这次爬取一点有意思的东西,爬豆瓣美女网站
1.爬取目标
这次爬虫比较简单,先只爬取豆瓣美女网站中的“大胸妹”tab,而且只爬取最外层的图片,不点开图集,如下

2.分析网页元素
网页源码如下
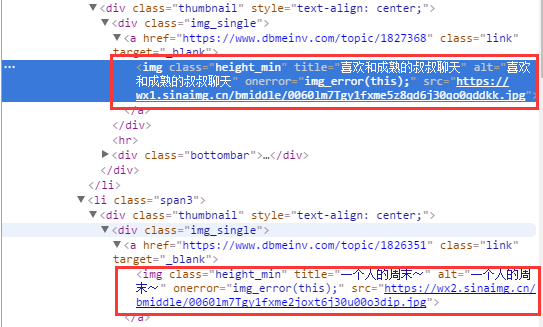
可以看到很明显的规律,每个图片都包裹在<img>标签中,而且title属性代表名称,src属性代表图片url
所以本次爬虫就提取上述2个元素:alt和src
可以用BeautifulSoup或者正则表达式进行提取
3.爬取过程
先贴出完整代码,再进行分析
# -*- coding:utf-8 -*- import requests from requests.exceptions import RequestException from bs4 import BeautifulSoup import bs4 import os def get_html(url, header=None): """请求初始url""" response = requests.get(url, headers=header) try: if response.status_code == 200: # print(response.status_code) # print(response.text) return response.text return None except RequestException: print("请求失败") return None def parse_html(html, list_data): """提取img的名称和图片url,并将名称和图片地址以字典形式返回""" soup = BeautifulSoup(html, 'html.parser') img = soup.find_all('img') for t in img: if isinstance(t, bs4.element.Tag): # print(t) name = t.get('alt') img_src = t.get('src') list_data.append([name, img_src]) dict_data = dict(list_data) return dict_data def get_image_content(url): """请求图片url,返回二进制内容""" print("正在下载", url) try: r = requests.get(url) if r.status_code == 200: return r.content return None except RequestException: return None def main(num=None, depth=None): base_url = 'https://www.dbmeinv.com/index.htm?' for i in range(1, depth): url = base_url + 'cid=' + str(num) + '&' + 'pager_offset=' + str(i) # print(url) header = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q = 0.9, image/webp,image/apng,*/*;q=' '0.8', 'Accept-Encoding': 'gzip,deflate,br', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Cache-Control': 'max-age=0', 'Connection': 'keep-alive', 'Host': 'www.dbmeinv.com', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0(WindowsNT6.1;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/' '70.0.3538.102Safari/537.36 ' } list_data = [] html = get_html(url) # print(html) dictdata = parse_html(html, list_data) # print(list_data) # print(dict(list_data)) # print(data) # for url in data.values(): # download_image(url) root_dir = os.path.dirname(os.path.abspath('.')) save_path = root_dir + '/pics/' for t in dictdata.items(): file_path = '{0}/{1}.{2}'.format(save_path, t[0], 'jpg') if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取 with open(file_path, 'wb') as f: f.write(get_image_content(t[1])) f.close() print('文件保存成功') if __name__ == '__main__': # t = main(2) # print(t) # 这样打印之所以为None,是因为main函数中没有任何内容返回出来,尴尬了。。。 main(2, 10)
(1)构造url
“大胸妹”首页url为:https://www.dbmeinv.com/index.htm?cid=2
翻到下一页后,变为:https://www.dbmeinv.com/index.htm?cid=2&pager_offset=2
可以看到有2个参数cid和pager_offset
所在在主函数中,定义了2个参数,一个表示“大胸妹”对应的cid值,一个表示翻页
def main(num=None, depth=None): base_url = 'https://www.dbmeinv.com/index.htm?' for i in range(1, depth): url = base_url + 'cid=' + str(num) + '&' + 'pager_offset=' + str(i)
(2)分析parse_html()方法
这个方法用来提取图片的title和src,使用的是BeautifulSoup;
传入2个参数,一个是初始url的返回内容,另外定义了一个list_data这里表示一个列表,会把提取到的title和src,以[title:src]的形式追加到list_data中;
然后再把list_data转换为字典返回出去,这样就得到了一个以title为键,以src为值的字典。
后面可以通过迭代这个字典,在保存图片时,使用图片的title作为图片名称
打印list_data和dict_data分别如下


(3)根据parse_html()方法得到图片url后,还需要进一步请求图片url,并将返回的二进制内容以jpg的格式进行保存
首先定义了一个get_image_content()方法,它与get_html()方法一样,不过是返回的二进制内容
然后就是主函数中构造图片保存的形式了:
因为parse_html()方法返回了dict_data,它是以title为键,以src为值的字典,
我们知道迭代字典,可以得到一个键值对组成的元组,如下:

所以可以通过迭代这个字典,分别提取字典的键作为图片名称,提取字典值作为图片url进行请求,如下:
root_dir = os.path.dirname(os.path.abspath('.')) save_path = root_dir + '/pics/' for t in dictdata.items(): file_path = '{0}/{1}.{2}'.format(save_path, t[0], 'jpg') if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取 with open(file_path, 'wb') as f: f.write(get_image_content(t[1])) f.close() print('文件保存成功')
t[0]表示每个键值对的键,即图片的title;t[1]表示每个键值对的值,即图片的url
最终保存的图片如下
