对于类似lucene这样的搜索程序来说,首先了解其整个组件结构是非常有必要的,现在整体主观上对它有一个简单了解,然后逐一击破学习。初学者很多人都以为lucene是一个完成的搜索程序,其实这种理解是错误的。它其实仅仅是搜索程序的核心索引和搜索模块的一部分。刚才我们说过Lucene是有索引和搜索的两个过程,包含索引创建、索引、搜索三个要点。让我们更细一些看Lucene的各组件的构成和工作流程:
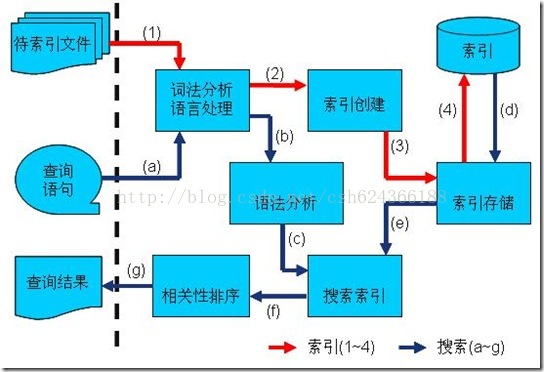
下面我们就简单来看一下lucene中两个最重要的组成部分
一:索引组件
使用索引可快速访问数据中的特定信息。索引是对数据记录中一列或多列的值进行排序的一种结构,索引是一个单独的、物理的数据结构,它是某个记录中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。会帮助您更快地获得该信息。大家想象一下,如果没有索引的话,我们查找某个文件的记录,最简单想到的方式就是一条一条记录的顺序查找,如果数据量比较小的话还没什么,如果数据量达到上百万,上千万的话,大家可以想象一下这个搜索时间。在lucene中使用索引就要必须建立对文本文件的索引,将文本内容转换成能快速进行搜索的文件格式。从而消除由于慢速顺序扫描带来的效率低的影响。大家可以把索引想象成一种数据结构,它可以提供一种对文本文件内容随机访问的机制。下面我们就来看一下整个索引的步骤
1.获取内容
Lucene本身没有提供获取内容的工具或者组件,内容是要开发者自己提供相应的程序。这一步包括使用网络爬虫或蜘蛛程序来搜索和界定需要索引的内容。当然,数据来源可能包括数据库、分布式文件系统、本地xml等等。lucene作为一款核心搜索库,不提供任何功能来实现内容获取。目前有大量的开源爬虫软件可以实现这个功能,例如:Solr,lucene的子项;Nutch,apache项目,包含大规模的爬虫工具,抓取和分辨web站点数据;Grub,比较流行的开源web爬虫工具;Heritrix,一款开源的Internet文档搜索程序;Aperture,支持从web站点、文件系统和邮箱中抓取,并解析和索引其中的文本数据。
获取到内容之后,下一步我们来看一下如何根据获取到的内容来建立相应的小数据块,也成为文档。
2.建立文档
获取原始内容后,需要对这些内容进行索引,必须将这些内容转换成部件(文档)。文档主要包括几个带值的域,比如标题,正文,摘要,作者和链接。如果文档和域比较重要的话,还可以添加权值。设计完方案后,需要将原始内容中的文本提取出来写入各个文档,这一步可以使用文档过滤器,开源项目如Tika,实现很好的文档过滤。如果要获取的原始内容存储于数据库中,有一些项目通过无缝链接内容获取步骤和文档建立步骤就能轻易地对数据库表进行航所以操作和搜索操作,例如DBSight,Hibernate Search,LuSQL,Compass和Oracle/Lucene集成项目。
3文档分析
搜索引擎不能直接对文本进行索引:必须将文本分割成一系列被称为语汇单元的独立的原子元素。每一个语汇单元能大致与语言中的“单词”对应起来,这个步骤决定文档中的文本域如何分割成语汇单元系列。lucene提供了大量内嵌的分析器可以轻松控制这步操作。
4文档索引
将文档加入到索引列表中。Lucene在这一步骤中提供了强档的API,只需简单调用提供的几个方法就可以实现出文档索引的建立。
为了提供好的用户体验,索引是必须要处理好的一环:在设计和定制索引程序时必须围绕如何提高用户的搜索体验来进行。
二:搜索组件
搜索组件即为输入搜索短语,然后进行分词,然从索引中查找单词,从而找到包含该单词的文档。搜索质量由查准率和查全率来衡量。搜索的细节还是比较复杂的。这也是我们以后讲解lucene的主要内容之一。尤其是在搜索速度和搜索大容量数据的能力在搜索技术中是比较重要的。搜索组件主要包括以下内容:
1.用户搜索界面:主要是和用户进行交互的页面,也就是呈现在浏览器中能看到的东西,这里主要考虑的就是页面UI设计了。一个良好的UI设计是吸引用户的重要组成部分。
2.建立查询:建立查询主要是指用户输入所要查询的短语,以普通HTML表单或者ajax的方式提交到后台服务器端。然后把词语传递给后台搜索引擎。这就是一个简单建立查询的过程。
3.搜索查询:即为查询检索索引然后返回与查询词语匹配的文档。然后把返回来的结构按照查询请求来排序。搜索查询组件覆盖了搜索引擎中大部分的复杂内容。
常见的搜索理论模型主要有以下3种:

4.展现结果:所谓展现结果,和第一个搜索界面类似。都是一个与用户交互的前端展示页面,作为一个搜索引擎,用户体验永远是第一位。其中前端展示在用户体现上占据了重要地位
Ok,上面就主要讲解了搜索程序的两个比较重要的组件,这里只是简单介绍一下,在以后的博文中我们还会详细介绍。最后我们就简单看一下lucene在这两个组件方面所提供的几个API。
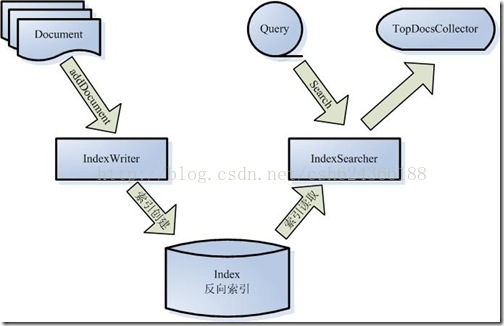
简单解释一下这个图:
1.被索引的文档用Document对象表示
2.IndexWriter通过函数addDocument将文档添加到索引中,实现创建索引的过程
3.Lucene的索引是反向索引
4.当用户查询请求时,Query代表用户查询语句
5.IndexSearcher通过函数search搜索Lucene Index
6.IndexSearcher计算Term Weight和Score并且将结果返回给用户
7.返回给用户的文档集合用TopDocsCollector表示