沉淀再出发:java中的equals()辨析
一、前言
关于java中的equals,我们可能非常奇怪,在Object中定义了这个函数,其他的很多类中都重载了它,导致了我们对于辨析其中的内涵有了混淆,再加上和“==”的比较,就显得更加的复杂了。
二、java中的equals()
2.1、Object.java中的equals()
让我们来看一下Object.java中的equals()。
首先是Object的定义:


1 /* 2 * Copyright (c) 1994, 2012, Oracle and/or its affiliates. All rights reserved. 3 * ORACLE PROPRIETARY/CONFIDENTIAL. Use is subject to license terms. 4 * 5 * 6 * 7 * 8 * 9 * 10 * 11 * 12 * 13 * 14 * 15 * 16 * 17 * 18 * 19 * 20 * 21 * 22 * 23 * 24 */ 25 26 package java.lang; 27 28 /** 29 * Class {@code Object} is the root of the class hierarchy. 30 * Every class has {@code Object} as a superclass. All objects, 31 * including arrays, implement the methods of this class. 32 * 33 * @author unascribed 34 * @see java.lang.Class 35 * @since JDK1.0 36 */ 37 public class Object { 38 39 private static native void registerNatives(); 40 static { 41 registerNatives(); 42 } 43 44 /** 45 * Returns the runtime class of this {@code Object}. The returned 46 * {@code Class} object is the object that is locked by {@code 47 * static synchronized} methods of the represented class. 48 * 49 * <p><b>The actual result type is {@code Class<? extends |X|>} 50 * where {@code |X|} is the erasure of the static type of the 51 * expression on which {@code getClass} is called.</b> For 52 * example, no cast is required in this code fragment:</p> 53 * 54 * <p> 55 * {@code Number n = 0; }<br> 56 * {@code Class<? extends Number> c = n.getClass(); } 57 * </p> 58 * 59 * @return The {@code Class} object that represents the runtime 60 * class of this object. 61 * @jls 15.8.2 Class Literals 62 */ 63 public final native Class<?> getClass(); 64 65 /** 66 * Returns a hash code value for the object. This method is 67 * supported for the benefit of hash tables such as those provided by 68 * {@link java.util.HashMap}. 69 * <p> 70 * The general contract of {@code hashCode} is: 71 * <ul> 72 * <li>Whenever it is invoked on the same object more than once during 73 * an execution of a Java application, the {@code hashCode} method 74 * must consistently return the same integer, provided no information 75 * used in {@code equals} comparisons on the object is modified. 76 * This integer need not remain consistent from one execution of an 77 * application to another execution of the same application. 78 * <li>If two objects are equal according to the {@code equals(Object)} 79 * method, then calling the {@code hashCode} method on each of 80 * the two objects must produce the same integer result. 81 * <li>It is <em>not</em> required that if two objects are unequal 82 * according to the {@link java.lang.Object#equals(java.lang.Object)} 83 * method, then calling the {@code hashCode} method on each of the 84 * two objects must produce distinct integer results. However, the 85 * programmer should be aware that producing distinct integer results 86 * for unequal objects may improve the performance of hash tables. 87 * </ul> 88 * <p> 89 * As much as is reasonably practical, the hashCode method defined by 90 * class {@code Object} does return distinct integers for distinct 91 * objects. (This is typically implemented by converting the internal 92 * address of the object into an integer, but this implementation 93 * technique is not required by the 94 * Java™ programming language.) 95 * 96 * @return a hash code value for this object. 97 * @see java.lang.Object#equals(java.lang.Object) 98 * @see java.lang.System#identityHashCode 99 */ 100 public native int hashCode(); 101 102 /** 103 * Indicates whether some other object is "equal to" this one. 104 * <p> 105 * The {@code equals} method implements an equivalence relation 106 * on non-null object references: 107 * <ul> 108 * <li>It is <i>reflexive</i>: for any non-null reference value 109 * {@code x}, {@code x.equals(x)} should return 110 * {@code true}. 111 * <li>It is <i>symmetric</i>: for any non-null reference values 112 * {@code x} and {@code y}, {@code x.equals(y)} 113 * should return {@code true} if and only if 114 * {@code y.equals(x)} returns {@code true}. 115 * <li>It is <i>transitive</i>: for any non-null reference values 116 * {@code x}, {@code y}, and {@code z}, if 117 * {@code x.equals(y)} returns {@code true} and 118 * {@code y.equals(z)} returns {@code true}, then 119 * {@code x.equals(z)} should return {@code true}. 120 * <li>It is <i>consistent</i>: for any non-null reference values 121 * {@code x} and {@code y}, multiple invocations of 122 * {@code x.equals(y)} consistently return {@code true} 123 * or consistently return {@code false}, provided no 124 * information used in {@code equals} comparisons on the 125 * objects is modified. 126 * <li>For any non-null reference value {@code x}, 127 * {@code x.equals(null)} should return {@code false}. 128 * </ul> 129 * <p> 130 * The {@code equals} method for class {@code Object} implements 131 * the most discriminating possible equivalence relation on objects; 132 * that is, for any non-null reference values {@code x} and 133 * {@code y}, this method returns {@code true} if and only 134 * if {@code x} and {@code y} refer to the same object 135 * ({@code x == y} has the value {@code true}). 136 * <p> 137 * Note that it is generally necessary to override the {@code hashCode} 138 * method whenever this method is overridden, so as to maintain the 139 * general contract for the {@code hashCode} method, which states 140 * that equal objects must have equal hash codes. 141 * 142 * @param obj the reference object with which to compare. 143 * @return {@code true} if this object is the same as the obj 144 * argument; {@code false} otherwise. 145 * @see #hashCode() 146 * @see java.util.HashMap 147 */ 148 public boolean equals(Object obj) { 149 return (this == obj); 150 } 151 152 /** 153 * Creates and returns a copy of this object. The precise meaning 154 * of "copy" may depend on the class of the object. The general 155 * intent is that, for any object {@code x}, the expression: 156 * <blockquote> 157 * <pre> 158 * x.clone() != x</pre></blockquote> 159 * will be true, and that the expression: 160 * <blockquote> 161 * <pre> 162 * x.clone().getClass() == x.getClass()</pre></blockquote> 163 * will be {@code true}, but these are not absolute requirements. 164 * While it is typically the case that: 165 * <blockquote> 166 * <pre> 167 * x.clone().equals(x)</pre></blockquote> 168 * will be {@code true}, this is not an absolute requirement. 169 * <p> 170 * By convention, the returned object should be obtained by calling 171 * {@code super.clone}. If a class and all of its superclasses (except 172 * {@code Object}) obey this convention, it will be the case that 173 * {@code x.clone().getClass() == x.getClass()}. 174 * <p> 175 * By convention, the object returned by this method should be independent 176 * of this object (which is being cloned). To achieve this independence, 177 * it may be necessary to modify one or more fields of the object returned 178 * by {@code super.clone} before returning it. Typically, this means 179 * copying any mutable objects that comprise the internal "deep structure" 180 * of the object being cloned and replacing the references to these 181 * objects with references to the copies. If a class contains only 182 * primitive fields or references to immutable objects, then it is usually 183 * the case that no fields in the object returned by {@code super.clone} 184 * need to be modified. 185 * <p> 186 * The method {@code clone} for class {@code Object} performs a 187 * specific cloning operation. First, if the class of this object does 188 * not implement the interface {@code Cloneable}, then a 189 * {@code CloneNotSupportedException} is thrown. Note that all arrays 190 * are considered to implement the interface {@code Cloneable} and that 191 * the return type of the {@code clone} method of an array type {@code T[]} 192 * is {@code T[]} where T is any reference or primitive type. 193 * Otherwise, this method creates a new instance of the class of this 194 * object and initializes all its fields with exactly the contents of 195 * the corresponding fields of this object, as if by assignment; the 196 * contents of the fields are not themselves cloned. Thus, this method 197 * performs a "shallow copy" of this object, not a "deep copy" operation. 198 * <p> 199 * The class {@code Object} does not itself implement the interface 200 * {@code Cloneable}, so calling the {@code clone} method on an object 201 * whose class is {@code Object} will result in throwing an 202 * exception at run time. 203 * 204 * @return a clone of this instance. 205 * @throws CloneNotSupportedException if the object's class does not 206 * support the {@code Cloneable} interface. Subclasses 207 * that override the {@code clone} method can also 208 * throw this exception to indicate that an instance cannot 209 * be cloned. 210 * @see java.lang.Cloneable 211 */ 212 protected native Object clone() throws CloneNotSupportedException; 213 214 /** 215 * Returns a string representation of the object. In general, the 216 * {@code toString} method returns a string that 217 * "textually represents" this object. The result should 218 * be a concise but informative representation that is easy for a 219 * person to read. 220 * It is recommended that all subclasses override this method. 221 * <p> 222 * The {@code toString} method for class {@code Object} 223 * returns a string consisting of the name of the class of which the 224 * object is an instance, the at-sign character `{@code @}', and 225 * the unsigned hexadecimal representation of the hash code of the 226 * object. In other words, this method returns a string equal to the 227 * value of: 228 * <blockquote> 229 * <pre> 230 * getClass().getName() + '@' + Integer.toHexString(hashCode()) 231 * </pre></blockquote> 232 * 233 * @return a string representation of the object. 234 */ 235 public String toString() { 236 return getClass().getName() + "@" + Integer.toHexString(hashCode()); 237 } 238 239 /** 240 * Wakes up a single thread that is waiting on this object's 241 * monitor. If any threads are waiting on this object, one of them 242 * is chosen to be awakened. The choice is arbitrary and occurs at 243 * the discretion of the implementation. A thread waits on an object's 244 * monitor by calling one of the {@code wait} methods. 245 * <p> 246 * The awakened thread will not be able to proceed until the current 247 * thread relinquishes the lock on this object. The awakened thread will 248 * compete in the usual manner with any other threads that might be 249 * actively competing to synchronize on this object; for example, the 250 * awakened thread enjoys no reliable privilege or disadvantage in being 251 * the next thread to lock this object. 252 * <p> 253 * This method should only be called by a thread that is the owner 254 * of this object's monitor. A thread becomes the owner of the 255 * object's monitor in one of three ways: 256 * <ul> 257 * <li>By executing a synchronized instance method of that object. 258 * <li>By executing the body of a {@code synchronized} statement 259 * that synchronizes on the object. 260 * <li>For objects of type {@code Class,} by executing a 261 * synchronized static method of that class. 262 * </ul> 263 * <p> 264 * Only one thread at a time can own an object's monitor. 265 * 266 * @throws IllegalMonitorStateException if the current thread is not 267 * the owner of this object's monitor. 268 * @see java.lang.Object#notifyAll() 269 * @see java.lang.Object#wait() 270 */ 271 public final native void notify(); 272 273 /** 274 * Wakes up all threads that are waiting on this object's monitor. A 275 * thread waits on an object's monitor by calling one of the 276 * {@code wait} methods. 277 * <p> 278 * The awakened threads will not be able to proceed until the current 279 * thread relinquishes the lock on this object. The awakened threads 280 * will compete in the usual manner with any other threads that might 281 * be actively competing to synchronize on this object; for example, 282 * the awakened threads enjoy no reliable privilege or disadvantage in 283 * being the next thread to lock this object. 284 * <p> 285 * This method should only be called by a thread that is the owner 286 * of this object's monitor. See the {@code notify} method for a 287 * description of the ways in which a thread can become the owner of 288 * a monitor. 289 * 290 * @throws IllegalMonitorStateException if the current thread is not 291 * the owner of this object's monitor. 292 * @see java.lang.Object#notify() 293 * @see java.lang.Object#wait() 294 */ 295 public final native void notifyAll(); 296 297 /** 298 * Causes the current thread to wait until either another thread invokes the 299 * {@link java.lang.Object#notify()} method or the 300 * {@link java.lang.Object#notifyAll()} method for this object, or a 301 * specified amount of time has elapsed. 302 * <p> 303 * The current thread must own this object's monitor. 304 * <p> 305 * This method causes the current thread (call it <var>T</var>) to 306 * place itself in the wait set for this object and then to relinquish 307 * any and all synchronization claims on this object. Thread <var>T</var> 308 * becomes disabled for thread scheduling purposes and lies dormant 309 * until one of four things happens: 310 * <ul> 311 * <li>Some other thread invokes the {@code notify} method for this 312 * object and thread <var>T</var> happens to be arbitrarily chosen as 313 * the thread to be awakened. 314 * <li>Some other thread invokes the {@code notifyAll} method for this 315 * object. 316 * <li>Some other thread {@linkplain Thread#interrupt() interrupts} 317 * thread <var>T</var>. 318 * <li>The specified amount of real time has elapsed, more or less. If 319 * {@code timeout} is zero, however, then real time is not taken into 320 * consideration and the thread simply waits until notified. 321 * </ul> 322 * The thread <var>T</var> is then removed from the wait set for this 323 * object and re-enabled for thread scheduling. It then competes in the 324 * usual manner with other threads for the right to synchronize on the 325 * object; once it has gained control of the object, all its 326 * synchronization claims on the object are restored to the status quo 327 * ante - that is, to the situation as of the time that the {@code wait} 328 * method was invoked. Thread <var>T</var> then returns from the 329 * invocation of the {@code wait} method. Thus, on return from the 330 * {@code wait} method, the synchronization state of the object and of 331 * thread {@code T} is exactly as it was when the {@code wait} method 332 * was invoked. 333 * <p> 334 * A thread can also wake up without being notified, interrupted, or 335 * timing out, a so-called <i>spurious wakeup</i>. While this will rarely 336 * occur in practice, applications must guard against it by testing for 337 * the condition that should have caused the thread to be awakened, and 338 * continuing to wait if the condition is not satisfied. In other words, 339 * waits should always occur in loops, like this one: 340 * <pre> 341 * synchronized (obj) { 342 * while (<condition does not hold>) 343 * obj.wait(timeout); 344 * ... // Perform action appropriate to condition 345 * } 346 * </pre> 347 * (For more information on this topic, see Section 3.2.3 in Doug Lea's 348 * "Concurrent Programming in Java (Second Edition)" (Addison-Wesley, 349 * 2000), or Item 50 in Joshua Bloch's "Effective Java Programming 350 * Language Guide" (Addison-Wesley, 2001). 351 * 352 * <p>If the current thread is {@linkplain java.lang.Thread#interrupt() 353 * interrupted} by any thread before or while it is waiting, then an 354 * {@code InterruptedException} is thrown. This exception is not 355 * thrown until the lock status of this object has been restored as 356 * described above. 357 * 358 * <p> 359 * Note that the {@code wait} method, as it places the current thread 360 * into the wait set for this object, unlocks only this object; any 361 * other objects on which the current thread may be synchronized remain 362 * locked while the thread waits. 363 * <p> 364 * This method should only be called by a thread that is the owner 365 * of this object's monitor. See the {@code notify} method for a 366 * description of the ways in which a thread can become the owner of 367 * a monitor. 368 * 369 * @param timeout the maximum time to wait in milliseconds. 370 * @throws IllegalArgumentException if the value of timeout is 371 * negative. 372 * @throws IllegalMonitorStateException if the current thread is not 373 * the owner of the object's monitor. 374 * @throws InterruptedException if any thread interrupted the 375 * current thread before or while the current thread 376 * was waiting for a notification. The <i>interrupted 377 * status</i> of the current thread is cleared when 378 * this exception is thrown. 379 * @see java.lang.Object#notify() 380 * @see java.lang.Object#notifyAll() 381 */ 382 public final native void wait(long timeout) throws InterruptedException; 383 384 /** 385 * Causes the current thread to wait until another thread invokes the 386 * {@link java.lang.Object#notify()} method or the 387 * {@link java.lang.Object#notifyAll()} method for this object, or 388 * some other thread interrupts the current thread, or a certain 389 * amount of real time has elapsed. 390 * <p> 391 * This method is similar to the {@code wait} method of one 392 * argument, but it allows finer control over the amount of time to 393 * wait for a notification before giving up. The amount of real time, 394 * measured in nanoseconds, is given by: 395 * <blockquote> 396 * <pre> 397 * 1000000*timeout+nanos</pre></blockquote> 398 * <p> 399 * In all other respects, this method does the same thing as the 400 * method {@link #wait(long)} of one argument. In particular, 401 * {@code wait(0, 0)} means the same thing as {@code wait(0)}. 402 * <p> 403 * The current thread must own this object's monitor. The thread 404 * releases ownership of this monitor and waits until either of the 405 * following two conditions has occurred: 406 * <ul> 407 * <li>Another thread notifies threads waiting on this object's monitor 408 * to wake up either through a call to the {@code notify} method 409 * or the {@code notifyAll} method. 410 * <li>The timeout period, specified by {@code timeout} 411 * milliseconds plus {@code nanos} nanoseconds arguments, has 412 * elapsed. 413 * </ul> 414 * <p> 415 * The thread then waits until it can re-obtain ownership of the 416 * monitor and resumes execution. 417 * <p> 418 * As in the one argument version, interrupts and spurious wakeups are 419 * possible, and this method should always be used in a loop: 420 * <pre> 421 * synchronized (obj) { 422 * while (<condition does not hold>) 423 * obj.wait(timeout, nanos); 424 * ... // Perform action appropriate to condition 425 * } 426 * </pre> 427 * This method should only be called by a thread that is the owner 428 * of this object's monitor. See the {@code notify} method for a 429 * description of the ways in which a thread can become the owner of 430 * a monitor. 431 * 432 * @param timeout the maximum time to wait in milliseconds. 433 * @param nanos additional time, in nanoseconds range 434 * 0-999999. 435 * @throws IllegalArgumentException if the value of timeout is 436 * negative or the value of nanos is 437 * not in the range 0-999999. 438 * @throws IllegalMonitorStateException if the current thread is not 439 * the owner of this object's monitor. 440 * @throws InterruptedException if any thread interrupted the 441 * current thread before or while the current thread 442 * was waiting for a notification. The <i>interrupted 443 * status</i> of the current thread is cleared when 444 * this exception is thrown. 445 */ 446 public final void wait(long timeout, int nanos) throws InterruptedException { 447 if (timeout < 0) { 448 throw new IllegalArgumentException("timeout value is negative"); 449 } 450 451 if (nanos < 0 || nanos > 999999) { 452 throw new IllegalArgumentException( 453 "nanosecond timeout value out of range"); 454 } 455 456 if (nanos > 0) { 457 timeout++; 458 } 459 460 wait(timeout); 461 } 462 463 /** 464 * Causes the current thread to wait until another thread invokes the 465 * {@link java.lang.Object#notify()} method or the 466 * {@link java.lang.Object#notifyAll()} method for this object. 467 * In other words, this method behaves exactly as if it simply 468 * performs the call {@code wait(0)}. 469 * <p> 470 * The current thread must own this object's monitor. The thread 471 * releases ownership of this monitor and waits until another thread 472 * notifies threads waiting on this object's monitor to wake up 473 * either through a call to the {@code notify} method or the 474 * {@code notifyAll} method. The thread then waits until it can 475 * re-obtain ownership of the monitor and resumes execution. 476 * <p> 477 * As in the one argument version, interrupts and spurious wakeups are 478 * possible, and this method should always be used in a loop: 479 * <pre> 480 * synchronized (obj) { 481 * while (<condition does not hold>) 482 * obj.wait(); 483 * ... // Perform action appropriate to condition 484 * } 485 * </pre> 486 * This method should only be called by a thread that is the owner 487 * of this object's monitor. See the {@code notify} method for a 488 * description of the ways in which a thread can become the owner of 489 * a monitor. 490 * 491 * @throws IllegalMonitorStateException if the current thread is not 492 * the owner of the object's monitor. 493 * @throws InterruptedException if any thread interrupted the 494 * current thread before or while the current thread 495 * was waiting for a notification. The <i>interrupted 496 * status</i> of the current thread is cleared when 497 * this exception is thrown. 498 * @see java.lang.Object#notify() 499 * @see java.lang.Object#notifyAll() 500 */ 501 public final void wait() throws InterruptedException { 502 wait(0); 503 } 504 505 /** 506 * Called by the garbage collector on an object when garbage collection 507 * determines that there are no more references to the object. 508 * A subclass overrides the {@code finalize} method to dispose of 509 * system resources or to perform other cleanup. 510 * <p> 511 * The general contract of {@code finalize} is that it is invoked 512 * if and when the Java™ virtual 513 * machine has determined that there is no longer any 514 * means by which this object can be accessed by any thread that has 515 * not yet died, except as a result of an action taken by the 516 * finalization of some other object or class which is ready to be 517 * finalized. The {@code finalize} method may take any action, including 518 * making this object available again to other threads; the usual purpose 519 * of {@code finalize}, however, is to perform cleanup actions before 520 * the object is irrevocably discarded. For example, the finalize method 521 * for an object that represents an input/output connection might perform 522 * explicit I/O transactions to break the connection before the object is 523 * permanently discarded. 524 * <p> 525 * The {@code finalize} method of class {@code Object} performs no 526 * special action; it simply returns normally. Subclasses of 527 * {@code Object} may override this definition. 528 * <p> 529 * The Java programming language does not guarantee which thread will 530 * invoke the {@code finalize} method for any given object. It is 531 * guaranteed, however, that the thread that invokes finalize will not 532 * be holding any user-visible synchronization locks when finalize is 533 * invoked. If an uncaught exception is thrown by the finalize method, 534 * the exception is ignored and finalization of that object terminates. 535 * <p> 536 * After the {@code finalize} method has been invoked for an object, no 537 * further action is taken until the Java virtual machine has again 538 * determined that there is no longer any means by which this object can 539 * be accessed by any thread that has not yet died, including possible 540 * actions by other objects or classes which are ready to be finalized, 541 * at which point the object may be discarded. 542 * <p> 543 * The {@code finalize} method is never invoked more than once by a Java 544 * virtual machine for any given object. 545 * <p> 546 * Any exception thrown by the {@code finalize} method causes 547 * the finalization of this object to be halted, but is otherwise 548 * ignored. 549 * 550 * @throws Throwable the {@code Exception} raised by this method 551 * @see java.lang.ref.WeakReference 552 * @see java.lang.ref.PhantomReference 553 * @jls 12.6 Finalization of Class Instances 554 */ 555 protected void finalize() throws Throwable { } 556 }
其次我们看看其中的函数:


这就是Object中的equals,非常的简单,完全就是比较两个对象的引用是不是同一个内存空间。因此如果直接使用这个equals来比较,使用new创建的对象就不相等了。
1 public boolean equals(Object obj) { 2 return (this == obj); 3 }
比如我们测试:
1 package com.consumer.test; 2 3 public class EqualTest { 4 public static void main(String[] args) { 5 MyTest m1=new MyTest(); 6 MyTest m2=new MyTest(); 7 System.out.println(m1==m2); 8 System.out.println(m1.equals(m2)); 9 } 10 11 } 12 class MyTest{ 13 public MyTest(){ 14 output(); 15 } 16 private void output(){ 17 System.out.println("创建对象成功!"); 18 } 19 }

2.2、String中的equals()
String的定义:
1 /* 2 * Copyright (c) 1994, 2013, Oracle and/or its affiliates. All rights reserved. 3 * ORACLE PROPRIETARY/CONFIDENTIAL. Use is subject to license terms. 4 * 5 * 6 * 7 * 8 * 9 * 10 * 11 * 12 * 13 * 14 * 15 * 16 * 17 * 18 * 19 * 20 * 21 * 22 * 23 * 24 */ 25 26 package java.lang; 27 28 import java.io.ObjectStreamField; 29 import java.io.UnsupportedEncodingException; 30 import java.nio.charset.Charset; 31 import java.util.ArrayList; 32 import java.util.Arrays; 33 import java.util.Comparator; 34 import java.util.Formatter; 35 import java.util.Locale; 36 import java.util.Objects; 37 import java.util.StringJoiner; 38 import java.util.regex.Matcher; 39 import java.util.regex.Pattern; 40 import java.util.regex.PatternSyntaxException; 41 42 /** 43 * The {@code String} class represents character strings. All 44 * string literals in Java programs, such as {@code "abc"}, are 45 * implemented as instances of this class. 46 * <p> 47 * Strings are constant; their values cannot be changed after they 48 * are created. String buffers support mutable strings. 49 * Because String objects are immutable they can be shared. For example: 50 * <blockquote><pre> 51 * String str = "abc"; 52 * </pre></blockquote><p> 53 * is equivalent to: 54 * <blockquote><pre> 55 * char data[] = {'a', 'b', 'c'}; 56 * String str = new String(data); 57 * </pre></blockquote><p> 58 * Here are some more examples of how strings can be used: 59 * <blockquote><pre> 60 * System.out.println("abc"); 61 * String cde = "cde"; 62 * System.out.println("abc" + cde); 63 * String c = "abc".substring(2,3); 64 * String d = cde.substring(1, 2); 65 * </pre></blockquote> 66 * <p> 67 * The class {@code String} includes methods for examining 68 * individual characters of the sequence, for comparing strings, for 69 * searching strings, for extracting substrings, and for creating a 70 * copy of a string with all characters translated to uppercase or to 71 * lowercase. Case mapping is based on the Unicode Standard version 72 * specified by the {@link java.lang.Character Character} class. 73 * <p> 74 * The Java language provides special support for the string 75 * concatenation operator ( + ), and for conversion of 76 * other objects to strings. String concatenation is implemented 77 * through the {@code StringBuilder}(or {@code StringBuffer}) 78 * class and its {@code append} method. 79 * String conversions are implemented through the method 80 * {@code toString}, defined by {@code Object} and 81 * inherited by all classes in Java. For additional information on 82 * string concatenation and conversion, see Gosling, Joy, and Steele, 83 * <i>The Java Language Specification</i>. 84 * 85 * <p> Unless otherwise noted, passing a <tt>null</tt> argument to a constructor 86 * or method in this class will cause a {@link NullPointerException} to be 87 * thrown. 88 * 89 * <p>A {@code String} represents a string in the UTF-16 format 90 * in which <em>supplementary characters</em> are represented by <em>surrogate 91 * pairs</em> (see the section <a href="Character.html#unicode">Unicode 92 * Character Representations</a> in the {@code Character} class for 93 * more information). 94 * Index values refer to {@code char} code units, so a supplementary 95 * character uses two positions in a {@code String}. 96 * <p>The {@code String} class provides methods for dealing with 97 * Unicode code points (i.e., characters), in addition to those for 98 * dealing with Unicode code units (i.e., {@code char} values). 99 * 100 * @author Lee Boynton 101 * @author Arthur van Hoff 102 * @author Martin Buchholz 103 * @author Ulf Zibis 104 * @see java.lang.Object#toString() 105 * @see java.lang.StringBuffer 106 * @see java.lang.StringBuilder 107 * @see java.nio.charset.Charset 108 * @since JDK1.0 109 */ 110 111 public final class String 112 implements java.io.Serializable, Comparable<String>, CharSequence { 113 /** The value is used for character storage. */ 114 private final char value[]; 115 116 /** Cache the hash code for the string */ 117 private int hash; // Default to 0 118 119 /** use serialVersionUID from JDK 1.0.2 for interoperability */ 120 private static final long serialVersionUID = -6849794470754667710L; 121 122 /** 123 * Class String is special cased within the Serialization Stream Protocol. 124 * 125 * A String instance is written into an ObjectOutputStream according to 126 * <a href="{@docRoot}/../platform/serialization/spec/output.html"> 127 * Object Serialization Specification, Section 6.2, "Stream Elements"</a> 128 */ 129 private static final ObjectStreamField[] serialPersistentFields = 130 new ObjectStreamField[0]; 131 132 /** 133 * Initializes a newly created {@code String} object so that it represents 134 * an empty character sequence. Note that use of this constructor is 135 * unnecessary since Strings are immutable. 136 */ 137 public String() { 138 this.value = "".value; 139 } 140 141 /** 142 * Initializes a newly created {@code String} object so that it represents 143 * the same sequence of characters as the argument; in other words, the 144 * newly created string is a copy of the argument string. Unless an 145 * explicit copy of {@code original} is needed, use of this constructor is 146 * unnecessary since Strings are immutable. 147 * 148 * @param original 149 * A {@code String} 150 */ 151 public String(String original) { 152 this.value = original.value; 153 this.hash = original.hash; 154 } 155 156 /** 157 * Allocates a new {@code String} so that it represents the sequence of 158 * characters currently contained in the character array argument. The 159 * contents of the character array are copied; subsequent modification of 160 * the character array does not affect the newly created string. 161 * 162 * @param value 163 * The initial value of the string 164 */ 165 public String(char value[]) { 166 this.value = Arrays.copyOf(value, value.length); 167 } 168 169 /** 170 * Allocates a new {@code String} that contains characters from a subarray 171 * of the character array argument. The {@code offset} argument is the 172 * index of the first character of the subarray and the {@code count} 173 * argument specifies the length of the subarray. The contents of the 174 * subarray are copied; subsequent modification of the character array does 175 * not affect the newly created string. 176 * 177 * @param value 178 * Array that is the source of characters 179 * 180 * @param offset 181 * The initial offset 182 * 183 * @param count 184 * The length 185 * 186 * @throws IndexOutOfBoundsException 187 * If the {@code offset} and {@code count} arguments index 188 * characters outside the bounds of the {@code value} array 189 */ 190 public String(char value[], int offset, int count) { 191 if (offset < 0) { 192 throw new StringIndexOutOfBoundsException(offset); 193 } 194 if (count <= 0) { 195 if (count < 0) { 196 throw new StringIndexOutOfBoundsException(count); 197 } 198 if (offset <= value.length) { 199 this.value = "".value; 200 return; 201 } 202 } 203 // Note: offset or count might be near -1>>>1. 204 if (offset > value.length - count) { 205 throw new StringIndexOutOfBoundsException(offset + count); 206 } 207 this.value = Arrays.copyOfRange(value, offset, offset+count); 208 } 209 210 /** 211 * Allocates a new {@code String} that contains characters from a subarray 212 * of the <a href="Character.html#unicode">Unicode code point</a> array 213 * argument. The {@code offset} argument is the index of the first code 214 * point of the subarray and the {@code count} argument specifies the 215 * length of the subarray. The contents of the subarray are converted to 216 * {@code char}s; subsequent modification of the {@code int} array does not 217 * affect the newly created string. 218 * 219 * @param codePoints 220 * Array that is the source of Unicode code points 221 * 222 * @param offset 223 * The initial offset 224 * 225 * @param count 226 * The length 227 * 228 * @throws IllegalArgumentException 229 * If any invalid Unicode code point is found in {@code 230 * codePoints} 231 * 232 * @throws IndexOutOfBoundsException 233 * If the {@code offset} and {@code count} arguments index 234 * characters outside the bounds of the {@code codePoints} array 235 * 236 * @since 1.5 237 */ 238 public String(int[] codePoints, int offset, int count) { 239 if (offset < 0) { 240 throw new StringIndexOutOfBoundsException(offset); 241 } 242 if (count <= 0) { 243 if (count < 0) { 244 throw new StringIndexOutOfBoundsException(count); 245 } 246 if (offset <= codePoints.length) { 247 this.value = "".value; 248 return; 249 } 250 } 251 // Note: offset or count might be near -1>>>1. 252 if (offset > codePoints.length - count) { 253 throw new StringIndexOutOfBoundsException(offset + count); 254 } 255 256 final int end = offset + count; 257 258 // Pass 1: Compute precise size of char[] 259 int n = count; 260 for (int i = offset; i < end; i++) { 261 int c = codePoints[i]; 262 if (Character.isBmpCodePoint(c)) 263 continue; 264 else if (Character.isValidCodePoint(c)) 265 n++; 266 else throw new IllegalArgumentException(Integer.toString(c)); 267 } 268 269 // Pass 2: Allocate and fill in char[] 270 final char[] v = new char[n]; 271 272 for (int i = offset, j = 0; i < end; i++, j++) { 273 int c = codePoints[i]; 274 if (Character.isBmpCodePoint(c)) 275 v[j] = (char)c; 276 else 277 Character.toSurrogates(c, v, j++); 278 } 279 280 this.value = v; 281 } 282 283 /** 284 * Allocates a new {@code String} constructed from a subarray of an array 285 * of 8-bit integer values. 286 * 287 * <p> The {@code offset} argument is the index of the first byte of the 288 * subarray, and the {@code count} argument specifies the length of the 289 * subarray. 290 * 291 * <p> Each {@code byte} in the subarray is converted to a {@code char} as 292 * specified in the method above. 293 * 294 * @deprecated This method does not properly convert bytes into characters. 295 * As of JDK 1.1, the preferred way to do this is via the 296 * {@code String} constructors that take a {@link 297 * java.nio.charset.Charset}, charset name, or that use the platform's 298 * default charset. 299 * 300 * @param ascii 301 * The bytes to be converted to characters 302 * 303 * @param hibyte 304 * The top 8 bits of each 16-bit Unicode code unit 305 * 306 * @param offset 307 * The initial offset 308 * @param count 309 * The length 310 * 311 * @throws IndexOutOfBoundsException 312 * If the {@code offset} or {@code count} argument is invalid 313 * 314 * @see #String(byte[], int) 315 * @see #String(byte[], int, int, java.lang.String) 316 * @see #String(byte[], int, int, java.nio.charset.Charset) 317 * @see #String(byte[], int, int) 318 * @see #String(byte[], java.lang.String) 319 * @see #String(byte[], java.nio.charset.Charset) 320 * @see #String(byte[]) 321 */ 322 @Deprecated 323 public String(byte ascii[], int hibyte, int offset, int count) { 324 checkBounds(ascii, offset, count); 325 char value[] = new char[count]; 326 327 if (hibyte == 0) { 328 for (int i = count; i-- > 0;) { 329 value[i] = (char)(ascii[i + offset] & 0xff); 330 } 331 } else { 332 hibyte <<= 8; 333 for (int i = count; i-- > 0;) { 334 value[i] = (char)(hibyte | (ascii[i + offset] & 0xff)); 335 } 336 } 337 this.value = value; 338 } 339 340 /** 341 * Allocates a new {@code String} containing characters constructed from 342 * an array of 8-bit integer values. Each character <i>c</i>in the 343 * resulting string is constructed from the corresponding component 344 * <i>b</i> in the byte array such that: 345 * 346 * <blockquote><pre> 347 * <b><i>c</i></b> == (char)(((hibyte & 0xff) << 8) 348 * | (<b><i>b</i></b> & 0xff)) 349 * </pre></blockquote> 350 * 351 * @deprecated This method does not properly convert bytes into 352 * characters. As of JDK 1.1, the preferred way to do this is via the 353 * {@code String} constructors that take a {@link 354 * java.nio.charset.Charset}, charset name, or that use the platform's 355 * default charset. 356 * 357 * @param ascii 358 * The bytes to be converted to characters 359 * 360 * @param hibyte 361 * The top 8 bits of each 16-bit Unicode code unit 362 * 363 * @see #String(byte[], int, int, java.lang.String) 364 * @see #String(byte[], int, int, java.nio.charset.Charset) 365 * @see #String(byte[], int, int) 366 * @see #String(byte[], java.lang.String) 367 * @see #String(byte[], java.nio.charset.Charset) 368 * @see #String(byte[]) 369 */ 370 @Deprecated 371 public String(byte ascii[], int hibyte) { 372 this(ascii, hibyte, 0, ascii.length); 373 } 374 375 /* Common private utility method used to bounds check the byte array 376 * and requested offset & length values used by the String(byte[],..) 377 * constructors. 378 */ 379 private static void checkBounds(byte[] bytes, int offset, int length) { 380 if (length < 0) 381 throw new StringIndexOutOfBoundsException(length); 382 if (offset < 0) 383 throw new StringIndexOutOfBoundsException(offset); 384 if (offset > bytes.length - length) 385 throw new StringIndexOutOfBoundsException(offset + length); 386 } 387 388 /** 389 * Constructs a new {@code String} by decoding the specified subarray of 390 * bytes using the specified charset. The length of the new {@code String} 391 * is a function of the charset, and hence may not be equal to the length 392 * of the subarray. 393 * 394 * <p> The behavior of this constructor when the given bytes are not valid 395 * in the given charset is unspecified. The {@link 396 * java.nio.charset.CharsetDecoder} class should be used when more control 397 * over the decoding process is required. 398 * 399 * @param bytes 400 * The bytes to be decoded into characters 401 * 402 * @param offset 403 * The index of the first byte to decode 404 * 405 * @param length 406 * The number of bytes to decode 407 408 * @param charsetName 409 * The name of a supported {@linkplain java.nio.charset.Charset 410 * charset} 411 * 412 * @throws UnsupportedEncodingException 413 * If the named charset is not supported 414 * 415 * @throws IndexOutOfBoundsException 416 * If the {@code offset} and {@code length} arguments index 417 * characters outside the bounds of the {@code bytes} array 418 * 419 * @since JDK1.1 420 */ 421 public String(byte bytes[], int offset, int length, String charsetName) 422 throws UnsupportedEncodingException { 423 if (charsetName == null) 424 throw new NullPointerException("charsetName"); 425 checkBounds(bytes, offset, length); 426 this.value = StringCoding.decode(charsetName, bytes, offset, length); 427 } 428 429 /** 430 * Constructs a new {@code String} by decoding the specified subarray of 431 * bytes using the specified {@linkplain java.nio.charset.Charset charset}. 432 * The length of the new {@code String} is a function of the charset, and 433 * hence may not be equal to the length of the subarray. 434 * 435 * <p> This method always replaces malformed-input and unmappable-character 436 * sequences with this charset's default replacement string. The {@link 437 * java.nio.charset.CharsetDecoder} class should be used when more control 438 * over the decoding process is required. 439 * 440 * @param bytes 441 * The bytes to be decoded into characters 442 * 443 * @param offset 444 * The index of the first byte to decode 445 * 446 * @param length 447 * The number of bytes to decode 448 * 449 * @param charset 450 * The {@linkplain java.nio.charset.Charset charset} to be used to 451 * decode the {@code bytes} 452 * 453 * @throws IndexOutOfBoundsException 454 * If the {@code offset} and {@code length} arguments index 455 * characters outside the bounds of the {@code bytes} array 456 * 457 * @since 1.6 458 */ 459 public String(byte bytes[], int offset, int length, Charset charset) { 460 if (charset == null) 461 throw new NullPointerException("charset"); 462 checkBounds(bytes, offset, length); 463 this.value = StringCoding.decode(charset, bytes, offset, length); 464 } 465 466 /** 467 * Constructs a new {@code String} by decoding the specified array of bytes 468 * using the specified {@linkplain java.nio.charset.Charset charset}. The 469 * length of the new {@code String} is a function of the charset, and hence 470 * may not be equal to the length of the byte array. 471 * 472 * <p> The behavior of this constructor when the given bytes are not valid 473 * in the given charset is unspecified. The {@link 474 * java.nio.charset.CharsetDecoder} class should be used when more control 475 * over the decoding process is required. 476 * 477 * @param bytes 478 * The bytes to be decoded into characters 479 * 480 * @param charsetName 481 * The name of a supported {@linkplain java.nio.charset.Charset 482 * charset} 483 * 484 * @throws UnsupportedEncodingException 485 * If the named charset is not supported 486 * 487 * @since JDK1.1 488 */ 489 public String(byte bytes[], String charsetName) 490 throws UnsupportedEncodingException { 491 this(bytes, 0, bytes.length, charsetName); 492 } 493 494 /** 495 * Constructs a new {@code String} by decoding the specified array of 496 * bytes using the specified {@linkplain java.nio.charset.Charset charset}. 497 * The length of the new {@code String} is a function of the charset, and 498 * hence may not be equal to the length of the byte array. 499 * 500 * <p> This method always replaces malformed-input and unmappable-character 501 * sequences with this charset's default replacement string. The {@link 502 * java.nio.charset.CharsetDecoder} class should be used when more control 503 * over the decoding process is required. 504 * 505 * @param bytes 506 * The bytes to be decoded into characters 507 * 508 * @param charset 509 * The {@linkplain java.nio.charset.Charset charset} to be used to 510 * decode the {@code bytes} 511 * 512 * @since 1.6 513 */ 514 public String(byte bytes[], Charset charset) { 515 this(bytes, 0, bytes.length, charset); 516 } 517 518 /** 519 * Constructs a new {@code String} by decoding the specified subarray of 520 * bytes using the platform's default charset. The length of the new 521 * {@code String} is a function of the charset, and hence may not be equal 522 * to the length of the subarray. 523 * 524 * <p> The behavior of this constructor when the given bytes are not valid 525 * in the default charset is unspecified. The {@link 526 * java.nio.charset.CharsetDecoder} class should be used when more control 527 * over the decoding process is required. 528 * 529 * @param bytes 530 * The bytes to be decoded into characters 531 * 532 * @param offset 533 * The index of the first byte to decode 534 * 535 * @param length 536 * The number of bytes to decode 537 * 538 * @throws IndexOutOfBoundsException 539 * If the {@code offset} and the {@code length} arguments index 540 * characters outside the bounds of the {@code bytes} array 541 * 542 * @since JDK1.1 543 */ 544 public String(byte bytes[], int offset, int length) { 545 checkBounds(bytes, offset, length); 546 this.value = StringCoding.decode(bytes, offset, length); 547 } 548 549 /** 550 * Constructs a new {@code String} by decoding the specified array of bytes 551 * using the platform's default charset. The length of the new {@code 552 * String} is a function of the charset, and hence may not be equal to the 553 * length of the byte array. 554 * 555 * <p> The behavior of this constructor when the given bytes are not valid 556 * in the default charset is unspecified. The {@link 557 * java.nio.charset.CharsetDecoder} class should be used when more control 558 * over the decoding process is required. 559 * 560 * @param bytes 561 * The bytes to be decoded into characters 562 * 563 * @since JDK1.1 564 */ 565 public String(byte bytes[]) { 566 this(bytes, 0, bytes.length); 567 } 568 569 /** 570 * Allocates a new string that contains the sequence of characters 571 * currently contained in the string buffer argument. The contents of the 572 * string buffer are copied; subsequent modification of the string buffer 573 * does not affect the newly created string. 574 * 575 * @param buffer 576 * A {@code StringBuffer} 577 */ 578 public String(StringBuffer buffer) { 579 synchronized(buffer) { 580 this.value = Arrays.copyOf(buffer.getValue(), buffer.length()); 581 } 582 } 583 584 /** 585 * Allocates a new string that contains the sequence of characters 586 * currently contained in the string builder argument. The contents of the 587 * string builder are copied; subsequent modification of the string builder 588 * does not affect the newly created string. 589 * 590 * <p> This constructor is provided to ease migration to {@code 591 * StringBuilder}. Obtaining a string from a string builder via the {@code 592 * toString} method is likely to run faster and is generally preferred. 593 * 594 * @param builder 595 * A {@code StringBuilder} 596 * 597 * @since 1.5 598 */ 599 public String(StringBuilder builder) { 600 this.value = Arrays.copyOf(builder.getValue(), builder.length()); 601 } 602 603 /* 604 * Package private constructor which shares value array for speed. 605 * this constructor is always expected to be called with share==true. 606 * a separate constructor is needed because we already have a public 607 * String(char[]) constructor that makes a copy of the given char[]. 608 */ 609 String(char[] value, boolean share) { 610 // assert share : "unshared not supported"; 611 this.value = value; 612 } 613 614 /** 615 * Returns the length of this string. 616 * The length is equal to the number of <a href="Character.html#unicode">Unicode 617 * code units</a> in the string. 618 * 619 * @return the length of the sequence of characters represented by this 620 * object. 621 */ 622 public int length() { 623 return value.length; 624 } 625 626 /** 627 * Returns {@code true} if, and only if, {@link #length()} is {@code 0}. 628 * 629 * @return {@code true} if {@link #length()} is {@code 0}, otherwise 630 * {@code false} 631 * 632 * @since 1.6 633 */ 634 public boolean isEmpty() { 635 return value.length == 0; 636 } 637 638 /** 639 * Returns the {@code char} value at the 640 * specified index. An index ranges from {@code 0} to 641 * {@code length() - 1}. The first {@code char} value of the sequence 642 * is at index {@code 0}, the next at index {@code 1}, 643 * and so on, as for array indexing. 644 * 645 * <p>If the {@code char} value specified by the index is a 646 * <a href="Character.html#unicode">surrogate</a>, the surrogate 647 * value is returned. 648 * 649 * @param index the index of the {@code char} value. 650 * @return the {@code char} value at the specified index of this string. 651 * The first {@code char} value is at index {@code 0}. 652 * @exception IndexOutOfBoundsException if the {@code index} 653 * argument is negative or not less than the length of this 654 * string. 655 */ 656 public char charAt(int index) { 657 if ((index < 0) || (index >= value.length)) { 658 throw new StringIndexOutOfBoundsException(index); 659 } 660 return value[index]; 661 } 662 663 /** 664 * Returns the character (Unicode code point) at the specified 665 * index. The index refers to {@code char} values 666 * (Unicode code units) and ranges from {@code 0} to 667 * {@link #length()}{@code - 1}. 668 * 669 * <p> If the {@code char} value specified at the given index 670 * is in the high-surrogate range, the following index is less 671 * than the length of this {@code String}, and the 672 * {@code char} value at the following index is in the 673 * low-surrogate range, then the supplementary code point 674 * corresponding to this surrogate pair is returned. Otherwise, 675 * the {@code char} value at the given index is returned. 676 * 677 * @param index the index to the {@code char} values 678 * @return the code point value of the character at the 679 * {@code index} 680 * @exception IndexOutOfBoundsException if the {@code index} 681 * argument is negative or not less than the length of this 682 * string. 683 * @since 1.5 684 */ 685 public int codePointAt(int index) { 686 if ((index < 0) || (index >= value.length)) { 687 throw new StringIndexOutOfBoundsException(index); 688 } 689 return Character.codePointAtImpl(value, index, value.length); 690 } 691 692 /** 693 * Returns the character (Unicode code point) before the specified 694 * index. The index refers to {@code char} values 695 * (Unicode code units) and ranges from {@code 1} to {@link 696 * CharSequence#length() length}. 697 * 698 * <p> If the {@code char} value at {@code (index - 1)} 699 * is in the low-surrogate range, {@code (index - 2)} is not 700 * negative, and the {@code char} value at {@code (index - 701 * 2)} is in the high-surrogate range, then the 702 * supplementary code point value of the surrogate pair is 703 * returned. If the {@code char} value at {@code index - 704 * 1} is an unpaired low-surrogate or a high-surrogate, the 705 * surrogate value is returned. 706 * 707 * @param index the index following the code point that should be returned 708 * @return the Unicode code point value before the given index. 709 * @exception IndexOutOfBoundsException if the {@code index} 710 * argument is less than 1 or greater than the length 711 * of this string. 712 * @since 1.5 713 */ 714 public int codePointBefore(int index) { 715 int i = index - 1; 716 if ((i < 0) || (i >= value.length)) { 717 throw new StringIndexOutOfBoundsException(index); 718 } 719 return Character.codePointBeforeImpl(value, index, 0); 720 } 721 722 /** 723 * Returns the number of Unicode code points in the specified text 724 * range of this {@code String}. The text range begins at the 725 * specified {@code beginIndex} and extends to the 726 * {@code char} at index {@code endIndex - 1}. Thus the 727 * length (in {@code char}s) of the text range is 728 * {@code endIndex-beginIndex}. Unpaired surrogates within 729 * the text range count as one code point each. 730 * 731 * @param beginIndex the index to the first {@code char} of 732 * the text range. 733 * @param endIndex the index after the last {@code char} of 734 * the text range. 735 * @return the number of Unicode code points in the specified text 736 * range 737 * @exception IndexOutOfBoundsException if the 738 * {@code beginIndex} is negative, or {@code endIndex} 739 * is larger than the length of this {@code String}, or 740 * {@code beginIndex} is larger than {@code endIndex}. 741 * @since 1.5 742 */ 743 public int codePointCount(int beginIndex, int endIndex) { 744 if (beginIndex < 0 || endIndex > value.length || beginIndex > endIndex) { 745 throw new IndexOutOfBoundsException(); 746 } 747 return Character.codePointCountImpl(value, beginIndex, endIndex - beginIndex); 748 } 749 750 /** 751 * Returns the index within this {@code String} that is 752 * offset from the given {@code index} by 753 * {@code codePointOffset} code points. Unpaired surrogates 754 * within the text range given by {@code index} and 755 * {@code codePointOffset} count as one code point each. 756 * 757 * @param index the index to be offset 758 * @param codePointOffset the offset in code points 759 * @return the index within this {@code String} 760 * @exception IndexOutOfBoundsException if {@code index} 761 * is negative or larger then the length of this 762 * {@code String}, or if {@code codePointOffset} is positive 763 * and the substring starting with {@code index} has fewer 764 * than {@code codePointOffset} code points, 765 * or if {@code codePointOffset} is negative and the substring 766 * before {@code index} has fewer than the absolute value 767 * of {@code codePointOffset} code points. 768 * @since 1.5 769 */ 770 public int offsetByCodePoints(int index, int codePointOffset) { 771 if (index < 0 || index > value.length) { 772 throw new IndexOutOfBoundsException(); 773 } 774 return Character.offsetByCodePointsImpl(value, 0, value.length, 775 index, codePointOffset); 776 } 777 778 /** 779 * Copy characters from this string into dst starting at dstBegin. 780 * This method doesn't perform any range checking. 781 */ 782 void getChars(char dst[], int dstBegin) { 783 System.arraycopy(value, 0, dst, dstBegin, value.length); 784 } 785 786 /** 787 * Copies characters from this string into the destination character 788 * array. 789 * <p> 790 * The first character to be copied is at index {@code srcBegin}; 791 * the last character to be copied is at index {@code srcEnd-1} 792 * (thus the total number of characters to be copied is 793 * {@code srcEnd-srcBegin}). The characters are copied into the 794 * subarray of {@code dst} starting at index {@code dstBegin} 795 * and ending at index: 796 * <blockquote><pre> 797 * dstBegin + (srcEnd-srcBegin) - 1 798 * </pre></blockquote> 799 * 800 * @param srcBegin index of the first character in the string 801 * to copy. 802 * @param srcEnd index after the last character in the string 803 * to copy. 804 * @param dst the destination array. 805 * @param dstBegin the start offset in the destination array. 806 * @exception IndexOutOfBoundsException If any of the following 807 * is true: 808 * <ul><li>{@code srcBegin} is negative. 809 * <li>{@code srcBegin} is greater than {@code srcEnd} 810 * <li>{@code srcEnd} is greater than the length of this 811 * string 812 * <li>{@code dstBegin} is negative 813 * <li>{@code dstBegin+(srcEnd-srcBegin)} is larger than 814 * {@code dst.length}</ul> 815 */ 816 public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) { 817 if (srcBegin < 0) { 818 throw new StringIndexOutOfBoundsException(srcBegin); 819 } 820 if (srcEnd > value.length) { 821 throw new StringIndexOutOfBoundsException(srcEnd); 822 } 823 if (srcBegin > srcEnd) { 824 throw new StringIndexOutOfBoundsException(srcEnd - srcBegin); 825 } 826 System.arraycopy(value, srcBegin, dst, dstBegin, srcEnd - srcBegin); 827 } 828 829 /** 830 * Copies characters from this string into the destination byte array. Each 831 * byte receives the 8 low-order bits of the corresponding character. The 832 * eight high-order bits of each character are not copied and do not 833 * participate in the transfer in any way. 834 * 835 * <p> The first character to be copied is at index {@code srcBegin}; the 836 * last character to be copied is at index {@code srcEnd-1}. The total 837 * number of characters to be copied is {@code srcEnd-srcBegin}. The 838 * characters, converted to bytes, are copied into the subarray of {@code 839 * dst} starting at index {@code dstBegin} and ending at index: 840 * 841 * <blockquote><pre> 842 * dstBegin + (srcEnd-srcBegin) - 1 843 * </pre></blockquote> 844 * 845 * @deprecated This method does not properly convert characters into 846 * bytes. As of JDK 1.1, the preferred way to do this is via the 847 * {@link #getBytes()} method, which uses the platform's default charset. 848 * 849 * @param srcBegin 850 * Index of the first character in the string to copy 851 * 852 * @param srcEnd 853 * Index after the last character in the string to copy 854 * 855 * @param dst 856 * The destination array 857 * 858 * @param dstBegin 859 * The start offset in the destination array 860 * 861 * @throws IndexOutOfBoundsException 862 * If any of the following is true: 863 * <ul> 864 * <li> {@code srcBegin} is negative 865 * <li> {@code srcBegin} is greater than {@code srcEnd} 866 * <li> {@code srcEnd} is greater than the length of this String 867 * <li> {@code dstBegin} is negative 868 * <li> {@code dstBegin+(srcEnd-srcBegin)} is larger than {@code 869 * dst.length} 870 * </ul> 871 */ 872 @Deprecated 873 public void getBytes(int srcBegin, int srcEnd, byte dst[], int dstBegin) { 874 if (srcBegin < 0) { 875 throw new StringIndexOutOfBoundsException(srcBegin); 876 } 877 if (srcEnd > value.length) { 878 throw new StringIndexOutOfBoundsException(srcEnd); 879 } 880 if (srcBegin > srcEnd) { 881 throw new StringIndexOutOfBoundsException(srcEnd - srcBegin); 882 } 883 Objects.requireNonNull(dst); 884 885 int j = dstBegin; 886 int n = srcEnd; 887 int i = srcBegin; 888 char[] val = value; /* avoid getfield opcode */ 889 890 while (i < n) { 891 dst[j++] = (byte)val[i++]; 892 } 893 } 894 895 /** 896 * Encodes this {@code String} into a sequence of bytes using the named 897 * charset, storing the result into a new byte array. 898 * 899 * <p> The behavior of this method when this string cannot be encoded in 900 * the given charset is unspecified. The {@link 901 * java.nio.charset.CharsetEncoder} class should be used when more control 902 * over the encoding process is required. 903 * 904 * @param charsetName 905 * The name of a supported {@linkplain java.nio.charset.Charset 906 * charset} 907 * 908 * @return The resultant byte array 909 * 910 * @throws UnsupportedEncodingException 911 * If the named charset is not supported 912 * 913 * @since JDK1.1 914 */ 915 public byte[] getBytes(String charsetName) 916 throws UnsupportedEncodingException { 917 if (charsetName == null) throw new NullPointerException(); 918 return StringCoding.encode(charsetName, value, 0, value.length); 919 } 920 921 /** 922 * Encodes this {@code String} into a sequence of bytes using the given 923 * {@linkplain java.nio.charset.Charset charset}, storing the result into a 924 * new byte array. 925 * 926 * <p> This method always replaces malformed-input and unmappable-character 927 * sequences with this charset's default replacement byte array. The 928 * {@link java.nio.charset.CharsetEncoder} class should be used when more 929 * control over the encoding process is required. 930 * 931 * @param charset 932 * The {@linkplain java.nio.charset.Charset} to be used to encode 933 * the {@code String} 934 * 935 * @return The resultant byte array 936 * 937 * @since 1.6 938 */ 939 public byte[] getBytes(Charset charset) { 940 if (charset == null) throw new NullPointerException(); 941 return StringCoding.encode(charset, value, 0, value.length); 942 } 943 944 /** 945 * Encodes this {@code String} into a sequence of bytes using the 946 * platform's default charset, storing the result into a new byte array. 947 * 948 * <p> The behavior of this method when this string cannot be encoded in 949 * the default charset is unspecified. The {@link 950 * java.nio.charset.CharsetEncoder} class should be used when more control 951 * over the encoding process is required. 952 * 953 * @return The resultant byte array 954 * 955 * @since JDK1.1 956 */ 957 public byte[] getBytes() { 958 return StringCoding.encode(value, 0, value.length); 959 } 960 961 /** 962 * Compares this string to the specified object. The result is {@code 963 * true} if and only if the argument is not {@code null} and is a {@code 964 * String} object that represents the same sequence of characters as this 965 * object. 966 * 967 * @param anObject 968 * The object to compare this {@code String} against 969 * 970 * @return {@code true} if the given object represents a {@code String} 971 * equivalent to this string, {@code false} otherwise 972 * 973 * @see #compareTo(String) 974 * @see #equalsIgnoreCase(String) 975 */ 976 public boolean equals(Object anObject) { 977 if (this == anObject) { 978 return true; 979 } 980 if (anObject instanceof String) { 981 String anotherString = (String)anObject; 982 int n = value.length; 983 if (n == anotherString.value.length) { 984 char v1[] = value; 985 char v2[] = anotherString.value; 986 int i = 0; 987 while (n-- != 0) { 988 if (v1[i] != v2[i]) 989 return false; 990 i++; 991 } 992 return true; 993 } 994 } 995 return false; 996 } 997 998 /** 999 * Compares this string to the specified {@code StringBuffer}. The result 1000 * is {@code true} if and only if this {@code String} represents the same 1001 * sequence of characters as the specified {@code StringBuffer}. This method 1002 * synchronizes on the {@code StringBuffer}. 1003 * 1004 * @param sb 1005 * The {@code StringBuffer} to compare this {@code String} against 1006 * 1007 * @return {@code true} if this {@code String} represents the same 1008 * sequence of characters as the specified {@code StringBuffer}, 1009 * {@code false} otherwise 1010 * 1011 * @since 1.4 1012 */ 1013 public boolean contentEquals(StringBuffer sb) { 1014 return contentEquals((CharSequence)sb); 1015 } 1016 1017 private boolean nonSyncContentEquals(AbstractStringBuilder sb) { 1018 char v1[] = value; 1019 char v2[] = sb.getValue(); 1020 int n = v1.length; 1021 if (n != sb.length()) { 1022 return false; 1023 } 1024 for (int i = 0; i < n; i++) { 1025 if (v1[i] != v2[i]) { 1026 return false; 1027 } 1028 } 1029 return true; 1030 } 1031 1032 /** 1033 * Compares this string to the specified {@code CharSequence}. The 1034 * result is {@code true} if and only if this {@code String} represents the 1035 * same sequence of char values as the specified sequence. Note that if the 1036 * {@code CharSequence} is a {@code StringBuffer} then the method 1037 * synchronizes on it. 1038 * 1039 * @param cs 1040 * The sequence to compare this {@code String} against 1041 * 1042 * @return {@code true} if this {@code String} represents the same 1043 * sequence of char values as the specified sequence, {@code 1044 * false} otherwise 1045 * 1046 * @since 1.5 1047 */ 1048 public boolean contentEquals(CharSequence cs) { 1049 // Argument is a StringBuffer, StringBuilder 1050 if (cs instanceof AbstractStringBuilder) { 1051 if (cs instanceof StringBuffer) { 1052 synchronized(cs) { 1053 return nonSyncContentEquals((AbstractStringBuilder)cs); 1054 } 1055 } else { 1056 return nonSyncContentEquals((AbstractStringBuilder)cs); 1057 } 1058 } 1059 // Argument is a String 1060 if (cs instanceof String) { 1061 return equals(cs); 1062 } 1063 // Argument is a generic CharSequence 1064 char v1[] = value; 1065 int n = v1.length; 1066 if (n != cs.length()) { 1067 return false; 1068 } 1069 for (int i = 0; i < n; i++) { 1070 if (v1[i] != cs.charAt(i)) { 1071 return false; 1072 } 1073 } 1074 return true; 1075 } 1076 1077 /** 1078 * Compares this {@code String} to another {@code String}, ignoring case 1079 * considerations. Two strings are considered equal ignoring case if they 1080 * are of the same length and corresponding characters in the two strings 1081 * are equal ignoring case. 1082 * 1083 * <p> Two characters {@code c1} and {@code c2} are considered the same 1084 * ignoring case if at least one of the following is true: 1085 * <ul> 1086 * <li> The two characters are the same (as compared by the 1087 * {@code ==} operator) 1088 * <li> Applying the method {@link 1089 * java.lang.Character#toUpperCase(char)} to each character 1090 * produces the same result 1091 * <li> Applying the method {@link 1092 * java.lang.Character#toLowerCase(char)} to each character 1093 * produces the same result 1094 * </ul> 1095 * 1096 * @param anotherString 1097 * The {@code String} to compare this {@code String} against 1098 * 1099 * @return {@code true} if the argument is not {@code null} and it 1100 * represents an equivalent {@code String} ignoring case; {@code 1101 * false} otherwise 1102 * 1103 * @see #equals(Object) 1104 */ 1105 public boolean equalsIgnoreCase(String anotherString) { 1106 return (this == anotherString) ? true 1107 : (anotherString != null) 1108 && (anotherString.value.length == value.length) 1109 && regionMatches(true, 0, anotherString, 0, value.length); 1110 } 1111 1112 /** 1113 * Compares two strings lexicographically. 1114 * The comparison is based on the Unicode value of each character in 1115 * the strings. The character sequence represented by this 1116 * {@code String} object is compared lexicographically to the 1117 * character sequence represented by the argument string. The result is 1118 * a negative integer if this {@code String} object 1119 * lexicographically precedes the argument string. The result is a 1120 * positive integer if this {@code String} object lexicographically 1121 * follows the argument string. The result is zero if the strings 1122 * are equal; {@code compareTo} returns {@code 0} exactly when 1123 * the {@link #equals(Object)} method would return {@code true}. 1124 * <p> 1125 * This is the definition of lexicographic ordering. If two strings are 1126 * different, then either they have different characters at some index 1127 * that is a valid index for both strings, or their lengths are different, 1128 * or both. If they have different characters at one or more index 1129 * positions, let <i>k</i> be the smallest such index; then the string 1130 * whose character at position <i>k</i> has the smaller value, as 1131 * determined by using the < operator, lexicographically precedes the 1132 * other string. In this case, {@code compareTo} returns the 1133 * difference of the two character values at position {@code k} in 1134 * the two string -- that is, the value: 1135 * <blockquote><pre> 1136 * this.charAt(k)-anotherString.charAt(k) 1137 * </pre></blockquote> 1138 * If there is no index position at which they differ, then the shorter 1139 * string lexicographically precedes the longer string. In this case, 1140 * {@code compareTo} returns the difference of the lengths of the 1141 * strings -- that is, the value: 1142 * <blockquote><pre> 1143 * this.length()-anotherString.length() 1144 * </pre></blockquote> 1145 * 1146 * @param anotherString the {@code String} to be compared. 1147 * @return the value {@code 0} if the argument string is equal to 1148 * this string; a value less than {@code 0} if this string 1149 * is lexicographically less than the string argument; and a 1150 * value greater than {@code 0} if this string is 1151 * lexicographically greater than the string argument. 1152 */ 1153 public int compareTo(String anotherString) { 1154 int len1 = value.length; 1155 int len2 = anotherString.value.length; 1156 int lim = Math.min(len1, len2); 1157 char v1[] = value; 1158 char v2[] = anotherString.value; 1159 1160 int k = 0; 1161 while (k < lim) { 1162 char c1 = v1[k]; 1163 char c2 = v2[k]; 1164 if (c1 != c2) { 1165 return c1 - c2; 1166 } 1167 k++; 1168 } 1169 return len1 - len2; 1170 } 1171 1172 /** 1173 * A Comparator that orders {@code String} objects as by 1174 * {@code compareToIgnoreCase}. This comparator is serializable. 1175 * <p> 1176 * Note that this Comparator does <em>not</em> take locale into account, 1177 * and will result in an unsatisfactory ordering for certain locales. 1178 * The java.text package provides <em>Collators</em> to allow 1179 * locale-sensitive ordering. 1180 * 1181 * @see java.text.Collator#compare(String, String) 1182 * @since 1.2 1183 */ 1184 public static final Comparator<String> CASE_INSENSITIVE_ORDER 1185 = new CaseInsensitiveComparator(); 1186 private static class CaseInsensitiveComparator 1187 implements Comparator<String>, java.io.Serializable { 1188 // use serialVersionUID from JDK 1.2.2 for interoperability 1189 private static final long serialVersionUID = 8575799808933029326L; 1190 1191 public int compare(String s1, String s2) { 1192 int n1 = s1.length(); 1193 int n2 = s2.length(); 1194 int min = Math.min(n1, n2); 1195 for (int i = 0; i < min; i++) { 1196 char c1 = s1.charAt(i); 1197 char c2 = s2.charAt(i); 1198 if (c1 != c2) { 1199 c1 = Character.toUpperCase(c1); 1200 c2 = Character.toUpperCase(c2); 1201 if (c1 != c2) { 1202 c1 = Character.toLowerCase(c1); 1203 c2 = Character.toLowerCase(c2); 1204 if (c1 != c2) { 1205 // No overflow because of numeric promotion 1206 return c1 - c2; 1207 } 1208 } 1209 } 1210 } 1211 return n1 - n2; 1212 } 1213 1214 /** Replaces the de-serialized object. */ 1215 private Object readResolve() { return CASE_INSENSITIVE_ORDER; } 1216 } 1217 1218 /** 1219 * Compares two strings lexicographically, ignoring case 1220 * differences. This method returns an integer whose sign is that of 1221 * calling {@code compareTo} with normalized versions of the strings 1222 * where case differences have been eliminated by calling 1223 * {@code Character.toLowerCase(Character.toUpperCase(character))} on 1224 * each character. 1225 * <p> 1226 * Note that this method does <em>not</em> take locale into account, 1227 * and will result in an unsatisfactory ordering for certain locales. 1228 * The java.text package provides <em>collators</em> to allow 1229 * locale-sensitive ordering. 1230 * 1231 * @param str the {@code String} to be compared. 1232 * @return a negative integer, zero, or a positive integer as the 1233 * specified String is greater than, equal to, or less 1234 * than this String, ignoring case considerations. 1235 * @see java.text.Collator#compare(String, String) 1236 * @since 1.2 1237 */ 1238 public int compareToIgnoreCase(String str) { 1239 return CASE_INSENSITIVE_ORDER.compare(this, str); 1240 } 1241 1242 /** 1243 * Tests if two string regions are equal. 1244 * <p> 1245 * A substring of this {@code String} object is compared to a substring 1246 * of the argument other. The result is true if these substrings 1247 * represent identical character sequences. The substring of this 1248 * {@code String} object to be compared begins at index {@code toffset} 1249 * and has length {@code len}. The substring of other to be compared 1250 * begins at index {@code ooffset} and has length {@code len}. The 1251 * result is {@code false} if and only if at least one of the following 1252 * is true: 1253 * <ul><li>{@code toffset} is negative. 1254 * <li>{@code ooffset} is negative. 1255 * <li>{@code toffset+len} is greater than the length of this 1256 * {@code String} object. 1257 * <li>{@code ooffset+len} is greater than the length of the other 1258 * argument. 1259 * <li>There is some nonnegative integer <i>k</i> less than {@code len} 1260 * such that: 1261 * {@code this.charAt(toffset + }<i>k</i>{@code ) != other.charAt(ooffset + } 1262 * <i>k</i>{@code )} 1263 * </ul> 1264 * 1265 * @param toffset the starting offset of the subregion in this string. 1266 * @param other the string argument. 1267 * @param ooffset the starting offset of the subregion in the string 1268 * argument. 1269 * @param len the number of characters to compare. 1270 * @return {@code true} if the specified subregion of this string 1271 * exactly matches the specified subregion of the string argument; 1272 * {@code false} otherwise. 1273 */ 1274 public boolean regionMatches(int toffset, String other, int ooffset, 1275 int len) { 1276 char ta[] = value; 1277 int to = toffset; 1278 char pa[] = other.value; 1279 int po = ooffset; 1280 // Note: toffset, ooffset, or len might be near -1>>>1. 1281 if ((ooffset < 0) || (toffset < 0) 1282 || (toffset > (long)value.length - len) 1283 || (ooffset > (long)other.value.length - len)) { 1284 return false; 1285 } 1286 while (len-- > 0) { 1287 if (ta[to++] != pa[po++]) { 1288 return false; 1289 } 1290 } 1291 return true; 1292 } 1293 1294 /** 1295 * Tests if two string regions are equal. 1296 * <p> 1297 * A substring of this {@code String} object is compared to a substring 1298 * of the argument {@code other}. The result is {@code true} if these 1299 * substrings represent character sequences that are the same, ignoring 1300 * case if and only if {@code ignoreCase} is true. The substring of 1301 * this {@code String} object to be compared begins at index 1302 * {@code toffset} and has length {@code len}. The substring of 1303 * {@code other} to be compared begins at index {@code ooffset} and 1304 * has length {@code len}. The result is {@code false} if and only if 1305 * at least one of the following is true: 1306 * <ul><li>{@code toffset} is negative. 1307 * <li>{@code ooffset} is negative. 1308 * <li>{@code toffset+len} is greater than the length of this 1309 * {@code String} object. 1310 * <li>{@code ooffset+len} is greater than the length of the other 1311 * argument. 1312 * <li>{@code ignoreCase} is {@code false} and there is some nonnegative 1313 * integer <i>k</i> less than {@code len} such that: 1314 * <blockquote><pre> 1315 * this.charAt(toffset+k) != other.charAt(ooffset+k) 1316 * </pre></blockquote> 1317 * <li>{@code ignoreCase} is {@code true} and there is some nonnegative 1318 * integer <i>k</i> less than {@code len} such that: 1319 * <blockquote><pre> 1320 * Character.toLowerCase(this.charAt(toffset+k)) != 1321 Character.toLowerCase(other.charAt(ooffset+k)) 1322 * </pre></blockquote> 1323 * and: 1324 * <blockquote><pre> 1325 * Character.toUpperCase(this.charAt(toffset+k)) != 1326 * Character.toUpperCase(other.charAt(ooffset+k)) 1327 * </pre></blockquote> 1328 * </ul> 1329 * 1330 * @param ignoreCase if {@code true}, ignore case when comparing 1331 * characters. 1332 * @param toffset the starting offset of the subregion in this 1333 * string. 1334 * @param other the string argument. 1335 * @param ooffset the starting offset of the subregion in the string 1336 * argument. 1337 * @param len the number of characters to compare. 1338 * @return {@code true} if the specified subregion of this string 1339 * matches the specified subregion of the string argument; 1340 * {@code false} otherwise. Whether the matching is exact 1341 * or case insensitive depends on the {@code ignoreCase} 1342 * argument. 1343 */ 1344 public boolean regionMatches(boolean ignoreCase, int toffset, 1345 String other, int ooffset, int len) { 1346 char ta[] = value; 1347 int to = toffset; 1348 char pa[] = other.value; 1349 int po = ooffset; 1350 // Note: toffset, ooffset, or len might be near -1>>>1. 1351 if ((ooffset < 0) || (toffset < 0) 1352 || (toffset > (long)value.length - len) 1353 || (ooffset > (long)other.value.length - len)) { 1354 return false; 1355 } 1356 while (len-- > 0) { 1357 char c1 = ta[to++]; 1358 char c2 = pa[po++]; 1359 if (c1 == c2) { 1360 continue; 1361 } 1362 if (ignoreCase) { 1363 // If characters don't match but case may be ignored, 1364 // try converting both characters to uppercase. 1365 // If the results match, then the comparison scan should 1366 // continue. 1367 char u1 = Character.toUpperCase(c1); 1368 char u2 = Character.toUpperCase(c2); 1369 if (u1 == u2) { 1370 continue; 1371 } 1372 // Unfortunately, conversion to uppercase does not work properly 1373 // for the Georgian alphabet, which has strange rules about case 1374 // conversion. So we need to make one last check before 1375 // exiting. 1376 if (Character.toLowerCase(u1) == Character.toLowerCase(u2)) { 1377 continue; 1378 } 1379 } 1380 return false; 1381 } 1382 return true; 1383 } 1384 1385 /** 1386 * Tests if the substring of this string beginning at the 1387 * specified index starts with the specified prefix. 1388 * 1389 * @param prefix the prefix. 1390 * @param toffset where to begin looking in this string. 1391 * @return {@code true} if the character sequence represented by the 1392 * argument is a prefix of the substring of this object starting 1393 * at index {@code toffset}; {@code false} otherwise. 1394 * The result is {@code false} if {@code toffset} is 1395 * negative or greater than the length of this 1396 * {@code String} object; otherwise the result is the same 1397 * as the result of the expression 1398 * <pre> 1399 * this.substring(toffset).startsWith(prefix) 1400 * </pre> 1401 */ 1402 public boolean startsWith(String prefix, int toffset) { 1403 char ta[] = value; 1404 int to = toffset; 1405 char pa[] = prefix.value; 1406 int po = 0; 1407 int pc = prefix.value.length; 1408 // Note: toffset might be near -1>>>1. 1409 if ((toffset < 0) || (toffset > value.length - pc)) { 1410 return false; 1411 } 1412 while (--pc >= 0) { 1413 if (ta[to++] != pa[po++]) { 1414 return false; 1415 } 1416 } 1417 return true; 1418 } 1419 1420 /** 1421 * Tests if this string starts with the specified prefix. 1422 * 1423 * @param prefix the prefix. 1424 * @return {@code true} if the character sequence represented by the 1425 * argument is a prefix of the character sequence represented by 1426 * this string; {@code false} otherwise. 1427 * Note also that {@code true} will be returned if the 1428 * argument is an empty string or is equal to this 1429 * {@code String} object as determined by the 1430 * {@link #equals(Object)} method. 1431 * @since 1. 0 1432 */ 1433 public boolean startsWith(String prefix) { 1434 return startsWith(prefix, 0); 1435 } 1436 1437 /** 1438 * Tests if this string ends with the specified suffix. 1439 * 1440 * @param suffix the suffix. 1441 * @return {@code true} if the character sequence represented by the 1442 * argument is a suffix of the character sequence represented by 1443 * this object; {@code false} otherwise. Note that the 1444 * result will be {@code true} if the argument is the 1445 * empty string or is equal to this {@code String} object 1446 * as determined by the {@link #equals(Object)} method. 1447 */ 1448 public boolean endsWith(String suffix) { 1449 return startsWith(suffix, value.length - suffix.value.length); 1450 } 1451 1452 /** 1453 * Returns a hash code for this string. The hash code for a 1454 * {@code String} object is computed as 1455 * <blockquote><pre> 1456 * s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1] 1457 * </pre></blockquote> 1458 * using {@code int} arithmetic, where {@code s[i]} is the 1459 * <i>i</i>th character of the string, {@code n} is the length of 1460 * the string, and {@code ^} indicates exponentiation. 1461 * (The hash value of the empty string is zero.) 1462 * 1463 * @return a hash code value for this object. 1464 */ 1465 public int hashCode() { 1466 int h = hash; 1467 if (h == 0 && value.length > 0) { 1468 char val[] = value; 1469 1470 for (int i = 0; i < value.length; i++) { 1471 h = 31 * h + val[i]; 1472 } 1473 hash = h; 1474 } 1475 return h; 1476 } 1477 1478 /** 1479 * Returns the index within this string of the first occurrence of 1480 * the specified character. If a character with value 1481 * {@code ch} occurs in the character sequence represented by 1482 * this {@code String} object, then the index (in Unicode 1483 * code units) of the first such occurrence is returned. For 1484 * values of {@code ch} in the range from 0 to 0xFFFF 1485 * (inclusive), this is the smallest value <i>k</i> such that: 1486 * <blockquote><pre> 1487 * this.charAt(<i>k</i>) == ch 1488 * </pre></blockquote> 1489 * is true. For other values of {@code ch}, it is the 1490 * smallest value <i>k</i> such that: 1491 * <blockquote><pre> 1492 * this.codePointAt(<i>k</i>) == ch 1493 * </pre></blockquote> 1494 * is true. In either case, if no such character occurs in this 1495 * string, then {@code -1} is returned. 1496 * 1497 * @param ch a character (Unicode code point). 1498 * @return the index of the first occurrence of the character in the 1499 * character sequence represented by this object, or 1500 * {@code -1} if the character does not occur. 1501 */ 1502 public int indexOf(int ch) { 1503 return indexOf(ch, 0); 1504 } 1505 1506 /** 1507 * Returns the index within this string of the first occurrence of the 1508 * specified character, starting the search at the specified index. 1509 * <p> 1510 * If a character with value {@code ch} occurs in the 1511 * character sequence represented by this {@code String} 1512 * object at an index no smaller than {@code fromIndex}, then 1513 * the index of the first such occurrence is returned. For values 1514 * of {@code ch} in the range from 0 to 0xFFFF (inclusive), 1515 * this is the smallest value <i>k</i> such that: 1516 * <blockquote><pre> 1517 * (this.charAt(<i>k</i>) == ch) {@code &&} (<i>k</i> >= fromIndex) 1518 * </pre></blockquote> 1519 * is true. For other values of {@code ch}, it is the 1520 * smallest value <i>k</i> such that: 1521 * <blockquote><pre> 1522 * (this.codePointAt(<i>k</i>) == ch) {@code &&} (<i>k</i> >= fromIndex) 1523 * </pre></blockquote> 1524 * is true. In either case, if no such character occurs in this 1525 * string at or after position {@code fromIndex}, then 1526 * {@code -1} is returned. 1527 * 1528 * <p> 1529 * There is no restriction on the value of {@code fromIndex}. If it 1530 * is negative, it has the same effect as if it were zero: this entire 1531 * string may be searched. If it is greater than the length of this 1532 * string, it has the same effect as if it were equal to the length of 1533 * this string: {@code -1} is returned. 1534 * 1535 * <p>All indices are specified in {@code char} values 1536 * (Unicode code units). 1537 * 1538 * @param ch a character (Unicode code point). 1539 * @param fromIndex the index to start the search from. 1540 * @return the index of the first occurrence of the character in the 1541 * character sequence represented by this object that is greater 1542 * than or equal to {@code fromIndex}, or {@code -1} 1543 * if the character does not occur. 1544 */ 1545 public int indexOf(int ch, int fromIndex) { 1546 final int max = value.length; 1547 if (fromIndex < 0) { 1548 fromIndex = 0; 1549 } else if (fromIndex >= max) { 1550 // Note: fromIndex might be near -1>>>1. 1551 return -1; 1552 } 1553 1554 if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) { 1555 // handle most cases here (ch is a BMP code point or a 1556 // negative value (invalid code point)) 1557 final char[] value = this.value; 1558 for (int i = fromIndex; i < max; i++) { 1559 if (value[i] == ch) { 1560 return i; 1561 } 1562 } 1563 return -1; 1564 } else { 1565 return indexOfSupplementary(ch, fromIndex); 1566 } 1567 } 1568 1569 /** 1570 * Handles (rare) calls of indexOf with a supplementary character. 1571 */ 1572 private int indexOfSupplementary(int ch, int fromIndex) { 1573 if (Character.isValidCodePoint(ch)) { 1574 final char[] value = this.value; 1575 final char hi = Character.highSurrogate(ch); 1576 final char lo = Character.lowSurrogate(ch); 1577 final int max = value.length - 1; 1578 for (int i = fromIndex; i < max; i++) { 1579 if (value[i] == hi && value[i + 1] == lo) { 1580 return i; 1581 } 1582 } 1583 } 1584 return -1; 1585 } 1586 1587 /** 1588 * Returns the index within this string of the last occurrence of 1589 * the specified character. For values of {@code ch} in the 1590 * range from 0 to 0xFFFF (inclusive), the index (in Unicode code 1591 * units) returned is the largest value <i>k</i> such that: 1592 * <blockquote><pre> 1593 * this.charAt(<i>k</i>) == ch 1594 * </pre></blockquote> 1595 * is true. For other values of {@code ch}, it is the 1596 * largest value <i>k</i> such that: 1597 * <blockquote><pre> 1598 * this.codePointAt(<i>k</i>) == ch 1599 * </pre></blockquote> 1600 * is true. In either case, if no such character occurs in this 1601 * string, then {@code -1} is returned. The 1602 * {@code String} is searched backwards starting at the last 1603 * character. 1604 * 1605 * @param ch a character (Unicode code point). 1606 * @return the index of the last occurrence of the character in the 1607 * character sequence represented by this object, or 1608 * {@code -1} if the character does not occur. 1609 */ 1610 public int lastIndexOf(int ch) { 1611 return lastIndexOf(ch, value.length - 1); 1612 } 1613 1614 /** 1615 * Returns the index within this string of the last occurrence of 1616 * the specified character, searching backward starting at the 1617 * specified index. For values of {@code ch} in the range 1618 * from 0 to 0xFFFF (inclusive), the index returned is the largest 1619 * value <i>k</i> such that: 1620 * <blockquote><pre> 1621 * (this.charAt(<i>k</i>) == ch) {@code &&} (<i>k</i> <= fromIndex) 1622 * </pre></blockquote> 1623 * is true. For other values of {@code ch}, it is the 1624 * largest value <i>k</i> such that: 1625 * <blockquote><pre> 1626 * (this.codePointAt(<i>k</i>) == ch) {@code &&} (<i>k</i> <= fromIndex) 1627 * </pre></blockquote> 1628 * is true. In either case, if no such character occurs in this 1629 * string at or before position {@code fromIndex}, then 1630 * {@code -1} is returned. 1631 * 1632 * <p>All indices are specified in {@code char} values 1633 * (Unicode code units). 1634 * 1635 * @param ch a character (Unicode code point). 1636 * @param fromIndex the index to start the search from. There is no 1637 * restriction on the value of {@code fromIndex}. If it is 1638 * greater than or equal to the length of this string, it has 1639 * the same effect as if it were equal to one less than the 1640 * length of this string: this entire string may be searched. 1641 * If it is negative, it has the same effect as if it were -1: 1642 * -1 is returned. 1643 * @return the index of the last occurrence of the character in the 1644 * character sequence represented by this object that is less 1645 * than or equal to {@code fromIndex}, or {@code -1} 1646 * if the character does not occur before that point. 1647 */ 1648 public int lastIndexOf(int ch, int fromIndex) { 1649 if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) { 1650 // handle most cases here (ch is a BMP code point or a 1651 // negative value (invalid code point)) 1652 final char[] value = this.value; 1653 int i = Math.min(fromIndex, value.length - 1); 1654 for (; i >= 0; i--) { 1655 if (value[i] == ch) { 1656 return i; 1657 } 1658 } 1659 return -1; 1660 } else { 1661 return lastIndexOfSupplementary(ch, fromIndex); 1662 } 1663 } 1664 1665 /** 1666 * Handles (rare) calls of lastIndexOf with a supplementary character. 1667 */ 1668 private int lastIndexOfSupplementary(int ch, int fromIndex) { 1669 if (Character.isValidCodePoint(ch)) { 1670 final char[] value = this.value; 1671 char hi = Character.highSurrogate(ch); 1672 char lo = Character.lowSurrogate(ch); 1673 int i = Math.min(fromIndex, value.length - 2); 1674 for (; i >= 0; i--) { 1675 if (value[i] == hi && value[i + 1] == lo) { 1676 return i; 1677 } 1678 } 1679 } 1680 return -1; 1681 } 1682 1683 /** 1684 * Returns the index within this string of the first occurrence of the 1685 * specified substring. 1686 * 1687 * <p>The returned index is the smallest value <i>k</i> for which: 1688 * <blockquote><pre> 1689 * this.startsWith(str, <i>k</i>) 1690 * </pre></blockquote> 1691 * If no such value of <i>k</i> exists, then {@code -1} is returned. 1692 * 1693 * @param str the substring to search for. 1694 * @return the index of the first occurrence of the specified substring, 1695 * or {@code -1} if there is no such occurrence. 1696 */ 1697 public int indexOf(String str) { 1698 return indexOf(str, 0); 1699 } 1700 1701 /** 1702 * Returns the index within this string of the first occurrence of the 1703 * specified substring, starting at the specified index. 1704 * 1705 * <p>The returned index is the smallest value <i>k</i> for which: 1706 * <blockquote><pre> 1707 * <i>k</i> >= fromIndex {@code &&} this.startsWith(str, <i>k</i>) 1708 * </pre></blockquote> 1709 * If no such value of <i>k</i> exists, then {@code -1} is returned. 1710 * 1711 * @param str the substring to search for. 1712 * @param fromIndex the index from which to start the search. 1713 * @return the index of the first occurrence of the specified substring, 1714 * starting at the specified index, 1715 * or {@code -1} if there is no such occurrence. 1716 */ 1717 public int indexOf(String str, int fromIndex) { 1718 return indexOf(value, 0, value.length, 1719 str.value, 0, str.value.length, fromIndex); 1720 } 1721 1722 /** 1723 * Code shared by String and AbstractStringBuilder to do searches. The 1724 * source is the character array being searched, and the target 1725 * is the string being searched for. 1726 * 1727 * @param source the characters being searched. 1728 * @param sourceOffset offset of the source string. 1729 * @param sourceCount count of the source string. 1730 * @param target the characters being searched for. 1731 * @param fromIndex the index to begin searching from. 1732 */ 1733 static int indexOf(char[] source, int sourceOffset, int sourceCount, 1734 String target, int fromIndex) { 1735 return indexOf(source, sourceOffset, sourceCount, 1736 target.value, 0, target.value.length, 1737 fromIndex); 1738 } 1739 1740 /** 1741 * Code shared by String and StringBuffer to do searches. The 1742 * source is the character array being searched, and the target 1743 * is the string being searched for. 1744 * 1745 * @param source the characters being searched. 1746 * @param sourceOffset offset of the source string. 1747 * @param sourceCount count of the source string. 1748 * @param target the characters being searched for. 1749 * @param targetOffset offset of the target string. 1750 * @param targetCount count of the target string. 1751 * @param fromIndex the index to begin searching from. 1752 */ 1753 static int indexOf(char[] source, int sourceOffset, int sourceCount, 1754 char[] target, int targetOffset, int targetCount, 1755 int fromIndex) { 1756 if (fromIndex >= sourceCount) { 1757 return (targetCount == 0 ? sourceCount : -1); 1758 } 1759 if (fromIndex < 0) { 1760 fromIndex = 0; 1761 } 1762 if (targetCount == 0) { 1763 return fromIndex; 1764 } 1765 1766 char first = target[targetOffset]; 1767 int max = sourceOffset + (sourceCount - targetCount); 1768 1769 for (int i = sourceOffset + fromIndex; i <= max; i++) { 1770 /* Look for first character. */ 1771 if (source[i] != first) { 1772 while (++i <= max && source[i] != first); 1773 } 1774 1775 /* Found first character, now look at the rest of v2 */ 1776 if (i <= max) { 1777 int j = i + 1; 1778 int end = j + targetCount - 1; 1779 for (int k = targetOffset + 1; j < end && source[j] 1780 == target[k]; j++, k++); 1781 1782 if (j == end) { 1783 /* Found whole string. */ 1784 return i - sourceOffset; 1785 } 1786 } 1787 } 1788 return -1; 1789 } 1790 1791 /** 1792 * Returns the index within this string of the last occurrence of the 1793 * specified substring. The last occurrence of the empty string "" 1794 * is considered to occur at the index value {@code this.length()}. 1795 * 1796 * <p>The returned index is the largest value <i>k</i> for which: 1797 * <blockquote><pre> 1798 * this.startsWith(str, <i>k</i>) 1799 * </pre></blockquote> 1800 * If no such value of <i>k</i> exists, then {@code -1} is returned. 1801 * 1802 * @param str the substring to search for. 1803 * @return the index of the last occurrence of the specified substring, 1804 * or {@code -1} if there is no such occurrence. 1805 */ 1806 public int lastIndexOf(String str) { 1807 return lastIndexOf(str, value.length); 1808 } 1809 1810 /** 1811 * Returns the index within this string of the last occurrence of the 1812 * specified substring, searching backward starting at the specified index. 1813 * 1814 * <p>The returned index is the largest value <i>k</i> for which: 1815 * <blockquote><pre> 1816 * <i>k</i> {@code <=} fromIndex {@code &&} this.startsWith(str, <i>k</i>) 1817 * </pre></blockquote> 1818 * If no such value of <i>k</i> exists, then {@code -1} is returned. 1819 * 1820 * @param str the substring to search for. 1821 * @param fromIndex the index to start the search from. 1822 * @return the index of the last occurrence of the specified substring, 1823 * searching backward from the specified index, 1824 * or {@code -1} if there is no such occurrence. 1825 */ 1826 public int lastIndexOf(String str, int fromIndex) { 1827 return lastIndexOf(value, 0, value.length, 1828 str.value, 0, str.value.length, fromIndex); 1829 } 1830 1831 /** 1832 * Code shared by String and AbstractStringBuilder to do searches. The 1833 * source is the character array being searched, and the target 1834 * is the string being searched for. 1835 * 1836 * @param source the characters being searched. 1837 * @param sourceOffset offset of the source string. 1838 * @param sourceCount count of the source string. 1839 * @param target the characters being searched for. 1840 * @param fromIndex the index to begin searching from. 1841 */ 1842 static int lastIndexOf(char[] source, int sourceOffset, int sourceCount, 1843 String target, int fromIndex) { 1844 return lastIndexOf(source, sourceOffset, sourceCount, 1845 target.value, 0, target.value.length, 1846 fromIndex); 1847 } 1848 1849 /** 1850 * Code shared by String and StringBuffer to do searches. The 1851 * source is the character array being searched, and the target 1852 * is the string being searched for. 1853 * 1854 * @param source the characters being searched. 1855 * @param sourceOffset offset of the source string. 1856 * @param sourceCount count of the source string. 1857 * @param target the characters being searched for. 1858 * @param targetOffset offset of the target string. 1859 * @param targetCount count of the target string. 1860 * @param fromIndex the index to begin searching from. 1861 */ 1862 static int lastIndexOf(char[] source, int sourceOffset, int sourceCount, 1863 char[] target, int targetOffset, int targetCount, 1864 int fromIndex) { 1865 /* 1866 * Check arguments; return immediately where possible. For 1867 * consistency, don't check for null str. 1868 */ 1869 int rightIndex = sourceCount - targetCount; 1870 if (fromIndex < 0) { 1871 return -1; 1872 } 1873 if (fromIndex > rightIndex) { 1874 fromIndex = rightIndex; 1875 } 1876 /* Empty string always matches. */ 1877 if (targetCount == 0) { 1878 return fromIndex; 1879 } 1880 1881 int strLastIndex = targetOffset + targetCount - 1; 1882 char strLastChar = target[strLastIndex]; 1883 int min = sourceOffset + targetCount - 1; 1884 int i = min + fromIndex; 1885 1886 startSearchForLastChar: 1887 while (true) { 1888 while (i >= min && source[i] != strLastChar) { 1889 i--; 1890 } 1891 if (i < min) { 1892 return -1; 1893 } 1894 int j = i - 1; 1895 int start = j - (targetCount - 1); 1896 int k = strLastIndex - 1; 1897 1898 while (j > start) { 1899 if (source[j--] != target[k--]) { 1900 i--; 1901 continue startSearchForLastChar; 1902 } 1903 } 1904 return start - sourceOffset + 1; 1905 } 1906 } 1907 1908 /** 1909 * Returns a string that is a substring of this string. The 1910 * substring begins with the character at the specified index and 1911 * extends to the end of this string. <p> 1912 * Examples: 1913 * <blockquote><pre> 1914 * "unhappy".substring(2) returns "happy" 1915 * "Harbison".substring(3) returns "bison" 1916 * "emptiness".substring(9) returns "" (an empty string) 1917 * </pre></blockquote> 1918 * 1919 * @param beginIndex the beginning index, inclusive. 1920 * @return the specified substring. 1921 * @exception IndexOutOfBoundsException if 1922 * {@code beginIndex} is negative or larger than the 1923 * length of this {@code String} object. 1924 */ 1925 public String substring(int beginIndex) { 1926 if (beginIndex < 0) { 1927 throw new StringIndexOutOfBoundsException(beginIndex); 1928 } 1929 int subLen = value.length - beginIndex; 1930 if (subLen < 0) { 1931 throw new StringIndexOutOfBoundsException(subLen); 1932 } 1933 return (beginIndex == 0) ? this : new String(value, beginIndex, subLen); 1934 } 1935 1936 /** 1937 * Returns a string that is a substring of this string. The 1938 * substring begins at the specified {@code beginIndex} and 1939 * extends to the character at index {@code endIndex - 1}. 1940 * Thus the length of the substring is {@code endIndex-beginIndex}. 1941 * <p> 1942 * Examples: 1943 * <blockquote><pre> 1944 * "hamburger".substring(4, 8) returns "urge" 1945 * "smiles".substring(1, 5) returns "mile" 1946 * </pre></blockquote> 1947 * 1948 * @param beginIndex the beginning index, inclusive. 1949 * @param endIndex the ending index, exclusive. 1950 * @return the specified substring. 1951 * @exception IndexOutOfBoundsException if the 1952 * {@code beginIndex} is negative, or 1953 * {@code endIndex} is larger than the length of 1954 * this {@code String} object, or 1955 * {@code beginIndex} is larger than 1956 * {@code endIndex}. 1957 */ 1958 public String substring(int beginIndex, int endIndex) { 1959 if (beginIndex < 0) { 1960 throw new StringIndexOutOfBoundsException(beginIndex); 1961 } 1962 if (endIndex > value.length) { 1963 throw new StringIndexOutOfBoundsException(endIndex); 1964 } 1965 int subLen = endIndex - beginIndex; 1966 if (subLen < 0) { 1967 throw new StringIndexOutOfBoundsException(subLen); 1968 } 1969 return ((beginIndex == 0) && (endIndex == value.length)) ? this 1970 : new String(value, beginIndex, subLen); 1971 } 1972 1973 /** 1974 * Returns a character sequence that is a subsequence of this sequence. 1975 * 1976 * <p> An invocation of this method of the form 1977 * 1978 * <blockquote><pre> 1979 * str.subSequence(begin, end)</pre></blockquote> 1980 * 1981 * behaves in exactly the same way as the invocation 1982 * 1983 * <blockquote><pre> 1984 * str.substring(begin, end)</pre></blockquote> 1985 * 1986 * @apiNote 1987 * This method is defined so that the {@code String} class can implement 1988 * the {@link CharSequence} interface. 1989 * 1990 * @param beginIndex the begin index, inclusive. 1991 * @param endIndex the end index, exclusive. 1992 * @return the specified subsequence. 1993 * 1994 * @throws IndexOutOfBoundsException 1995 * if {@code beginIndex} or {@code endIndex} is negative, 1996 * if {@code endIndex} is greater than {@code length()}, 1997 * or if {@code beginIndex} is greater than {@code endIndex} 1998 * 1999 * @since 1.4 2000 * @spec JSR-51 2001 */ 2002 public CharSequence subSequence(int beginIndex, int endIndex) { 2003 return this.substring(beginIndex, endIndex); 2004 } 2005 2006 /** 2007 * Concatenates the specified string to the end of this string. 2008 * <p> 2009 * If the length of the argument string is {@code 0}, then this 2010 * {@code String} object is returned. Otherwise, a 2011 * {@code String} object is returned that represents a character 2012 * sequence that is the concatenation of the character sequence 2013 * represented by this {@code String} object and the character 2014 * sequence represented by the argument string.<p> 2015 * Examples: 2016 * <blockquote><pre> 2017 * "cares".concat("s") returns "caress" 2018 * "to".concat("get").concat("her") returns "together" 2019 * </pre></blockquote> 2020 * 2021 * @param str the {@code String} that is concatenated to the end 2022 * of this {@code String}. 2023 * @return a string that represents the concatenation of this object's 2024 * characters followed by the string argument's characters. 2025 */ 2026 public String concat(String str) { 2027 int otherLen = str.length(); 2028 if (otherLen == 0) { 2029 return this; 2030 } 2031 int len = value.length; 2032 char buf[] = Arrays.copyOf(value, len + otherLen); 2033 str.getChars(buf, len); 2034 return new String(buf, true); 2035 } 2036 2037 /** 2038 * Returns a string resulting from replacing all occurrences of 2039 * {@code oldChar} in this string with {@code newChar}. 2040 * <p> 2041 * If the character {@code oldChar} does not occur in the 2042 * character sequence represented by this {@code String} object, 2043 * then a reference to this {@code String} object is returned. 2044 * Otherwise, a {@code String} object is returned that 2045 * represents a character sequence identical to the character sequence 2046 * represented by this {@code String} object, except that every 2047 * occurrence of {@code oldChar} is replaced by an occurrence 2048 * of {@code newChar}. 2049 * <p> 2050 * Examples: 2051 * <blockquote><pre> 2052 * "mesquite in your cellar".replace('e', 'o') 2053 * returns "mosquito in your collar" 2054 * "the war of baronets".replace('r', 'y') 2055 * returns "the way of bayonets" 2056 * "sparring with a purple porpoise".replace('p', 't') 2057 * returns "starring with a turtle tortoise" 2058 * "JonL".replace('q', 'x') returns "JonL" (no change) 2059 * </pre></blockquote> 2060 * 2061 * @param oldChar the old character. 2062 * @param newChar the new character. 2063 * @return a string derived from this string by replacing every 2064 * occurrence of {@code oldChar} with {@code newChar}. 2065 */ 2066 public String replace(char oldChar, char newChar) { 2067 if (oldChar != newChar) { 2068 int len = value.length; 2069 int i = -1; 2070 char[] val = value; /* avoid getfield opcode */ 2071 2072 while (++i < len) { 2073 if (val[i] == oldChar) { 2074 break; 2075 } 2076 } 2077 if (i < len) { 2078 char buf[] = new char[len]; 2079 for (int j = 0; j < i; j++) { 2080 buf[j] = val[j]; 2081 } 2082 while (i < len) { 2083 char c = val[i]; 2084 buf[i] = (c == oldChar) ? newChar : c; 2085 i++; 2086 } 2087 return new String(buf, true); 2088 } 2089 } 2090 return this; 2091 } 2092 2093 /** 2094 * Tells whether or not this string matches the given <a 2095 * href="../util/regex/Pattern.html#sum">regular expression</a>. 2096 * 2097 * <p> An invocation of this method of the form 2098 * <i>str</i>{@code .matches(}<i>regex</i>{@code )} yields exactly the 2099 * same result as the expression 2100 * 2101 * <blockquote> 2102 * {@link java.util.regex.Pattern}.{@link java.util.regex.Pattern#matches(String,CharSequence) 2103 * matches(<i>regex</i>, <i>str</i>)} 2104 * </blockquote> 2105 * 2106 * @param regex 2107 * the regular expression to which this string is to be matched 2108 * 2109 * @return {@code true} if, and only if, this string matches the 2110 * given regular expression 2111 * 2112 * @throws PatternSyntaxException 2113 * if the regular expression's syntax is invalid 2114 * 2115 * @see java.util.regex.Pattern 2116 * 2117 * @since 1.4 2118 * @spec JSR-51 2119 */ 2120 public boolean matches(String regex) { 2121 return Pattern.matches(regex, this); 2122 } 2123 2124 /** 2125 * Returns true if and only if this string contains the specified 2126 * sequence of char values. 2127 * 2128 * @param s the sequence to search for 2129 * @return true if this string contains {@code s}, false otherwise 2130 * @since 1.5 2131 */ 2132 public boolean contains(CharSequence s) { 2133 return indexOf(s.toString()) > -1; 2134 } 2135 2136 /** 2137 * Replaces the first substring of this string that matches the given <a 2138 * href="../util/regex/Pattern.html#sum">regular expression</a> with the 2139 * given replacement. 2140 * 2141 * <p> An invocation of this method of the form 2142 * <i>str</i>{@code .replaceFirst(}<i>regex</i>{@code ,} <i>repl</i>{@code )} 2143 * yields exactly the same result as the expression 2144 * 2145 * <blockquote> 2146 * <code> 2147 * {@link java.util.regex.Pattern}.{@link 2148 * java.util.regex.Pattern#compile compile}(<i>regex</i>).{@link 2149 * java.util.regex.Pattern#matcher(java.lang.CharSequence) matcher}(<i>str</i>).{@link 2150 * java.util.regex.Matcher#replaceFirst replaceFirst}(<i>repl</i>) 2151 * </code> 2152 * </blockquote> 2153 * 2154 *<p> 2155 * Note that backslashes ({@code \}) and dollar signs ({@code $}) in the 2156 * replacement string may cause the results to be different than if it were 2157 * being treated as a literal replacement string; see 2158 * {@link java.util.regex.Matcher#replaceFirst}. 2159 * Use {@link java.util.regex.Matcher#quoteReplacement} to suppress the special 2160 * meaning of these characters, if desired. 2161 * 2162 * @param regex 2163 * the regular expression to which this string is to be matched 2164 * @param replacement 2165 * the string to be substituted for the first match 2166 * 2167 * @return The resulting {@code String} 2168 * 2169 * @throws PatternSyntaxException 2170 * if the regular expression's syntax is invalid 2171 * 2172 * @see java.util.regex.Pattern 2173 * 2174 * @since 1.4 2175 * @spec JSR-51 2176 */ 2177 public String replaceFirst(String regex, String replacement) { 2178 return Pattern.compile(regex).matcher(this).replaceFirst(replacement); 2179 } 2180 2181 /** 2182 * Replaces each substring of this string that matches the given <a 2183 * href="../util/regex/Pattern.html#sum">regular expression</a> with the 2184 * given replacement. 2185 * 2186 * <p> An invocation of this method of the form 2187 * <i>str</i>{@code .replaceAll(}<i>regex</i>{@code ,} <i>repl</i>{@code )} 2188 * yields exactly the same result as the expression 2189 * 2190 * <blockquote> 2191 * <code> 2192 * {@link java.util.regex.Pattern}.{@link 2193 * java.util.regex.Pattern#compile compile}(<i>regex</i>).{@link 2194 * java.util.regex.Pattern#matcher(java.lang.CharSequence) matcher}(<i>str</i>).{@link 2195 * java.util.regex.Matcher#replaceAll replaceAll}(<i>repl</i>) 2196 * </code> 2197 * </blockquote> 2198 * 2199 *<p> 2200 * Note that backslashes ({@code \}) and dollar signs ({@code $}) in the 2201 * replacement string may cause the results to be different than if it were 2202 * being treated as a literal replacement string; see 2203 * {@link java.util.regex.Matcher#replaceAll Matcher.replaceAll}. 2204 * Use {@link java.util.regex.Matcher#quoteReplacement} to suppress the special 2205 * meaning of these characters, if desired. 2206 * 2207 * @param regex 2208 * the regular expression to which this string is to be matched 2209 * @param replacement 2210 * the string to be substituted for each match 2211 * 2212 * @return The resulting {@code String} 2213 * 2214 * @throws PatternSyntaxException 2215 * if the regular expression's syntax is invalid 2216 * 2217 * @see java.util.regex.Pattern 2218 * 2219 * @since 1.4 2220 * @spec JSR-51 2221 */ 2222 public String replaceAll(String regex, String replacement) { 2223 return Pattern.compile(regex).matcher(this).replaceAll(replacement); 2224 } 2225 2226 /** 2227 * Replaces each substring of this string that matches the literal target 2228 * sequence with the specified literal replacement sequence. The 2229 * replacement proceeds from the beginning of the string to the end, for 2230 * example, replacing "aa" with "b" in the string "aaa" will result in 2231 * "ba" rather than "ab". 2232 * 2233 * @param target The sequence of char values to be replaced 2234 * @param replacement The replacement sequence of char values 2235 * @return The resulting string 2236 * @since 1.5 2237 */ 2238 public String replace(CharSequence target, CharSequence replacement) { 2239 return Pattern.compile(target.toString(), Pattern.LITERAL).matcher( 2240 this).replaceAll(Matcher.quoteReplacement(replacement.toString())); 2241 } 2242 2243 /** 2244 * Splits this string around matches of the given 2245 * <a href="../util/regex/Pattern.html#sum">regular expression</a>. 2246 * 2247 * <p> The array returned by this method contains each substring of this 2248 * string that is terminated by another substring that matches the given 2249 * expression or is terminated by the end of the string. The substrings in 2250 * the array are in the order in which they occur in this string. If the 2251 * expression does not match any part of the input then the resulting array 2252 * has just one element, namely this string. 2253 * 2254 * <p> When there is a positive-width match at the beginning of this 2255 * string then an empty leading substring is included at the beginning 2256 * of the resulting array. A zero-width match at the beginning however 2257 * never produces such empty leading substring. 2258 * 2259 * <p> The {@code limit} parameter controls the number of times the 2260 * pattern is applied and therefore affects the length of the resulting 2261 * array. If the limit <i>n</i> is greater than zero then the pattern 2262 * will be applied at most <i>n</i> - 1 times, the array's 2263 * length will be no greater than <i>n</i>, and the array's last entry 2264 * will contain all input beyond the last matched delimiter. If <i>n</i> 2265 * is non-positive then the pattern will be applied as many times as 2266 * possible and the array can have any length. If <i>n</i> is zero then 2267 * the pattern will be applied as many times as possible, the array can 2268 * have any length, and trailing empty strings will be discarded. 2269 * 2270 * <p> The string {@code "boo:and:foo"}, for example, yields the 2271 * following results with these parameters: 2272 * 2273 * <blockquote><table cellpadding=1 cellspacing=0 summary="Split example showing regex, limit, and result"> 2274 * <tr> 2275 * <th>Regex</th> 2276 * <th>Limit</th> 2277 * <th>Result</th> 2278 * </tr> 2279 * <tr><td align=center>:</td> 2280 * <td align=center>2</td> 2281 * <td>{@code { "boo", "and:foo" }}</td></tr> 2282 * <tr><td align=center>:</td> 2283 * <td align=center>5</td> 2284 * <td>{@code { "boo", "and", "foo" }}</td></tr> 2285 * <tr><td align=center>:</td> 2286 * <td align=center>-2</td> 2287 * <td>{@code { "boo", "and", "foo" }}</td></tr> 2288 * <tr><td align=center>o</td> 2289 * <td align=center>5</td> 2290 * <td>{@code { "b", "", ":and:f", "", "" }}</td></tr> 2291 * <tr><td align=center>o</td> 2292 * <td align=center>-2</td> 2293 * <td>{@code { "b", "", ":and:f", "", "" }}</td></tr> 2294 * <tr><td align=center>o</td> 2295 * <td align=center>0</td> 2296 * <td>{@code { "b", "", ":and:f" }}</td></tr> 2297 * </table></blockquote> 2298 * 2299 * <p> An invocation of this method of the form 2300 * <i>str.</i>{@code split(}<i>regex</i>{@code ,} <i>n</i>{@code )} 2301 * yields the same result as the expression 2302 * 2303 * <blockquote> 2304 * <code> 2305 * {@link java.util.regex.Pattern}.{@link 2306 * java.util.regex.Pattern#compile compile}(<i>regex</i>).{@link 2307 * java.util.regex.Pattern#split(java.lang.CharSequence,int) split}(<i>str</i>, <i>n</i>) 2308 * </code> 2309 * </blockquote> 2310 * 2311 * 2312 * @param regex 2313 * the delimiting regular expression 2314 * 2315 * @param limit 2316 * the result threshold, as described above 2317 * 2318 * @return the array of strings computed by splitting this string 2319 * around matches of the given regular expression 2320 * 2321 * @throws PatternSyntaxException 2322 * if the regular expression's syntax is invalid 2323 * 2324 * @see java.util.regex.Pattern 2325 * 2326 * @since 1.4 2327 * @spec JSR-51 2328 */ 2329 public String[] split(String regex, int limit) { 2330 /* fastpath if the regex is a 2331 (1)one-char String and this character is not one of the 2332 RegEx's meta characters ".$|()[{^?*+\\", or 2333 (2)two-char String and the first char is the backslash and 2334 the second is not the ascii digit or ascii letter. 2335 */ 2336 char ch = 0; 2337 if (((regex.value.length == 1 && 2338 ".$|()[{^?*+\\".indexOf(ch = regex.charAt(0)) == -1) || 2339 (regex.length() == 2 && 2340 regex.charAt(0) == '\\' && 2341 (((ch = regex.charAt(1))-'0')|('9'-ch)) < 0 && 2342 ((ch-'a')|('z'-ch)) < 0 && 2343 ((ch-'A')|('Z'-ch)) < 0)) && 2344 (ch < Character.MIN_HIGH_SURROGATE || 2345 ch > Character.MAX_LOW_SURROGATE)) 2346 { 2347 int off = 0; 2348 int next = 0; 2349 boolean limited = limit > 0; 2350 ArrayList<String> list = new ArrayList<>(); 2351 while ((next = indexOf(ch, off)) != -1) { 2352 if (!limited || list.size() < limit - 1) { 2353 list.add(substring(off, next)); 2354 off = next + 1; 2355 } else { // last one 2356 //assert (list.size() == limit - 1); 2357 list.add(substring(off, value.length)); 2358 off = value.length; 2359 break; 2360 } 2361 } 2362 // If no match was found, return this 2363 if (off == 0) 2364 return new String[]{this}; 2365 2366 // Add remaining segment 2367 if (!limited || list.size() < limit) 2368 list.add(substring(off, value.length)); 2369 2370 // Construct result 2371 int resultSize = list.size(); 2372 if (limit == 0) { 2373 while (resultSize > 0 && list.get(resultSize - 1).length() == 0) { 2374 resultSize--; 2375 } 2376 } 2377 String[] result = new String[resultSize]; 2378 return list.subList(0, resultSize).toArray(result); 2379 } 2380 return Pattern.compile(regex).split(this, limit); 2381 } 2382 2383 /** 2384 * Splits this string around matches of the given <a 2385 * href="../util/regex/Pattern.html#sum">regular expression</a>. 2386 * 2387 * <p> This method works as if by invoking the two-argument {@link 2388 * #split(String, int) split} method with the given expression and a limit 2389 * argument of zero. Trailing empty strings are therefore not included in 2390 * the resulting array. 2391 * 2392 * <p> The string {@code "boo:and:foo"}, for example, yields the following 2393 * results with these expressions: 2394 * 2395 * <blockquote><table cellpadding=1 cellspacing=0 summary="Split examples showing regex and result"> 2396 * <tr> 2397 * <th>Regex</th> 2398 * <th>Result</th> 2399 * </tr> 2400 * <tr><td align=center>:</td> 2401 * <td>{@code { "boo", "and", "foo" }}</td></tr> 2402 * <tr><td align=center>o</td> 2403 * <td>{@code { "b", "", ":and:f" }}</td></tr> 2404 * </table></blockquote> 2405 * 2406 * 2407 * @param regex 2408 * the delimiting regular expression 2409 * 2410 * @return the array of strings computed by splitting this string 2411 * around matches of the given regular expression 2412 * 2413 * @throws PatternSyntaxException 2414 * if the regular expression's syntax is invalid 2415 * 2416 * @see java.util.regex.Pattern 2417 * 2418 * @since 1.4 2419 * @spec JSR-51 2420 */ 2421 public String[] split(String regex) { 2422 return split(regex, 0); 2423 } 2424 2425 /** 2426 * Returns a new String composed of copies of the 2427 * {@code CharSequence elements} joined together with a copy of 2428 * the specified {@code delimiter}. 2429 * 2430 * <blockquote>For example, 2431 * <pre>{@code 2432 * String message = String.join("-", "Java", "is", "cool"); 2433 * // message returned is: "Java-is-cool" 2434 * }</pre></blockquote> 2435 * 2436 * Note that if an element is null, then {@code "null"} is added. 2437 * 2438 * @param delimiter the delimiter that separates each element 2439 * @param elements the elements to join together. 2440 * 2441 * @return a new {@code String} that is composed of the {@code elements} 2442 * separated by the {@code delimiter} 2443 * 2444 * @throws NullPointerException If {@code delimiter} or {@code elements} 2445 * is {@code null} 2446 * 2447 * @see java.util.StringJoiner 2448 * @since 1.8 2449 */ 2450 public static String join(CharSequence delimiter, CharSequence... elements) { 2451 Objects.requireNonNull(delimiter); 2452 Objects.requireNonNull(elements); 2453 // Number of elements not likely worth Arrays.stream overhead. 2454 StringJoiner joiner = new StringJoiner(delimiter); 2455 for (CharSequence cs: elements) { 2456 joiner.add(cs); 2457 } 2458 return joiner.toString(); 2459 } 2460 2461 /** 2462 * Returns a new {@code String} composed of copies of the 2463 * {@code CharSequence elements} joined together with a copy of the 2464 * specified {@code delimiter}. 2465 * 2466 * <blockquote>For example, 2467 * <pre>{@code 2468 * List<String> strings = new LinkedList<>(); 2469 * strings.add("Java");strings.add("is"); 2470 * strings.add("cool"); 2471 * String message = String.join(" ", strings); 2472 * //message returned is: "Java is cool" 2473 * 2474 * Set<String> strings = new LinkedHashSet<>(); 2475 * strings.add("Java"); strings.add("is"); 2476 * strings.add("very"); strings.add("cool"); 2477 * String message = String.join("-", strings); 2478 * //message returned is: "Java-is-very-cool" 2479 * }</pre></blockquote> 2480 * 2481 * Note that if an individual element is {@code null}, then {@code "null"} is added. 2482 * 2483 * @param delimiter a sequence of characters that is used to separate each 2484 * of the {@code elements} in the resulting {@code String} 2485 * @param elements an {@code Iterable} that will have its {@code elements} 2486 * joined together. 2487 * 2488 * @return a new {@code String} that is composed from the {@code elements} 2489 * argument 2490 * 2491 * @throws NullPointerException If {@code delimiter} or {@code elements} 2492 * is {@code null} 2493 * 2494 * @see #join(CharSequence,CharSequence...) 2495 * @see java.util.StringJoiner 2496 * @since 1.8 2497 */ 2498 public static String join(CharSequence delimiter, 2499 Iterable<? extends CharSequence> elements) { 2500 Objects.requireNonNull(delimiter); 2501 Objects.requireNonNull(elements); 2502 StringJoiner joiner = new StringJoiner(delimiter); 2503 for (CharSequence cs: elements) { 2504 joiner.add(cs); 2505 } 2506 return joiner.toString(); 2507 } 2508 2509 /** 2510 * Converts all of the characters in this {@code String} to lower 2511 * case using the rules of the given {@code Locale}. Case mapping is based 2512 * on the Unicode Standard version specified by the {@link java.lang.Character Character} 2513 * class. Since case mappings are not always 1:1 char mappings, the resulting 2514 * {@code String} may be a different length than the original {@code String}. 2515 * <p> 2516 * Examples of lowercase mappings are in the following table: 2517 * <table border="1" summary="Lowercase mapping examples showing language code of locale, upper case, lower case, and description"> 2518 * <tr> 2519 * <th>Language Code of Locale</th> 2520 * <th>Upper Case</th> 2521 * <th>Lower Case</th> 2522 * <th>Description</th> 2523 * </tr> 2524 * <tr> 2525 * <td>tr (Turkish)</td> 2526 * <td>\u0130</td> 2527 * <td>\u0069</td> 2528 * <td>capital letter I with dot above -> small letter i</td> 2529 * </tr> 2530 * <tr> 2531 * <td>tr (Turkish)</td> 2532 * <td>\u0049</td> 2533 * <td>\u0131</td> 2534 * <td>capital letter I -> small letter dotless i </td> 2535 * </tr> 2536 * <tr> 2537 * <td>(all)</td> 2538 * <td>French Fries</td> 2539 * <td>french fries</td> 2540 * <td>lowercased all chars in String</td> 2541 * </tr> 2542 * <tr> 2543 * <td>(all)</td> 2544 * <td><img src="doc-files/capiota.gif" alt="capiota"><img src="doc-files/capchi.gif" alt="capchi"> 2545 * <img src="doc-files/captheta.gif" alt="captheta"><img src="doc-files/capupsil.gif" alt="capupsil"> 2546 * <img src="doc-files/capsigma.gif" alt="capsigma"></td> 2547 * <td><img src="doc-files/iota.gif" alt="iota"><img src="doc-files/chi.gif" alt="chi"> 2548 * <img src="doc-files/theta.gif" alt="theta"><img src="doc-files/upsilon.gif" alt="upsilon"> 2549 * <img src="doc-files/sigma1.gif" alt="sigma"></td> 2550 * <td>lowercased all chars in String</td> 2551 * </tr> 2552 * </table> 2553 * 2554 * @param locale use the case transformation rules for this locale 2555 * @return the {@code String}, converted to lowercase. 2556 * @see java.lang.String#toLowerCase() 2557 * @see java.lang.String#toUpperCase() 2558 * @see java.lang.String#toUpperCase(Locale) 2559 * @since 1.1 2560 */ 2561 public String toLowerCase(Locale locale) { 2562 if (locale == null) { 2563 throw new NullPointerException(); 2564 } 2565 2566 int firstUpper; 2567 final int len = value.length; 2568 2569 /* Now check if there are any characters that need to be changed. */ 2570 scan: { 2571 for (firstUpper = 0 ; firstUpper < len; ) { 2572 char c = value[firstUpper]; 2573 if ((c >= Character.MIN_HIGH_SURROGATE) 2574 && (c <= Character.MAX_HIGH_SURROGATE)) { 2575 int supplChar = codePointAt(firstUpper); 2576 if (supplChar != Character.toLowerCase(supplChar)) { 2577 break scan; 2578 } 2579 firstUpper += Character.charCount(supplChar); 2580 } else { 2581 if (c != Character.toLowerCase(c)) { 2582 break scan; 2583 } 2584 firstUpper++; 2585 } 2586 } 2587 return this; 2588 } 2589 2590 char[] result = new char[len]; 2591 int resultOffset = 0; /* result may grow, so i+resultOffset 2592 * is the write location in result */ 2593 2594 /* Just copy the first few lowerCase characters. */ 2595 System.arraycopy(value, 0, result, 0, firstUpper); 2596 2597 String lang = locale.getLanguage(); 2598 boolean localeDependent = 2599 (lang == "tr" || lang == "az" || lang == "lt"); 2600 char[] lowerCharArray; 2601 int lowerChar; 2602 int srcChar; 2603 int srcCount; 2604 for (int i = firstUpper; i < len; i += srcCount) { 2605 srcChar = (int)value[i]; 2606 if ((char)srcChar >= Character.MIN_HIGH_SURROGATE 2607 && (char)srcChar <= Character.MAX_HIGH_SURROGATE) { 2608 srcChar = codePointAt(i); 2609 srcCount = Character.charCount(srcChar); 2610 } else { 2611 srcCount = 1; 2612 } 2613 if (localeDependent || 2614 srcChar == '\u03A3' || // GREEK CAPITAL LETTER SIGMA 2615 srcChar == '\u0130') { // LATIN CAPITAL LETTER I WITH DOT ABOVE 2616 lowerChar = ConditionalSpecialCasing.toLowerCaseEx(this, i, locale); 2617 } else { 2618 lowerChar = Character.toLowerCase(srcChar); 2619 } 2620 if ((lowerChar == Character.ERROR) 2621 || (lowerChar >= Character.MIN_SUPPLEMENTARY_CODE_POINT)) { 2622 if (lowerChar == Character.ERROR) { 2623 lowerCharArray = 2624 ConditionalSpecialCasing.toLowerCaseCharArray(this, i, locale); 2625 } else if (srcCount == 2) { 2626 resultOffset += Character.toChars(lowerChar, result, i + resultOffset) - srcCount; 2627 continue; 2628 } else { 2629 lowerCharArray = Character.toChars(lowerChar); 2630 } 2631 2632 /* Grow result if needed */ 2633 int mapLen = lowerCharArray.length; 2634 if (mapLen > srcCount) { 2635 char[] result2 = new char[result.length + mapLen - srcCount]; 2636 System.arraycopy(result, 0, result2, 0, i + resultOffset); 2637 result = result2; 2638 } 2639 for (int x = 0; x < mapLen; ++x) { 2640 result[i + resultOffset + x] = lowerCharArray[x]; 2641 } 2642 resultOffset += (mapLen - srcCount); 2643 } else { 2644 result[i + resultOffset] = (char)lowerChar; 2645 } 2646 } 2647 return new String(result, 0, len + resultOffset); 2648 } 2649 2650 /** 2651 * Converts all of the characters in this {@code String} to lower 2652 * case using the rules of the default locale. This is equivalent to calling 2653 * {@code toLowerCase(Locale.getDefault())}. 2654 * <p> 2655 * <b>Note:</b> This method is locale sensitive, and may produce unexpected 2656 * results if used for strings that are intended to be interpreted locale 2657 * independently. 2658 * Examples are programming language identifiers, protocol keys, and HTML 2659 * tags. 2660 * For instance, {@code "TITLE".toLowerCase()} in a Turkish locale 2661 * returns {@code "t\u005Cu0131tle"}, where '\u005Cu0131' is the 2662 * LATIN SMALL LETTER DOTLESS I character. 2663 * To obtain correct results for locale insensitive strings, use 2664 * {@code toLowerCase(Locale.ROOT)}. 2665 * <p> 2666 * @return the {@code String}, converted to lowercase. 2667 * @see java.lang.String#toLowerCase(Locale) 2668 */ 2669 public String toLowerCase() { 2670 return toLowerCase(Locale.getDefault()); 2671 } 2672 2673 /** 2674 * Converts all of the characters in this {@code String} to upper 2675 * case using the rules of the given {@code Locale}. Case mapping is based 2676 * on the Unicode Standard version specified by the {@link java.lang.Character Character} 2677 * class. Since case mappings are not always 1:1 char mappings, the resulting 2678 * {@code String} may be a different length than the original {@code String}. 2679 * <p> 2680 * Examples of locale-sensitive and 1:M case mappings are in the following table. 2681 * 2682 * <table border="1" summary="Examples of locale-sensitive and 1:M case mappings. Shows Language code of locale, lower case, upper case, and description."> 2683 * <tr> 2684 * <th>Language Code of Locale</th> 2685 * <th>Lower Case</th> 2686 * <th>Upper Case</th> 2687 * <th>Description</th> 2688 * </tr> 2689 * <tr> 2690 * <td>tr (Turkish)</td> 2691 * <td>\u0069</td> 2692 * <td>\u0130</td> 2693 * <td>small letter i -> capital letter I with dot above</td> 2694 * </tr> 2695 * <tr> 2696 * <td>tr (Turkish)</td> 2697 * <td>\u0131</td> 2698 * <td>\u0049</td> 2699 * <td>small letter dotless i -> capital letter I</td> 2700 * </tr> 2701 * <tr> 2702 * <td>(all)</td> 2703 * <td>\u00df</td> 2704 * <td>\u0053 \u0053</td> 2705 * <td>small letter sharp s -> two letters: SS</td> 2706 * </tr> 2707 * <tr> 2708 * <td>(all)</td> 2709 * <td>Fahrvergnügen</td> 2710 * <td>FAHRVERGNÜGEN</td> 2711 * <td></td> 2712 * </tr> 2713 * </table> 2714 * @param locale use the case transformation rules for this locale 2715 * @return the {@code String}, converted to uppercase. 2716 * @see java.lang.String#toUpperCase() 2717 * @see java.lang.String#toLowerCase() 2718 * @see java.lang.String#toLowerCase(Locale) 2719 * @since 1.1 2720 */ 2721 public String toUpperCase(Locale locale) { 2722 if (locale == null) { 2723 throw new NullPointerException(); 2724 } 2725 2726 int firstLower; 2727 final int len = value.length; 2728 2729 /* Now check if there are any characters that need to be changed. */ 2730 scan: { 2731 for (firstLower = 0 ; firstLower < len; ) { 2732 int c = (int)value[firstLower]; 2733 int srcCount; 2734 if ((c >= Character.MIN_HIGH_SURROGATE) 2735 && (c <= Character.MAX_HIGH_SURROGATE)) { 2736 c = codePointAt(firstLower); 2737 srcCount = Character.charCount(c); 2738 } else { 2739 srcCount = 1; 2740 } 2741 int upperCaseChar = Character.toUpperCaseEx(c); 2742 if ((upperCaseChar == Character.ERROR) 2743 || (c != upperCaseChar)) { 2744 break scan; 2745 } 2746 firstLower += srcCount; 2747 } 2748 return this; 2749 } 2750 2751 /* result may grow, so i+resultOffset is the write location in result */ 2752 int resultOffset = 0; 2753 char[] result = new char[len]; /* may grow */ 2754 2755 /* Just copy the first few upperCase characters. */ 2756 System.arraycopy(value, 0, result, 0, firstLower); 2757 2758 String lang = locale.getLanguage(); 2759 boolean localeDependent = 2760 (lang == "tr" || lang == "az" || lang == "lt"); 2761 char[] upperCharArray; 2762 int upperChar; 2763 int srcChar; 2764 int srcCount; 2765 for (int i = firstLower; i < len; i += srcCount) { 2766 srcChar = (int)value[i]; 2767 if ((char)srcChar >= Character.MIN_HIGH_SURROGATE && 2768 (char)srcChar <= Character.MAX_HIGH_SURROGATE) { 2769 srcChar = codePointAt(i); 2770 srcCount = Character.charCount(srcChar); 2771 } else { 2772 srcCount = 1; 2773 } 2774 if (localeDependent) { 2775 upperChar = ConditionalSpecialCasing.toUpperCaseEx(this, i, locale); 2776 } else { 2777 upperChar = Character.toUpperCaseEx(srcChar); 2778 } 2779 if ((upperChar == Character.ERROR) 2780 || (upperChar >= Character.MIN_SUPPLEMENTARY_CODE_POINT)) { 2781 if (upperChar == Character.ERROR) { 2782 if (localeDependent) { 2783 upperCharArray = 2784 ConditionalSpecialCasing.toUpperCaseCharArray(this, i, locale); 2785 } else { 2786 upperCharArray = Character.toUpperCaseCharArray(srcChar); 2787 } 2788 } else if (srcCount == 2) { 2789 resultOffset += Character.toChars(upperChar, result, i + resultOffset) - srcCount; 2790 continue; 2791 } else { 2792 upperCharArray = Character.toChars(upperChar); 2793 } 2794 2795 /* Grow result if needed */ 2796 int mapLen = upperCharArray.length; 2797 if (mapLen > srcCount) { 2798 char[] result2 = new char[result.length + mapLen - srcCount]; 2799 System.arraycopy(result, 0, result2, 0, i + resultOffset); 2800 result = result2; 2801 } 2802 for (int x = 0; x < mapLen; ++x) { 2803 result[i + resultOffset + x] = upperCharArray[x]; 2804 } 2805 resultOffset += (mapLen - srcCount); 2806 } else { 2807 result[i + resultOffset] = (char)upperChar; 2808 } 2809 } 2810 return new String(result, 0, len + resultOffset); 2811 } 2812 2813 /** 2814 * Converts all of the characters in this {@code String} to upper 2815 * case using the rules of the default locale. This method is equivalent to 2816 * {@code toUpperCase(Locale.getDefault())}. 2817 * <p> 2818 * <b>Note:</b> This method is locale sensitive, and may produce unexpected 2819 * results if used for strings that are intended to be interpreted locale 2820 * independently. 2821 * Examples are programming language identifiers, protocol keys, and HTML 2822 * tags. 2823 * For instance, {@code "title".toUpperCase()} in a Turkish locale 2824 * returns {@code "T\u005Cu0130TLE"}, where '\u005Cu0130' is the 2825 * LATIN CAPITAL LETTER I WITH DOT ABOVE character. 2826 * To obtain correct results for locale insensitive strings, use 2827 * {@code toUpperCase(Locale.ROOT)}. 2828 * <p> 2829 * @return the {@code String}, converted to uppercase. 2830 * @see java.lang.String#toUpperCase(Locale) 2831 */ 2832 public String toUpperCase() { 2833 return toUpperCase(Locale.getDefault()); 2834 } 2835 2836 /** 2837 * Returns a string whose value is this string, with any leading and trailing 2838 * whitespace removed. 2839 * <p> 2840 * If this {@code String} object represents an empty character 2841 * sequence, or the first and last characters of character sequence 2842 * represented by this {@code String} object both have codes 2843 * greater than {@code '\u005Cu0020'} (the space character), then a 2844 * reference to this {@code String} object is returned. 2845 * <p> 2846 * Otherwise, if there is no character with a code greater than 2847 * {@code '\u005Cu0020'} in the string, then a 2848 * {@code String} object representing an empty string is 2849 * returned. 2850 * <p> 2851 * Otherwise, let <i>k</i> be the index of the first character in the 2852 * string whose code is greater than {@code '\u005Cu0020'}, and let 2853 * <i>m</i> be the index of the last character in the string whose code 2854 * is greater than {@code '\u005Cu0020'}. A {@code String} 2855 * object is returned, representing the substring of this string that 2856 * begins with the character at index <i>k</i> and ends with the 2857 * character at index <i>m</i>-that is, the result of 2858 * {@code this.substring(k, m + 1)}. 2859 * <p> 2860 * This method may be used to trim whitespace (as defined above) from 2861 * the beginning and end of a string. 2862 * 2863 * @return A string whose value is this string, with any leading and trailing white 2864 * space removed, or this string if it has no leading or 2865 * trailing white space. 2866 */ 2867 public String trim() { 2868 int len = value.length; 2869 int st = 0; 2870 char[] val = value; /* avoid getfield opcode */ 2871 2872 while ((st < len) && (val[st] <= ' ')) { 2873 st++; 2874 } 2875 while ((st < len) && (val[len - 1] <= ' ')) { 2876 len--; 2877 } 2878 return ((st > 0) || (len < value.length)) ? substring(st, len) : this; 2879 } 2880 2881 /** 2882 * This object (which is already a string!) is itself returned. 2883 * 2884 * @return the string itself. 2885 */ 2886 public String toString() { 2887 return this; 2888 } 2889 2890 /** 2891 * Converts this string to a new character array. 2892 * 2893 * @return a newly allocated character array whose length is the length 2894 * of this string and whose contents are initialized to contain 2895 * the character sequence represented by this string. 2896 */ 2897 public char[] toCharArray() { 2898 // Cannot use Arrays.copyOf because of class initialization order issues 2899 char result[] = new char[value.length]; 2900 System.arraycopy(value, 0, result, 0, value.length); 2901 return result; 2902 } 2903 2904 /** 2905 * Returns a formatted string using the specified format string and 2906 * arguments. 2907 * 2908 * <p> The locale always used is the one returned by {@link 2909 * java.util.Locale#getDefault() Locale.getDefault()}. 2910 * 2911 * @param format 2912 * A <a href="../util/Formatter.html#syntax">format string</a> 2913 * 2914 * @param args 2915 * Arguments referenced by the format specifiers in the format 2916 * string. If there are more arguments than format specifiers, the 2917 * extra arguments are ignored. The number of arguments is 2918 * variable and may be zero. The maximum number of arguments is 2919 * limited by the maximum dimension of a Java array as defined by 2920 * <cite>The Java™ Virtual Machine Specification</cite>. 2921 * The behaviour on a 2922 * {@code null} argument depends on the <a 2923 * href="../util/Formatter.html#syntax">conversion</a>. 2924 * 2925 * @throws java.util.IllegalFormatException 2926 * If a format string contains an illegal syntax, a format 2927 * specifier that is incompatible with the given arguments, 2928 * insufficient arguments given the format string, or other 2929 * illegal conditions. For specification of all possible 2930 * formatting errors, see the <a 2931 * href="../util/Formatter.html#detail">Details</a> section of the 2932 * formatter class specification. 2933 * 2934 * @return A formatted string 2935 * 2936 * @see java.util.Formatter 2937 * @since 1.5 2938 */ 2939 public static String format(String format, Object... args) { 2940 return new Formatter().format(format, args).toString(); 2941 } 2942 2943 /** 2944 * Returns a formatted string using the specified locale, format string, 2945 * and arguments. 2946 * 2947 * @param l 2948 * The {@linkplain java.util.Locale locale} to apply during 2949 * formatting. If {@code l} is {@code null} then no localization 2950 * is applied. 2951 * 2952 * @param format 2953 * A <a href="../util/Formatter.html#syntax">format string</a> 2954 * 2955 * @param args 2956 * Arguments referenced by the format specifiers in the format 2957 * string. If there are more arguments than format specifiers, the 2958 * extra arguments are ignored. The number of arguments is 2959 * variable and may be zero. The maximum number of arguments is 2960 * limited by the maximum dimension of a Java array as defined by 2961 * <cite>The Java™ Virtual Machine Specification</cite>. 2962 * The behaviour on a 2963 * {@code null} argument depends on the 2964 * <a href="../util/Formatter.html#syntax">conversion</a>. 2965 * 2966 * @throws java.util.IllegalFormatException 2967 * If a format string contains an illegal syntax, a format 2968 * specifier that is incompatible with the given arguments, 2969 * insufficient arguments given the format string, or other 2970 * illegal conditions. For specification of all possible 2971 * formatting errors, see the <a 2972 * href="../util/Formatter.html#detail">Details</a> section of the 2973 * formatter class specification 2974 * 2975 * @return A formatted string 2976 * 2977 * @see java.util.Formatter 2978 * @since 1.5 2979 */ 2980 public static String format(Locale l, String format, Object... args) { 2981 return new Formatter(l).format(format, args).toString(); 2982 } 2983 2984 /** 2985 * Returns the string representation of the {@code Object} argument. 2986 * 2987 * @param obj an {@code Object}. 2988 * @return if the argument is {@code null}, then a string equal to 2989 * {@code "null"}; otherwise, the value of 2990 * {@code obj.toString()} is returned. 2991 * @see java.lang.Object#toString() 2992 */ 2993 public static String valueOf(Object obj) { 2994 return (obj == null) ? "null" : obj.toString(); 2995 } 2996 2997 /** 2998 * Returns the string representation of the {@code char} array 2999 * argument. The contents of the character array are copied; subsequent 3000 * modification of the character array does not affect the returned 3001 * string. 3002 * 3003 * @param data the character array. 3004 * @return a {@code String} that contains the characters of the 3005 * character array. 3006 */ 3007 public static String valueOf(char data[]) { 3008 return new String(data); 3009 } 3010 3011 /** 3012 * Returns the string representation of a specific subarray of the 3013 * {@code char} array argument. 3014 * <p> 3015 * The {@code offset} argument is the index of the first 3016 * character of the subarray. The {@code count} argument 3017 * specifies the length of the subarray. The contents of the subarray 3018 * are copied; subsequent modification of the character array does not 3019 * affect the returned string. 3020 * 3021 * @param data the character array. 3022 * @param offset initial offset of the subarray. 3023 * @param count length of the subarray. 3024 * @return a {@code String} that contains the characters of the 3025 * specified subarray of the character array. 3026 * @exception IndexOutOfBoundsException if {@code offset} is 3027 * negative, or {@code count} is negative, or 3028 * {@code offset+count} is larger than 3029 * {@code data.length}. 3030 */ 3031 public static String valueOf(char data[], int offset, int count) { 3032 return new String(data, offset, count); 3033 } 3034 3035 /** 3036 * Equivalent to {@link #valueOf(char[], int, int)}. 3037 * 3038 * @param data the character array. 3039 * @param offset initial offset of the subarray. 3040 * @param count length of the subarray. 3041 * @return a {@code String} that contains the characters of the 3042 * specified subarray of the character array. 3043 * @exception IndexOutOfBoundsException if {@code offset} is 3044 * negative, or {@code count} is negative, or 3045 * {@code offset+count} is larger than 3046 * {@code data.length}. 3047 */ 3048 public static String copyValueOf(char data[], int offset, int count) { 3049 return new String(data, offset, count); 3050 } 3051 3052 /** 3053 * Equivalent to {@link #valueOf(char[])}. 3054 * 3055 * @param data the character array. 3056 * @return a {@code String} that contains the characters of the 3057 * character array. 3058 */ 3059 public static String copyValueOf(char data[]) { 3060 return new String(data); 3061 } 3062 3063 /** 3064 * Returns the string representation of the {@code boolean} argument. 3065 * 3066 * @param b a {@code boolean}. 3067 * @return if the argument is {@code true}, a string equal to 3068 * {@code "true"} is returned; otherwise, a string equal to 3069 * {@code "false"} is returned. 3070 */ 3071 public static String valueOf(boolean b) { 3072 return b ? "true" : "false"; 3073 } 3074 3075 /** 3076 * Returns the string representation of the {@code char} 3077 * argument. 3078 * 3079 * @param c a {@code char}. 3080 * @return a string of length {@code 1} containing 3081 * as its single character the argument {@code c}. 3082 */ 3083 public static String valueOf(char c) { 3084 char data[] = {c}; 3085 return new String(data, true); 3086 } 3087 3088 /** 3089 * Returns the string representation of the {@code int} argument. 3090 * <p> 3091 * The representation is exactly the one returned by the 3092 * {@code Integer.toString} method of one argument. 3093 * 3094 * @param i an {@code int}. 3095 * @return a string representation of the {@code int} argument. 3096 * @see java.lang.Integer#toString(int, int) 3097 */ 3098 public static String valueOf(int i) { 3099 return Integer.toString(i); 3100 } 3101 3102 /** 3103 * Returns the string representation of the {@code long} argument. 3104 * <p> 3105 * The representation is exactly the one returned by the 3106 * {@code Long.toString} method of one argument. 3107 * 3108 * @param l a {@code long}. 3109 * @return a string representation of the {@code long} argument. 3110 * @see java.lang.Long#toString(long) 3111 */ 3112 public static String valueOf(long l) { 3113 return Long.toString(l); 3114 } 3115 3116 /** 3117 * Returns the string representation of the {@code float} argument. 3118 * <p> 3119 * The representation is exactly the one returned by the 3120 * {@code Float.toString} method of one argument. 3121 * 3122 * @param f a {@code float}. 3123 * @return a string representation of the {@code float} argument. 3124 * @see java.lang.Float#toString(float) 3125 */ 3126 public static String valueOf(float f) { 3127 return Float.toString(f); 3128 } 3129 3130 /** 3131 * Returns the string representation of the {@code double} argument. 3132 * <p> 3133 * The representation is exactly the one returned by the 3134 * {@code Double.toString} method of one argument. 3135 * 3136 * @param d a {@code double}. 3137 * @return a string representation of the {@code double} argument. 3138 * @see java.lang.Double#toString(double) 3139 */ 3140 public static String valueOf(double d) { 3141 return Double.toString(d); 3142 } 3143 3144 /** 3145 * Returns a canonical representation for the string object. 3146 * <p> 3147 * A pool of strings, initially empty, is maintained privately by the 3148 * class {@code String}. 3149 * <p> 3150 * When the intern method is invoked, if the pool already contains a 3151 * string equal to this {@code String} object as determined by 3152 * the {@link #equals(Object)} method, then the string from the pool is 3153 * returned. Otherwise, this {@code String} object is added to the 3154 * pool and a reference to this {@code String} object is returned. 3155 * <p> 3156 * It follows that for any two strings {@code s} and {@code t}, 3157 * {@code s.intern() == t.intern()} is {@code true} 3158 * if and only if {@code s.equals(t)} is {@code true}. 3159 * <p> 3160 * All literal strings and string-valued constant expressions are 3161 * interned. String literals are defined in section 3.10.5 of the 3162 * <cite>The Java™ Language Specification</cite>. 3163 * 3164 * @return a string that has the same contents as this string, but is 3165 * guaranteed to be from a pool of unique strings. 3166 */ 3167 public native String intern(); 3168 }


再看一下其中的equals(),我们发现首先是看看是不是同一个对象,这个是和Object中的equals()一样的,否则如果是String类型或者继承该类型(不可能,因为String是final修饰的)的我们就比较,看看这两个字符串中的每一个字符是否相等,如果完全相等,则也返回true,这样就弥补了Object的缺点。
1 public boolean equals(Object anObject) { 2 if (this == anObject) { 3 return true; 4 } 5 if (anObject instanceof String) { 6 String anotherString = (String)anObject; 7 int n = value.length; 8 if (n == anotherString.value.length) { 9 char v1[] = value; 10 char v2[] = anotherString.value; 11 int i = 0; 12 while (n-- != 0) { 13 if (v1[i] != v2[i]) 14 return false; 15 i++; 16 } 17 return true; 18 } 19 } 20 return false; 21 }
下面是一个比较的例子,对于不使用new来产生的对象,其实存在方法区,作为静态常量处理,只有一个,因此比较起来就相等了;对于new创建出来的就直接放到了堆栈区了,创建了两个对象,因此引用不相等,但是值相等。
1 package com.consumer.test; 2 3 public class StringTest { 4 public static void main(String[] args) { 5 String i1="这是字符串"; 6 String i2="这是字符串"; 7 String i3=new String("这是字符串"); 8 String i4=new String("这是字符串"); 9 10 System.out.println("测试:"+(i1==i2)); 11 System.out.println("测试:"+(i3==i4)); 12 13 System.out.println("测试"+ (i1.equals(i2))); 14 System.out.println("测试"+ (i3.equals(i4))); 15 } 16 }
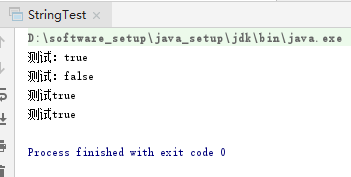
String的valueOf():
1 public static String valueOf(Object obj) { 2 return (obj == null) ? "null" : obj.toString(); 3 }
1 public String toString() { 2 return getClass().getName() + "@" + Integer.toHexString(hashCode()); 3 }

2.3、Integer中的equals()
最后让我们看看Integer中的equals方法,这里就更加的特殊了。
1 /* 2 * Copyright (c) 1994, 2013, Oracle and/or its affiliates. All rights reserved. 3 * ORACLE PROPRIETARY/CONFIDENTIAL. Use is subject to license terms. 4 * 5 * 6 * 7 * 8 * 9 * 10 * 11 * 12 * 13 * 14 * 15 * 16 * 17 * 18 * 19 * 20 * 21 * 22 * 23 * 24 */ 25 26 package java.lang; 27 28 import java.lang.annotation.Native; 29 30 /** 31 * The {@code Integer} class wraps a value of the primitive type 32 * {@code int} in an object. An object of type {@code Integer} 33 * contains a single field whose type is {@code int}. 34 * 35 * <p>In addition, this class provides several methods for converting 36 * an {@code int} to a {@code String} and a {@code String} to an 37 * {@code int}, as well as other constants and methods useful when 38 * dealing with an {@code int}. 39 * 40 * <p>Implementation note: The implementations of the "bit twiddling" 41 * methods (such as {@link #highestOneBit(int) highestOneBit} and 42 * {@link #numberOfTrailingZeros(int) numberOfTrailingZeros}) are 43 * based on material from Henry S. Warren, Jr.'s <i>Hacker's 44 * Delight</i>, (Addison Wesley, 2002). 45 * 46 * @author Lee Boynton 47 * @author Arthur van Hoff 48 * @author Josh Bloch 49 * @author Joseph D. Darcy 50 * @since JDK1.0 51 */ 52 public final class Integer extends Number implements Comparable<Integer> { 53 /** 54 * A constant holding the minimum value an {@code int} can 55 * have, -2<sup>31</sup>. 56 */ 57 @Native public static final int MIN_VALUE = 0x80000000; 58 59 /** 60 * A constant holding the maximum value an {@code int} can 61 * have, 2<sup>31</sup>-1. 62 */ 63 @Native public static final int MAX_VALUE = 0x7fffffff; 64 65 /** 66 * The {@code Class} instance representing the primitive type 67 * {@code int}. 68 * 69 * @since JDK1.1 70 */ 71 @SuppressWarnings("unchecked") 72 public static final Class<Integer> TYPE = (Class<Integer>) Class.getPrimitiveClass("int"); 73 74 /** 75 * All possible chars for representing a number as a String 76 */ 77 final static char[] digits = { 78 '0' , '1' , '2' , '3' , '4' , '5' , 79 '6' , '7' , '8' , '9' , 'a' , 'b' , 80 'c' , 'd' , 'e' , 'f' , 'g' , 'h' , 81 'i' , 'j' , 'k' , 'l' , 'm' , 'n' , 82 'o' , 'p' , 'q' , 'r' , 's' , 't' , 83 'u' , 'v' , 'w' , 'x' , 'y' , 'z' 84 }; 85 86 /** 87 * Returns a string representation of the first argument in the 88 * radix specified by the second argument. 89 * 90 * <p>If the radix is smaller than {@code Character.MIN_RADIX} 91 * or larger than {@code Character.MAX_RADIX}, then the radix 92 * {@code 10} is used instead. 93 * 94 * <p>If the first argument is negative, the first element of the 95 * result is the ASCII minus character {@code '-'} 96 * ({@code '\u005Cu002D'}). If the first argument is not 97 * negative, no sign character appears in the result. 98 * 99 * <p>The remaining characters of the result represent the magnitude 100 * of the first argument. If the magnitude is zero, it is 101 * represented by a single zero character {@code '0'} 102 * ({@code '\u005Cu0030'}); otherwise, the first character of 103 * the representation of the magnitude will not be the zero 104 * character. The following ASCII characters are used as digits: 105 * 106 * <blockquote> 107 * {@code 0123456789abcdefghijklmnopqrstuvwxyz} 108 * </blockquote> 109 * 110 * These are {@code '\u005Cu0030'} through 111 * {@code '\u005Cu0039'} and {@code '\u005Cu0061'} through 112 * {@code '\u005Cu007A'}. If {@code radix} is 113 * <var>N</var>, then the first <var>N</var> of these characters 114 * are used as radix-<var>N</var> digits in the order shown. Thus, 115 * the digits for hexadecimal (radix 16) are 116 * {@code 0123456789abcdef}. If uppercase letters are 117 * desired, the {@link java.lang.String#toUpperCase()} method may 118 * be called on the result: 119 * 120 * <blockquote> 121 * {@code Integer.toString(n, 16).toUpperCase()} 122 * </blockquote> 123 * 124 * @param i an integer to be converted to a string. 125 * @param radix the radix to use in the string representation. 126 * @return a string representation of the argument in the specified radix. 127 * @see java.lang.Character#MAX_RADIX 128 * @see java.lang.Character#MIN_RADIX 129 */ 130 public static String toString(int i, int radix) { 131 if (radix < Character.MIN_RADIX || radix > Character.MAX_RADIX) 132 radix = 10; 133 134 /* Use the faster version */ 135 if (radix == 10) { 136 return toString(i); 137 } 138 139 char buf[] = new char[33]; 140 boolean negative = (i < 0); 141 int charPos = 32; 142 143 if (!negative) { 144 i = -i; 145 } 146 147 while (i <= -radix) { 148 buf[charPos--] = digits[-(i % radix)]; 149 i = i / radix; 150 } 151 buf[charPos] = digits[-i]; 152 153 if (negative) { 154 buf[--charPos] = '-'; 155 } 156 157 return new String(buf, charPos, (33 - charPos)); 158 } 159 160 /** 161 * Returns a string representation of the first argument as an 162 * unsigned integer value in the radix specified by the second 163 * argument. 164 * 165 * <p>If the radix is smaller than {@code Character.MIN_RADIX} 166 * or larger than {@code Character.MAX_RADIX}, then the radix 167 * {@code 10} is used instead. 168 * 169 * <p>Note that since the first argument is treated as an unsigned 170 * value, no leading sign character is printed. 171 * 172 * <p>If the magnitude is zero, it is represented by a single zero 173 * character {@code '0'} ({@code '\u005Cu0030'}); otherwise, 174 * the first character of the representation of the magnitude will 175 * not be the zero character. 176 * 177 * <p>The behavior of radixes and the characters used as digits 178 * are the same as {@link #toString(int, int) toString}. 179 * 180 * @param i an integer to be converted to an unsigned string. 181 * @param radix the radix to use in the string representation. 182 * @return an unsigned string representation of the argument in the specified radix. 183 * @see #toString(int, int) 184 * @since 1.8 185 */ 186 public static String toUnsignedString(int i, int radix) { 187 return Long.toUnsignedString(toUnsignedLong(i), radix); 188 } 189 190 /** 191 * Returns a string representation of the integer argument as an 192 * unsigned integer in base 16. 193 * 194 * <p>The unsigned integer value is the argument plus 2<sup>32</sup> 195 * if the argument is negative; otherwise, it is equal to the 196 * argument. This value is converted to a string of ASCII digits 197 * in hexadecimal (base 16) with no extra leading 198 * {@code 0}s. 199 * 200 * <p>The value of the argument can be recovered from the returned 201 * string {@code s} by calling {@link 202 * Integer#parseUnsignedInt(String, int) 203 * Integer.parseUnsignedInt(s, 16)}. 204 * 205 * <p>If the unsigned magnitude is zero, it is represented by a 206 * single zero character {@code '0'} ({@code '\u005Cu0030'}); 207 * otherwise, the first character of the representation of the 208 * unsigned magnitude will not be the zero character. The 209 * following characters are used as hexadecimal digits: 210 * 211 * <blockquote> 212 * {@code 0123456789abcdef} 213 * </blockquote> 214 * 215 * These are the characters {@code '\u005Cu0030'} through 216 * {@code '\u005Cu0039'} and {@code '\u005Cu0061'} through 217 * {@code '\u005Cu0066'}. If uppercase letters are 218 * desired, the {@link java.lang.String#toUpperCase()} method may 219 * be called on the result: 220 * 221 * <blockquote> 222 * {@code Integer.toHexString(n).toUpperCase()} 223 * </blockquote> 224 * 225 * @param i an integer to be converted to a string. 226 * @return the string representation of the unsigned integer value 227 * represented by the argument in hexadecimal (base 16). 228 * @see #parseUnsignedInt(String, int) 229 * @see #toUnsignedString(int, int) 230 * @since JDK1.0.2 231 */ 232 public static String toHexString(int i) { 233 return toUnsignedString0(i, 4); 234 } 235 236 /** 237 * Returns a string representation of the integer argument as an 238 * unsigned integer in base 8. 239 * 240 * <p>The unsigned integer value is the argument plus 2<sup>32</sup> 241 * if the argument is negative; otherwise, it is equal to the 242 * argument. This value is converted to a string of ASCII digits 243 * in octal (base 8) with no extra leading {@code 0}s. 244 * 245 * <p>The value of the argument can be recovered from the returned 246 * string {@code s} by calling {@link 247 * Integer#parseUnsignedInt(String, int) 248 * Integer.parseUnsignedInt(s, 8)}. 249 * 250 * <p>If the unsigned magnitude is zero, it is represented by a 251 * single zero character {@code '0'} ({@code '\u005Cu0030'}); 252 * otherwise, the first character of the representation of the 253 * unsigned magnitude will not be the zero character. The 254 * following characters are used as octal digits: 255 * 256 * <blockquote> 257 * {@code 01234567} 258 * </blockquote> 259 * 260 * These are the characters {@code '\u005Cu0030'} through 261 * {@code '\u005Cu0037'}. 262 * 263 * @param i an integer to be converted to a string. 264 * @return the string representation of the unsigned integer value 265 * represented by the argument in octal (base 8). 266 * @see #parseUnsignedInt(String, int) 267 * @see #toUnsignedString(int, int) 268 * @since JDK1.0.2 269 */ 270 public static String toOctalString(int i) { 271 return toUnsignedString0(i, 3); 272 } 273 274 /** 275 * Returns a string representation of the integer argument as an 276 * unsigned integer in base 2. 277 * 278 * <p>The unsigned integer value is the argument plus 2<sup>32</sup> 279 * if the argument is negative; otherwise it is equal to the 280 * argument. This value is converted to a string of ASCII digits 281 * in binary (base 2) with no extra leading {@code 0}s. 282 * 283 * <p>The value of the argument can be recovered from the returned 284 * string {@code s} by calling {@link 285 * Integer#parseUnsignedInt(String, int) 286 * Integer.parseUnsignedInt(s, 2)}. 287 * 288 * <p>If the unsigned magnitude is zero, it is represented by a 289 * single zero character {@code '0'} ({@code '\u005Cu0030'}); 290 * otherwise, the first character of the representation of the 291 * unsigned magnitude will not be the zero character. The 292 * characters {@code '0'} ({@code '\u005Cu0030'}) and {@code 293 * '1'} ({@code '\u005Cu0031'}) are used as binary digits. 294 * 295 * @param i an integer to be converted to a string. 296 * @return the string representation of the unsigned integer value 297 * represented by the argument in binary (base 2). 298 * @see #parseUnsignedInt(String, int) 299 * @see #toUnsignedString(int, int) 300 * @since JDK1.0.2 301 */ 302 public static String toBinaryString(int i) { 303 return toUnsignedString0(i, 1); 304 } 305 306 /** 307 * Convert the integer to an unsigned number. 308 */ 309 private static String toUnsignedString0(int val, int shift) { 310 // assert shift > 0 && shift <=5 : "Illegal shift value"; 311 int mag = Integer.SIZE - Integer.numberOfLeadingZeros(val); 312 int chars = Math.max(((mag + (shift - 1)) / shift), 1); 313 char[] buf = new char[chars]; 314 315 formatUnsignedInt(val, shift, buf, 0, chars); 316 317 // Use special constructor which takes over "buf". 318 return new String(buf, true); 319 } 320 321 /** 322 * Format a long (treated as unsigned) into a character buffer. 323 * @param val the unsigned int to format 324 * @param shift the log2 of the base to format in (4 for hex, 3 for octal, 1 for binary) 325 * @param buf the character buffer to write to 326 * @param offset the offset in the destination buffer to start at 327 * @param len the number of characters to write 328 * @return the lowest character location used 329 */ 330 static int formatUnsignedInt(int val, int shift, char[] buf, int offset, int len) { 331 int charPos = len; 332 int radix = 1 << shift; 333 int mask = radix - 1; 334 do { 335 buf[offset + --charPos] = Integer.digits[val & mask]; 336 val >>>= shift; 337 } while (val != 0 && charPos > 0); 338 339 return charPos; 340 } 341 342 final static char [] DigitTens = { 343 '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', 344 '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', 345 '2', '2', '2', '2', '2', '2', '2', '2', '2', '2', 346 '3', '3', '3', '3', '3', '3', '3', '3', '3', '3', 347 '4', '4', '4', '4', '4', '4', '4', '4', '4', '4', 348 '5', '5', '5', '5', '5', '5', '5', '5', '5', '5', 349 '6', '6', '6', '6', '6', '6', '6', '6', '6', '6', 350 '7', '7', '7', '7', '7', '7', '7', '7', '7', '7', 351 '8', '8', '8', '8', '8', '8', '8', '8', '8', '8', 352 '9', '9', '9', '9', '9', '9', '9', '9', '9', '9', 353 } ; 354 355 final static char [] DigitOnes = { 356 '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 357 '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 358 '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 359 '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 360 '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 361 '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 362 '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 363 '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 364 '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 365 '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 366 } ; 367 368 // I use the "invariant division by multiplication" trick to 369 // accelerate Integer.toString. In particular we want to 370 // avoid division by 10. 371 // 372 // The "trick" has roughly the same performance characteristics 373 // as the "classic" Integer.toString code on a non-JIT VM. 374 // The trick avoids .rem and .div calls but has a longer code 375 // path and is thus dominated by dispatch overhead. In the 376 // JIT case the dispatch overhead doesn't exist and the 377 // "trick" is considerably faster than the classic code. 378 // 379 // TODO-FIXME: convert (x * 52429) into the equiv shift-add 380 // sequence. 381 // 382 // RE: Division by Invariant Integers using Multiplication 383 // T Gralund, P Montgomery 384 // ACM PLDI 1994 385 // 386 387 /** 388 * Returns a {@code String} object representing the 389 * specified integer. The argument is converted to signed decimal 390 * representation and returned as a string, exactly as if the 391 * argument and radix 10 were given as arguments to the {@link 392 * #toString(int, int)} method. 393 * 394 * @param i an integer to be converted. 395 * @return a string representation of the argument in base 10. 396 */ 397 public static String toString(int i) { 398 if (i == Integer.MIN_VALUE) 399 return "-2147483648"; 400 int size = (i < 0) ? stringSize(-i) + 1 : stringSize(i); 401 char[] buf = new char[size]; 402 getChars(i, size, buf); 403 return new String(buf, true); 404 } 405 406 /** 407 * Returns a string representation of the argument as an unsigned 408 * decimal value. 409 * 410 * The argument is converted to unsigned decimal representation 411 * and returned as a string exactly as if the argument and radix 412 * 10 were given as arguments to the {@link #toUnsignedString(int, 413 * int)} method. 414 * 415 * @param i an integer to be converted to an unsigned string. 416 * @return an unsigned string representation of the argument. 417 * @see #toUnsignedString(int, int) 418 * @since 1.8 419 */ 420 public static String toUnsignedString(int i) { 421 return Long.toString(toUnsignedLong(i)); 422 } 423 424 /** 425 * Places characters representing the integer i into the 426 * character array buf. The characters are placed into 427 * the buffer backwards starting with the least significant 428 * digit at the specified index (exclusive), and working 429 * backwards from there. 430 * 431 * Will fail if i == Integer.MIN_VALUE 432 */ 433 static void getChars(int i, int index, char[] buf) { 434 int q, r; 435 int charPos = index; 436 char sign = 0; 437 438 if (i < 0) { 439 sign = '-'; 440 i = -i; 441 } 442 443 // Generate two digits per iteration 444 while (i >= 65536) { 445 q = i / 100; 446 // really: r = i - (q * 100); 447 r = i - ((q << 6) + (q << 5) + (q << 2)); 448 i = q; 449 buf [--charPos] = DigitOnes[r]; 450 buf [--charPos] = DigitTens[r]; 451 } 452 453 // Fall thru to fast mode for smaller numbers 454 // assert(i <= 65536, i); 455 for (;;) { 456 q = (i * 52429) >>> (16+3); 457 r = i - ((q << 3) + (q << 1)); // r = i-(q*10) ... 458 buf [--charPos] = digits [r]; 459 i = q; 460 if (i == 0) break; 461 } 462 if (sign != 0) { 463 buf [--charPos] = sign; 464 } 465 } 466 467 final static int [] sizeTable = { 9, 99, 999, 9999, 99999, 999999, 9999999, 468 99999999, 999999999, Integer.MAX_VALUE }; 469 470 // Requires positive x 471 static int stringSize(int x) { 472 for (int i=0; ; i++) 473 if (x <= sizeTable[i]) 474 return i+1; 475 } 476 477 /** 478 * Parses the string argument as a signed integer in the radix 479 * specified by the second argument. The characters in the string 480 * must all be digits of the specified radix (as determined by 481 * whether {@link java.lang.Character#digit(char, int)} returns a 482 * nonnegative value), except that the first character may be an 483 * ASCII minus sign {@code '-'} ({@code '\u005Cu002D'}) to 484 * indicate a negative value or an ASCII plus sign {@code '+'} 485 * ({@code '\u005Cu002B'}) to indicate a positive value. The 486 * resulting integer value is returned. 487 * 488 * <p>An exception of type {@code NumberFormatException} is 489 * thrown if any of the following situations occurs: 490 * <ul> 491 * <li>The first argument is {@code null} or is a string of 492 * length zero. 493 * 494 * <li>The radix is either smaller than 495 * {@link java.lang.Character#MIN_RADIX} or 496 * larger than {@link java.lang.Character#MAX_RADIX}. 497 * 498 * <li>Any character of the string is not a digit of the specified 499 * radix, except that the first character may be a minus sign 500 * {@code '-'} ({@code '\u005Cu002D'}) or plus sign 501 * {@code '+'} ({@code '\u005Cu002B'}) provided that the 502 * string is longer than length 1. 503 * 504 * <li>The value represented by the string is not a value of type 505 * {@code int}. 506 * </ul> 507 * 508 * <p>Examples: 509 * <blockquote><pre> 510 * parseInt("0", 10) returns 0 511 * parseInt("473", 10) returns 473 512 * parseInt("+42", 10) returns 42 513 * parseInt("-0", 10) returns 0 514 * parseInt("-FF", 16) returns -255 515 * parseInt("1100110", 2) returns 102 516 * parseInt("2147483647", 10) returns 2147483647 517 * parseInt("-2147483648", 10) returns -2147483648 518 * parseInt("2147483648", 10) throws a NumberFormatException 519 * parseInt("99", 8) throws a NumberFormatException 520 * parseInt("Kona", 10) throws a NumberFormatException 521 * parseInt("Kona", 27) returns 411787 522 * </pre></blockquote> 523 * 524 * @param s the {@code String} containing the integer 525 * representation to be parsed 526 * @param radix the radix to be used while parsing {@code s}. 527 * @return the integer represented by the string argument in the 528 * specified radix. 529 * @exception NumberFormatException if the {@code String} 530 * does not contain a parsable {@code int}. 531 */ 532 public static int parseInt(String s, int radix) 533 throws NumberFormatException 534 { 535 /* 536 * WARNING: This method may be invoked early during VM initialization 537 * before IntegerCache is initialized. Care must be taken to not use 538 * the valueOf method. 539 */ 540 541 if (s == null) { 542 throw new NumberFormatException("null"); 543 } 544 545 if (radix < Character.MIN_RADIX) { 546 throw new NumberFormatException("radix " + radix + 547 " less than Character.MIN_RADIX"); 548 } 549 550 if (radix > Character.MAX_RADIX) { 551 throw new NumberFormatException("radix " + radix + 552 " greater than Character.MAX_RADIX"); 553 } 554 555 int result = 0; 556 boolean negative = false; 557 int i = 0, len = s.length(); 558 int limit = -Integer.MAX_VALUE; 559 int multmin; 560 int digit; 561 562 if (len > 0) { 563 char firstChar = s.charAt(0); 564 if (firstChar < '0') { // Possible leading "+" or "-" 565 if (firstChar == '-') { 566 negative = true; 567 limit = Integer.MIN_VALUE; 568 } else if (firstChar != '+') 569 throw NumberFormatException.forInputString(s); 570 571 if (len == 1) // Cannot have lone "+" or "-" 572 throw NumberFormatException.forInputString(s); 573 i++; 574 } 575 multmin = limit / radix; 576 while (i < len) { 577 // Accumulating negatively avoids surprises near MAX_VALUE 578 digit = Character.digit(s.charAt(i++),radix); 579 if (digit < 0) { 580 throw NumberFormatException.forInputString(s); 581 } 582 if (result < multmin) { 583 throw NumberFormatException.forInputString(s); 584 } 585 result *= radix; 586 if (result < limit + digit) { 587 throw NumberFormatException.forInputString(s); 588 } 589 result -= digit; 590 } 591 } else { 592 throw NumberFormatException.forInputString(s); 593 } 594 return negative ? result : -result; 595 } 596 597 /** 598 * Parses the string argument as a signed decimal integer. The 599 * characters in the string must all be decimal digits, except 600 * that the first character may be an ASCII minus sign {@code '-'} 601 * ({@code '\u005Cu002D'}) to indicate a negative value or an 602 * ASCII plus sign {@code '+'} ({@code '\u005Cu002B'}) to 603 * indicate a positive value. The resulting integer value is 604 * returned, exactly as if the argument and the radix 10 were 605 * given as arguments to the {@link #parseInt(java.lang.String, 606 * int)} method. 607 * 608 * @param s a {@code String} containing the {@code int} 609 * representation to be parsed 610 * @return the integer value represented by the argument in decimal. 611 * @exception NumberFormatException if the string does not contain a 612 * parsable integer. 613 */ 614 public static int parseInt(String s) throws NumberFormatException { 615 return parseInt(s,10); 616 } 617 618 /** 619 * Parses the string argument as an unsigned integer in the radix 620 * specified by the second argument. An unsigned integer maps the 621 * values usually associated with negative numbers to positive 622 * numbers larger than {@code MAX_VALUE}. 623 * 624 * The characters in the string must all be digits of the 625 * specified radix (as determined by whether {@link 626 * java.lang.Character#digit(char, int)} returns a nonnegative 627 * value), except that the first character may be an ASCII plus 628 * sign {@code '+'} ({@code '\u005Cu002B'}). The resulting 629 * integer value is returned. 630 * 631 * <p>An exception of type {@code NumberFormatException} is 632 * thrown if any of the following situations occurs: 633 * <ul> 634 * <li>The first argument is {@code null} or is a string of 635 * length zero. 636 * 637 * <li>The radix is either smaller than 638 * {@link java.lang.Character#MIN_RADIX} or 639 * larger than {@link java.lang.Character#MAX_RADIX}. 640 * 641 * <li>Any character of the string is not a digit of the specified 642 * radix, except that the first character may be a plus sign 643 * {@code '+'} ({@code '\u005Cu002B'}) provided that the 644 * string is longer than length 1. 645 * 646 * <li>The value represented by the string is larger than the 647 * largest unsigned {@code int}, 2<sup>32</sup>-1. 648 * 649 * </ul> 650 * 651 * 652 * @param s the {@code String} containing the unsigned integer 653 * representation to be parsed 654 * @param radix the radix to be used while parsing {@code s}. 655 * @return the integer represented by the string argument in the 656 * specified radix. 657 * @throws NumberFormatException if the {@code String} 658 * does not contain a parsable {@code int}. 659 * @since 1.8 660 */ 661 public static int parseUnsignedInt(String s, int radix) 662 throws NumberFormatException { 663 if (s == null) { 664 throw new NumberFormatException("null"); 665 } 666 667 int len = s.length(); 668 if (len > 0) { 669 char firstChar = s.charAt(0); 670 if (firstChar == '-') { 671 throw new 672 NumberFormatException(String.format("Illegal leading minus sign " + 673 "on unsigned string %s.", s)); 674 } else { 675 if (len <= 5 || // Integer.MAX_VALUE in Character.MAX_RADIX is 6 digits 676 (radix == 10 && len <= 9) ) { // Integer.MAX_VALUE in base 10 is 10 digits 677 return parseInt(s, radix); 678 } else { 679 long ell = Long.parseLong(s, radix); 680 if ((ell & 0xffff_ffff_0000_0000L) == 0) { 681 return (int) ell; 682 } else { 683 throw new 684 NumberFormatException(String.format("String value %s exceeds " + 685 "range of unsigned int.", s)); 686 } 687 } 688 } 689 } else { 690 throw NumberFormatException.forInputString(s); 691 } 692 } 693 694 /** 695 * Parses the string argument as an unsigned decimal integer. The 696 * characters in the string must all be decimal digits, except 697 * that the first character may be an an ASCII plus sign {@code 698 * '+'} ({@code '\u005Cu002B'}). The resulting integer value 699 * is returned, exactly as if the argument and the radix 10 were 700 * given as arguments to the {@link 701 * #parseUnsignedInt(java.lang.String, int)} method. 702 * 703 * @param s a {@code String} containing the unsigned {@code int} 704 * representation to be parsed 705 * @return the unsigned integer value represented by the argument in decimal. 706 * @throws NumberFormatException if the string does not contain a 707 * parsable unsigned integer. 708 * @since 1.8 709 */ 710 public static int parseUnsignedInt(String s) throws NumberFormatException { 711 return parseUnsignedInt(s, 10); 712 } 713 714 /** 715 * Returns an {@code Integer} object holding the value 716 * extracted from the specified {@code String} when parsed 717 * with the radix given by the second argument. The first argument 718 * is interpreted as representing a signed integer in the radix 719 * specified by the second argument, exactly as if the arguments 720 * were given to the {@link #parseInt(java.lang.String, int)} 721 * method. The result is an {@code Integer} object that 722 * represents the integer value specified by the string. 723 * 724 * <p>In other words, this method returns an {@code Integer} 725 * object equal to the value of: 726 * 727 * <blockquote> 728 * {@code new Integer(Integer.parseInt(s, radix))} 729 * </blockquote> 730 * 731 * @param s the string to be parsed. 732 * @param radix the radix to be used in interpreting {@code s} 733 * @return an {@code Integer} object holding the value 734 * represented by the string argument in the specified 735 * radix. 736 * @exception NumberFormatException if the {@code String} 737 * does not contain a parsable {@code int}. 738 */ 739 public static Integer valueOf(String s, int radix) throws NumberFormatException { 740 return Integer.valueOf(parseInt(s,radix)); 741 } 742 743 /** 744 * Returns an {@code Integer} object holding the 745 * value of the specified {@code String}. The argument is 746 * interpreted as representing a signed decimal integer, exactly 747 * as if the argument were given to the {@link 748 * #parseInt(java.lang.String)} method. The result is an 749 * {@code Integer} object that represents the integer value 750 * specified by the string. 751 * 752 * <p>In other words, this method returns an {@code Integer} 753 * object equal to the value of: 754 * 755 * <blockquote> 756 * {@code new Integer(Integer.parseInt(s))} 757 * </blockquote> 758 * 759 * @param s the string to be parsed. 760 * @return an {@code Integer} object holding the value 761 * represented by the string argument. 762 * @exception NumberFormatException if the string cannot be parsed 763 * as an integer. 764 */ 765 public static Integer valueOf(String s) throws NumberFormatException { 766 return Integer.valueOf(parseInt(s, 10)); 767 } 768 769 /** 770 * Cache to support the object identity semantics of autoboxing for values between 771 * -128 and 127 (inclusive) as required by JLS. 772 * 773 * The cache is initialized on first usage. The size of the cache 774 * may be controlled by the {@code -XX:AutoBoxCacheMax=<size>} option. 775 * During VM initialization, java.lang.Integer.IntegerCache.high property 776 * may be set and saved in the private system properties in the 777 * sun.misc.VM class. 778 */ 779 780 private static class IntegerCache { 781 static final int low = -128; 782 static final int high; 783 static final Integer cache[]; 784 785 static { 786 // high value may be configured by property 787 int h = 127; 788 String integerCacheHighPropValue = 789 sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high"); 790 if (integerCacheHighPropValue != null) { 791 try { 792 int i = parseInt(integerCacheHighPropValue); 793 i = Math.max(i, 127); 794 // Maximum array size is Integer.MAX_VALUE 795 h = Math.min(i, Integer.MAX_VALUE - (-low) -1); 796 } catch( NumberFormatException nfe) { 797 // If the property cannot be parsed into an int, ignore it. 798 } 799 } 800 high = h; 801 802 cache = new Integer[(high - low) + 1]; 803 int j = low; 804 for(int k = 0; k < cache.length; k++) 805 cache[k] = new Integer(j++); 806 807 // range [-128, 127] must be interned (JLS7 5.1.7) 808 assert IntegerCache.high >= 127; 809 } 810 811 private IntegerCache() {} 812 } 813 814 /** 815 * Returns an {@code Integer} instance representing the specified 816 * {@code int} value. If a new {@code Integer} instance is not 817 * required, this method should generally be used in preference to 818 * the constructor {@link #Integer(int)}, as this method is likely 819 * to yield significantly better space and time performance by 820 * caching frequently requested values. 821 * 822 * This method will always cache values in the range -128 to 127, 823 * inclusive, and may cache other values outside of this range. 824 * 825 * @param i an {@code int} value. 826 * @return an {@code Integer} instance representing {@code i}. 827 * @since 1.5 828 */ 829 public static Integer valueOf(int i) { 830 if (i >= IntegerCache.low && i <= IntegerCache.high) 831 return IntegerCache.cache[i + (-IntegerCache.low)]; 832 return new Integer(i); 833 } 834 835 /** 836 * The value of the {@code Integer}. 837 * 838 * @serial 839 */ 840 private final int value; 841 842 /** 843 * Constructs a newly allocated {@code Integer} object that 844 * represents the specified {@code int} value. 845 * 846 * @param value the value to be represented by the 847 * {@code Integer} object. 848 */ 849 public Integer(int value) { 850 this.value = value; 851 } 852 853 /** 854 * Constructs a newly allocated {@code Integer} object that 855 * represents the {@code int} value indicated by the 856 * {@code String} parameter. The string is converted to an 857 * {@code int} value in exactly the manner used by the 858 * {@code parseInt} method for radix 10. 859 * 860 * @param s the {@code String} to be converted to an 861 * {@code Integer}. 862 * @exception NumberFormatException if the {@code String} does not 863 * contain a parsable integer. 864 * @see java.lang.Integer#parseInt(java.lang.String, int) 865 */ 866 public Integer(String s) throws NumberFormatException { 867 this.value = parseInt(s, 10); 868 } 869 870 /** 871 * Returns the value of this {@code Integer} as a {@code byte} 872 * after a narrowing primitive conversion. 873 * @jls 5.1.3 Narrowing Primitive Conversions 874 */ 875 public byte byteValue() { 876 return (byte)value; 877 } 878 879 /** 880 * Returns the value of this {@code Integer} as a {@code short} 881 * after a narrowing primitive conversion. 882 * @jls 5.1.3 Narrowing Primitive Conversions 883 */ 884 public short shortValue() { 885 return (short)value; 886 } 887 888 /** 889 * Returns the value of this {@code Integer} as an 890 * {@code int}. 891 */ 892 public int intValue() { 893 return value; 894 } 895 896 /** 897 * Returns the value of this {@code Integer} as a {@code long} 898 * after a widening primitive conversion. 899 * @jls 5.1.2 Widening Primitive Conversions 900 * @see Integer#toUnsignedLong(int) 901 */ 902 public long longValue() { 903 return (long)value; 904 } 905 906 /** 907 * Returns the value of this {@code Integer} as a {@code float} 908 * after a widening primitive conversion. 909 * @jls 5.1.2 Widening Primitive Conversions 910 */ 911 public float floatValue() { 912 return (float)value; 913 } 914 915 /** 916 * Returns the value of this {@code Integer} as a {@code double} 917 * after a widening primitive conversion. 918 * @jls 5.1.2 Widening Primitive Conversions 919 */ 920 public double doubleValue() { 921 return (double)value; 922 } 923 924 /** 925 * Returns a {@code String} object representing this 926 * {@code Integer}'s value. The value is converted to signed 927 * decimal representation and returned as a string, exactly as if 928 * the integer value were given as an argument to the {@link 929 * java.lang.Integer#toString(int)} method. 930 * 931 * @return a string representation of the value of this object in 932 * base 10. 933 */ 934 public String toString() { 935 return toString(value); 936 } 937 938 /** 939 * Returns a hash code for this {@code Integer}. 940 * 941 * @return a hash code value for this object, equal to the 942 * primitive {@code int} value represented by this 943 * {@code Integer} object. 944 */ 945 @Override 946 public int hashCode() { 947 return Integer.hashCode(value); 948 } 949 950 /** 951 * Returns a hash code for a {@code int} value; compatible with 952 * {@code Integer.hashCode()}. 953 * 954 * @param value the value to hash 955 * @since 1.8 956 * 957 * @return a hash code value for a {@code int} value. 958 */ 959 public static int hashCode(int value) { 960 return value; 961 } 962 963 /** 964 * Compares this object to the specified object. The result is 965 * {@code true} if and only if the argument is not 966 * {@code null} and is an {@code Integer} object that 967 * contains the same {@code int} value as this object. 968 * 969 * @param obj the object to compare with. 970 * @return {@code true} if the objects are the same; 971 * {@code false} otherwise. 972 */ 973 public boolean equals(Object obj) { 974 if (obj instanceof Integer) { 975 return value == ((Integer)obj).intValue(); 976 } 977 return false; 978 } 979 980 /** 981 * Determines the integer value of the system property with the 982 * specified name. 983 * 984 * <p>The first argument is treated as the name of a system 985 * property. System properties are accessible through the {@link 986 * java.lang.System#getProperty(java.lang.String)} method. The 987 * string value of this property is then interpreted as an integer 988 * value using the grammar supported by {@link Integer#decode decode} and 989 * an {@code Integer} object representing this value is returned. 990 * 991 * <p>If there is no property with the specified name, if the 992 * specified name is empty or {@code null}, or if the property 993 * does not have the correct numeric format, then {@code null} is 994 * returned. 995 * 996 * <p>In other words, this method returns an {@code Integer} 997 * object equal to the value of: 998 * 999 * <blockquote> 1000 * {@code getInteger(nm, null)} 1001 * </blockquote> 1002 * 1003 * @param nm property name. 1004 * @return the {@code Integer} value of the property. 1005 * @throws SecurityException for the same reasons as 1006 * {@link System#getProperty(String) System.getProperty} 1007 * @see java.lang.System#getProperty(java.lang.String) 1008 * @see java.lang.System#getProperty(java.lang.String, java.lang.String) 1009 */ 1010 public static Integer getInteger(String nm) { 1011 return getInteger(nm, null); 1012 } 1013 1014 /** 1015 * Determines the integer value of the system property with the 1016 * specified name. 1017 * 1018 * <p>The first argument is treated as the name of a system 1019 * property. System properties are accessible through the {@link 1020 * java.lang.System#getProperty(java.lang.String)} method. The 1021 * string value of this property is then interpreted as an integer 1022 * value using the grammar supported by {@link Integer#decode decode} and 1023 * an {@code Integer} object representing this value is returned. 1024 * 1025 * <p>The second argument is the default value. An {@code Integer} object 1026 * that represents the value of the second argument is returned if there 1027 * is no property of the specified name, if the property does not have 1028 * the correct numeric format, or if the specified name is empty or 1029 * {@code null}. 1030 * 1031 * <p>In other words, this method returns an {@code Integer} object 1032 * equal to the value of: 1033 * 1034 * <blockquote> 1035 * {@code getInteger(nm, new Integer(val))} 1036 * </blockquote> 1037 * 1038 * but in practice it may be implemented in a manner such as: 1039 * 1040 * <blockquote><pre> 1041 * Integer result = getInteger(nm, null); 1042 * return (result == null) ? new Integer(val) : result; 1043 * </pre></blockquote> 1044 * 1045 * to avoid the unnecessary allocation of an {@code Integer} 1046 * object when the default value is not needed. 1047 * 1048 * @param nm property name. 1049 * @param val default value. 1050 * @return the {@code Integer} value of the property. 1051 * @throws SecurityException for the same reasons as 1052 * {@link System#getProperty(String) System.getProperty} 1053 * @see java.lang.System#getProperty(java.lang.String) 1054 * @see java.lang.System#getProperty(java.lang.String, java.lang.String) 1055 */ 1056 public static Integer getInteger(String nm, int val) { 1057 Integer result = getInteger(nm, null); 1058 return (result == null) ? Integer.valueOf(val) : result; 1059 } 1060 1061 /** 1062 * Returns the integer value of the system property with the 1063 * specified name. The first argument is treated as the name of a 1064 * system property. System properties are accessible through the 1065 * {@link java.lang.System#getProperty(java.lang.String)} method. 1066 * The string value of this property is then interpreted as an 1067 * integer value, as per the {@link Integer#decode decode} method, 1068 * and an {@code Integer} object representing this value is 1069 * returned; in summary: 1070 * 1071 * <ul><li>If the property value begins with the two ASCII characters 1072 * {@code 0x} or the ASCII character {@code #}, not 1073 * followed by a minus sign, then the rest of it is parsed as a 1074 * hexadecimal integer exactly as by the method 1075 * {@link #valueOf(java.lang.String, int)} with radix 16. 1076 * <li>If the property value begins with the ASCII character 1077 * {@code 0} followed by another character, it is parsed as an 1078 * octal integer exactly as by the method 1079 * {@link #valueOf(java.lang.String, int)} with radix 8. 1080 * <li>Otherwise, the property value is parsed as a decimal integer 1081 * exactly as by the method {@link #valueOf(java.lang.String, int)} 1082 * with radix 10. 1083 * </ul> 1084 * 1085 * <p>The second argument is the default value. The default value is 1086 * returned if there is no property of the specified name, if the 1087 * property does not have the correct numeric format, or if the 1088 * specified name is empty or {@code null}. 1089 * 1090 * @param nm property name. 1091 * @param val default value. 1092 * @return the {@code Integer} value of the property. 1093 * @throws SecurityException for the same reasons as 1094 * {@link System#getProperty(String) System.getProperty} 1095 * @see System#getProperty(java.lang.String) 1096 * @see System#getProperty(java.lang.String, java.lang.String) 1097 */ 1098 public static Integer getInteger(String nm, Integer val) { 1099 String v = null; 1100 try { 1101 v = System.getProperty(nm); 1102 } catch (IllegalArgumentException | NullPointerException e) { 1103 } 1104 if (v != null) { 1105 try { 1106 return Integer.decode(v); 1107 } catch (NumberFormatException e) { 1108 } 1109 } 1110 return val; 1111 } 1112 1113 /** 1114 * Decodes a {@code String} into an {@code Integer}. 1115 * Accepts decimal, hexadecimal, and octal numbers given 1116 * by the following grammar: 1117 * 1118 * <blockquote> 1119 * <dl> 1120 * <dt><i>DecodableString:</i> 1121 * <dd><i>Sign<sub>opt</sub> DecimalNumeral</i> 1122 * <dd><i>Sign<sub>opt</sub></i> {@code 0x} <i>HexDigits</i> 1123 * <dd><i>Sign<sub>opt</sub></i> {@code 0X} <i>HexDigits</i> 1124 * <dd><i>Sign<sub>opt</sub></i> {@code #} <i>HexDigits</i> 1125 * <dd><i>Sign<sub>opt</sub></i> {@code 0} <i>OctalDigits</i> 1126 * 1127 * <dt><i>Sign:</i> 1128 * <dd>{@code -} 1129 * <dd>{@code +} 1130 * </dl> 1131 * </blockquote> 1132 * 1133 * <i>DecimalNumeral</i>, <i>HexDigits</i>, and <i>OctalDigits</i> 1134 * are as defined in section 3.10.1 of 1135 * <cite>The Java™ Language Specification</cite>, 1136 * except that underscores are not accepted between digits. 1137 * 1138 * <p>The sequence of characters following an optional 1139 * sign and/or radix specifier ("{@code 0x}", "{@code 0X}", 1140 * "{@code #}", or leading zero) is parsed as by the {@code 1141 * Integer.parseInt} method with the indicated radix (10, 16, or 1142 * 8). This sequence of characters must represent a positive 1143 * value or a {@link NumberFormatException} will be thrown. The 1144 * result is negated if first character of the specified {@code 1145 * String} is the minus sign. No whitespace characters are 1146 * permitted in the {@code String}. 1147 * 1148 * @param nm the {@code String} to decode. 1149 * @return an {@code Integer} object holding the {@code int} 1150 * value represented by {@code nm} 1151 * @exception NumberFormatException if the {@code String} does not 1152 * contain a parsable integer. 1153 * @see java.lang.Integer#parseInt(java.lang.String, int) 1154 */ 1155 public static Integer decode(String nm) throws NumberFormatException { 1156 int radix = 10; 1157 int index = 0; 1158 boolean negative = false; 1159 Integer result; 1160 1161 if (nm.length() == 0) 1162 throw new NumberFormatException("Zero length string"); 1163 char firstChar = nm.charAt(0); 1164 // Handle sign, if present 1165 if (firstChar == '-') { 1166 negative = true; 1167 index++; 1168 } else if (firstChar == '+') 1169 index++; 1170 1171 // Handle radix specifier, if present 1172 if (nm.startsWith("0x", index) || nm.startsWith("0X", index)) { 1173 index += 2; 1174 radix = 16; 1175 } 1176 else if (nm.startsWith("#", index)) { 1177 index ++; 1178 radix = 16; 1179 } 1180 else if (nm.startsWith("0", index) && nm.length() > 1 + index) { 1181 index ++; 1182 radix = 8; 1183 } 1184 1185 if (nm.startsWith("-", index) || nm.startsWith("+", index)) 1186 throw new NumberFormatException("Sign character in wrong position"); 1187 1188 try { 1189 result = Integer.valueOf(nm.substring(index), radix); 1190 result = negative ? Integer.valueOf(-result.intValue()) : result; 1191 } catch (NumberFormatException e) { 1192 // If number is Integer.MIN_VALUE, we'll end up here. The next line 1193 // handles this case, and causes any genuine format error to be 1194 // rethrown. 1195 String constant = negative ? ("-" + nm.substring(index)) 1196 : nm.substring(index); 1197 result = Integer.valueOf(constant, radix); 1198 } 1199 return result; 1200 } 1201 1202 /** 1203 * Compares two {@code Integer} objects numerically. 1204 * 1205 * @param anotherInteger the {@code Integer} to be compared. 1206 * @return the value {@code 0} if this {@code Integer} is 1207 * equal to the argument {@code Integer}; a value less than 1208 * {@code 0} if this {@code Integer} is numerically less 1209 * than the argument {@code Integer}; and a value greater 1210 * than {@code 0} if this {@code Integer} is numerically 1211 * greater than the argument {@code Integer} (signed 1212 * comparison). 1213 * @since 1.2 1214 */ 1215 public int compareTo(Integer anotherInteger) { 1216 return compare(this.value, anotherInteger.value); 1217 } 1218 1219 /** 1220 * Compares two {@code int} values numerically. 1221 * The value returned is identical to what would be returned by: 1222 * <pre> 1223 * Integer.valueOf(x).compareTo(Integer.valueOf(y)) 1224 * </pre> 1225 * 1226 * @param x the first {@code int} to compare 1227 * @param y the second {@code int} to compare 1228 * @return the value {@code 0} if {@code x == y}; 1229 * a value less than {@code 0} if {@code x < y}; and 1230 * a value greater than {@code 0} if {@code x > y} 1231 * @since 1.7 1232 */ 1233 public static int compare(int x, int y) { 1234 return (x < y) ? -1 : ((x == y) ? 0 : 1); 1235 } 1236 1237 /** 1238 * Compares two {@code int} values numerically treating the values 1239 * as unsigned. 1240 * 1241 * @param x the first {@code int} to compare 1242 * @param y the second {@code int} to compare 1243 * @return the value {@code 0} if {@code x == y}; a value less 1244 * than {@code 0} if {@code x < y} as unsigned values; and 1245 * a value greater than {@code 0} if {@code x > y} as 1246 * unsigned values 1247 * @since 1.8 1248 */ 1249 public static int compareUnsigned(int x, int y) { 1250 return compare(x + MIN_VALUE, y + MIN_VALUE); 1251 } 1252 1253 /** 1254 * Converts the argument to a {@code long} by an unsigned 1255 * conversion. In an unsigned conversion to a {@code long}, the 1256 * high-order 32 bits of the {@code long} are zero and the 1257 * low-order 32 bits are equal to the bits of the integer 1258 * argument. 1259 * 1260 * Consequently, zero and positive {@code int} values are mapped 1261 * to a numerically equal {@code long} value and negative {@code 1262 * int} values are mapped to a {@code long} value equal to the 1263 * input plus 2<sup>32</sup>. 1264 * 1265 * @param x the value to convert to an unsigned {@code long} 1266 * @return the argument converted to {@code long} by an unsigned 1267 * conversion 1268 * @since 1.8 1269 */ 1270 public static long toUnsignedLong(int x) { 1271 return ((long) x) & 0xffffffffL; 1272 } 1273 1274 /** 1275 * Returns the unsigned quotient of dividing the first argument by 1276 * the second where each argument and the result is interpreted as 1277 * an unsigned value. 1278 * 1279 * <p>Note that in two's complement arithmetic, the three other 1280 * basic arithmetic operations of add, subtract, and multiply are 1281 * bit-wise identical if the two operands are regarded as both 1282 * being signed or both being unsigned. Therefore separate {@code 1283 * addUnsigned}, etc. methods are not provided. 1284 * 1285 * @param dividend the value to be divided 1286 * @param divisor the value doing the dividing 1287 * @return the unsigned quotient of the first argument divided by 1288 * the second argument 1289 * @see #remainderUnsigned 1290 * @since 1.8 1291 */ 1292 public static int divideUnsigned(int dividend, int divisor) { 1293 // In lieu of tricky code, for now just use long arithmetic. 1294 return (int)(toUnsignedLong(dividend) / toUnsignedLong(divisor)); 1295 } 1296 1297 /** 1298 * Returns the unsigned remainder from dividing the first argument 1299 * by the second where each argument and the result is interpreted 1300 * as an unsigned value. 1301 * 1302 * @param dividend the value to be divided 1303 * @param divisor the value doing the dividing 1304 * @return the unsigned remainder of the first argument divided by 1305 * the second argument 1306 * @see #divideUnsigned 1307 * @since 1.8 1308 */ 1309 public static int remainderUnsigned(int dividend, int divisor) { 1310 // In lieu of tricky code, for now just use long arithmetic. 1311 return (int)(toUnsignedLong(dividend) % toUnsignedLong(divisor)); 1312 } 1313 1314 1315 // Bit twiddling 1316 1317 /** 1318 * The number of bits used to represent an {@code int} value in two's 1319 * complement binary form. 1320 * 1321 * @since 1.5 1322 */ 1323 @Native public static final int SIZE = 32; 1324 1325 /** 1326 * The number of bytes used to represent a {@code int} value in two's 1327 * complement binary form. 1328 * 1329 * @since 1.8 1330 */ 1331 public static final int BYTES = SIZE / Byte.SIZE; 1332 1333 /** 1334 * Returns an {@code int} value with at most a single one-bit, in the 1335 * position of the highest-order ("leftmost") one-bit in the specified 1336 * {@code int} value. Returns zero if the specified value has no 1337 * one-bits in its two's complement binary representation, that is, if it 1338 * is equal to zero. 1339 * 1340 * @param i the value whose highest one bit is to be computed 1341 * @return an {@code int} value with a single one-bit, in the position 1342 * of the highest-order one-bit in the specified value, or zero if 1343 * the specified value is itself equal to zero. 1344 * @since 1.5 1345 */ 1346 public static int highestOneBit(int i) { 1347 // HD, Figure 3-1 1348 i |= (i >> 1); 1349 i |= (i >> 2); 1350 i |= (i >> 4); 1351 i |= (i >> 8); 1352 i |= (i >> 16); 1353 return i - (i >>> 1); 1354 } 1355 1356 /** 1357 * Returns an {@code int} value with at most a single one-bit, in the 1358 * position of the lowest-order ("rightmost") one-bit in the specified 1359 * {@code int} value. Returns zero if the specified value has no 1360 * one-bits in its two's complement binary representation, that is, if it 1361 * is equal to zero. 1362 * 1363 * @param i the value whose lowest one bit is to be computed 1364 * @return an {@code int} value with a single one-bit, in the position 1365 * of the lowest-order one-bit in the specified value, or zero if 1366 * the specified value is itself equal to zero. 1367 * @since 1.5 1368 */ 1369 public static int lowestOneBit(int i) { 1370 // HD, Section 2-1 1371 return i & -i; 1372 } 1373 1374 /** 1375 * Returns the number of zero bits preceding the highest-order 1376 * ("leftmost") one-bit in the two's complement binary representation 1377 * of the specified {@code int} value. Returns 32 if the 1378 * specified value has no one-bits in its two's complement representation, 1379 * in other words if it is equal to zero. 1380 * 1381 * <p>Note that this method is closely related to the logarithm base 2. 1382 * For all positive {@code int} values x: 1383 * <ul> 1384 * <li>floor(log<sub>2</sub>(x)) = {@code 31 - numberOfLeadingZeros(x)} 1385 * <li>ceil(log<sub>2</sub>(x)) = {@code 32 - numberOfLeadingZeros(x - 1)} 1386 * </ul> 1387 * 1388 * @param i the value whose number of leading zeros is to be computed 1389 * @return the number of zero bits preceding the highest-order 1390 * ("leftmost") one-bit in the two's complement binary representation 1391 * of the specified {@code int} value, or 32 if the value 1392 * is equal to zero. 1393 * @since 1.5 1394 */ 1395 public static int numberOfLeadingZeros(int i) { 1396 // HD, Figure 5-6 1397 if (i == 0) 1398 return 32; 1399 int n = 1; 1400 if (i >>> 16 == 0) { n += 16; i <<= 16; } 1401 if (i >>> 24 == 0) { n += 8; i <<= 8; } 1402 if (i >>> 28 == 0) { n += 4; i <<= 4; } 1403 if (i >>> 30 == 0) { n += 2; i <<= 2; } 1404 n -= i >>> 31; 1405 return n; 1406 } 1407 1408 /** 1409 * Returns the number of zero bits following the lowest-order ("rightmost") 1410 * one-bit in the two's complement binary representation of the specified 1411 * {@code int} value. Returns 32 if the specified value has no 1412 * one-bits in its two's complement representation, in other words if it is 1413 * equal to zero. 1414 * 1415 * @param i the value whose number of trailing zeros is to be computed 1416 * @return the number of zero bits following the lowest-order ("rightmost") 1417 * one-bit in the two's complement binary representation of the 1418 * specified {@code int} value, or 32 if the value is equal 1419 * to zero. 1420 * @since 1.5 1421 */ 1422 public static int numberOfTrailingZeros(int i) { 1423 // HD, Figure 5-14 1424 int y; 1425 if (i == 0) return 32; 1426 int n = 31; 1427 y = i <<16; if (y != 0) { n = n -16; i = y; } 1428 y = i << 8; if (y != 0) { n = n - 8; i = y; } 1429 y = i << 4; if (y != 0) { n = n - 4; i = y; } 1430 y = i << 2; if (y != 0) { n = n - 2; i = y; } 1431 return n - ((i << 1) >>> 31); 1432 } 1433 1434 /** 1435 * Returns the number of one-bits in the two's complement binary 1436 * representation of the specified {@code int} value. This function is 1437 * sometimes referred to as the <i>population count</i>. 1438 * 1439 * @param i the value whose bits are to be counted 1440 * @return the number of one-bits in the two's complement binary 1441 * representation of the specified {@code int} value. 1442 * @since 1.5 1443 */ 1444 public static int bitCount(int i) { 1445 // HD, Figure 5-2 1446 i = i - ((i >>> 1) & 0x55555555); 1447 i = (i & 0x33333333) + ((i >>> 2) & 0x33333333); 1448 i = (i + (i >>> 4)) & 0x0f0f0f0f; 1449 i = i + (i >>> 8); 1450 i = i + (i >>> 16); 1451 return i & 0x3f; 1452 } 1453 1454 /** 1455 * Returns the value obtained by rotating the two's complement binary 1456 * representation of the specified {@code int} value left by the 1457 * specified number of bits. (Bits shifted out of the left hand, or 1458 * high-order, side reenter on the right, or low-order.) 1459 * 1460 * <p>Note that left rotation with a negative distance is equivalent to 1461 * right rotation: {@code rotateLeft(val, -distance) == rotateRight(val, 1462 * distance)}. Note also that rotation by any multiple of 32 is a 1463 * no-op, so all but the last five bits of the rotation distance can be 1464 * ignored, even if the distance is negative: {@code rotateLeft(val, 1465 * distance) == rotateLeft(val, distance & 0x1F)}. 1466 * 1467 * @param i the value whose bits are to be rotated left 1468 * @param distance the number of bit positions to rotate left 1469 * @return the value obtained by rotating the two's complement binary 1470 * representation of the specified {@code int} value left by the 1471 * specified number of bits. 1472 * @since 1.5 1473 */ 1474 public static int rotateLeft(int i, int distance) { 1475 return (i << distance) | (i >>> -distance); 1476 } 1477 1478 /** 1479 * Returns the value obtained by rotating the two's complement binary 1480 * representation of the specified {@code int} value right by the 1481 * specified number of bits. (Bits shifted out of the right hand, or 1482 * low-order, side reenter on the left, or high-order.) 1483 * 1484 * <p>Note that right rotation with a negative distance is equivalent to 1485 * left rotation: {@code rotateRight(val, -distance) == rotateLeft(val, 1486 * distance)}. Note also that rotation by any multiple of 32 is a 1487 * no-op, so all but the last five bits of the rotation distance can be 1488 * ignored, even if the distance is negative: {@code rotateRight(val, 1489 * distance) == rotateRight(val, distance & 0x1F)}. 1490 * 1491 * @param i the value whose bits are to be rotated right 1492 * @param distance the number of bit positions to rotate right 1493 * @return the value obtained by rotating the two's complement binary 1494 * representation of the specified {@code int} value right by the 1495 * specified number of bits. 1496 * @since 1.5 1497 */ 1498 public static int rotateRight(int i, int distance) { 1499 return (i >>> distance) | (i << -distance); 1500 } 1501 1502 /** 1503 * Returns the value obtained by reversing the order of the bits in the 1504 * two's complement binary representation of the specified {@code int} 1505 * value. 1506 * 1507 * @param i the value to be reversed 1508 * @return the value obtained by reversing order of the bits in the 1509 * specified {@code int} value. 1510 * @since 1.5 1511 */ 1512 public static int reverse(int i) { 1513 // HD, Figure 7-1 1514 i = (i & 0x55555555) << 1 | (i >>> 1) & 0x55555555; 1515 i = (i & 0x33333333) << 2 | (i >>> 2) & 0x33333333; 1516 i = (i & 0x0f0f0f0f) << 4 | (i >>> 4) & 0x0f0f0f0f; 1517 i = (i << 24) | ((i & 0xff00) << 8) | 1518 ((i >>> 8) & 0xff00) | (i >>> 24); 1519 return i; 1520 } 1521 1522 /** 1523 * Returns the signum function of the specified {@code int} value. (The 1524 * return value is -1 if the specified value is negative; 0 if the 1525 * specified value is zero; and 1 if the specified value is positive.) 1526 * 1527 * @param i the value whose signum is to be computed 1528 * @return the signum function of the specified {@code int} value. 1529 * @since 1.5 1530 */ 1531 public static int signum(int i) { 1532 // HD, Section 2-7 1533 return (i >> 31) | (-i >>> 31); 1534 } 1535 1536 /** 1537 * Returns the value obtained by reversing the order of the bytes in the 1538 * two's complement representation of the specified {@code int} value. 1539 * 1540 * @param i the value whose bytes are to be reversed 1541 * @return the value obtained by reversing the bytes in the specified 1542 * {@code int} value. 1543 * @since 1.5 1544 */ 1545 public static int reverseBytes(int i) { 1546 return ((i >>> 24) ) | 1547 ((i >> 8) & 0xFF00) | 1548 ((i << 8) & 0xFF0000) | 1549 ((i << 24)); 1550 } 1551 1552 /** 1553 * Adds two integers together as per the + operator. 1554 * 1555 * @param a the first operand 1556 * @param b the second operand 1557 * @return the sum of {@code a} and {@code b} 1558 * @see java.util.function.BinaryOperator 1559 * @since 1.8 1560 */ 1561 public static int sum(int a, int b) { 1562 return a + b; 1563 } 1564 1565 /** 1566 * Returns the greater of two {@code int} values 1567 * as if by calling {@link Math#max(int, int) Math.max}. 1568 * 1569 * @param a the first operand 1570 * @param b the second operand 1571 * @return the greater of {@code a} and {@code b} 1572 * @see java.util.function.BinaryOperator 1573 * @since 1.8 1574 */ 1575 public static int max(int a, int b) { 1576 return Math.max(a, b); 1577 } 1578 1579 /** 1580 * Returns the smaller of two {@code int} values 1581 * as if by calling {@link Math#min(int, int) Math.min}. 1582 * 1583 * @param a the first operand 1584 * @param b the second operand 1585 * @return the smaller of {@code a} and {@code b} 1586 * @see java.util.function.BinaryOperator 1587 * @since 1.8 1588 */ 1589 public static int min(int a, int b) { 1590 return Math.min(a, b); 1591 } 1592 1593 /** use serialVersionUID from JDK 1.0.2 for interoperability */ 1594 @Native private static final long serialVersionUID = 1360826667806852920L; 1595 }

1 public boolean equals(Object obj) { 2 if (obj instanceof Integer) { 3 return value == ((Integer)obj).intValue(); 4 } 5 return false; 6 }

首先看看这个对象是不是Integer的类型的,如果是的话,我们比较一下两个对象的int类型的value是否相等。这样似乎和String的比较方法差不多了,但是如果是使用“==”来比较的时候就差得多了,因为这里的Integer使用了缓存,将[-128,127]的数字都缓存了一下,导致了两者相同,否则就创建出一个新的对象。
1 package com.consumer.test; 2 3 public class IntegerTest { 4 public static void main(String[] args) { 5 Integer i1=1; 6 Integer i2=1; 7 8 Integer i3=128; 9 Integer i4=128; 10 11 Integer i5=-128; 12 Integer i6=-128; 13 14 Integer i7=1000; 15 Integer i8=1000; 16 17 System.out.println("测试:"+(i1==i2)); 18 System.out.println("测试:"+(i3==i4)); 19 System.out.println("测试:"+(i5==i6)); 20 System.out.println("测试:"+(i7==i8)); 21 22 System.out.println("===================="); 23 24 System.out.println("测试"+ (i1.equals(i2))); 25 System.out.println("测试"+ (i3.equals(i4))); 26 System.out.println("测试"+ (i5.equals(i6))); 27 System.out.println("测试"+ (i7.equals(i8))); 28 } 29 }
让我们来看看这个缓存的定义,我们可以看到自动为我们创建了[-128,127]这么大的缓存空间。
1 private static class IntegerCache { 2 static final int low = -128; 3 static final int high; 4 static final Integer cache[]; 5 6 static { 7 // high value may be configured by property 8 int h = 127; 9 String integerCacheHighPropValue = 10 sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high"); 11 if (integerCacheHighPropValue != null) { 12 try { 13 int i = parseInt(integerCacheHighPropValue); 14 i = Math.max(i, 127); 15 // Maximum array size is Integer.MAX_VALUE 16 h = Math.min(i, Integer.MAX_VALUE - (-low) -1); 17 } catch( NumberFormatException nfe) { 18 // If the property cannot be parsed into an int, ignore it. 19 } 20 } 21 high = h; 22 23 cache = new Integer[(high - low) + 1]; 24 int j = low; 25 for(int k = 0; k < cache.length; k++) 26 cache[k] = new Integer(j++); 27 28 // range [-128, 127] must be interned (JLS7 5.1.7) 29 assert IntegerCache.high >= 127; 30 } 31 32 private IntegerCache() {} 33 }
再看一下valueOf方法,可以看到当我们传递的数字如果在这个期间的话直接就发挥缓存的值,这样空间得到了节省,否则我们在新建一个Integer对象返回,这就是其中的奥秘。

由此可以看到String和Integer都采用了优化方法,对于String,如果是str="..."这样定义的对象,就会将这些东西放到一个String池之中,只保留一份备份,因此,无论String的字符串是什么都可以这样来做==是true的;但是对于Integer就采用了另一种缓存的方式,只缓存了[-128,127]这些数值,超出了就直接创建新的对象,这样的设计和两者的应用场合是相关的,我们应该有清晰的了解。
三、总结
通过源码和一些例子,我们更加清晰地了解了equals和“==”的作用,以及在不同地方的区别,对我们编写程序有着深刻的意义。