术的要求也是不一样的。
2. 技术预研:数据复杂度、关系复杂度与数据量
解决问题定义之后,我们就会去做一些技术调研,确定现代技术的边界在哪里,包括什么技术是能做的,能做到什么程度,以及做到这个程度需要多少代价。
3. 数据收集
首先,数据量需要充足。
接下来,数据质量很重要。要对收集到的数据做标记,如果数据上有大量的标记错误,这个数据基本上就没法用,所以需要进行数据清洗,一遍遍地进行数据纠错,提升数据质量。
数据分布也很重要,必须满足产品要求的所有应用场景。比如,人脸识别如果需要识别侧脸,那么数据当中就需要有足够的侧脸数据,否则分布就不够好。
4. 模型训练:准确评价模型
数据准备好以后,就进入训练模型的环节。这里的关键是你怎么去评价这个模型。
首先,测试集的设计非常重要,测试模型用的数据和用来训练模型的数据必须是完全分开的,测试时一定要用模型没看过的数据去检验这个算法做得好不好。
测试数据的选择也是非常重要的,不同的测试数据有可能导致你检验的结果完全相反,所以这个设计必须以产品要求的应用作为出发点,就是需要涵盖哪些不同的 CASE,针对每个 CASE 都要有一些不同的测量数据,最后才能得出结论,这个技术是不是能够满足产品需求。
另外模型设计也需要考虑性能要求,比如是在手机上线,还是在一个后端服务器上线,两者对计算资源的消耗要求不一样。手机上可消耗的资源会受到限制,那么模型就要做得非常小。
5. 工程开发:基础架构保证高性能,辅助算法完成最后 10%
模型训练后、产品上线前,还需要有一定辅助的工程。比如在后端上线,要有一个基础的深度学习特定集群,一般都是 CPU 集群。如果是在手机端上线,需要在手机上有一个引擎,像快手自己开发的 YCNN 引擎就是属于这种基础架构,对模型和技术的性能有着很大影响。
另一方面,除了 AI 升级的算法本身,一些传统算法的辅助也非常必要。例如 AlphaGo,大家通常知道这是深度学习的成果,其实也结合了例如蒙特卡洛树搜索之类的传统算法才能达到它当时的成绩。很多时候解决问题,除了深度学习提供的模式识别能力,还要依赖推理、搜索等其他能力的辅助。
6. 产品化:好的产品能化腐朽为神奇
工程开发结束就可以产品化了,一个好的产品设计是可以化腐朽为神奇的。很多技术有时并没达到一个非常好的状态,但可以用一些好的设计去规避技术缺点,发挥技术的长处。这个流程可能是在最后阶段,但是实际用户体验设计在问题定义的时候就已经开始了。
7. 版本迭代:持续改进
产品上线后,还需要对版本进行迭代,修复上线过程中发现的一些问题。这里需要强调的一点还是数据,数据占据了 AI 项目大概四分之三以上的时间。上线以后第一时间就要开始收集数据,因为这才是用户在使用时候的数据,是最贴合应用场景的数据,所以也是最重要的数据。