- 《SilhoNet: An RGB Method for 3D Object Pose Estimation and Grasp Planning》
2018,Gideon Billings and Matthew Johnson-Roberson,SilhoNet
1.引言:
自主机器人操纵通常涉及两项任务:
1)估计待操纵物体的姿态
2)选择可行的抓取点
在仅限于单目相机的场景时,过去的研究重点是分别解决这些问题。
本文中,作者引入了一种名为SilhoNet的新方法,它弥合了这两项任务之间的差距。使用卷积神经网络(CNN)管道,接受感兴趣区域(ROI)并同时预测具有相关遮挡掩模对象的中间轮廓表示,然后从预测的轮廓回归3D姿态。从预先计算的数据库中抓取点通过将它们反投影到遮挡物上进行过滤,以找到场景中可见的点。
本文中,主要的贡献有:
1) SilhoNet,一种新的基于RGB的深度学习方法,用于估计复杂场景中的姿态和遮挡;
2) 使用中间轮廓表示以便于在合成数据上学习模型以预测真实数据上的3D对象姿态,有效地桥接模拟到真实的域迁移;
3) 在新场景中使用推断轮廓的投影选择未被遮挡的抓握点的方法;
4) 对视觉上具有挑战性的YCB-Video数据集进行评估,其中提出的方法优于最先进的RGB方法。
2.实现方案
本文的方法:是结合1)深度学习对单目图像中3D姿态估计的能力和2)对象模型的先验知识,并通过考虑杂乱环境中其他对象的遮挡来过滤预先计算的抓握点。
该方法主要由两个阶段组成:
1)预测对象的中间轮廓表示和遮挡掩模
2)从预测的轮廓回归3D方向四元数
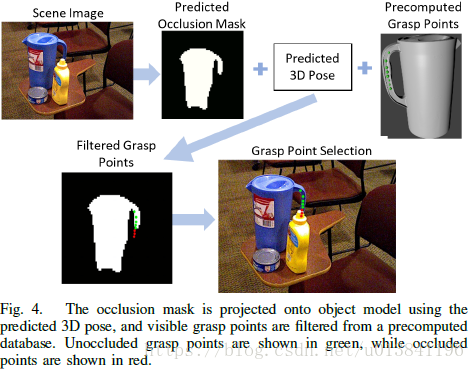
基于RGB视点中检测到的对象的估计遮挡和对象模型的先验知识,从预先计算的抓握数据库确定可行的抓握点。
网络结构:
A. Overview of the Network Pipeline
网络的输入是RGB图像和识别物体的ROI边界框以及对应的类别标签。第一阶段使用VGG16主干末端带有反卷积层,从RGB输入图像生成特征图。输入图像中的提取特征与来自一组渲染对象视点的特征连接,然后通过两个相同结构的网络分支来预测完整的未被遮挡的轮廓和遮挡遮罩。网络的第二阶段通过ResNet-18架构传递预测的轮廓,在末端具有两个完全连接的层,已输出表示3D姿态的L2标准化四元数。
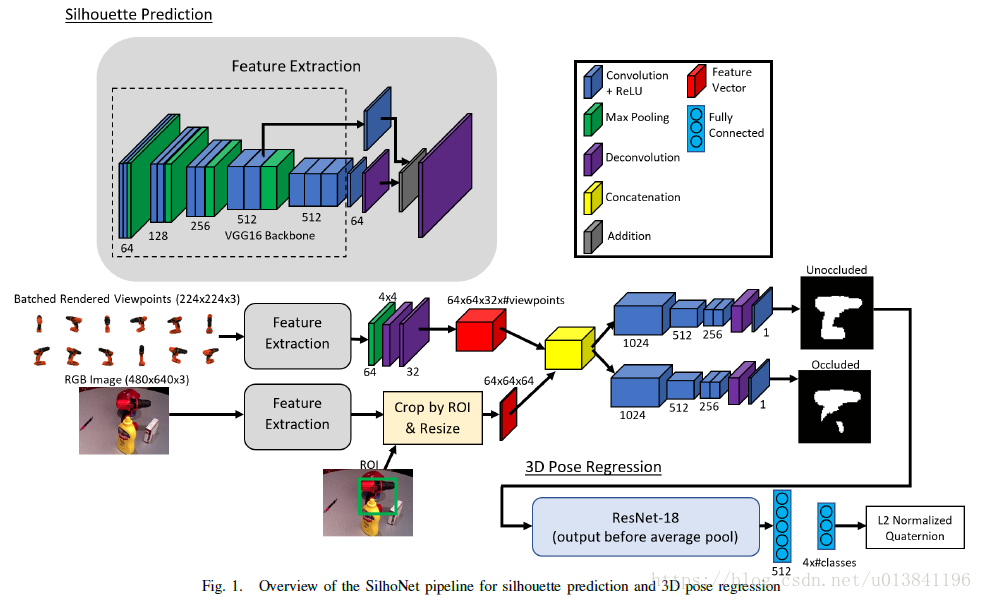
- Predicted ROIs:
ROI在特征提取阶段之后作为网络的输入特征,它主要用于从输入图像特征图中裁剪出相应的区域。然后通过缩小特征图或使用双线性插值将其缩放,将裁剪的特征图调整为高度和宽度=64x64。 - Rendered Model Viewpoints:
我们能够通过生成一组与检测到的对象类相关联的合成预渲染视点作为第一阶段的附加输入,来提高轮廓预测性能的网络。对于每个类,我们从对象模型渲染了一组12个视点,每个视点的维度为224x224。由于中间目标是轮廓预测,这些合成渲染在捕捉不同方向的真实物体的形状和轮廓方面做得非常出色,尽管模拟物体的视觉外观存在典型的域差异。
识别物体的所有视图都通过特征提取阶段,然后通过4x4的最大池化,再增加两个反卷积层,将其调整为64x64大小,通道为32的特征映射。在实现中,本文为每个对象即时提取渲染视图的特征映射,然后与裁剪和调整大小的输入图像特征图进行连接,提供给网络。 - Silhouette Prediction:
网络的第一阶段将对象的中间轮廓表示预测为64x64的二维掩模。
网络的第一部分是VGG16特征提取器,它以1/2,1/4,1/8和1/16比例生成特征图。1/8和1/16比例特征图都具有512的输出通道尺寸。使用两个卷积层将两者的通道减小到64。
RGB的特征映射与渲染的视点特征映射连接,从而生成大小为64x64x448的单个特征向量矩阵。特征向量矩阵被传送到两个相同的网络分支中,其中一个输出轮廓预测而另一个输出遮挡掩模。 - 3D Pose Regression:
本文使用四元数表示3D姿态,它可以表示连续空间中的作用于单位长度矢量的3D旋转。
网络的第二阶段接收预测的轮廓概率图,将某些值阈值化为二进制掩模,并输出对象姿态的四元数预测。网络的这个阶段由ResNet-18骨干网组成。
B. Grasp Point Detection
最后一步是检测视觉上可行的抓取点。给定对象的估计3D姿态和预先计算的抓握点的数据库,我们将每个抓取点从对象框架投影到相机框架中的遮挡遮罩上。掩模的未被遮挡部分上的点被认为是有效的,并且可以从有效集中选择最高得分抓握。
3.实验结果
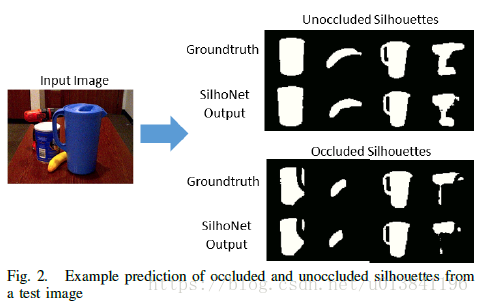
第一阶段数据结果显示:
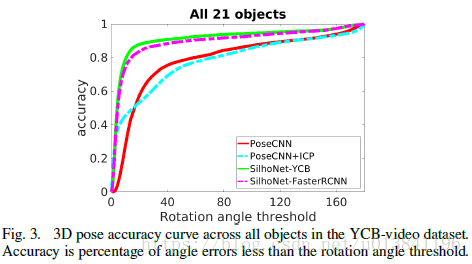
和其他网络结构进行比较:
小结:
特征提取用到了多尺度,使用识别物体的ROI作为输入,中间掩模进行遮挡检测和姿态估计。
参考:
http://www.sohu.com/a/255001737_100177858