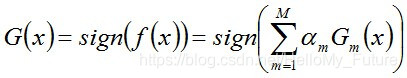1.Adaboost的原理
Adaboost是一种迭代算法,针对同一个训练集中的不同分类器,然后把这些弱分类器集合起来,构成一个更强的最终分类器。(Adaptive boosting)自适应增强算法,擅长处理分类问题、标签问题和回归问题,用于数据分类问题较为多见。对于分类器而言,它是基于测试过程中错误反馈调节的分类器的分类效果。
2.算法的流程
算法实际上是一个简单的弱分类算法的提升过程,通过不断的训练,从而提高数据的分类能力。具体来说,整个算法的流程可以分为3步:
1.初始化训练集的权值分布,若训练集中有N个样本,则每个样本的权值为 1/N;
2.在训练的过程中,如果某个样本被正确分类,那么在下一轮的训练中,这个样本的权值就会减小,相反,若某个样本没有被正确分类,那么在下一轮这个样本的权值就会增加,所有权值变更过的样本在下一轮中又会重新训练,不断的进行迭代下去。
3.最后是将各个训练的弱分类器组合成强分类器,根据弱分类器的误差来判断权值,若弱分类器的误差率较大,那么在最终的强分类器中,它的权值就会较小,反之,误差率较小的,那么权值就会较大。
具体流程:
给定一个训练数据集T={(x1,y1),(x2,y2),...(xN,yN)},其中的实例 x∈X,而实例空间X∈R,y属于标记集合{-1,+1},
步骤1:初始化训练数据的权值分布,每一个初始化训练样本的权值为 1/N
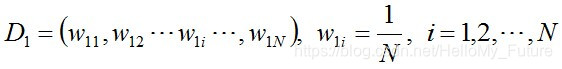
步骤2:不断的进行迭代,用m = 1,2,...,n,来表示迭代了多少轮
使用具有权值分布Dm的训练数据集,得到基本分类器(一般选误差率最低的阈值来作为基本分类器)
![]()
计算Gm(x)在数据训练集上的分类误差率
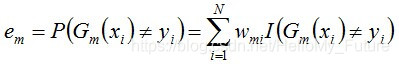
那么,Gm(x)的分类误差率em就是被Gm(x)误分类样本的权值之和。
接下来计算Gm(x)的系数,此系数am直接代表着这个分类器在最终分类器中的权重
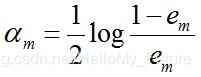
这个公式一般也可以写成am=1/2ln( (1-em)/em),表示自然底数为e,可以得到当em ≤ 1/2时,am ≥ 0,am随着·em的减小而增大,即误差率越小的分类器在最终分类器中权重越大。
更新训练集中的所有权值分布,然后进行下一轮迭代中。
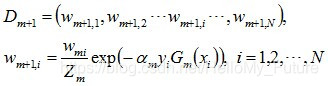
可以得到基本分类器Gm(x)被错误分类的样本权值增大,而正确分类的权值减小,比较侧重于较难分的样本上。
进行规范化,组成规范化因子Zm,使之成为一个概率分布
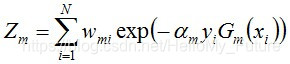
组合各个分类器:
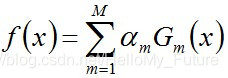
从而得到最终分类器: