相关阅读
【小家java】java5新特性(简述十大新特性) 重要一跃
【小家java】java6新特性(简述十大新特性) 鸡肋升级
【小家java】java7新特性(简述八大新特性) 不温不火
【小家java】java8新特性(简述十大新特性) 饱受赞誉
【小家java】java9新特性(简述十大新特性) 褒贬不一
【小家java】java10新特性(简述十大新特性) 小步迭代
【小家java】java11新特性(简述八大新特性) 首个重磅LTS版本
【小家java】Java中的线程池,你真的用对了吗?(教你用正确的姿势使用线程池)
小家Java】一次Java线程池误用(newFixedThreadPool)引发的线上血案和总结
【小家java】BlockingQueue阻塞队列详解以及5大实现(ArrayBlockingQueue、DelayQueue、LinkedBlockingQueue…)
【小家java】用 ThreadPoolExecutor/ThreadPoolTaskExecutor 线程池技术提高系统吞吐量(附带线程池参数详解和使用注意事项)
这是一个十分严重的线上问题
自从最近的某年某月某天起,线上服务开始变得不那么稳定(软病)。在高峰期,时常有几台机器的内存持续飙升,并且无法回收,导致服务不可用。
给出监控中GC的采样曲线:
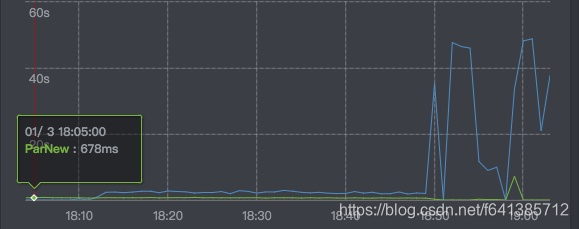
内存使用曲线如下:
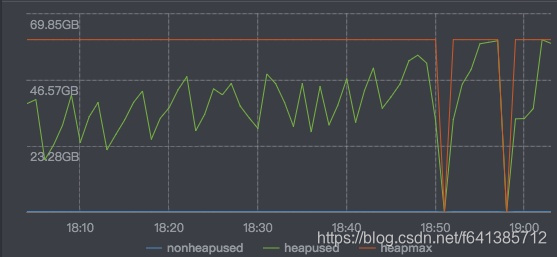
如上两张图显示:18:50-19:00的这10分钟阶段里,服务已经处于不可用的状态了。这就导致了:上游服务的超时异常会增加,该台机器会触发熔断。
熔断触发后,这台机器的流量会打到其他机器,其他机器发生类似的情况的可能性会提高,极端情况会引起所有服务宕机,造成雪崩,曲线掉底。
问题分析和猜想
结合我们的业务情况,我们监控到在那段时间里,访问量是最高的,属于一个高峰情况,因此我们初步断定,这个和流量高并发有密不可分个的关系。
1、因为线上内存过大,如果采用 jmap dump的方式,这个任务可能需要很久才可以执行完,同时把这么大的文件存放起来导入工具也是一件很难的事情
2、再看JVM启动参数,也很久没有变更过 Xms, Xmx, -XX:NewRatio, -XX:SurvivorRatio, 虽然没有仔细分析程序使用内存情况,但看起来也无大碍。
3、于是开始找代码,某年某天某月~ 嗯,注意到一段这样的代码提交:
private static ExecutorService executor = Executors.newFixedThreadPool(15);
public static void push2Kafka(Object msg) {
executor.execute(new WriteTask(msg, false));
}
这段代码的功能是:每次线上调用,都会把计算结果的日志打到 Kafka,Kafka消费方再继续后续的逻辑。
看这块代码的问题:咋一看,好像没什么问题,但深入分析,问题就出现在
Executors.newFixedThreadPool(15)这段代码上。
因为使用了 newFixedThreadPool 线程池,而它的工作机制是,固定了N个线程,而提交给线程池的任务队列是不限制大小的,如果Kafka发消息被阻塞或者变慢,那么显然队列里面的内容会越来越多,也就会导致这样的问题。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
如上,采用的是LinkedBlockingQueue,而它默认是一个无界队列。因此若使用不当,讲很快导致内存被打满,需要谨慎啊。
验证猜想
为了验证这个想法,做了个小实验,把 newFixedThreadPool 线程池的线程个数调小一点,然后自己模拟压测一下:
测试代码如下:
/**
* @author [email protected]
* @description
* @date 2018-11-04 10:13
*/
public class Main {
//创建一个固定线程池
private static ExecutorService executor = Executors.newFixedThreadPool(1);
//向kafka里推送消费
public static void push2Kafka(Object msg) {
executor.execute(() -> {
try {
//模拟 占用的内存大小
Byte[] bytes = new Byte[1024 * 1000 * 1000];
System.out.println(Thread.currentThread().getName() + "-->任务放到线程池:" + msg);
TimeUnit.MINUTES.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
public static void main(String[] args) {
//模拟高并发环境下 一直向线程池里面不停的塞任务
for (int i = 0; i < Integer.MAX_VALUE; i++) {
System.out.println("塞任务start..." + i);
push2Kafka(i);
System.out.println("塞任务end..." + i);
}
}
}
打开JConsole查看JVM的CPU、内存相关使用情况:
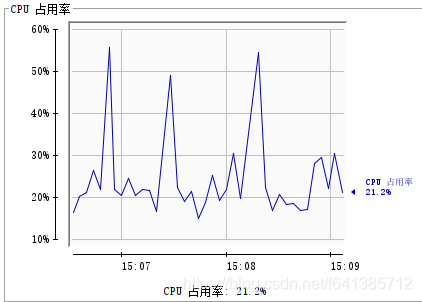
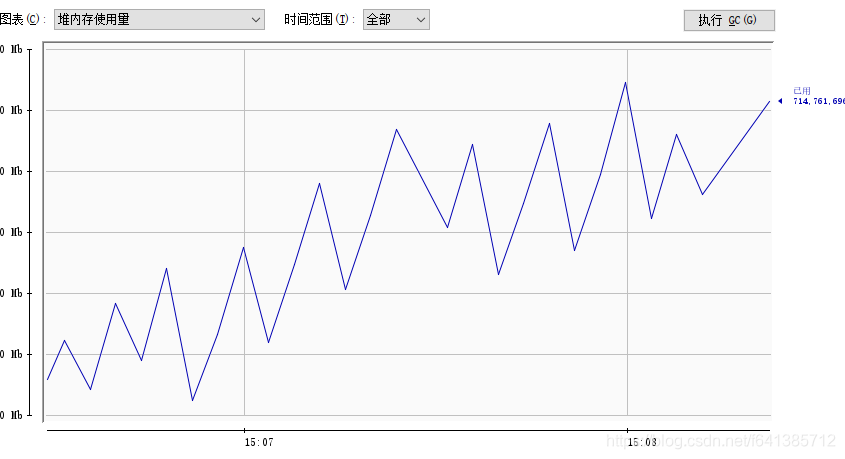
内存情况逐渐攀升,最终可以看出程序近乎停止。最终抛出内存异常
Exception in thread "pool-1-thread-295" java.lang.OutOfMemoryError: Java heap space
然而,电脑本机的实体内存,也是几乎会被占满:
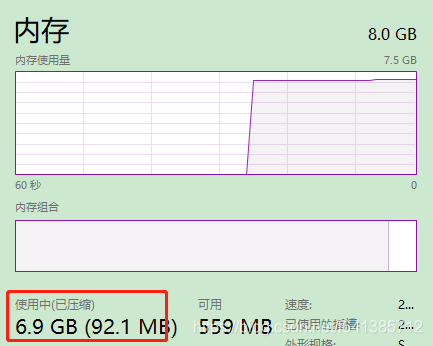
下面是程序启用和停止的内存情况:
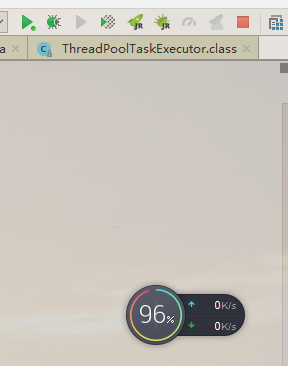
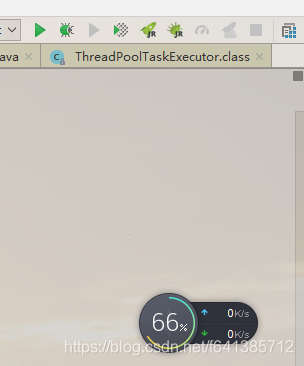
综上所诉,我们的猜想是正确的。如果消费的速度小于生产的速度,内存随着时间的堆积,很快就能被打满了。
解决方案
问题根源找到了,解决的方法其实就非常的简单了,采取了自定义线程池参数。
在我们的修复方案中,选择的就是有界队列,虽然会有部分任务被丢失,但是我们线上是排序日志搜集任务,所以对部分对丢失是可以容忍的。
Java提供的四种常用线程池解析 Executors
既然楼主踩坑就是使用了 JDK 的默认实现,那么再来看看这些默认实现到底干了什么,封装了哪些参数。简而言之 Executors 工厂方法Executors.newCachedThreadPool() 提供了无界线程池,可以进行自动线程回收;Executors.newFixedThreadPool(int) 提供了固定大小线程池,内部使用无界队列;Executors.newSingleThreadExecutor() 提供了单个后台线程。
newCachedThreadPool:可缓存线程池
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
这种类型的线程池特点是:
- 工作线程的创建数量几乎没有限制(其实也有限制的,数目为Interger. MAX_VALUE), 这样可灵活的往线程池中添加线程。
- 如果长时间没有往线程池中提交任务,即如果工作线程空闲了指定的时间(默认为1分钟),则该工作线程将自动终止。终止后,如果你又提交了新的任务,则线程池重新创建一个工作线程。
- 在使用CachedThreadPool时,一定要注意控制任务的数量,否则,由于大量线程同时运行,很有会造成系统瘫痪。
public class Main {
public static void main(String[] args) {
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int index = i;
try {
Thread.sleep(index * 100);
} catch (Exception e) {
e.printStackTrace();
}
cachedThreadPool.execute(() -> System.out.println(index + "当前线程" + Thread.currentThread().getName()));
}
}
}
输出:
0当前线程pool-1-thread-1
1当前线程pool-1-thread-1
2当前线程pool-1-thread-1
3当前线程pool-1-thread-1
4当前线程pool-1-thread-1
5当前线程pool-1-thread-1
6当前线程pool-1-thread-1
7当前线程pool-1-thread-1
8当前线程pool-1-thread-1
9当前线程pool-1-thread-1
发现10个线程都是使用的线程1,线程池为无限大,当执行第二个任务时第一个任务已经完成,会复用执行第一个任务的线程,而不用每次新建线程。
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
看代码一目了然了,线程数量固定,使用无限大的队列。再次强调,楼主就是踩的这个无限大队列的坑。
newScheduledThreadPool
创建一个定长线程池,支持定时及周期性任务执行。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
在来看看ScheduledThreadPoolExecutor()的构造函数:
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
ScheduledThreadPoolExecutor的父类即ThreadPoolExecutor,因此这里各参数含义和上面一样。值得关心的是DelayedWorkQueue这个阻塞对列。
它作为静态内部类就在ScheduledThreadPoolExecutor中进行了实现。简单的说,DelayedWorkQueue是一个无界队列,它能按一定的顺序对工作队列中的元素进行排列。
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
注意:该静态方法,禁止使用,因为里面有不少坑,这里不做过多解释
关于线程池的阻塞队列的各种用法,请参见博文:
【小家java】BlockingQueue阻塞队列详解以及5大实现(ArrayBlockingQueue、DelayQueue、LinkedBlockingQueue…)
结束语
虽然之前学习了不少相关知识,但是只有在实践中踩坑才能印象深刻吧
可以通过Executors静态工厂构建线程池,但一般不建议这样使用。
附:ThreadFactory简单介绍
ThreadFactory是一个线程工厂。用来创建线程。这里为什么要使用线程工厂呢?其实就是为了统一在创建线程时设置一些参数,如是否守护线程。线程一些特性等,如优先级。通过这个TreadFactory创建出来的线程能保证有相同的特性。它首先是一个接口类,而且方法只有一个。就是创建一个线程。
public interface ThreadFactory {
Thread newThread(Runnable r);
}
所以我们可以自己实现这个工厂,然后定制属于我们自己的一类线程
class MyThreadFactory implements ThreadFactory {
private int counter;
private String name;
private List<String> stats;
public MyThreadFactory(String name) {
counter = 0;
this.name = name;
stats = new ArrayList<String>();
}
@Override
public Thread newThread(Runnable run) {
Thread t = new Thread(run, name + "-Thread-" + counter);
counter++;
stats.add(String.format("Created thread %d with name %s on%s\n",t.getId(), t.getName(), new Date()));
return t;
}
public String getStas() {
StringBuffer buffer = new StringBuffer();
Iterator<String> it = stats.iterator();
while (it.hasNext()) {
buffer.append(it.next());
buffer.append("\n");
}
return buffer.toString();
}
}
//使用:
MyThreadFactory factory = new MyThreadFactory("MyThreadFactory");
Thread thread = factory.newThread(new MyTask(i));
thread.start();