经过前面的简单理论介绍,相信大家对搜索引擎lucene有个简单的了解。前面我们也提到过在lucene中主要包括索引和搜索这两大方面的组件。今天我们我们就通过一个简单的实例来看一下lucene给我们提供的有关这两个组件的简单用法。
一:创建索引
在用lucene搜索之前,我们首先要做的就是是创建索引,只有有索引了,我们才有了搜索的对象,下面我们就根据一个创建索引的小demo来一步步分析一下创建索引的步骤:
public class Indexer {
private IndexWriter writer = null;
public Indexer(String indexDir) throws Exception {
Directory dir = FSDirectory.open(new File(indexDir));//打开保存索引目录
writer = new IndexWriter(dir, new StandardAnalyzer(Version.LUCENE_30),
true, IndexWriter.MaxFieldLength.UNLIMITED);//创建lucene IndexWriter,创建索引工具
}
public void close() throws Exception
{
writer.close();
}
public int index(String dataDir, FileFilter filter) throws Exception {
File[] files = new File(dataDir).listFiles();
for (File file : files) {//遍历文件目录下所有txt文件,把文件加入索引
if(!file.isDirectory() && !file.isHidden() && file.exists()
&& (filter == null || filter.accept(file))) {
indexFile(file);
}
}
return writer.numDocs();
}
private Document getDocument(File f) {
Document doc = new Document();
try {
doc.add(new Field("content", new FileReader(f)));
doc.add(new Field("fileName", f.getName(), Field.Store.YES,
Field.Index.NOT_ANALYZED));
doc.add(new Field("filePath", f.getCanonicalPath(),
Field.Store.YES, Field.Index.NOT_ANALYZED));
} catch (Exception e) {
e.printStackTrace();
}
return doc;
}
public void indexFile(File f) throws Exception {
System.out.println("make indexfile is " + f.getCanonicalPath());
Document doc = getDocument(f);//创建文件document
writer.addDocument(doc);//把当前文件document加入索引
}
public static void main(String[] args) throws Exception {
String indexDir = "d:\\";// 创建索引的目录
String dataDir = "d:\\a\\";// 创建文件目录
long begin = System.currentTimeMillis();
Indexer index = new Indexer(indexDir);
int numIndexed;
numIndexed = index.index(dataDir, new TextFilesFilter());
long end = System.currentTimeMillis();
index.close();
System.out.println("all makeindex num is:"+numIndexed+" use time :"+(end-begin));
}
}
class TextFilesFilter implements FileFilter
{
public boolean accept(File file)
{
return file.getName().toLowerCase().endsWith(".txt");
}
}
从上面demo中的注释中相信大家也差不多也能看懂大体意思。下面我们还是从main函数一步步的看一下吧
1. 首先根据构造方法创建实例对象时创建索引器indexWriter。这是创建索引时用到的一个主要类,在下面我们会详细降到。
2. 创建完索引器之后,根据指定的文件目录遍历所有符合要求的文件,然后对每一个文件创建一个Document对象。
3. 把创建的document对象加入索引器进行索引。
上面只是大体的介绍了一下整个索引步骤,有些细节我没有提到,相信大家也很容易看懂。比如床架文件过滤fiter之类的操作。
Ok,写到这里,我们就来看一下运行这个创建索引程序能看到什么结果吧。
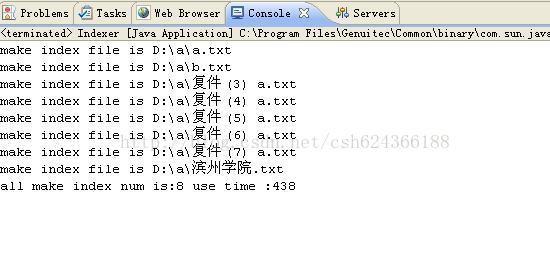
运行之后,我们会发现,在我们制定的索引文件夹下会多出以下几个文件:这几个文件具体是什么东东,其实我也不知道,也许以后慢慢的会研究到这些索引文件的内容:

二:搜索相关
Ok,索引内容我们就简单介绍到这,下面我们来看一下lucene中搜索方面的简单实现,还是以一段简单的代码来认识一下:
public class Searcher {
public static void main(String[] args) throws Exception {
String indexDir = "d:\\index";// 创建索引的目录
System.out.println("请输入您要搜索的关键字:");
Scanner scanner = new Scanner(System.in);
String queryStr = scanner.next();
Search(indexDir,queryStr);
}
public static void Search(String indexDir, String queryStr) throws Exception
{
Directory dir = FSDirectory.open(new File(indexDir));
IndexSearcher searcher = new IndexSearcher(dir);
QueryParserparser = new QueryParser(Version.LUCENE_30,"content",new StandardAnalyzer(Version.LUCENE_30));
Query query = parser.parse(queryStr);
TopDocs hits = searcher.search(query, 10);
long begin = System.currentTimeMillis();
TopDocs hits = searcher.search(query, 10);
long end = System.currentTimeMillis();
System.out.println("search the word: "+queryStr+". all search use time is:"+(end-begin)+"。 and get resultnum is : "+hits.totalHits);
for(ScoreDoc doc :hits.scoreDocs)
{
Document document = searcher.doc(doc.doc);
System.out.println(document.get("filePath"));
}
}
}
下面还是简单说一下实现的基本过程:
1. 首先打开索引文件,然后输入要搜索的关键字
2. 创建索引搜索器IndexSearcher,创建查询条件QueryParser
3. 利用查询字符串解析字符串在索引返回Query对象。
4. 调用indexsearcher的search方法进行查询,返回TopDocs对象。
5. 遍历查询得到的结果。
运行一下这个searcher我们会得到以下结果:
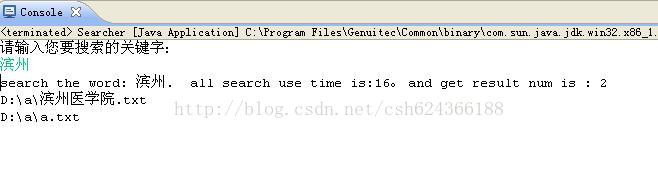
当然了。我们这里只是做一个小小的demo来学习lucene的搜索组件,读者自己可以做成web应用程序类型或者桌面应用的类型。这里我们只是简单的实现后端代码。搜索过程就在控制台简单实现一下。有兴趣的读者可以美化一下。这里我们也只是简单的搜索了一个关键字,也没有进行分词之类的,在以后的文章中我们会慢慢完善,一点点与应用搜索引擎靠近。
三、索引过程中的核心类
1. IndexWriter(写索引)是索引过程中的核心类。这个类负责创建新索引或者打开已有索引,以及向索引中添加、删除或者更新被索引文档的信息。其实这个类可以这样理解,它就是对索引中的内容进行CRUD的。但不能进行读取或者搜索。可以改变索引里面的内容。
2. Directrory类描述了lucene索引的存放位置。这个类是一个抽象类,它的子类负责实现指定具体的索引位置。在上面的例子中我们用FSDirectory.open方法来获取真实文件在文件系统的存储路径。
3. Analyzer:IndexWriter不能直接索引文本,这需要先由Analyzer类将文本进行分词。我们看一下在Lucenein Action 这本书中对lucene的介绍:

4. Document:document对象是指一组域的集合,其实他是指一个虚拟的文档。这里的文档是我们从很多类型文件中(比如web页面,邮件内容)中提取相关信息组成的一些元数据。一个Document 对象由多个Field 对象组成的。可以把一个Document 对象想象成数据库中的一个记录,而每个Field 对象就是记录的一个字段。
5. Filed索引中的每个文档都包含一个或多个不同命名的域。这些域都包含在field的类中。每个域都有一个域名和对应的域值。就和键值对类似。也就是说Field对象是用来描述一个文档的某个属性的,比如一封电子邮件的标题和内容可以用两个Field 对象分别描述。
四、搜索过程的核心类
1. IndexSearcher:这个类类似于一个搜索组件的大管家,负责对索引的搜索。它只能以只读的方式打开一个索引,所以可以有多个IndexSearcher 的实例在一个索引上进行操作。利用其search方法可以把query类封装好的查询关键字和条件进行查询。一个典型的应用实例:
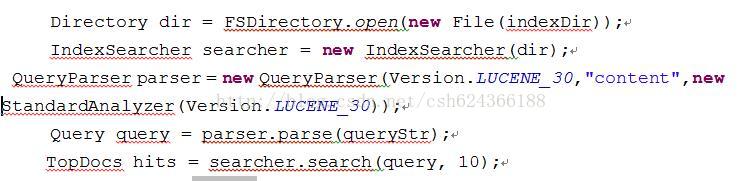
2. Term 是搜索的基本单位,这个类主要有查询域名和域值组成。一个Term 对象有两个String 类型的域组成。生成一个Term 对象可以有如下一条语句来完成:
Term term = newTerm(“fieldName”,”queryWord”); 其中第一个参数代表了要在文档的哪一个 Field 上进行查找,第二个参数代表了要查询的关键词。
3. Query:此类主要是一个查询类的综合,类中可以指定查询域和一些查询条件。这算是一个查询父类,它有很多子类。最常用的实现类是TermQuery。其余它还有一些BooleanQuery、TermRangeQuery、FiteredQuery等类。
4. TermQuery:TermQuery 是抽象类 Query 的一个子类,它同时也是 Lucene 支持的最为基本的一个查询类。生成一个 TermQuery 对象由如下语句完成: TermQuerytermQuery = new TermQuery(new Term(“fieldName”,”queryWord”)); 它的构造函数只接受一个参数,那就是一个 Term 对象。
5.Hits 是用来保存搜索的结果的。在搜索完成之后,需要把搜索结果返回并显示给用户,只有这样才算是完成搜索的目的。在lucene中,搜索的结果的集合是用hits类的实例来表示的。这里再提一下hits,这也是lucene比较精彩的地方,熟悉hibernate的朋友都知道hibernate有一个延迟加载的属性,同样,lucene也有。hits对象也是采用延迟加载的方式返回结果的,当要访问某个文档时,hits对象就在内部对lucene的索引又进行一次检索,最后
才将结果返回到页面显示。hits对象中主要方法有:
length(): 返回搜索结果的总数,下面简单的用法中有用到hit的这一个方法
doc(int n): 返回第n个文档
iterator(): 返回一个迭代器
6.TopDocs: 搜索结果的容器。TopFieldDocs是其派生类,也是存放搜索结果的容器。他是一个简单的指针容器。指针一般指向排名前N项的搜索结果。
OK,以上就是我们简单的对Lucene常用核心类的功能简单说了一下,在以后的文章中几乎每个类我们都会仔细的研究的,甚至应该会读一下他的源码。所以,有些内容弄不明白大家不用着急。
欲知更多精彩内容,欢迎继续关注本博。