csv文件的读取,有两种方法:调用pandas库函数或者直接用TensorFlow读取,
1、调用pandas
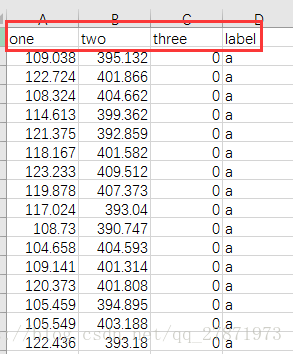
data.csv是自己随便搞的一个数据文件,数据样例和读取代码如下:
import tensorflow as tf
import pandas as pd
def pd_read_csv():
data_frame = pd.read_csv("data.csv", sep=",")
data1 = []
data2 = []
data3 = []
data4 = []
for index in data_frame.index:
data_row = data_frame.loc[index]
data1.append(data_row["one"])
data2.append(data_row["two"])
data3.append(data_row["three"])
data4.append(data_row["label"])
return (data1,data2,data3,data4)
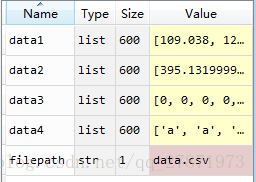
data1, data2, data3, data4 = pd_read_csv()数据的第一行都是有特征的,比如one、two.......,当然也可以是纯数字,只需要修改如下:
#部分代码修改
data_frame = pd.read_csv("data.csv", header=None)
dataset = data_frame.values
data_x = dataset[:, 0:3].astype(float)#前三列为data1-data3
label = dataset[:, 3] #第四列为data4或者label
得到的结果为:
2、使用TensorFlow方法
TensorFlow读取csv文件相比较pandas要复杂,还是使用上面的数据文件,只不过把第一行的特征删掉,data1是data的副本,TensorFlow这个读取方法可以一次读取多个文件。过程如下:
- 产生文件名列表,可以一次读取多个csv文件;
- 读取原始数据;
- 解析读出的原始数据,转化成数值数据或指定格式的数据;
- 开启多线程协调器,启动输入管道;
- 读取结束。
import tensorflow as tf
filename_queue = tf.train.string_input_producer(["data.csv", "data1.csv"])
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# key返回的是读取文件和行数信息;value是按行读取到的原始字符串,送到decoder解析
record_defaults = [[1.0], [1.0], [1.0], ["Null"]]
# 这里的数据类型和文件数据类型一致,必须是list形式
col1, col2, col3, col4 = tf.decode_csv(value, record_defaults=record_defaults)
features = tf.stack([col1, col2, col3])
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(600):
example, label = sess.run([features, col4])
print (example,col4)
coord.request_stop()
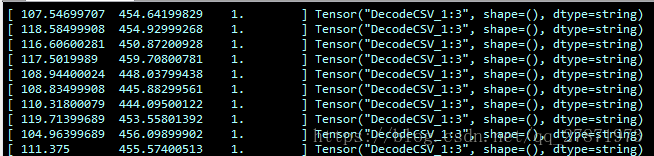
coord.join(threads)结果如下:
这里有几个点需要注意,代码注释中也已经写明。
- 文件名列表可以自己生成,也可以手写。
- key是文件信息和当前读取的行数,value是原始字符串。
- defualt有两个作用,一个是指定当前列的数据类型,一个是替补空值。
- 按行读取后读出的每个值都是rank为0的标量。
- stack函数可以堆叠,组成一个新的tensor,默认axis=0,因此就会横向把前面的标量串成一个rank为1的tensor。
参考:
[1] https://blog.csdn.net/freedom098/article/details/56006130