HyperLeger Fabric开发(五)——HyperLeger Fabric账本存储
一、HyperLeger Fabric账本简介
Fabric里的数据以分布式账本的形式存储。账本由一系列有顺序和防篡改的记录组成,记录包含着数据的全部状态改变。账本中的数据项以键值对的形式存放,账本中所有的键值对构成了账本的状态,也称为世界状态(World State)。
每个通道中有唯一的账本,由通道中所有成员共同维护着账本,每个记账节点上都保存了所属通道的账本的一个副本,因而是分布式账本。对账本的访问需要通过链码实现对账本键值对的增加、删除、更新和查询等的操作。
账本由区块链和状态数据库两部分组成。
区块链是一组不可更改的有序的区块(数据块),记录着全部交易的日志。每个区块中包含若干个交易的数据,不同区块所包含的交易数量可以不同。区块之间用哈希链(Hashed-link)关联:每个区块头包含该区块所有交易的哈希值以及上一个区块头的哈希值。链式结构可以确保每个区块的数据不可更改以及每个区块之间的顺序关系不可更改。因此,区块链的区块只可以添加在链的尾部。
状态数据库记录了账本中所有键值对的当前值,相当于对当前账本的交易日志做了索引。链码执行交易的时候需要读取账本的当前状态,从状态数据库可以迅速获取键值的最新状态。
如果没有状态数据库,要获得某个键值时,需要遍历整个区块链中和该键值相关的交易,效率非常低,因此,读取状态数据库可以认为是快速定位和访问某个键值的方法。另外,当状态数据库出现故障的时候,可以通过遍历账本重新生成。
当一个区块附加到区块链尾部的时候,如果区块中的有效交易修改了键值对,则会在状态数据库中作相应的更新,确保区块链和状态数据库始终保持一致。
区块链的数据块以文件形式保存在各个节点中。状态数据库可以是各种键值数据库,Fabric缺省使用LevelDB ,也支持CouchDB的选项。CouchDB除了支持键值数据外,也支持JSON格式的文档模型,能够做复杂的查询。
二、HyperLeger Fabric交易流程
1、客户端向背书节点发送交易提案请求
客户端首先构建交易提案,交易提案的作用是调用通道中的链码来读取或者写入账本的数据。客户端使用Fabric SDK创建交易提案,并使用用户的私钥对交易提案进行签名。
Fabric SDK作用有两个,一个是将交易提案封装成符合gRPC协议的Protobuf格式的消息,一个是对创建的交易提案进行签名。
客户端打包完交易提案后,将交易提案提交给通道中的背书节点。背书节点的背书策略定义了哪些背书节点签名背书后交易才能有效,客户端根据背书策略选择相应的背书节点,并向相应背书节点提交交易提案。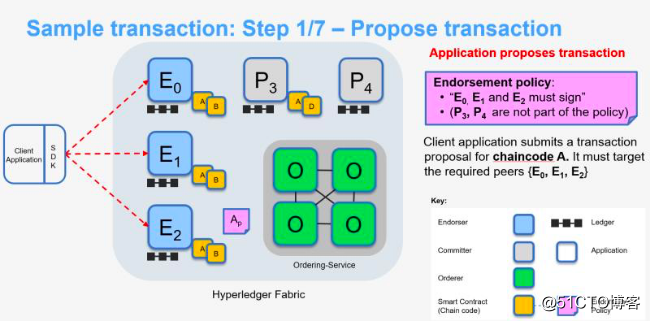
根据背书策略,E0,E1,E2三个背书节点需要完成签名背书。
2、背书节点对交易提案进行签名背书
背书节点收到交易提案后,使用MSP模块验证签名并确定请求者是否被合理授权进行交易提案的操作(使用每个channel对应的ACL进行验证),背书节点以交易提案凭证为输入,基于当前状态的数据库执行来生成交易结果,输出包括反馈值、读取集和写入集。此时,账本并未进行更新。背书节点会将背书节点输出、背书节点签名、是否背书声明作为交易提案反馈回传给客户端的SDK。
首先校验交易的签名是否合法,然后根据签名者的身份,确认其是否具有权限进行相关交易。此外,背书节点还需要检查交易提案的格式是否正确以及是否已经提交过(防止重放***)。
在所有合法性校验通过后,背书节点按照交易提案调用链码模拟执行交易。链码执行时,读取的数据(键值对)是背书节点中本地的状态数据库,链码读取过的数据回被归总到读集(Read Set);链码对状态数据库的写操作并不会对账本做改变,所有的写操作将归总到一个写入集(Write Set)中记录下来。读集和写集将在确认节点中用于确定交易是否最终写入账本。
在链码执行完成后,背书节点把链码模拟执行后得到的读写集(Read-Write Set)等信息签名后发回给客户端。此时,交易信息只在客户端和单个背书节点之间达成共识,并没有完成全网共识,各个客户端的交易顺序没有确定,可能存在双花问题,所以不是一个有效交易。同时,客户端需要收到大多数背书节点的验证回复后,才算验证成功,具体的背书策略由智能合约代码控制,可以由开发者自由配置。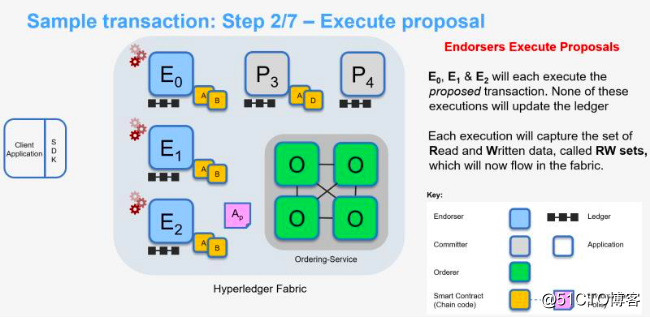
背书节点E0,E1,E2执行签名背书。
3、背书节点将签名背书结果返回给客户端
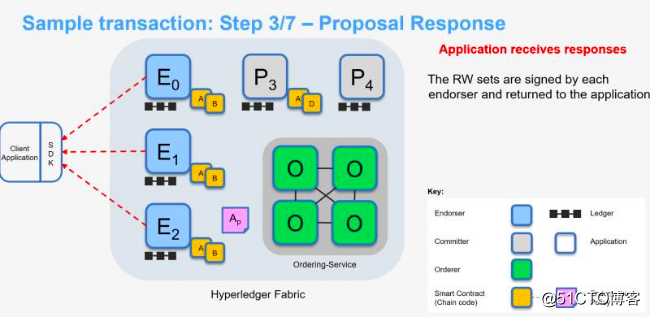
背书节点完成签名背书后,将反馈值、读取集和写入集、背书节点签名、是否背书声明作为交易提案反馈回传给客户端。
4、客户端向排序服务提交交易
客户端在收到背书节点的签名背书结果后,检查背书节点的签名并比较不同背书节点的结果是否一致。如果交易提案是查询账本的请求,则客户端无需提交交易给排序节点。如果交易提案是更新账本的请求,客户端在收集到满足背书策略的足够多背书节点的签名背书结果后,把背书节点返回的读写集、所有背书节点的签名和通道号发给排序服务节点。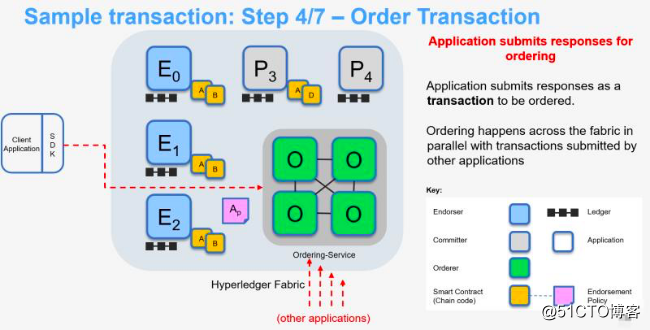
5、排序服务节点生成区块
排序服务节点在收到各个节点发来的交易后,并不检查交易的全部内容,而是按照交易中的通道号对交易分类排序,然后把相同通道的交易批量打包成区块。排序服务的共识算法以组件化形式插入Fabric网络,即开发者可以自由选择合适的共识算法。
排序服务节点将为特定通道生成的区块广播给通道中所有组织的主导节点。区块的广播有两种触发条件,一种是当通道的交易数量达到某个预设的阈值,另一种是在交易数量没有超过阈值但距离上次广播的时间超过某个特定阈值,也可触发广播数据块。两种方式相结合,使得经过排序的交易及时生成区块并广播给通道的Peer节点(记账节点)。
排序服务节点只是决定交易处理的顺序,并不对交易的合法性进行校验,也不负责维护账本信息,只有记账节点才有账本写入权限。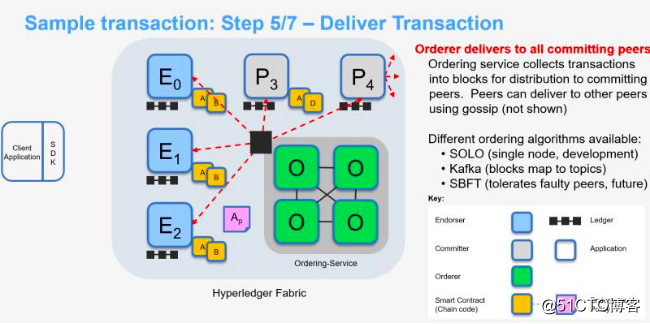
6、记账节点进行交易验证
记账节点收到排序服务节点发来的区块后,逐笔检查区块中的交易。先检查交易的合法性以及该交易是否曾经出现过。然后调用校验系统链码(VSCC,Validation System Chaincode)检验交易的签名背书是否合法,以及背书的数量是否满足背书策略的要求。
记账节点对交易进行多版本并发控制(MVCC)检查,即校验交易的读集(Read Set)是否和当前账本中的版本一致(即没有变化)。如果没有改变,说明交易写集(Write Set)中对数据的修改有效,把该交易标注为有效,交易的写集更新到状态数据库中。如果当前账本的数据和读集版本不一致,则该交易被标注为无效,不更新状态数据库。区块中的交易数据在标注成有效或无效后封装成区块写入账本的区块链中。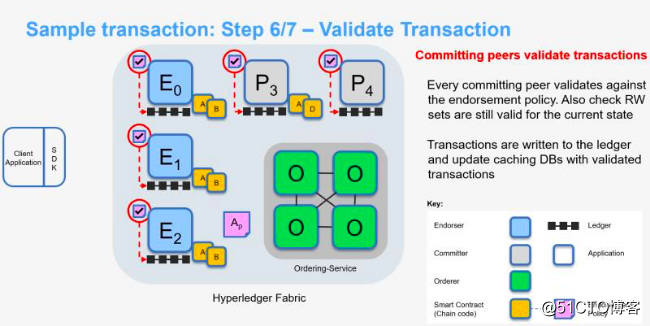
交易流程中,采用MVCC的乐观锁模型,提高了系统的并发能力。但MVCC也带来了一些局限性。例如,在同一个区块中若有两个交易先后对某个数据项做更新,顺序在后的交易将失败,因为后序交易的读集版本和当前数据项版本已经不一致。
7、记账节点通知客户端
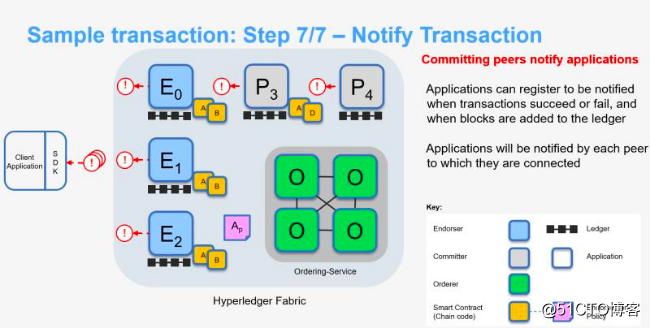
客户端会收到每一个连接的记账节点的通知。
8、交易流程总结
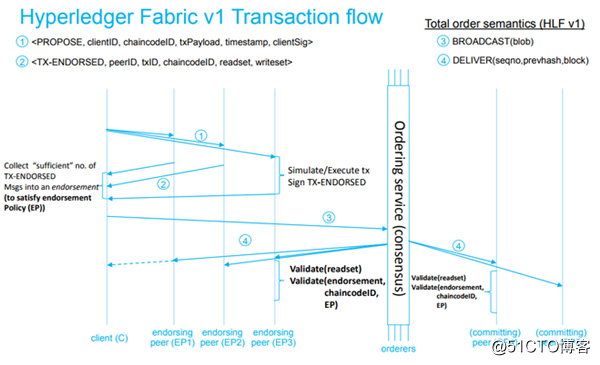
区块链的账本由Peer节点维护,并不是由排序服务集群维护,所以,只有Peer节点(背书节点和记账节点)包含完整的区块链信息,而排序服务集群只负责对交易进行排序,只保留处理过程中的一部分区块链信息。
Hyperledger Fabric网络中的节点是一个逻辑的概念,并不一定是一个台物理设备,但对于生产环境,为了系统架构的解耦,提高扩展性以及通过主机隔离提高安全性,Peer节点不能和排序服务节点部署在一台机器上,而背书节点和记账节点可以部署在同一台机器上。 背书节点校验客户端的签名,然后执行智能合约代码模拟交易。交易处理完成后,对交易信息签名,返回给客户端。客户端收到签名后的交易信息后,发给排序服务节点排序。排序服务节点将交易信息排序打包成区块后,广播发给记账节点,写入区块链中。
三、HyperLeger Fabric账本存储原理
1、Fabric账本存储原理
Fabric区块链网络中,每个通道都有其账本,每个Peer节点都保存着其所加入通道的账本,Peer节点的账本包含如下数据:
A、账本编号,用于快速查询存在哪些账本
B、账本数据,用于区块数据存储
C、区块索引,用于快速查询区块/交易
D、状态数据,用于最新的世界状态数据
E、历史数据:跟踪键的历史
Fabric的Peer节点账本中有四种数据库,idStore(ledgerID数据库)、blkstorage(block文件存储)、statedb(状态数据库)、historydb(历史数据库)。
账本数据库基于文件系统,将区块存储在文件块中,然后在区块索引LevelDB中存储区块交易对应的文件块及其偏移,即将区块索引LevelDB作为账本数据库的索引。目前支持的区块索引有:区块编号、区块哈希、交易ID、区块交易编号。
状态数据库存储的是所有曾经在交易中出现的键值对的最新值。调用链码执行交易可以改变状态数据,为了高效的执行链码调用,所有数据的最新值都被存放在状态数据库中;状态数据库是有序交易日志的快照,任何时候都可以根据交易日志重新生成状态数据库;状态数据库会在Peer节点启动的时候自动恢复或重构,未完备前,本Peer节点不会接受新的交易;状态数据库可以使用LevelDB或者CouchDB,CouchDB能够存储任意的二进制数据,支持富文本查询。
历史状态数据库用于查询某个key的历史修改记录,历史状态数据库并不存储key具体的值,而只记录在某个区块的某个交易里,某key变动了一次。后续需要查询的时候,根据变动历史去查询实际变动的值。
ledgerID数据库存储chainID,用于快速查询节点存在哪些账本。
对于单链的Peer节点账本(不包含ledgerID数据库)结构如下: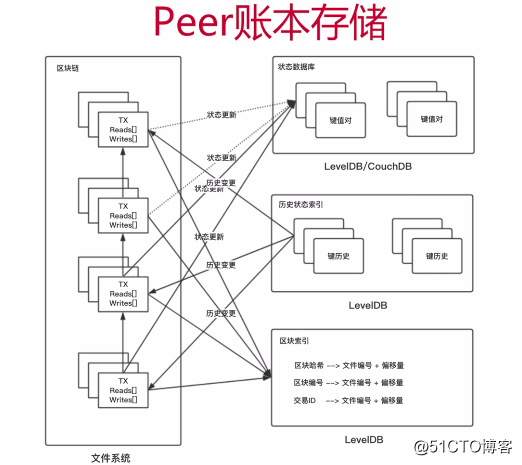
2、Peer账本结构
ledgersData是Peer节点账本的根目录,Peer节点的账本存储在Peer节点容器的/var/hyperledger/production/ledgersData目录下,通过命令行可以进入Peer节点容器进行查看,命令如下:
docker exec -it peer0.org1.example.com bash
Peer节点的本地账本结构如下: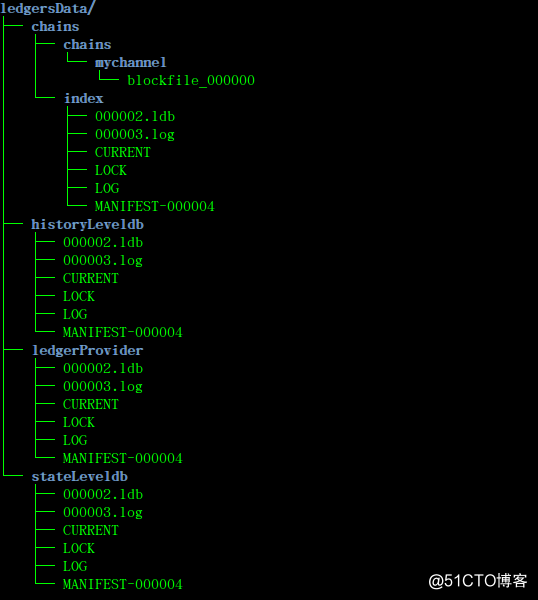
chains/chains目录下的mychannel目录channel的名称,Fabric支持多通道的机制,而通道之间的账本是隔离的,每个通道都有自己的账本空间。
chains/index目录包含levelDB数据库文件,存储区块索引数据库,使用leveldb实现。
historyLeveldb目录存储智能合约中写入的key的历史记录的索引地址,使用leveldb实现。
ledgerProvider目录存储当前节点所包含channel的信息(已经创建的channel id 和正在创建中的channel id),使用leveldb实现。
stateLeveldb目录存储智能合约写入的数据,可选择使用leveldb或couchDB
3、账本数据
账本数据以二进制文件的形式存储的,每个账本数据存储在不同的目录下。账本数据的所有操作都通过区块文件管理器实现。区块文件管理器创建的文件以blockfile_为前缀,6位数字为后缀,后缀必须是从小到大连续的数字,中间不能有缺失,因此账本最大可以持有1000000个文件块。默认的区块文件块大小的上限是64M(目前硬编码在代码中)。账本数据的结构如下: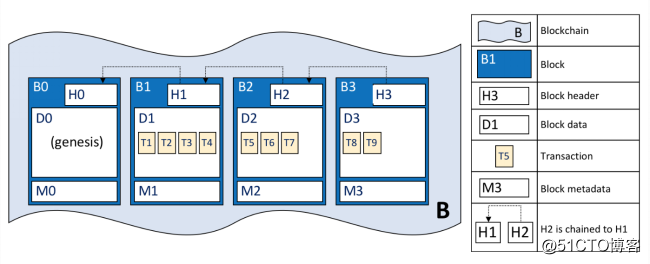
B代表区块链账本数据。其中B0为创世区块,其中包含了区块头H0,区块数据D0(创世区块里不包含交易数据),区块元数据M0。区块B1区块头H1,其中包含了前一个区块B0的加密hash和本身区块的加密hash。
4、区块结构
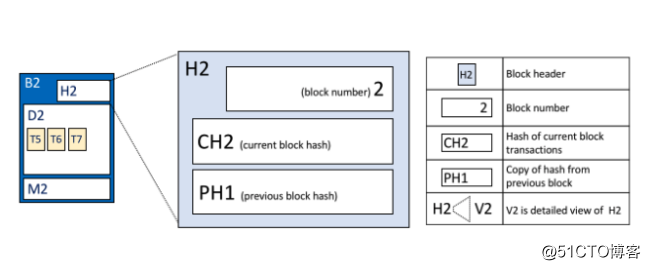
(1)区块头
区块头(Block Header)包含三部分:
A、区块数(Block Number):一个从0(创世区块)开始的整数,并且对于附加到区块链的每个新块增加1。
C、当前区块hash(Current Block Hash):当前区块中包含的所有交易的hash。
C、前一区块hash(Previous Block Hash):前一个区块的hash。
(2)区块数据
区块数据(Block Data)包含一组交易,交易在区块创建时写入。
(3)区块元数据
区块元数据(Block Matadata)包含区块创建时间,写入客户端的证书,公钥和签名。
5、交易结构
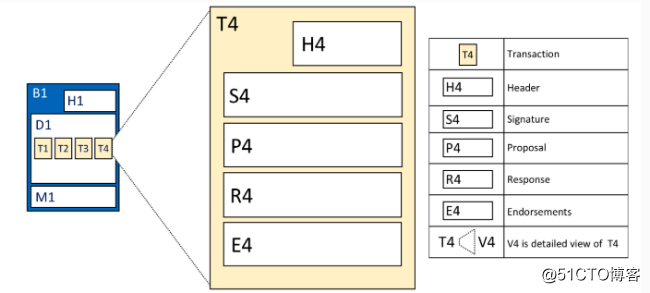
(1)交易头
交易头中包含了一些重要的交易元数据,例如链码的名称、版本。
签名
(2)签名
签名包含由客户端创建的加密签名,由客户端的私钥生成,用于检查交易有没有被篡改。
(3)交易提案
交易提案包含由客户端生成的交易请求参数。
(4)交易提案返回
交易提案返回包含由背书节点返回的模拟执行结果(读写集RWset)。
(5)背书
背书包含交易的背书,一个返回对应多个背书。
6、区块索引
区块索引用于快速定位区块。
索引键可以是区块高度、区块哈希、交易哈希。
索引值为区块文件编号+文件内偏移量+区块数据长度。
Hyperledger Fabric提供了多种区块索引的方式,以便能快速找到区块。索引的内容是文件位置指针(File Location Pointer)。文件位置指针由三个部分组成:所在文件的编号(fileSuffixNum)、文件内的偏移量(offset)、区块占用的字节数(bytesLength)。