文章目录
索引的创建和删除
建表时创建索引
create table user (
name VARCHAR(20) ,
sex BOOLEAN ,
[UNIQUE][FULLTEXT][PRIMARY KEY]INDEX index_name(id)
);
给已存在的表创建索引
1.添加PRIMARY KEY(主键索引)
ALTER TABLEtable_nameADD PRIMARY KEY (column)
2.添加UNIQUE(唯一索引)
ALTER TABLEtable_nameADD UNIQUE (column)
3.添加INDEX(普通索引)
ALTER TABLEtable_nameADD INDEX index_name (column)
4.添加FULLTEXT(全文索引)
ALTER TABLEtable_nameADD FULLTEXT (column)
5.添加多列索引
ALTER TABLEtable_nameADD INDEX index_name (column1,column2,column3)
删除索引
alter table table_name drop index_name
索引的分类
普通索引 :没有任何限制条件,可以给任何类型的字段创建普通索引
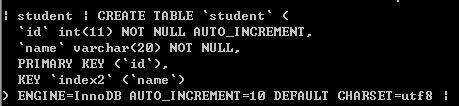
唯一性索引 :使用 UNIQUE 修饰的字段,值不能够重复,主键索引就隶属于唯一性索引
主键索引 :使用 Primary Key 修饰的字段会自动创建索引
单列索引 :在一个字段上创建索引
多列索引 :在表的多个字段上创建索引
全文索引 :使用 FULLTEXT 参数可以设置全文索引,只支持 CAHR,VARCHAR和TEXT类型的字段上。常用于数据量较大的字符串类型上,可以提高查询速度;只有 MyISAM 存储引擎支持
索引的底层结构(以InnoDB的索引结构为例)
B树
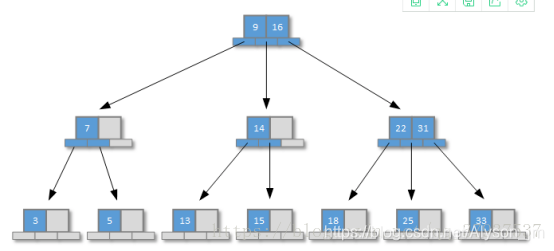
B+树
B树和B+树的区别
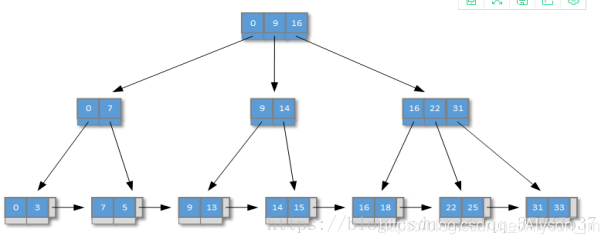
- B+树的所有叶子节点连接到一条链表上
- B树的所有节点不仅要存索引值,还要存索引值所在的行的记录,B+树的非叶子节点只存索引值,只有叶子节点存储索引值和索引所在行的记录。
- B+树的层数较少,查找索引时I/O操作较少
- B树,索引关键字在整个树的每个节点都存在,谁离根节点近,谁搜索的速度就快
- B+索引关键字, 都会出现在叶子节点上,非叶子节点只存关键字,意味着所有的记录都在叶子节点上存储,所有记录搜索的时间是平均的.
数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
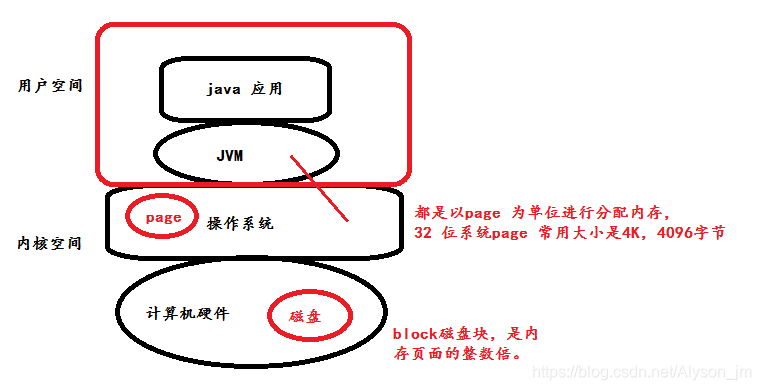
系统底层结构
系统分为用户空间、内核空间两部分。
用户空间通过操作系统来控制计算机硬件中的磁盘来读取数据,计算机硬件和操作系统之间数据传输是以块为单位的,操作系统和用户空间是以页来传输数据,块为页的倍数。
SQL 的查表操作
- 检查where条件字段有没有创建过索引,从磁盘上加载索引文件(以块为单位)到内存上(这个过程会产生磁盘I/O,这个就是影响查询最关键的东西)
- 在内存中用索引文件的数据构造一棵二叉树
- 先加载根节点到用户空间,用户空间判断下一个需要加载的节点,从内存中再加载进来。
- 直到找到叶子节点
索引的使用
我们通过一些例子来比使用索引的好处。这是后面例子中用的数据表。
Explain
explain显示了mysql如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。
使用方法,在select语句前加上explain就可以了
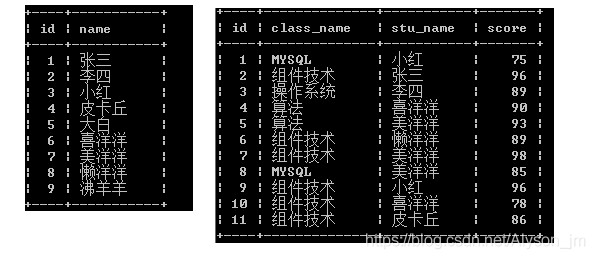
没有索引查询
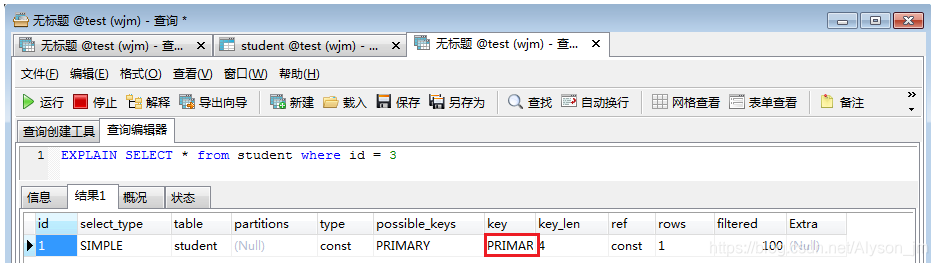
初始时,表里只有三条数据,上面row = 3,表示当前查询为全表查询。key = null,没有使用索引。
有索引查询
ID 为主键,当前查询用了主键查询,row =1,提高了效率。

给经常作为where过滤条件的字段和分组排序字段创建联合索引
- 根据联合索引的第一个字段进行过滤得到一个结果集
- 结果集已经拍好了序,直接从内存中拿出来,减少了外部排序
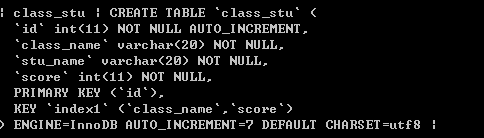
下面这个语句中,class_name 没有创建索引,并且我们按照score排序,rows = 6,它使用了全表遍历,并且使用了外部排序,这非常的耗费资源。
-
按照class_stu进行全表查询,得到一个结果集
-
对结果集进行外部排序
创建联合索引
-
根据索引树得到一个结果集
-
得到的这个结果集已经按照score排好了序。
要使用联合索引,一定要先使用联合索引的第一个字段
虽然score建立了索引,但是它是索引的第二个字段,索引树是按照联合索引的第一个字段建立的,所以SQL选择了全表查询。
内连接查询查询过程
-
Mysql先比较哪个表小,从小表里找到所有的记录
-
去大表里取数据进行比较。
-
大表决定了查询的次数,小表决定了每次循环的查询时间。
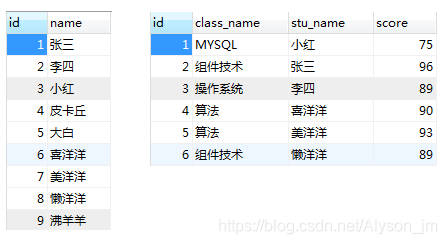
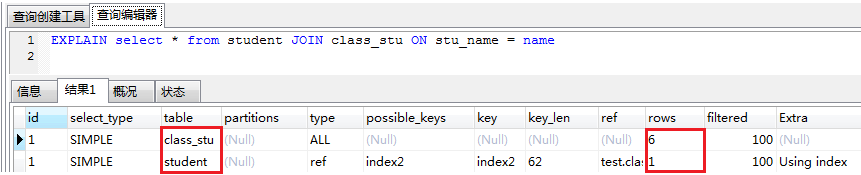
在这个例子中就是先对class_stu 进行全表查询,然后根据class_stu的值去student里一个一个匹配(因为大表student没有加索引)
所以内连接查询在大表里加索引,加快了匹配的效率。
给大表增加索引
加了索引之后大表student 就不是全表查询了,加快了查询效率。- 大表小表也不是绝对的。如果大表有过滤条件,那就判断哪个开销小哪个就是小表,如果大表的过滤条件有加索引,并且过滤掉后的数据比小表还少,那么此时大表就变成了小表。
- 当大表student有过滤条件时,SQL判断student过滤后只有一条数据,就将student作为小表,大表就变成了class_stu.根据student的数据对calss_stu一行一行匹配。
- 给class_stu的stu_name加索引,此时calss_stu 的rows = 3,比原来的rows = 8 来说效率提高了一点。
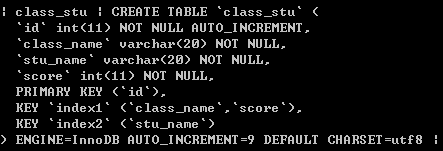
3.左连接查询
左连接查询是把左边的数据全部拿出来,去和右边进行匹配,给右表加索引会增加查询效率。
右表没加索引
给表图加上索引
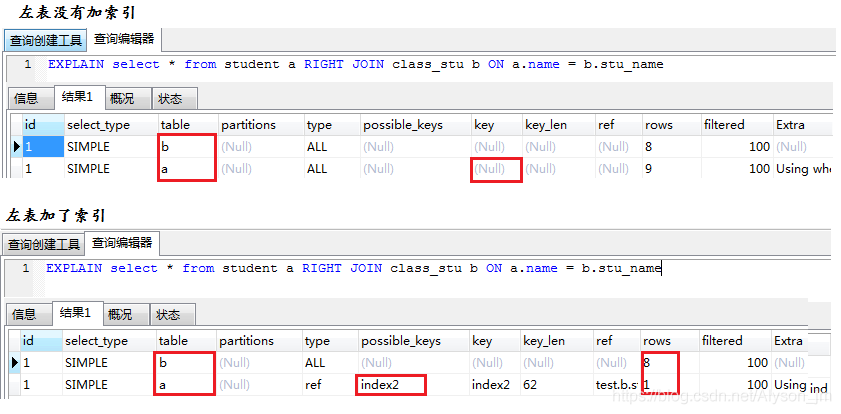
4.右连接查询
右连接查询和左连接查询刚好相反,右边的数据被全部拿出,去和左边的表进行匹配,给左表加索引会增加查询效率。






索引的设计要求
- 给经常作为where过滤条件的字段和分组排序字段创建联合索引。
- 要使用联合索引,一定要先使用联合索引的第一个字段。
- 一般给区分度高的字段创建索引。
- 尤其是对于字符串类型的字段,创建索引的时候可以指定索引的长度,只用字符串的一部分来创建索引数据就可以啦。
- 索引的数目不宜过多
- 使用数据量少的索引(如前缀索引,主要针对字符串类型,字符串类型,尽量创建前缀索引)
- 对于多列索引,优先指定最左边的列集.
使用索引的注意事项
无法使用索引的情况
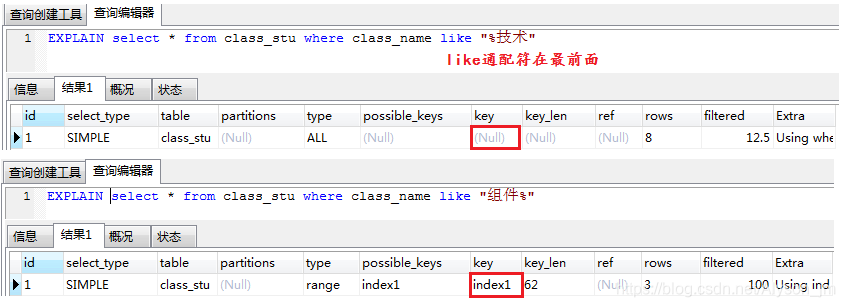
| like “%XXX%” | not in | <> | or |
1、 like通配符放到前面是没有索引的
当通配符在最前面表示前面任意什么字符都可以,根据索引树的结构来说,SQL不知道怎么判断,所以就放弃使用索引。
2、使用not in 无法用到索引
找不在某个集合里面的元素还是要遍历B树里所有的元素,直接全表查询更方便。
3、使用!= 无法用到索引,同理<>也无法用到索引
4、使用or无法用到索引
通过or连接有多个查询条件,一次查询只能用一个索引,即使SQL使用了某个索引,也不可避免的要再进行一次全表查询,降低了效率,所以SQL放弃了使用索引。



索引不宜过多
索引的数据结构是B树,在查询时会增加效率,但是在插入和更新数据的时候会降低效率,得不偿失。
只select需要用到的字段,尽量不要用到
B+树存储的是索引的关键字,除了关键字还有主键值,通过主键值去主键索引树(主键索引树里每个数据项不仅存储主键值,还存储主键对应的行的记录),里面查找需要的记录。
用*查询会先按照索引关键字找到对应的主键值,然后通过主键值进行主键索引,产生了二次索引。
需要查询部分值的时候,可以建立联合索引,将过滤条件用作联合索引的第一个字段。
索引的长度最好限制一下
索引的长度如果太长,每一个节点里存储的索引数就比较少,增加了查找的次数。